






 本文深入解析了Elasticsearch中的聚合查询功能,包括terms聚合用于统计各分组出现频率,及cardinality聚合实现去重计数,如统计不同班级数量。通过具体示例,帮助读者理解并掌握ES查询技巧。
本文深入解析了Elasticsearch中的聚合查询功能,包括terms聚合用于统计各分组出现频率,及cardinality聚合实现去重计数,如统计不同班级数量。通过具体示例,帮助读者理解并掌握ES查询技巧。
terms:聚合分组,类似于sql中group by,结果为每个单位出现的次数,需要给定size值,不然默认最大为10
"aggs": {
"classid": {
"terms": {
"field": "classid",
"size": 10
}
}
}
查询结果:
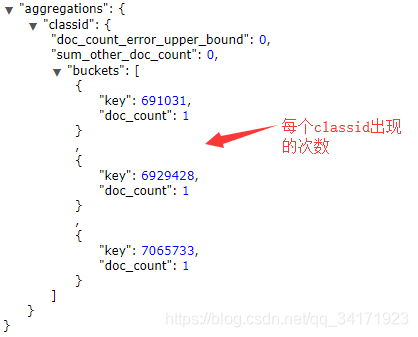
cardinality: 去重,类似于sql中distinct ,结果为单位数量,
如查询共有多少个班级:
"aggs": {
"classid": {
"cardinality": {
"field": "classid"
}
}
}
查询结果:
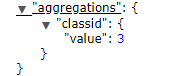

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









