










目录
核心思想
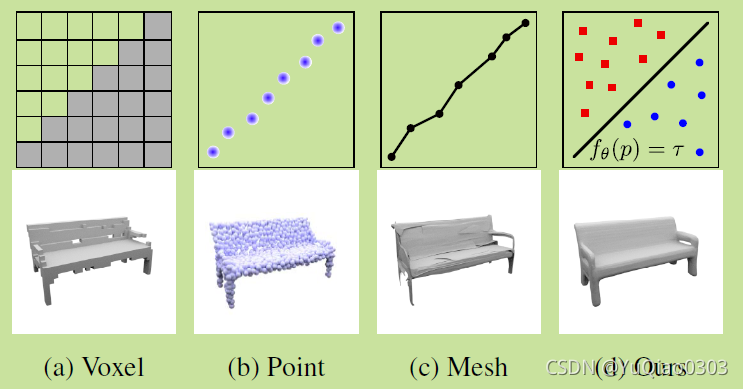
本文提出了一种3D图形的表示方法,并给出了得到他的网络架构和训练方法。
用decision boundary 来表示物体的表面。
这个方法贼好,放在2D类比,就像像素图和矢量图,矢量图是精度是无限的,但又不会耗费额外的内存。
(对啊,早该想到啊,怎么会2019年才出来。。。既然2D可以有矢量图,3D就不能吗)
具体一点,一个物体用一个occupancy function 来表示:
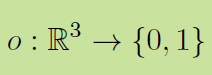
注意,是实数空间,不是离散的按一定分辨率取样的。
然后用一个神经网络来逼近这个函数,给每个实空间的3D点一个0-1之间的占用概率(因此和二分类模型等价)。神经网络f输入是一个点和一个几何体的表示(X),输出是一个0-1之间的实数,表示这个点在这个几何体里的概率。
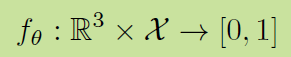
这不就完事儿了,直接拿数据训练一下呀,就是一个普通的二分类网络。
对不同输入类型的数据,用不同encoder来输入。
单个图像:ResNet
体素:3D CNN
点云:PointNet等
涉及到的底层模块
