







 本文探讨了SQL中的GROUP BY语句、HAVING子句的应用,以及视图的作用,涵盖了索引优化、聚集索引与非聚集索引的区别,以及事务的隔离级别。通过实例讲解了如何利用这些技术管理数据库并提升查询效率。
本文探讨了SQL中的GROUP BY语句、HAVING子句的应用,以及视图的作用,涵盖了索引优化、聚集索引与非聚集索引的区别,以及事务的隔离级别。通过实例讲解了如何利用这些技术管理数据库并提升查询效率。
GROUP BY 语句可结合一些聚合函数来使用(用于将每行数据根据某个字段进行分组)
如:统计 access_log 各个 site_id 的访问量:
SELECT site_id, SUM(access_log.count) AS nums
FROM access_log GROUP BY site_id;HAVING 子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
如:查找总访问量大于 200 的网站。
SELECT Websites.name, Websites.url, SUM(access_log.count) AS nums FROM (access_log
INNER JOIN Websites
ON access_log.site_id=Websites.id)
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;view(视图)的作用:
1、视图隐藏了底层的表结构,简化了数据访问操作,客户端不再需要知道底层表的结构及其之间的关系。
2、视图提供了一个统一访问数据的接口。(即可以允许用户通过视图访问数据的安全机制,而不授予用户直接访问底层表的权限)
3、从而加强了安全性,使用户只能看到视图所显示的数据。
4、视图还可以被嵌套,一个视图中可以嵌套另一个视图
(“对视图数据的操作最终会操作原表”)
index索引的作用
https://www.runoob.com/mysql/mysql-index.html
提高mysql的检索速度
索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,建立索引会占用磁盘空间的索引文件。
CREATE INDEX indexName ON table_name (column_name)聚集索引和非聚集索引的区别:

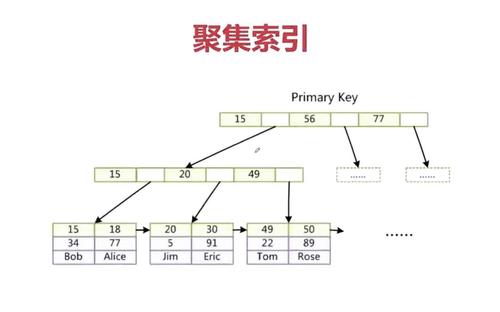
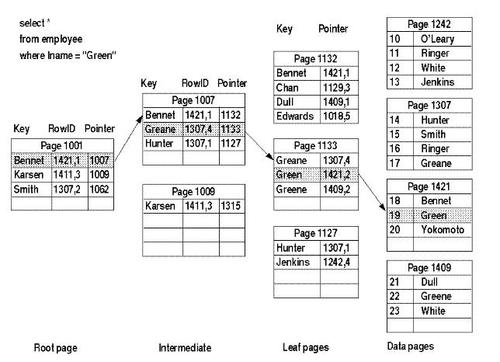
- 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个
- 聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续
- 聚集索引:物理存储按照索引排序;聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序
- 非聚集索引:物理存储不按照索引排序;非聚集索引则就是普通索引了,仅仅只是对数据列创建相应的索引,不影响整个表的物理存储顺序.
- 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
事务的隔离级别


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









