






 本文介绍如何利用Python的BeautifulSoup库从指定网站抓取文章标题和内容,包括清洗数据和保存至本地文件的过程。
本文介绍如何利用Python的BeautifulSoup库从指定网站抓取文章标题和内容,包括清洗数据和保存至本地文件的过程。
本文使用了beautifulSoup
帮助文档 URL:http://beautifulsoup.readthedocs.io/zh_CN/latest/
是中文版的,不懂的可以查。
目标网站:http://www.acfun.cn/a/ac4875397

首先F12查看页面代码,找到其中的关键标签。



requests 库:用来发送各种请求
初始代码:
import requests
from bs4 import BeautifulSoup
res=requests.get('http://www.acfun.cn/a/ac4875397') #请求页面
#这里是get请求,还有post请求,用于提交表单数据
AcObj=BeautifulSoup(res.content,'lxml') #将网页源码构转化为BeautifulSoup对象
title = AcObj.find_all('div','caption')#提取爽文title
a_list=AcObj.find_all('div','article-content') #提取爽文内容
print(title)
print(a_list)
爬取结果
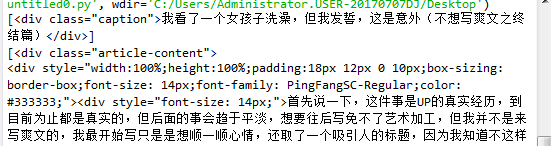
可以看到,内容中又大量的杂质。
注意,爬取出来的内容是储存在列表中的。
可以将列表再次转化为beautifulSoup对象,使用text方法,清除多余的标签。
title_Obj=BeautifulSoup(str(title), 'lxml')
bsObj=BeautifulSoup(str(a_list), 'lxml')
print(title_Obj.text)
print(bsObj.text)
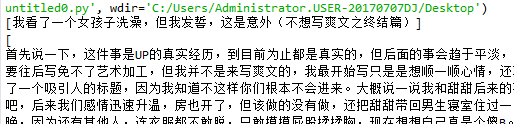
最后,将爬取到的内容写入txt文件中
首先创建名为 happy的文件夹,再在文件夹中创建txt文件
import os
path='e:\\happy\\'
folder = os.path.exists(path)
if not folder: #判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(path) #makedirs 创建文件时如果路径不存在会创建这个路径
print('creating...')
print('OK...')
else:
print('文件夹已经存在')
name='123'
full_path = path + name + '.txt'
file = open(full_path,'w')
最后的代码:
import requests
from bs4 import BeautifulSoup
import os
res=requests.get('http://www.acfun.cn/a/ac4875397') #请求页面
#这里是get请求,还有post请求,用于提交表单数据
AcObj=BeautifulSoup(res.content,'lxml') #将网页源码构转化为BeautifulSoup对象
title = AcObj.find_all('div','caption')#提取爽文title
a_list=AcObj.find_all('div','article-content') #提取爽文内容
#打印
title_Obj=BeautifulSoup(str(title), 'lxml')
bsObj=BeautifulSoup(str(a_list), 'lxml')
print(title_Obj.text)
print(bsObj.text)
path='e:\\happy\\'
folder = os.path.exists(path)
if not folder: #判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(path) #makedirs 创建文件时如果路径不存在会创建这个路径
print('creating...')
print('OK...')
else:
print('文件夹已经存在')
full_path = path + str(title_Obj.text) + '.txt'
file = open(full_path,'w')
file.write(str(bsObj.text))
file.close()

这只是爬取了一篇文章,但我们的目标是
所有的爽文!!!!

















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