Marching box算法,生成mesh用的
Fast-Quadric-Mesh-Simplification algorithm: 简化mesh用的。似乎不是一个通用方法,而是github上一个挺好的算法。https://github.com/sp4cerat/Fast-Quadric-Mesh-Simplification
网络结构
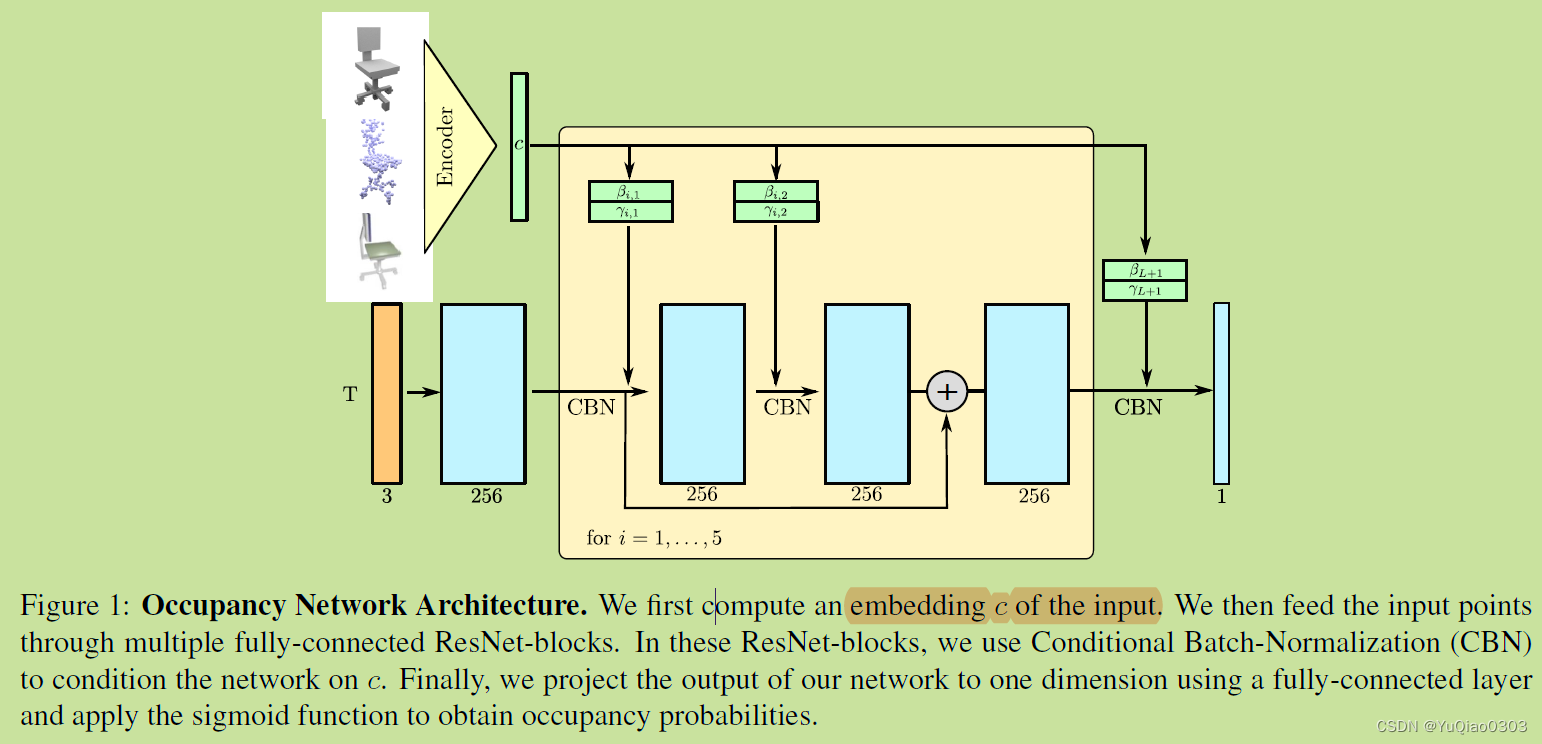
训练
需要采样进行训练。
每个minibatch采样k个点。
论文4.6比较了不同的采样方式,发现在boundingbox内均匀采样,并加一个小的padding,效果最好。
损失函数就是交叉熵函数。
mesh提取
网络训练好后,如何得到mesh呢?
论文提出 Multiresolution IsoSurface Extraction (MISE), 多分辨率表面提取算法。输入训练好的occupancy network,输出mesh。
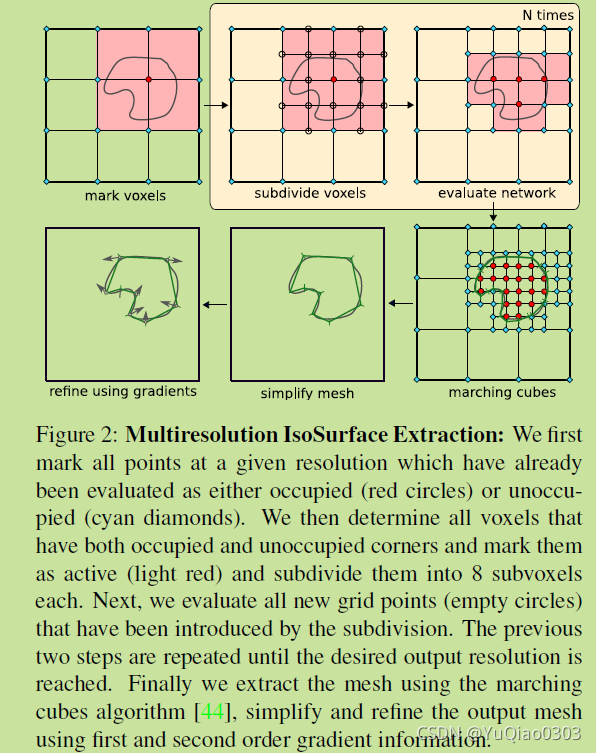
方法描述:
- 把要判断的范围按一个粗粒度的初始分辨率分成grid。每个grid有一些角点(三维的话相当于一个cube,有8个顶点)
- 所有这些角点,用训练好的网络计算出occupancy value (0-1之间的实数).
