




 DistilBERT是一种通过知识蒸馏技术从大型BERT模型中提炼出的小型化版本,它在保持性能的同时显著减少了参数数量,提高了运行速度。本文介绍了DistilBERT的设计理念,包括去除token-type embeddings和pooler层,仅保留6层transformer,并采用特定的初始化和训练策略。
DistilBERT是一种通过知识蒸馏技术从大型BERT模型中提炼出的小型化版本,它在保持性能的同时显著减少了参数数量,提高了运行速度。本文介绍了DistilBERT的设计理念,包括去除token-type embeddings和pooler层,仅保留6层transformer,并采用特定的初始化和训练策略。
前言
Abstract
就是蒸馏bert,减少参数,加快速度。
1、Introduction
基于 Transformer 的与预训练的模型尺寸越来越大:
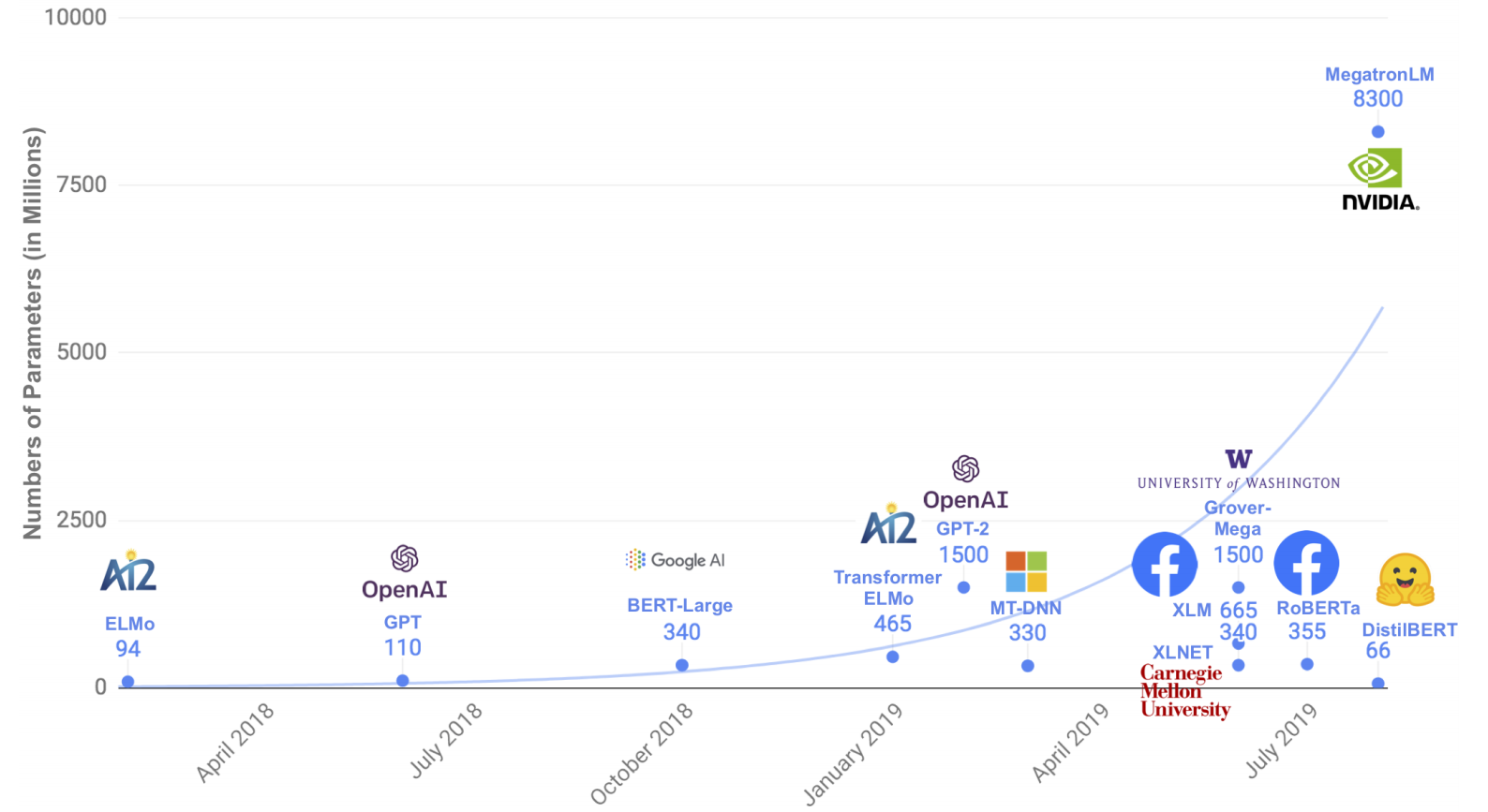
模型越来越大,速度也越来越慢,然后作者提出蒸馏的方法解决该问题。
作者在这篇论文中证明了使用预先经过知识蒸馏训练的小得多的语言模型可以在许多下游任务上达到相似的性能,从而使得模型在推理时更轻更快。
2、Knowledge distillation
这部分就介绍了经典的模型蒸馏的方法。有兴趣也可以去看我 FastbBert 的博客,里面也有介绍。
3、DistilBERT: a distilled version of BERT
- 1、它的整体的模型很简单,就是将 Bert 中的 token-type embeddings 和 pooler 层移除,其它结构不变,然后只用6层 transformer。
- 2、初始化学生网络,从 teacher 模型中每两层中抽取一层来初始化 student 模型。
- 3、使用训练Bert的预料,来进行蒸馏训练。
没了。
感觉这篇论文简单粗暴,全程一个公式都没有,然后效果还不错,后面的论文动不动就把它拉出来吊打一顿。

















 2637
2637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









