







Callisto: Entropy based test generation and data quality assessment for Machine Learning Systems
简介:
论文标题
- Callisto: Entropy based test generation and data quality assessment for Machine Learning Systems
- Callisto:基于熵的测试生成和数据机器学习系统的质量评估
简介:
-
提出了一个从测试集中选择高质量的测试例子的工具Callisto
-
两种算法:
- 选择适当的用例进行反例生成(旋转,平移等等变换)
- 评价用例质量
两种算法都是基于熵的,即用softmax后得到的向量进行熵计算,比较简单
总之:CALLISTO是一个框架,使用熵来生成测试并最小化测试集
用例边界

我们在图1中说明了CALLISTO的测试生成方法的直觉。考虑变形变换M(例如,少量旋转图片)和输入A1,A2和A。基本方法是将M应用于所有引出的数据点 大量的计算开销。 CALLISTO旨在发现诸如A之类的点,这些点将允许用户有选择地将变形关系应用于可能导致错误的输入。 CALLISTO将避开诸如A1和A2之类的点。
就是选择距离边界较近的点,熵大的就是容易接近边界的
熵计算公式
H ′ = − ∑ i = 1 N l i ln l i \begin{array}{cc} H^{\prime}=-\sum_{i=1}^{N} l_{i} \ln l_{i} \end{array} H′=−∑i=1Nlilnli
eg:
[
l
0
,
l
1
,
l
2
,
l
3
]
A
≈
[
0.033
,
0.033
,
0.9
,
0.034
]
A
≈
0.44
\begin{array}{cc} \left[l_{0}, l_{1}, l_{2}, l_{3}\right]_{A} \approx[0.033,0.033,0.9,0.034] \\ A ≈ 0.44 \end{array}
[l0,l1,l2,l3]A≈[0.033,0.033,0.9,0.034]A≈0.44
就是用softmax后的值计算熵
算法
符号定义
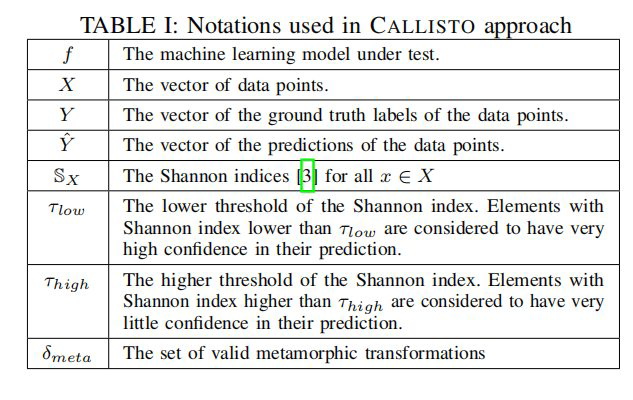
正在测试的机器学习模型。
数据点向量。
真实标签的向量。
数据点预测的向量。
所有x∈X 的熵
熵的下限。元素与香农指数低于τ 低被认为具有对他们的预测充满信心。
熵的上限。香农指数的较高阈值。元素与香农指数高于τ 高被认为具有对他们的预测缺乏信心。
有效的数据转换方法集
可以看出定义是比较简单的,数据质量直接与熵的大小挂钩
算法1:选出测试集

从所有集合中选择出熵高(选定标签)的放入集合G,再将G中反例进行变换并选出错误用例集合E
流程图
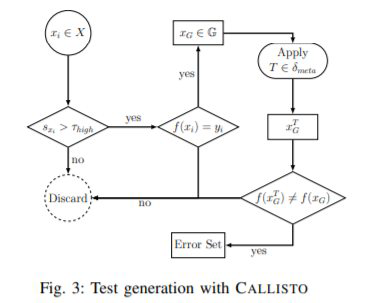
算法2:评价数据质量

就是熵小于某个值就是低质量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