- 网络超参数 τ \tau τ,物体厚度。大于等于 τ \tau τ的为occupied,否则为un occupied. (可以认为边界点的occupancy value 为 τ \tau τ。)
- 如果一个grid,他有的角点是occupied,有的是unoccupied,那他就是active的grid,后面要继续考察。(淡红色的那些grid)
- 把所有active的grid再次细分,(对半分,最后一共八个)。重复以上步骤,直到满足目标分辨率。
- 用marching cubes 算法来得到mesh。(线性插值认为一个grid的一条边中,和等值面的交点由顶点值做线性插值计算。(等值面是occupancy value为 τ \tau τ的面)
- 用一阶和二阶梯度来优化一下得到的mesh。
marching cubes的一张图示:来自视频
这个视频6分钟,原理只在前半部分三分钟左右,一看就懂,清楚明白
(一个cube8个点,每个点可能在或不在,所以一共2^8, but thankfullly, 只有14种,其余的都是对称)

一些细节:
- 初始分辨率需要足够高。一个极端例子是grid太大,整个物体都包进去了。这样grid角点全都是not occupied, 检测出来的物体就没有mesh了。实际发现大约32^3 差不多了。
- refine的具体细节
- 第一步:用 Fast-Quadric-Mesh-Simplification algorithm 简化模型。
- 第二步:用一二阶梯度优化。
- 每个面随机采样得到点pk, minimize the loss:
- (这里没看懂)
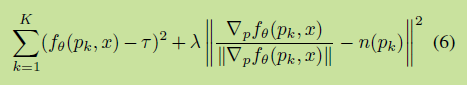
实验
概述
三方面实验
-
先检验复杂3D模型用occupancy net的表达能力。也就是将ground truth转换为occupancy net的形式。看二者的精度差别和存储空间差别。主要是和基于体素的方法对比。(废话,那肯定好啊)
