







 本文介绍了几种图像超分辨率网络。ESPCN提出直接在低分辨率图像上提取特征得到高分辨率图像的高效方法,核心是亚像素卷积层;VDSR应用残差网络结构,学习高低分辨率图像间的高频残差,有加深网络、残差学习等贡献;DRCN首次将递归神经网络用于超分辨率处理,利用残差学习加深网络。
本文介绍了几种图像超分辨率网络。ESPCN提出直接在低分辨率图像上提取特征得到高分辨率图像的高效方法,核心是亚像素卷积层;VDSR应用残差网络结构,学习高低分辨率图像间的高频残差,有加深网络、残差学习等贡献;DRCN首次将递归神经网络用于超分辨率处理,利用残差学习加深网络。
ESPCN
(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network, CVPR2016)
作者在本文中介绍到,像SRCNN那样的方法,由于需要将低分辨率图像通过上采样插值得到与高分辨率图像相同大小的尺寸,再输入到网络中,这意味着要在较高的分辨率上进行卷积操作,从而增加了计算复杂度。本文提出了一种直接在低分辨率图像尺寸上提取特征,计算得到高分辨率图像的高效方法。ESPCN网络结构如下图所示。
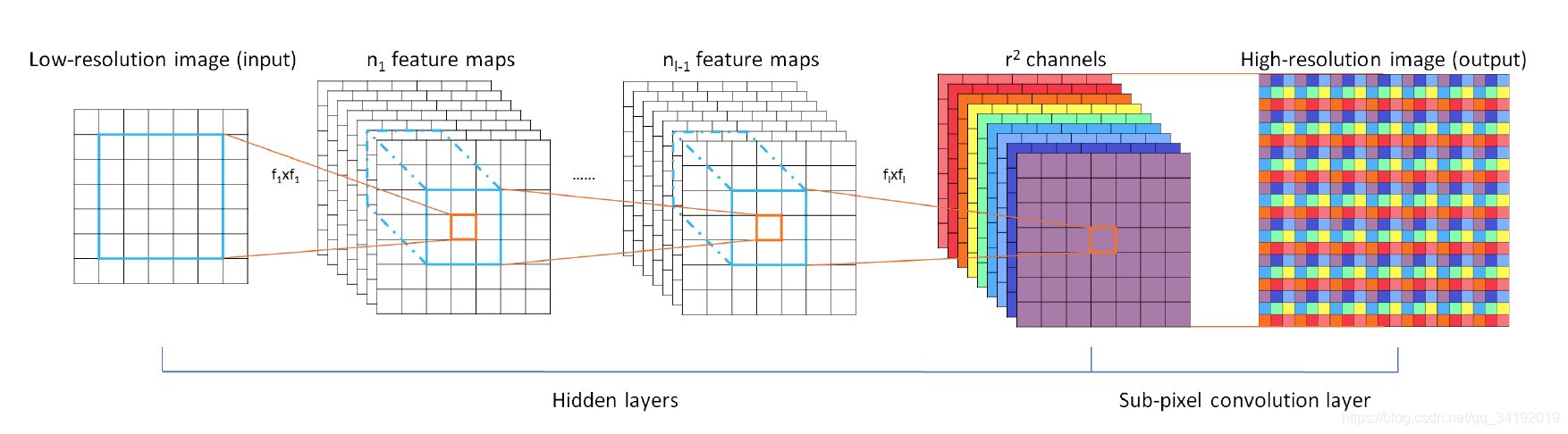
ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。网络的输入是原始低分辨率图像,通过三个卷积层以后,得到通道数为 的与输入图像大小一样的特征图像。再将特征图像每个像素的 个通道重新排列成一个 的区域,对应高分辨率图像中一个 大小的子块,从而大小为 的特征图像被重新排列成 的高分辨率图像。我理解的亚像素卷积层包含两个过程,一个普通的卷积层和后面的排列像素的步骤。就是说,最后一层卷积层输出的特征个数需要设置成固定值,即放大倍数r的平方,这样总的像素个数就与要得到的高分辨率图像一致,将像素进行重新排列就能得到高分辨率图。
在ESPCN网络中,图像尺寸放大过程的插值函数被隐含地包含在前面的卷积层中,可以自动学习到。由于卷积运算都是在低分辨率图像尺寸大小上进行,因此效率会较高。
训练时,可以将输入的训练数据,预处理成重新排列操作前的格式,比如将21×21的单通道图,预处理成9个通道,7×7的图,这样在训练时,就不需要做重新排列的操作。另外,ESPCN激活函数采用tanh替代了ReLU。损失函数为均方误差。
github(tensorflow): https://github.com/drakelevy/ESPCN-TensorFlowhttps://
github(pytorch): https://github.com/leftthomas/ESPCNhttps://
github(caffe): https://github.com/wangxuewen99/Super-Resolution/tree/master/ESPCN
VDSR
