




 本文提出了一种基于图神经网络的文本分类方法TextGCN,该方法通过构建文本图,利用文档和词的异构信息,实现了在多个基准数据集上的最佳分类效果。
本文提出了一种基于图神经网络的文本分类方法TextGCN,该方法通过构建文本图,利用文档和词的异构信息,实现了在多个基准数据集上的最佳分类效果。
前言
- 论文地址:https://wvvw.aaai.org/ojs/index.php/AAAI/article/view/4725
- 代码:https://github.com/yao8839836/text_gcn
Introduction
本文是解决分类任务
两个贡献点:
- 提出了使用图神经网络来解决文本分类,有效利用文档、词等的异构信息。
- 在 benchmark 上达到了 state-of-the-art 的效果。
Related Work
作者在这部分主要介绍了两部分内容:
- 一是传统的分类方法和深度学习的方法。
- 二是介绍了 GCN 在其他 NLP 任务上的一些应用。
Method
1、GCN
先介绍常规的 GCN 模型:
- graph G = ( V , E ) G = (V, E) G=(V,E),其中 V V V 表示 node, E E E 表示 edge,这里假设每个节点都与自己相连。
- A A A 是 graph G G G 的邻接矩阵。
- X X X 是一个特征矩阵, X ∈ R n × m X \in R^{n\times m} X∈Rn×m, n n n 是节点数, m m m 是特征数。
- D D D 是度矩阵, D i i = ∑ j A i j D_{ii} = \sum_jA_{ij} Dii=∑jAij,它是一个对角矩阵。
