










 优先队列是一种数据结构,用于高效地处理具有优先级的数据。通过二叉堆实现,常见操作包括向上筛选和向下筛选,常用于解决在大量数据中找出前k大或小的数的问题,复杂度为O(k+nlogk),优于排序方法。初始化一个大小为n的堆的时间复杂度为O(n)。
优先队列是一种数据结构,用于高效地处理具有优先级的数据。通过二叉堆实现,常见操作包括向上筛选和向下筛选,常用于解决在大量数据中找出前k大或小的数的问题,复杂度为O(k+nlogk),优于排序方法。初始化一个大小为n的堆的时间复杂度为O(n)。
优先队列(Priority Queue)
特点
- 能保证每次取出的元素都是队列中优先级别最高的。
- 优先级别可以是自定义的,例如,数据的数值越大,优先级越高;或者数据的数值越小,优先级越高。优先级别甚至可以通过各种复杂的计算得到。
应用场景
- 从一堆杂乱无章的数据当中按照一定的顺序(或者优先级)逐步地筛选出部分乃至全部的数据。
举例:任意一个数组,找出前 k 大的数。
解法 1:先对这个数组进行排序,然后依次输出前 k 大的数,复杂度将会是 O(nlogn),其中,n 是数组的元素个数。这是一种直接的办法。
解法 2:使用优先队列,复杂度优化成 O(k + nlogk)。
- 当数据量很大(即 n 很大),而 k 相对较小的时候,显然,利用优先队列能有效地降低算法复杂度。因为要找出前 k 大的数,并不需要对所有的数进行排序。
实现
优先队列的本质是一个二叉堆结构。堆在英文里叫 Binary Heap,它是利用一个数组结构来实现的完全二叉树。 换句话说,优先队列的本质是一个数组,数组里的每个元素既有可能是其他元素的父节点,也有可能是其他元素的子节点,而且,每个父节点只能有两个子节点,很像一棵二叉树的结构。
牢记下面优先队列有三个重要的性质。
- 数组里的第一个元素 array[0] 拥有最高的优先级别。
- 给定一个下标 i,那么对于元素 array[i] 而言:
- 它的父节点所对应的元素下标是 (i-1)/2
- 它的左孩子所对应的元素下标是 2×i + 1
- 它的右孩子所对应的元素下标是 2×i + 2
- 数组里每个元素的优先级别都要高于它两个孩子的优先级别。
优先队列最基本的操作有两个。
1. 向上筛选(sift up / bubble up)
- 当有新的数据加入到优先队列中,新的数据首先被放置在二叉堆的底部。
- 不断进行向上筛选的操作,即如果发现该数据的优先级别比父节点的优先级别还要高,那么就和父节点的元素相互交换,再接着往上进行比较,直到无法再继续交换为止。
- 时间复杂度:由于二叉堆是一棵完全二叉树,并假设堆的大小为 k,因此整个过程其实就是沿着树的高度往上爬,所以只需要 O(logk) 的时间。
2. 向下筛选(sift down / bubble down)
- 当堆顶的元素被取出时,要更新堆顶的元素来作为下一次按照优先级顺序被取出的对象,需要将堆底部的元素放置到堆顶,然后不断地对它执行向下筛选的操作。
- 将该元素和它的两个孩子节点对比优先级,如果优先级最高的是其中一个孩子,就将该元素和那个孩子进行交换,然后反复进行下去,直到无法继续交换为止。
- 时间复杂度:整个过程就是沿着树的高度往下爬,所以时间复杂度也是 O(logk)。因此,无论是添加新的数据还是取出堆顶的元素,都需要 O(logk) 的时间。
初始化
- 优先队列的初始化是一个最重要的时间复杂度,是分析运用优先队列性能时必不可少的,也是经常容易弄错的地方。
举例:有 n 个数据,需要创建一个大小为 n 的堆。
误区:每当把一个数据加入到堆里,都要对其执行向上筛选的操作,这样一来就是 O(nlogn)。
解法:在创建这个堆的过程中,二叉树的大小是从 1 逐渐增长到 n 的,所以整个算法的复杂度经过推导,最终的结果是 O(n)。
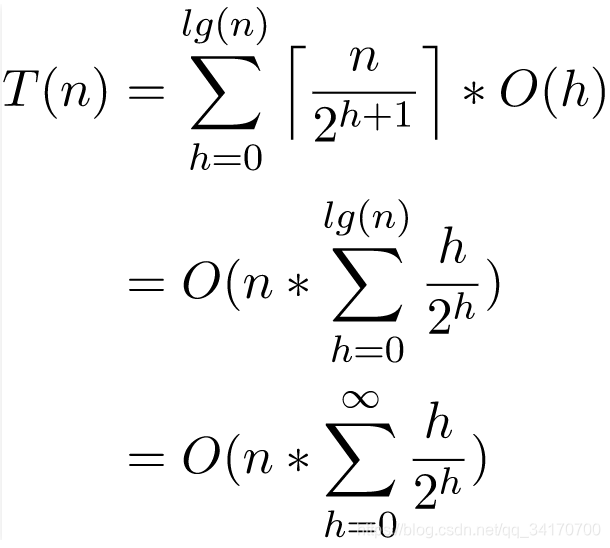
- 注意:算法面试中是不要求推导的,你只需要记住,初始化一个大小为 n 的堆,所需要的时间是 O(n) 即可


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