(Accurate Image Super-Resolution Using Very Deep Convolutional Networks, CVPR2016)
在介绍VDSR之前,首先想先提一下何恺明在2015年的时候提出的残差网络ResNet。ResNet的提出,解决了之前网络结构比较深时无法训练的问题,性能也得到了提升,ResNet也获得了CVPR2016的best paper。残差网络结构(residual network)被应用在了大量的工作中。
正如在VDSR论文中作者提到,输入的低分辨率图像和输出的高分辨率图像在很大程度上是相似的,也就是指低分辨率图像携带的低频信息与高分辨率图像的低频信息相近,训练时带上这部分会多花费大量的时间,实际上我们只需要学习高分辨率图像和低分辨率图像之间的高频部分残差即可。残差网络结构的思想特别适合用来解决超分辨率问题,可以说影响了之后的深度学习超分辨率方法。VDSR是最直接明显的学习残差的结构,其网络结构如下图所示。
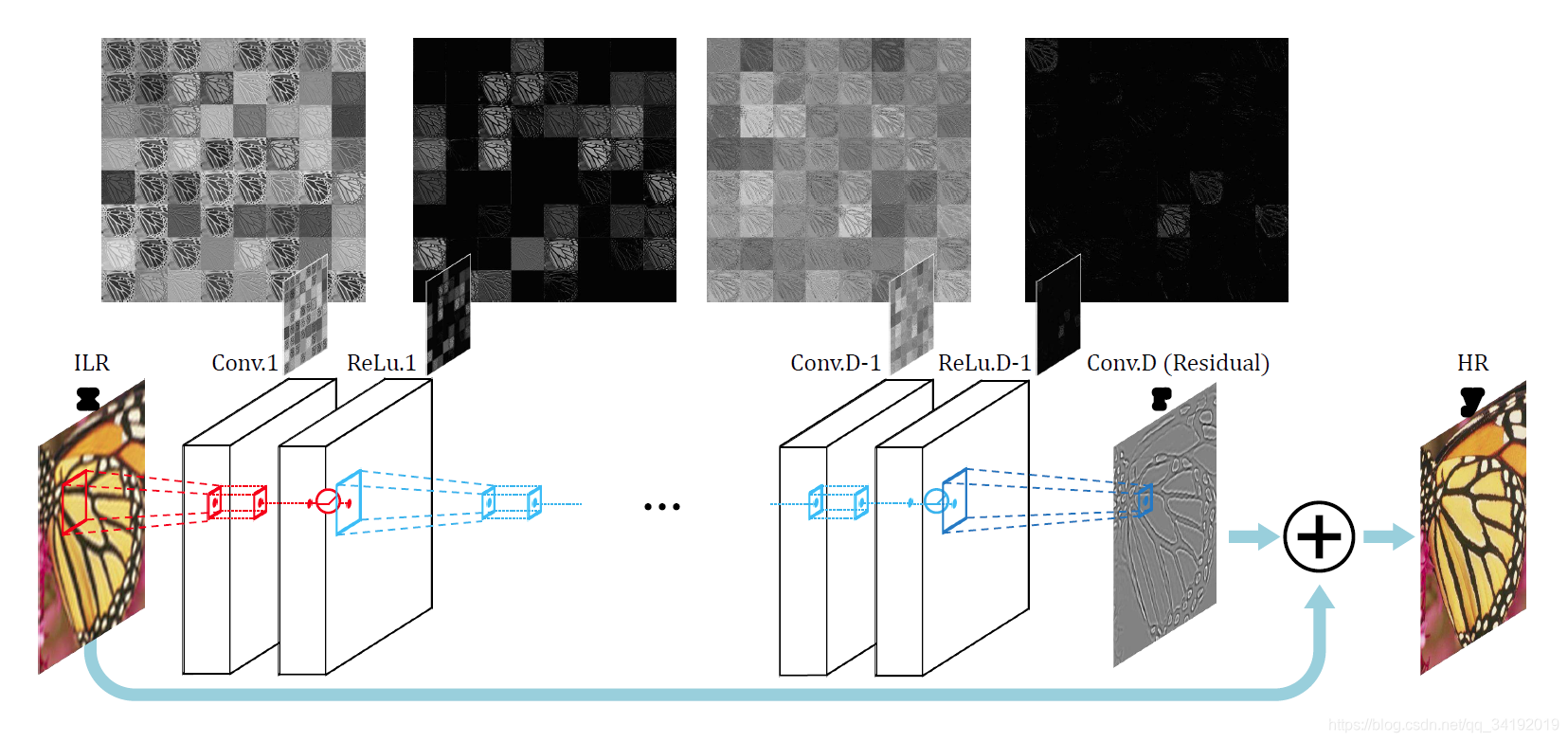
VDSR将插值后得到的变成目标尺寸的低分辨率图像作为网络的输入,再将这个图像与网络学到的残差相加得到最终的网络的输出。VDSR主要有4点贡献。1.加深了网络结构(20层),使得越深的网络层拥有更大的感受野。文章选取3×3的卷积核,深度为D的网络拥有(2D+1)×(2D+1)的感受野。2.采用残差学习,残差图像比较稀疏,大部分值都为0或者比较小,因此收敛速度快。