图卷积网络公式如下:
L
(
1
)
=
ρ
(
A
~
X
W
0
)
L^{(1)} = \rho (\tilde{A}XW_{0})
L(1)=ρ(A~XW0)
L ( j + 1 ) = ρ ( A ~ L ( j ) W j ) L^{(j+1)} = \rho(\tilde{A}L^{(j)}W_j) L(j+1)=ρ(A~L(j)Wj)
其中, A ~ = D − 1 2 A D − 1 2 \tilde{A} = D^{-\frac{1}{2}}AD^{-\frac{1}{2}} A~=D−21AD−21,且 W 0 ∈ R m × k W_0 \in R^{m\times k} W0∈Rm×k, ρ \rho ρ 是激活函数。
2、Text GCN
这部分是作者提出来的,首先作构建了一个文本图,图中的 node 包括 word 和 document,用 one-hot 编码初始化 X X X。图中的边分为两种,分别是 document-word 和 word-word,边的权重定义如下:

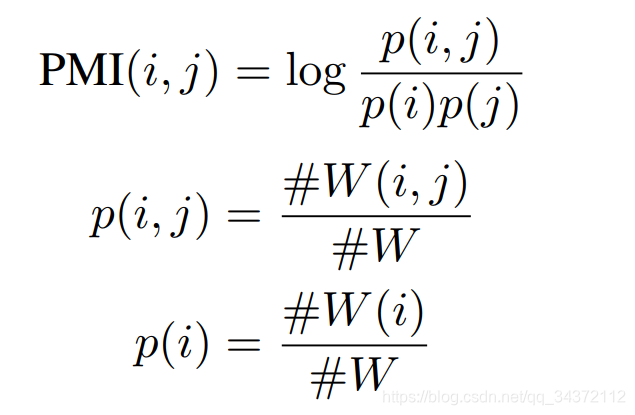
# W ( i ) \#W(i) #W(i) 是在语料集上包含 word i 的滑动窗口的个数, # W ( i , j ) \# W(i, j) #W(i,j) 是包含 word i 和 word j 的滑动窗口的个数, # W \# W #W 是整体滑动窗口的个数。具体来说,PMI 就是算单词 i 和单词 j 同时出现的概率比上单词 i 和单词 j 单独出现的概率。一个正的 PMI 值表示在语料中有高的语义相关性。
得到矩阵
A
A
