







链表、队列、映射、二叉树
1. 链表
是Linux中最简单最普通的数据结构。
存放和操作可变数量元素的数据结构。
Linu内核标准链表采用灵活性很高的环形双向链表。
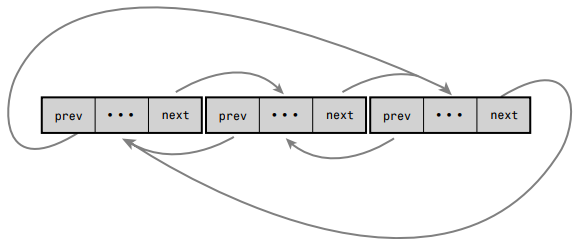
Linux内核中的链表 比较特殊
Linux内核中的链表实现与众不同,
它不是把数据结构塞入链表,
而是将链表节点塞入数据结构( embed a linked list node in the structure!)。
1. 将数据结构放入节点:
/* list_element是一个节点 */
struct list_element {
unsigned long tail_length; /* data1 */
unsigned long weight; /* data2 */
bool is_fantastic; /* data3 */
struct list_element *next;
struct list_element *prev;
};
2. 将节点放入数据结构:
/* list_head是一个节点 */
struct list_head {
struct list_head *next
struct list_head *prev;
}
struct fox {
unsigned long tail_length; /* data1 */
unsigned long weight; /* data2 */
bool is_fantastic; /* data3 */
struct list_head list; /* 将list_head节点放入fox数据结构 */
};
为什么这么做,我的理解是:
- 使得此链表的节点可以嵌入到多种类型的结构体,也就是说该类型的链表可以存放多种类型数据;
- 内核已经提供了创建、管理、操作链表的各种例程,根本无需关心所嵌入的数据结构是什么;
- 单纯的两个指针并不占用多大空间,内核中有的数据较大,如果将数据嵌到节点那么可能造成浪费,尤其是嵌入式领域。
list_entry、container_of和offsetof宏
list_entry()
container_of()
offsetof()
问题来了,这样的链表索引出的结果仅仅是某个节点的member list,那怎么得到节点的数据呢,其实只需要获得该节点的起始地址就行了。通过成员的指针怎么得到节点的起始地址呢?,需要使用linux提供的宏container_of。
offsetof是用来判断结构体中成员的偏移位置,container_of宏用来根据成员的地址来获取结构体的地址。
container_of宏需要三个参数:
ptr表示成员member所在的位置,
type结构体类型,
member结构体的一个成员的名称。
// offsetof,求取结构体类型为type的结构中member成员的偏移量
#define offsetof(type, member) (size_t)&(((type*)0)->member)
// container_of, 根据 结构体成员指针、结构体类型、成员名称 获取节点的起始地址
#define container_of(ptr, type, member) ({
const typeof( ((type*)0)->member ) *__mptr = (ptr);
(type *)( (char *)__mptr - offsetof(type, member) ); // (char *)(ptr)使得指针的加减操作步长为一字节
})
一个例子解释offsetof和container_of宏
#include <stdio.h>
#include <stddef.h>
// Linux中的链表
struct list_head{
struct list_head *next;
struct list_head *prev;
};
// 一个自定义数据结构,然后将节点放入本数据结构
struct AAA{
char i;
long j;
struct list_head list;
};
// &( (type *)0)->member ) 直接获取member的相对位置
#define offset_of_member(type, member) (size_t)&( ((type *)0)->member )
// 根据 结构体成员指针、结构体类型、成员名称 获取节点的起始地址(简化容易理解)
// (char *)(ptr)使得指针的加减操作步长为一字节
#define container_of(ptr, type, member) ({ \
(type *)( (char *)ptr - offset_of_member(type, member) ); \
})
// // 实际实现如下
// #define container_of(ptr, type, member) ({ \
// const typeof( ((type *)0)->member ) *__mptr = (ptr); \
// (type *)( (char *)ptr - offset_of_member(type, member) ); \
// })
int main()
{
// 定义AAA型结构体变量aaa并初始化,aaa也是一个节点
struct AAA aaa = {
.i = 127,
.j = 123456789,
.list.next = aaa.list.prev = NULL,
};
printf("\naaa.i = %d\naaa.j = %d\n", aaa.i, aaa.j);
// 查看member的offset
printf("offset i: %d\n", offset_of_member(struct AAA, i));
printf("offset j: %d\n", offset_of_member(struct AAA, j));
printf("offset p: %d\n", offset_of_member(struct AAA, list));