VDSR还应用了自适应梯度裁剪(Adjustable Gradient Clipping),将梯度限制在某一范围,也能够加快收敛过程。3.VDSR在每次卷积前都对图像进行补0操作,这样保证了所有的特征图和最终的输出图像在尺寸上都保持一致,解决了图像通过逐步卷积会越来越小的问题。文中说实验证明补0操作对边界像素的预测结果也能够得到提升。4.VDSR将不同倍数的图像混合在一起训练,这样训练出来的一个模型就可以解决不同倍数的超分辨率问题。
code: https://cv.snu.ac.kr/research/VDSR/
github(caffe): https://github.com/huangzehao/caffe-vdsrhttps://
github(tensorflow): https://github.com/Jongchan/tensorflow-vdsrhttps://
github(pytorch): https://github.com/twtygqyy/pytorch-vdsrhttps://
DRCN
(Deeply-Recursive Convolutional Network for Image Super-Resolution, CVPR2016)
DRCN与上面的VDSR都是来自首尔国立大学计算机视觉实验室的工作,两篇论文都发表在CVPR2016上,两种方法的结果非常接近。DRCN第一次将之前已有的递归神经网络(Recursive Neural Network)结构应用在超分辨率处理中。同时,利用残差学习的思想(文中的跳跃连接(Skip-Connection)),加深了网络结构(16个递归),增加了网络感受野,提升了性能。DRCN网络结构如下图所示。