A 后,剩下的就是利用 GCN 的常规操作,这里作者用了两层 GCN(作者实验表面两层效果最好):
Z
=
s
o
f
t
m
a
x
(
A
~
R
e
L
U
(
A
~
X
W
0
)
W
1
)
Z = softmax(\tilde{A}ReLU(\tilde{A}XW_0)W_1)
Z=softmax(A~ReLU(A~XW0)W1)
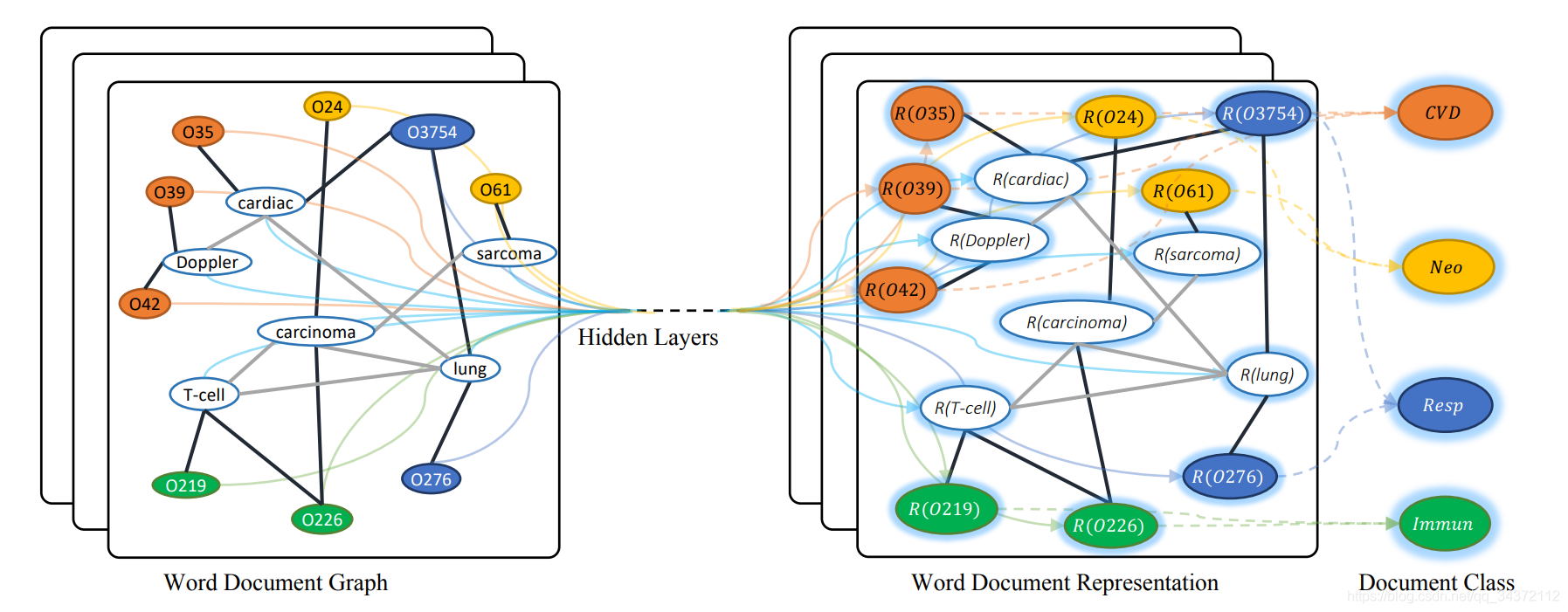
然后在每个有标记的 document 顶点上,利用交叉熵计算损失。整体如下,其中,O开头的是 document nodes,其它的是 word nodes,不同的颜色代表文档不同的类别:
Experiment
实验数据如下图:
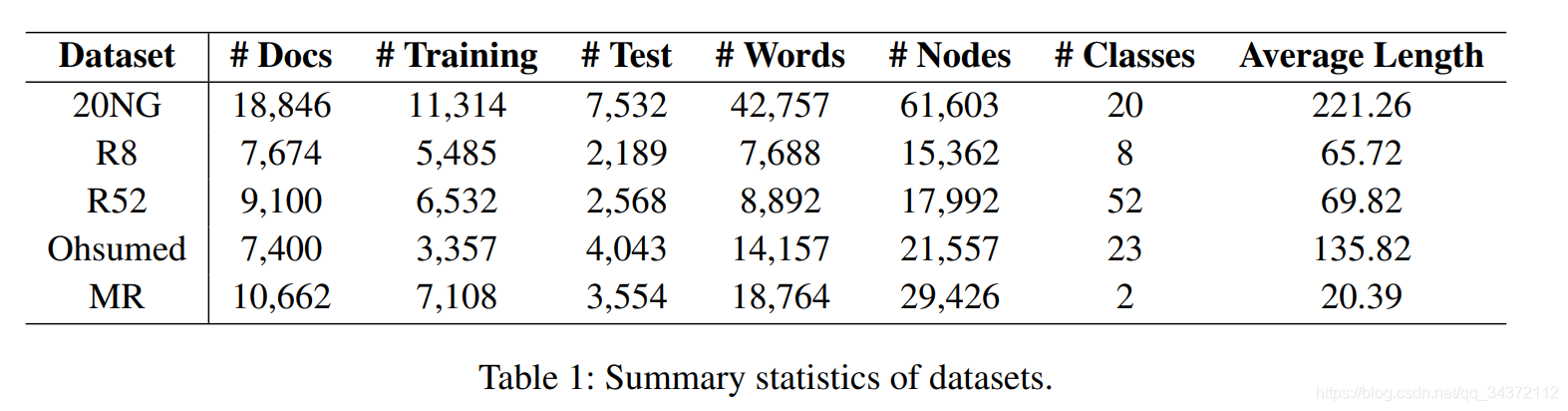
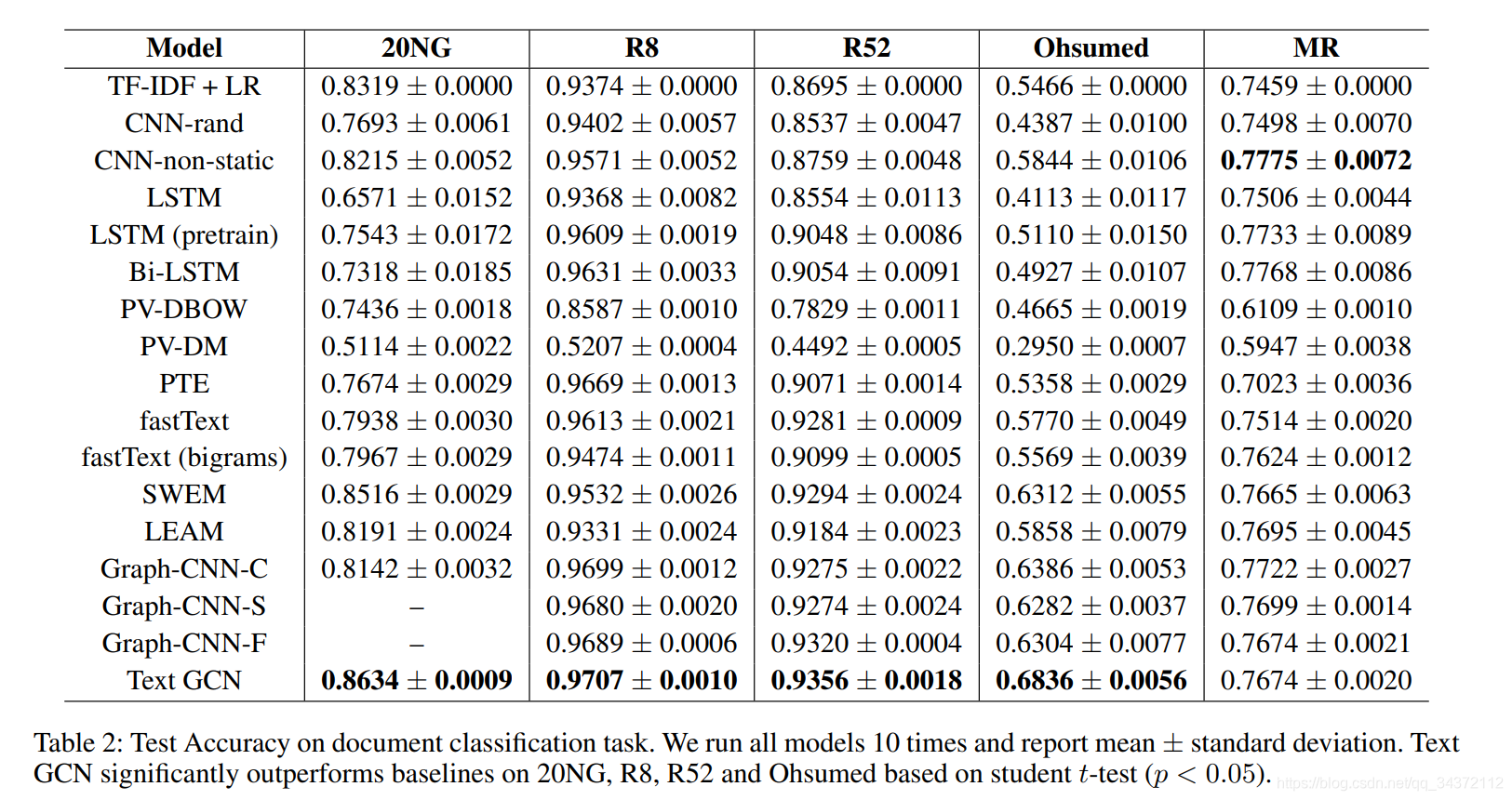
作者利用 NLTK 去除了前 4 个数据集的停用词,并去除了频次小于 5 的低频次。MR 数据集因为句子太短了,没有必要再删。实验结果如下:
另外,窗口大小、第一层 GCN 输出向量维度的大小对结果也会有影响,这里作者做了对比实验,个人感觉不重要,就不放图了。
Conclusion and Future Work
这部分没什么重点,就说提出了用 GCN 做文本分类且得到 state-of-the-art 的效果。
个人总结
- 效果提升有限,可能是调参的功能。
- 不能对新文本做预测。

















 3039
3039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









