







 本文解决Hadoop本地运行时出现的文件未找到错误。通过更改配置文件core-site.xml并设置临时文件存储目录,成功解决了因主机名包含空格导致的问题。
本文解决Hadoop本地运行时出现的文件未找到错误。通过更改配置文件core-site.xml并设置临时文件存储目录,成功解决了因主机名包含空格导致的问题。
完美解决hadoop本地运行时出现:
Caused by: java.io.FileNotFoundException: D:/tmp/hadoop-win%2010/mapred/local/localRunner/root/jobcache/job_local384849921_0001/attempt_local384849921_0001_m_000000_0/output/file.out.index
意思是临时文件没找到,手动进入电脑目录下,目录确实为空,根本没有文件,猜想就是临时文件夹建立出现问题,
出现这个问题,网上说是电脑的名字有空格导致,但是修改了,运行程序还是这个问题,而且建立的文件夹还是用的之前的主机名
解决思路:参考在linux虚拟机上运行的hadoop的core-site.xml的配置文件,hadoop运行时需要指定临时的文件存储目录:
因此在代码中加入:
Configuration conf = new Configuration();
conf.set("hadoop.tmp.dir", "E:/hdfs_tmp_cache"); //指定hadoop运行时在本地的临时工作目录
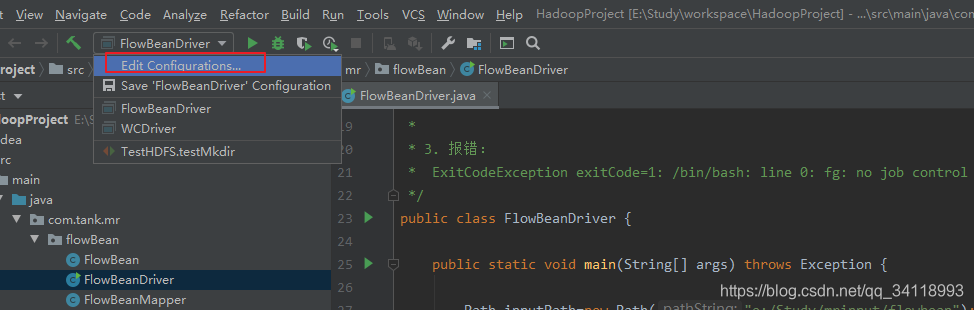
然后在Run configurations 的jvm参数里设置:-DHADOOP_USER_NAME=root 这个root可以随便取名
以下是idea操作
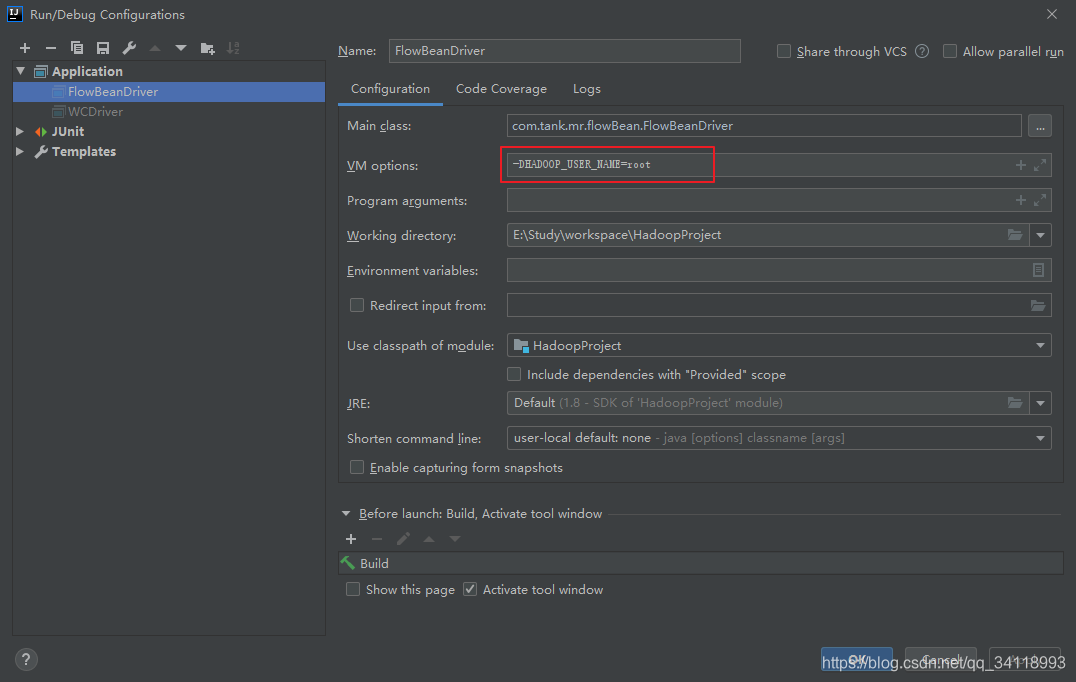
可以手动建一下临时文件:
E:\hdfs_tmp_cache\mapred\local\localRunner\root 这里的root就是这个设置的用户名

















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