-
再针对single image, noisy point clouds, low resolution voxel representations 分别实验
-
最后验证生成能力。
baseline方法:
| single image | point cloud | voxel | |
|---|---|---|---|
| voxel based | 3D-R2N2 | 3D-R2N2 | |
| point based | PointSet Generating Networks(PSGN) | PSGN | |
| mesh based | Pixel2Mesh & AtlasNet | Deep Marching Cubes (DMC) |
Dataset: ShapeNet
评价指标(Metrics):
-
IoU:模型的交并比。越高越好。(只有watertight mesh 能用)
-
Chamfer-L1 distance:越小越好。(全部可用)
accuracy和completeness的平均。
accuracy是预测mesh上的点到groud truth上的点最近的距离。(两者各随机采样100k个点,取均值)
completeness是 反过来,ground truth上面的点,到最近的output mesh上的点的距离。
用KD tree求距离。 -
normal consistency score:还没看懂 (点云不可用)
(一个mesh的法线) 和 (另一个mesh中,他的最近邻居的发现)的绝对点集。(取均值)
具体实验
表达能力实验
给定ground truth的mesh,训练occupancy network。
同时也用体素表达这个ground truth。
对比体素法和ONet的 IoU 和 参数大小。
定量分析:ONet精度更高,参数更少
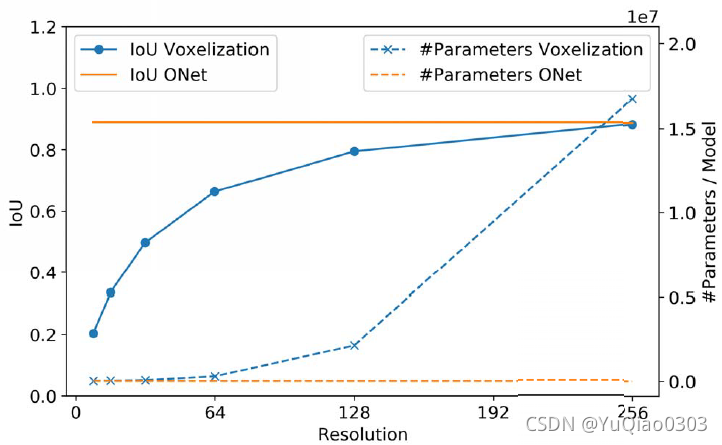
平均IoU约为0.89,与精度关系不大。