printf("offset p1: %d\n", offset_of_member(struct AAA, list.next));
printf("offset p2: %d\n", offset_of_member(struct AAA, list.prev));
// 直接查看节点aaa的起始地址
printf("\nobs_aaa1_addr: %p\n", &aaa);
// 通过container_of间接获取节点aaa的起始地址
printf("obs_aaa2_addr: %p\n", container_of(&aaa.i, struct AAA, i));
printf("obs_aaa3_addr: %p\n", container_of(&aaa.j, struct AAA, j));
printf("obs_aaa4_addr: %p\n", container_of(&aaa.list, struct AAA, list));
printf("obs_aaa5_addr: %p\n", container_of(&aaa.list.next, struct AAA, list.next));
printf("obs_aaa6_addr: %p\n", container_of(&aaa.list.prev, struct AAA, list.prev));
return 0;
}
对链表的操作
对链表操作的所有函数的 复杂度都为O(1)。无论链表大小和传入的参数,都在恒定的时间完成任务。
1. 创建链表
就是创建一个特殊的指针索引,能够索引到整个链表。链表的头结点,索引节点,而实际上它就是一个常规的list_head。
static LIST_HEAD(fox_list); // 定义并初始化一个名为fox_list的链表
2. 添加节点到链表
// 在head节点后插入new节点
list_add(struct list_head *new, struct list_head *head);
// 在head节点前插入new节点,可以用它实现队列
list_add_tail(struct list_head *new, struct list_head *head);
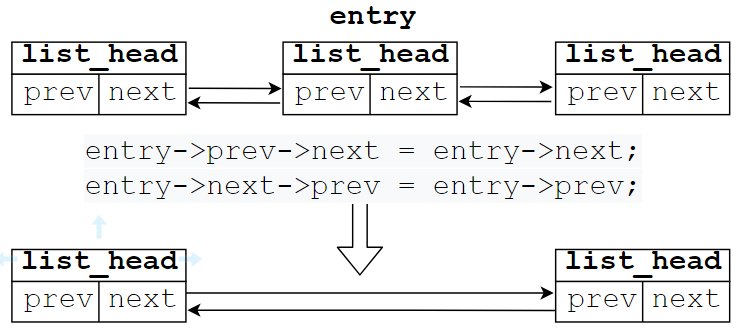
3. 删除节点
list_del(struct list_head *entry),该函数并不会释放entry和entry节点对应的数据结构所占内存,仅仅是将entry元素从链表中移除。
// 将fox这个数据结构构成的节点从链表中删除,但是节点的数据还在
list_del(&fox->list);
// 将entry节点从链表中删除,并且重新初始化entry
list_del_init(struct list_head *entry);
4. 移动合并节点
移动
// 从一个链表中移除list节点,将list节点添加到另一个链表的head节点的后面
list_move(struct list_head *list, struct list_head *head);
// 从一个链表中移除list节点,将list节点添加到另一个链表的head节点的前面
list_move_tail(struct list_head *list, struct list_head *head);
合并
// 将list指向的链表 添加到另一个链表的head节点后
list_splice(struct list_head *list, struct list_head *head);
// 将list指向的链表 添加到另一个链表的head节点后,然后重新初始化那个空链表
list_splice_init(struct list_head *list, struct list_head *head);
5. 判断是否为空
list_empty(struct list_head *head);
遍历链表(Traversing Linked Lists)
和链表操作函数不同,遍历链表的复杂度为O(n),n为链表元素个数。
1. 基本方法
用list_for_each()宏,使用两个list_head类型参数,第一个用于指向当前项不断移动指向下一个元素,第二个是链表的head,它只能遍历list_head指针,通常要结合list_entry()宏得到指向的数据结构。
struct list_head *p; // 需要查找的链表节点
struct fox *f; // 保存查找的结果
list_for_each(p, &fox_list) { // p指针依次移动指向下一项
/* f points to the structure in which the list is embedded */
f = list_entry(p, struct fox, list); // 返回 包含p的那个数据结构的 指针,f为遍历结果
}
// 宏list_entry的参数:
// `ptr`表示成员member所在的位置,list当然也是其成员
// `type`结构体类型,
// `member`结构体的一个成员的名称。
2. 可用方法,常用方法
遍历链表得到的是list_head类型指针,通常没有什么用,我们需要得到节点对应的数据结构。有现成的宏list_for_each_entry(pos, head, member),内部也是用list_entry()宏实现的。
pos:那个数据结构的指针,可看作list_entry()返回值
head:链表头
member:数据结构的成员如list
一个小例子:
struct fox *f;
list_for_each_entry(f, &fox_list, list) {
/* on each iteration, ‘f’ points to the next fox structure ... */
// f为遍历链表节点对应的数据结构,但是好像这种遍历方法只适合 存储同类型的数据 的链表,不太明白?