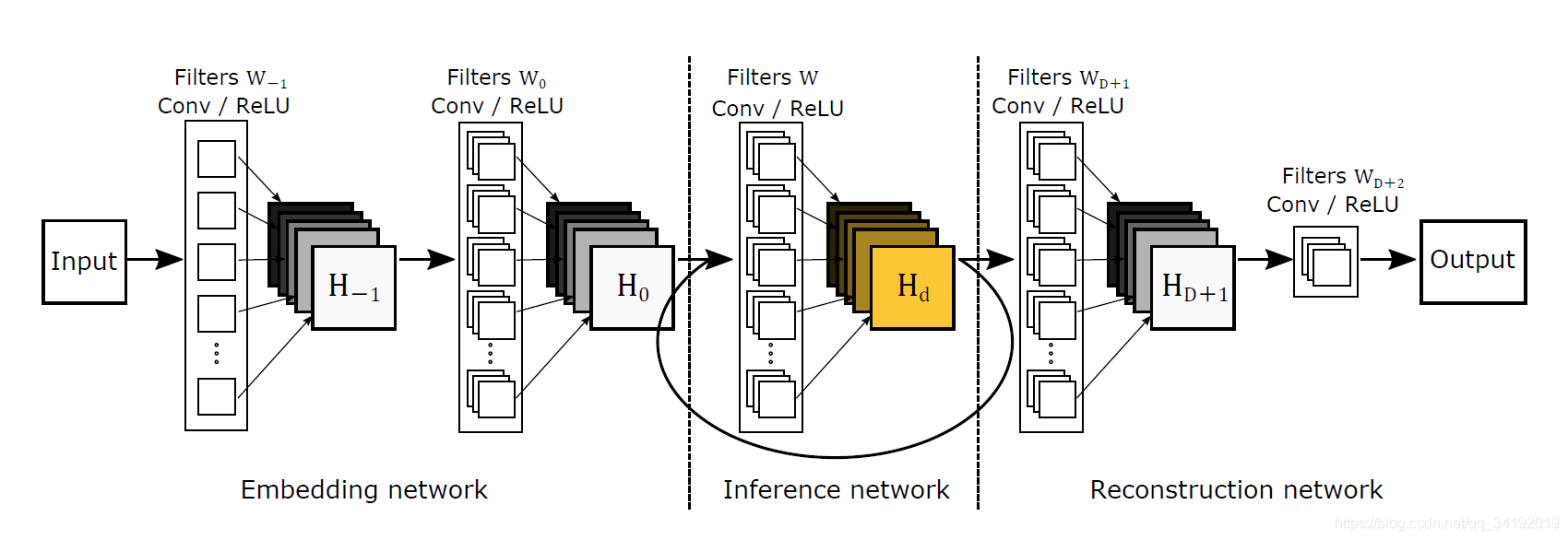
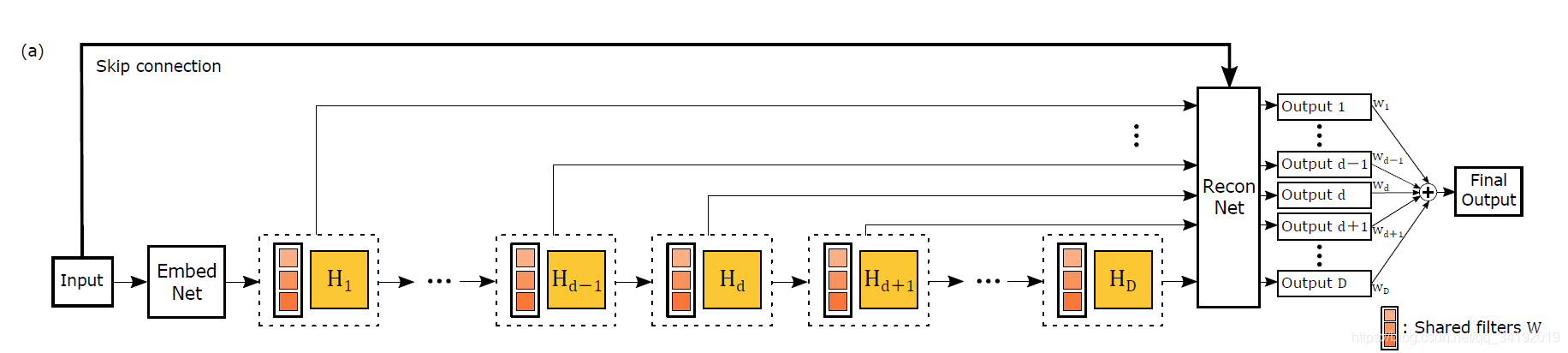
DRCN输入的是插值后的图像,分为三个模块,第一个是Embedding network,相当于特征提取,第二个是Inference network, 相当于特征的非线性映射,第三个是Reconstruction network,即从特征图像恢复最后的重建结果。其中的Inference network是一个递归网络,即数据循环地通过该层多次。将这个循环进行展开,等效于使用同一组参数的多个串联的卷积层,如下图所示。

RED
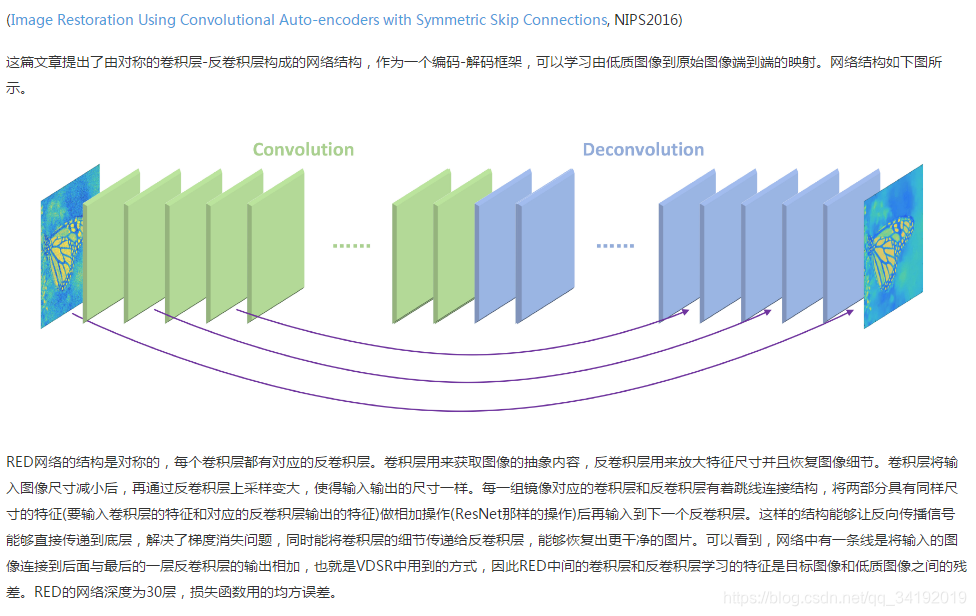
DRRN
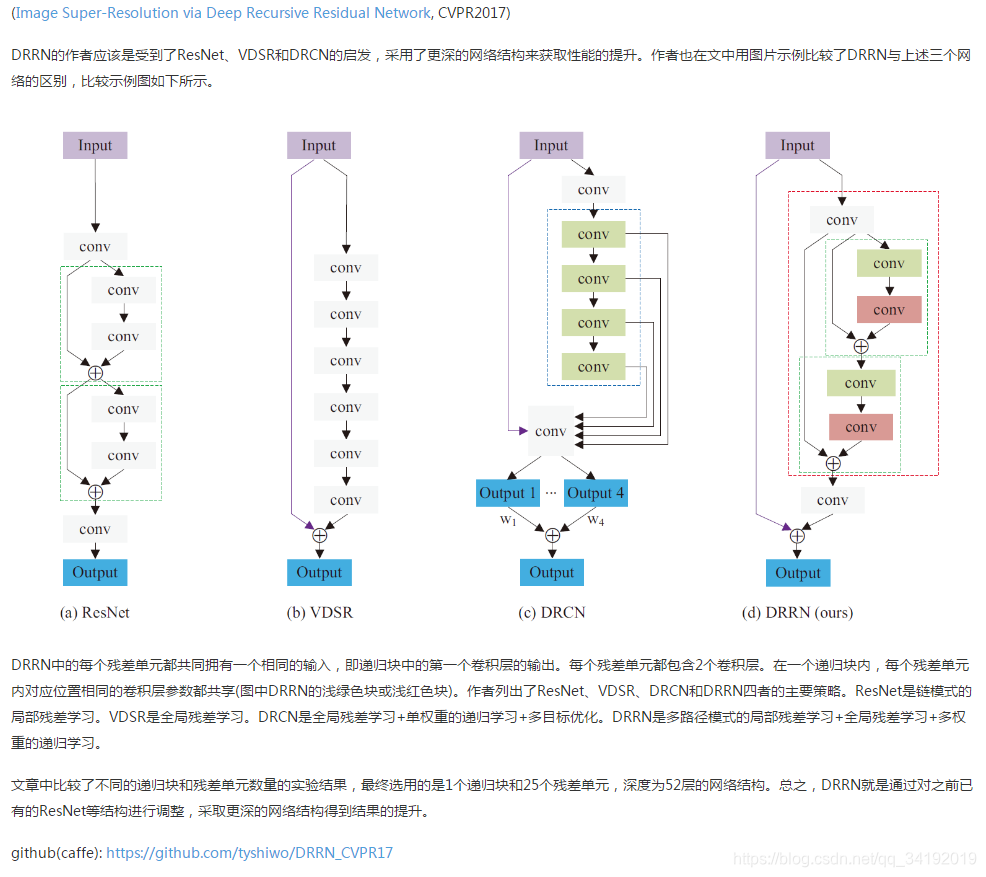
LapSRN
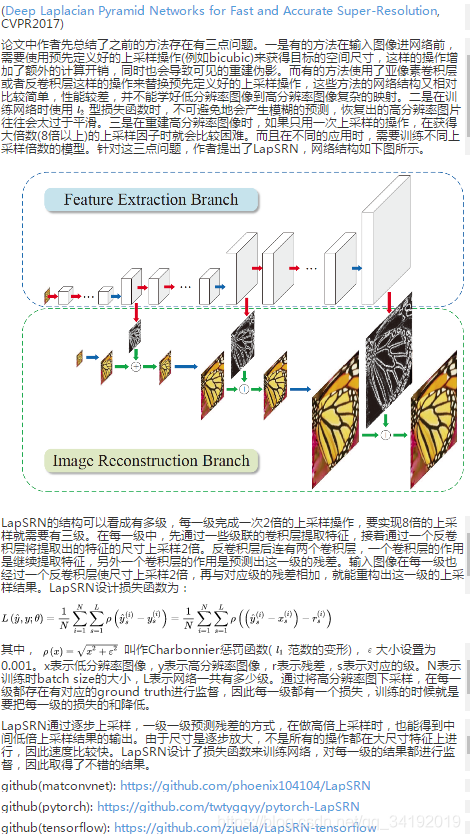
原文https://blog.youkuaiyun.com/aBlueMouse/article/details/78710553

















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