定性分析:肉眼可见的细致平滑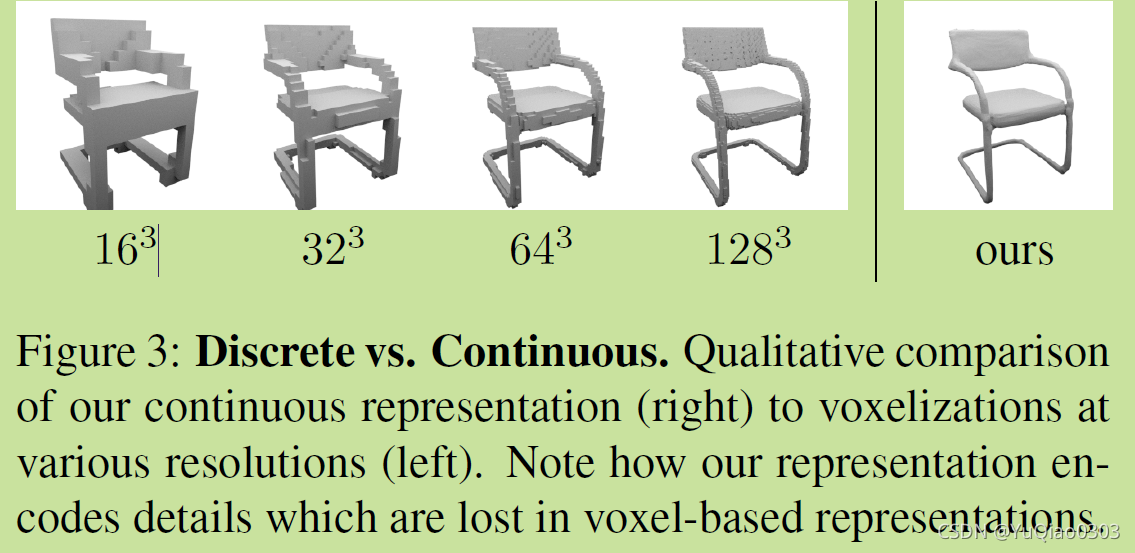
单个图像3D重建实验:
定量分析:ShapeNet数据集
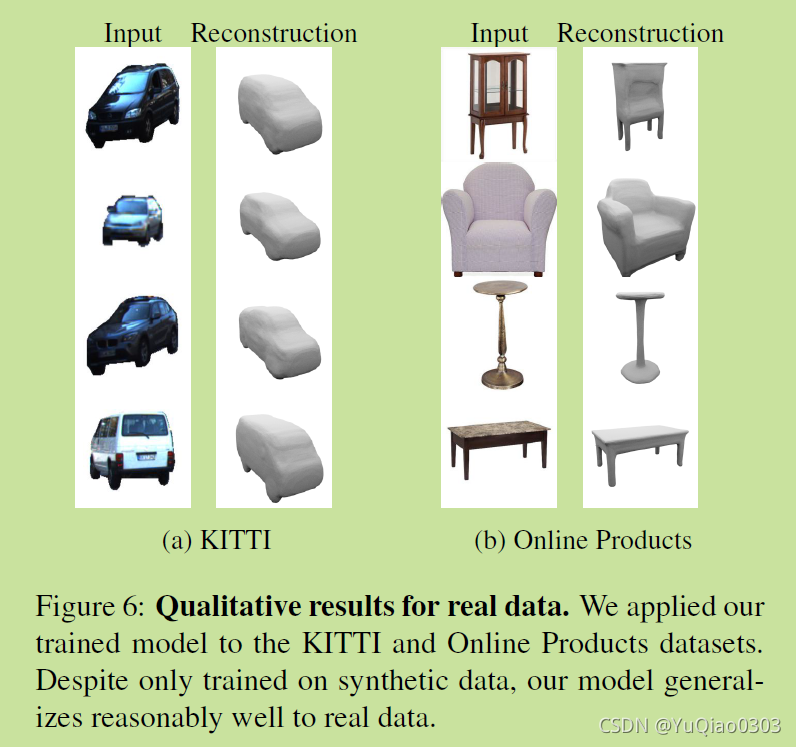
定性分析:KITTI 和 OnlineProducts dataset
ShapeNet:

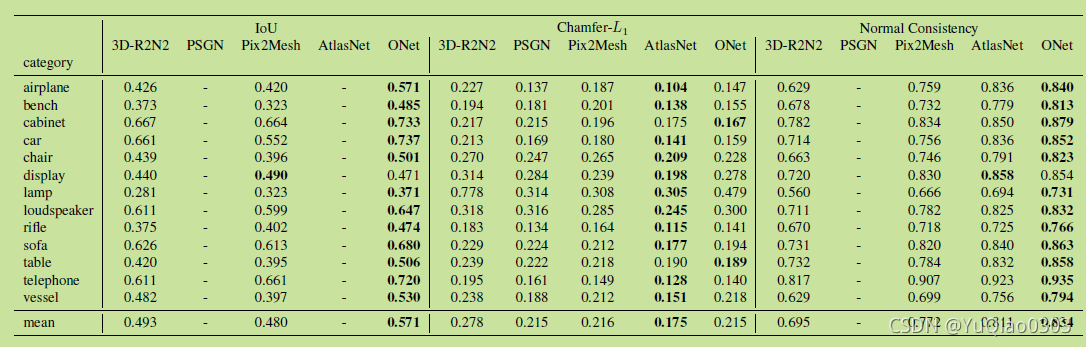
有趣的是,在Chamfer-L1指标上,其实是AtlasNet最好。
说是PSGN,Pixel2Mesh , AtlasNet都在这个指标上训练了;Onet没有,但也不错。
real data
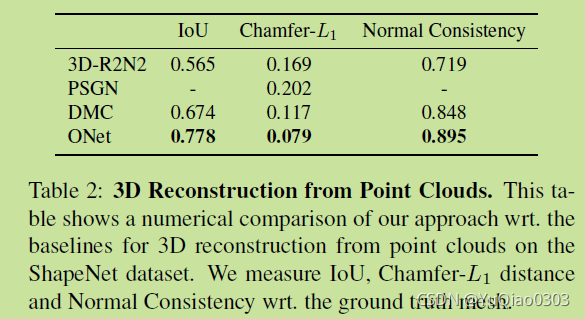
点云补全实验:
ShapeNet里面的几何体,采样300个点,再用高斯加噪声。
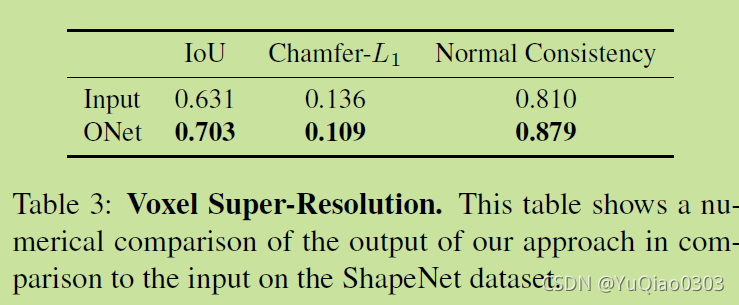
体素重建实验
把体素super resolution:分辨率提到贼高。
输入体素,输出mesh。
无条件mesh生成
有点没看懂,好像是不给定输入,(可能是随机feature作为输入),生成新模型。
能确定的是unsupervised。
但不知道类别是怎么给定的。

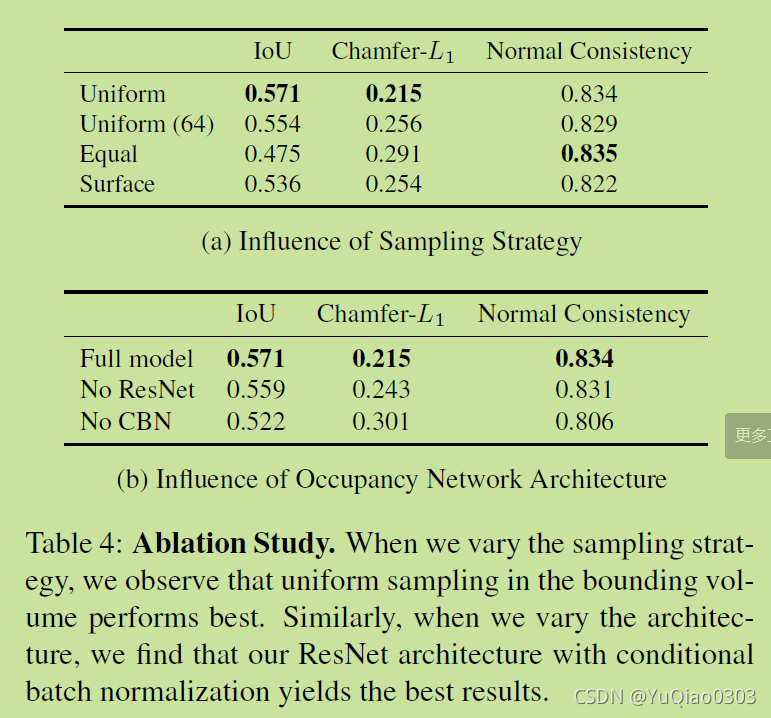
消融实验(Ablation Study)
采样方法中发现均匀采样最好。
模型架构上发现ResNet和CBN(conditional batch normalization )都很有用。
代码运行配环境个人笔记
注释掉CMakeList里面的compute_30
可能需要安装glew和 另一个啥
apt-get install parallel

















 6611
6611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