}
3. 反向遍历链表
存在的理由:性能,当知道节点的大概位置 反向遍历也许更近快;堆栈,用链表实现堆栈时需要从尾向前遍历。
list_for_each_entry_reverse(pos, head, member);
4. 遍历的同时删除
标准遍历方法建立在不改变链表项的前提。如果在标准遍历中删除项,将找不到下一节点(或上一节点)的指针。Linux也提供了可以在遍历时删除节点的操作,需要提供next指针,类型与pos一致。
pos: 那个数据结构的指针,可看作list_entry()返回值
next:临时保存当前项的指针,防止删除找不到前后指针,类型与pos一致
head:链表头
member:数据结构的成员如list
// 遍历时可以删除
list_for_each_entry_safe(pos, next, head, member);
// 反向遍历时可以删除
list_for_each_entry_safe_reverse(pos, n, head, member);
注意:删除时需要保护数据,进行锁定,因为可能其他地方并发地删除或操作。
2. 队列
任何操作系统内核都少不了一种编程模型:生产者和消费者。实现该方法的简单方式就是队列。
生产者产生数据,消费者处理数据。
kfifo
kfifo和其他队列差不多,两个主要操作,enqueue和dequeue。
维护两个偏移量,in offset入口偏移 和 out offset出口偏移。下次入(出)队列时的偏移。出口偏移总是小于等于入口偏移 out offset <= in offset。
1. 创建队列
动态创建更常用kfifo_alloc,创建并初始化一个大小为size的kfifo,size必须是2的幂,成功返回0,失败返回负数错误码。
int kfifo_alloc(struct kfifo *fifo, unsigned int size, gfp_t gfp_mask);
2. 入出队列 偷窥
入:把from指针所指的len字节数据拷贝到fifo队列中,成功则返回拷贝成功的数据长度,如果队列空闲小于len则最多拷贝该长度数据,返回值可能小于len,返回0则表示没有拷贝任何数据。
出:从 fifo中 拷贝 len长度的数据 到to缓冲中,成功则返回拷贝的数据长度。出队后数据不再在队列中。
偷窥:仅仅查看数据,数据还在队列里面。
// 入队
unsigned int kfifo_in(struct kfifo *fifo, const void *from, unsigned int len);
// 出队
unsigned int kfifo_out(struct kfifo *fifo, void *to, unsigned int len);
// 仅仅偷窥数据
unsigned int kfifo_out_peek(struct kfifo *fifo, void *to, unsigned int len, unsigned offset);
3. 获取队列长度,空或者满
kfifo队列空间总大小
static inline unsigned int kfifo_size(struct kfifo *fifo);
kfifo已有数据的大小
static inline unsigned int kfifo_len(struct kfifo *fifo);
kfifio还有多少空间
static inline unsigned int kfifo_avail(struct kfifo *fifo);
空或者满
空或者满则返回非0值,相反返回0。
static inline int kfifo_is_empty(struct kfifo *fifo);
static inline int kfifo_is_full(struct kfifo *fifo);
重置和撤销队列
重置就是抛弃所有队列中已有的内容,
static inline void kfifo_reset(struct kfifo *fifo);
撤销使用kfifo_alloc()分配的队列,用kfifo_free()。释放的方法 取决于创建的方法。
3. 映射
也叫关联数组,键到值的关联关系 为映射。
哈希 和 二叉搜索树 都可以实现映射。
哈希和二叉树的差异
- hash表具有相对较好的平均时间复杂度。二叉树有着更好的最坏时间复杂度。
- hash表通过hash函数能够映射不同类型的key。二叉树没有hash,更多用于同类key。
- hash表中的key经过hash之后是无序的,便于点查找(linkedhashmap是又加了一个指针)。二叉树能够满足顺序保存,便于范围查找。
- hash收缩操作耗时间,而二叉树在内存上释放和扩展有着天然独特的优势。
Linux中的映射,是一个简单的映射数据结构,并非一个通用的映射。映射一个唯一的标识数(UID)到指针。idr数据结构用于映射用户空间的UID。
1. 初始化一个idr
可以动态分配或者静态定义一个数据结构idr数据结构,然后调用idr_init()初始化。
struct idr id_huh; /* statically define idr structure */
idr_init(&id_huh); /* initialize provided idr structure */
2. 分配一个新的UID
需要两步:1. 告诉idr你需要分配UID,idr也许需要调整大小(在无锁情况下分配内存); 2. 请求新的UID。
// 1. 在需要的时候调整后备树大小,使用gfp标识。成功返回1,失败返回0,与内核其他函数有区别
int idr_pre_get(struct idr *idp, gfp_t gfp_mask);
// 2. 实际获取新UID,关联到ptr上,并将其加到idr。
// 成功时返回0,错误时返回非0错误码-EAGAIN说明需要再次调用idr_pre_get();
// -ENOSPC表示idr已满
int idr_get_new(struct idr *idp, void *ptr, int *id);
// 例子:
int id;
do {
if (!idr_pre_get(&idr_huh, GFP_KERNEL))
return -ENOSPC;
ret = idr_get_new(&idr_huh, ptr, &id);
} while (ret == -EAGAIN);
查找UID
调用者要给出UID,idr将返回对应指针。错误则返回空指针。
void *idr_find(struct idr *idp, int id);
删除UID
从idr中删除UID,并将id关联的指针一起从映射中删除,但是没有办法提示任何错误。
void idr_remove(struct idr *idp, int id);
撤销idr
只释放idr未使用的内存。
void idr_destroy(struct idr *idp);
4. 二叉树
树结构是一个 能提供分层的树型数据结构。
在数学意义上,树是一个无还的、连接的有向图。
二叉搜索树BST
二叉搜索树是一个节点有序的二叉树,顺序遵循下列法则:
- 根的 左分支值 都小于 根节点值
- 右分支值 都大于 根节点的值
- 所有子树都是二叉搜索树
搜索一个给定值(对数) 按序遍历树(线性)。
自平衡二叉搜索树
平衡二叉搜索树:所有叶子节点深度差不超过1的二叉搜索树。
自平衡二叉树:其操作都试图维持(半)平衡的二叉搜索树。
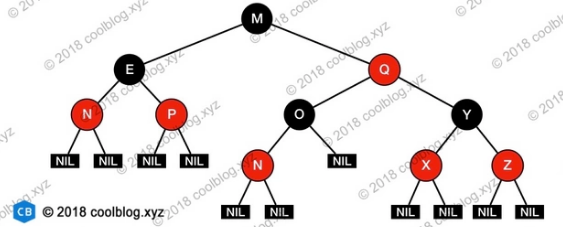
1. 红黑树
优秀博客:https://segmentfault.com/a/1190000012728513
红黑树是自平衡二叉搜索树,能维持半平衡结构,遵循6个属性:
- 节点是红色或黑色
- 根是黑色
- 所有叶子都是黑色(叶子是NIL节点)
- 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
- 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点(简称黑高)
有了性质4和5之后即可保证任意节点到其每个叶子节点路径最长不会超过最短路径的2倍。解释从根节点到叶子节点的最长路径为什么不会超过最短路径的两倍:
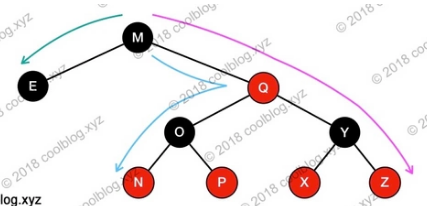
第四条,红色节点必须有两个子节点(红色节点不能是其他红色节点的子节点或父节点)。
第五条,从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
这两条保证了树里的最长路径一定是红黑交替的路径,而最短则是全黑色路径,所以最长不超过最短路径的两倍。
红黑树的插入效率和树中节点数呈对数关系。
rbtree
Linux中的红黑树为rbtree,根节点由rb_root数据结构描述,创建一个红黑树并用特殊值初始化RB_ROOT:
struct rb_root root = RB_ROOT;
树里的其他节点由rb_node描述。rbtree的实现并没有提供搜索和插入例程,需要用户自己定义,因为C语言不容易进行泛型编程,最有效的搜索和插入需要用户自己去实现。
数据结构以及选择
1. 链表
- 对数据结构上文主要操作是遍历,使用链表,没有比线性复杂度更好的算法去遍历了。
- 当性能不是首要考虑,存储的数据较少,需要和内核其他链表的代码交互时,也优先选择链表。
- 存储大小不明的数据集合,可以动态添加数据项。
2. 队列
- 符合生产者/消费者的情况,可以使用队列
- 需要定长缓冲
3. 映射
- 映射1个UID到对象,Linux是针对UID到指针的映射。
4. 红黑树
- 存储大量数据,并要求检索迅速,红黑树保证 搜索时间复杂度为对数关系 同时 遍历时间复杂度为线性关系。
内核还实现了基数(trie)和位图
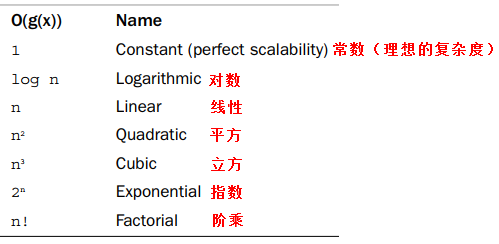
算法复杂度(伸缩度)
常用的是研究算法的渐进行为(asymptotic behavior),指当算法的输入为无限大时算法的行为。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









