







 本文介绍了字典树(Trie树)的概念及其在字符串查找和统计中的优势。通过代码展示了字典树的插入、搜索和删除操作,并解释了`end`和`path`属性的作用。文章还探讨了如何优化字典树以处理不同字符集,并提醒读者注意避免误判。
本文介绍了字典树(Trie树)的概念及其在字符串查找和统计中的优势。通过代码展示了字典树的插入、搜索和删除操作,并解释了`end`和`path`属性的作用。文章还探讨了如何优化字典树以处理不同字符集,并提醒读者注意避免误判。
大家好,都吃晚饭了吗?我是Kaiqisan,是一个已经走出社恐的一般生徒,这一篇文章咱来讲讲字典树把,之前在给别人代答辩数据结构的时候初次了解到这个概念,今天在刷算法课的时候右看到了,所以就有了这个视频
首先还是明确一个概念,什么是字典树?
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
------------------------------- 以上内容来自百度百科 https://baike.baidu.com/item/%E5%AD%97%E5%85%B8%E6%A0%91/9825209?fr=aladdin
以上图文来自网络
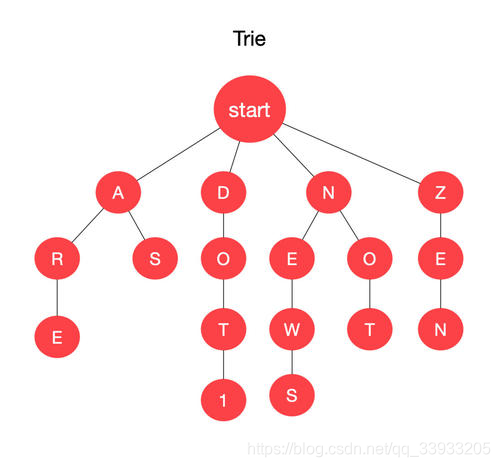
查找树最大的功能如其名,可以查找一个单词是否存在以及其出现的频次,比如一个单词zen,就使用上面的树来查找,就一个一个单词的去比对,从根节点出发查看所有的子节点,康康有没有第一个字符的节点,如果没有,就没找到,如果找到了就到这个子节点的子节点,接着匹配第二个字符。
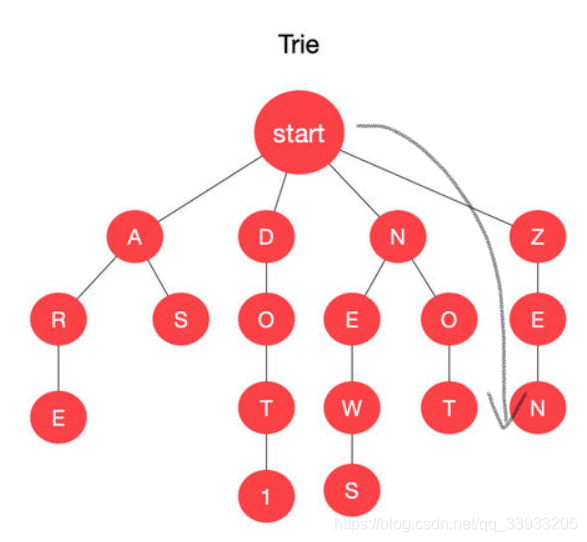
接下来,我们就来用代码实现它的增删改查吧!
这个字典序只是考虑了所有小写的字符
class dictionaryTree {
public int path;
public int end;
public dictionaryTree[] nexts;
public dictionaryTree() {
path = 0;
end = 0;
nexts = new dictionaryTree[26];
// 在生成一个节点的时候再生成其26个字母的指针,一开始因为什么都没有,就全部指向null
Arrays.fill(nexts, null);
}
// 录入单词
public void insert(String word) {
if (word == null) {
return;
}
char[] arr = word.toCharArray();
dictionaryTree node = this; // this表示根节点
int index = 0;
for (int i = 0; i < arr.length; i++) {
index = arr[i] - 'a'; // 找到和字母a的ascii编码的偏差
if (node.nexts[index] == null) {
node.nexts[index] = new dictionaryTree(); // 给个指针
}
node = node.nexts[index];
node.path++;
}
node.end++;
}
// 查找单词
public boolean search(String word) {
if (word == null) {
return false;
}
char[] arr = word.toCharArray();
int index = 0;
dictionaryTree node = this;
for (int i = 0; i < arr.length; i++) {
index = arr[i] - 'a';
if (node.nexts[index] == null) { // 走到思路,找不到了
return false;
}
node = node.nexts[index];
}
// 如果到底了,判断end是否为0,如果为0,这个单词不存在,反之就是存在
return node.end > 0;
}
// 删除单词
public boolean delete(String word) {
// 删除一个单词的前提是这个单词存在
if (search(word)) {
char[] arr = word.toCharArray();
dictionaryTree node = this;
int index = 0;
for (int i = 0; i < arr.length; i++) {
index = arr[i] - 'a';
if (--node.nexts[index].path == 0) {
// 如果path为0了表示这个节点没用了,需要抛弃
node.nexts[index] = null;
return true;
}
node = node.nexts[index];
}
node.end--;
return true;
} else {
return false;
}
}
}
属性讲解:end表示有多少单词在此处结尾 path表示有多少单词在拼写的过程中经过这里,可以把它们当做停靠站和终点站。
end是防止在找单词的时候出现错找,如果没有end的话,我们遍历树的时候只能通过有没有走到死路(指针指向null)来判断。假如我们往字典树录入一个单词apple,然后找单词app照理来说它不会被找到,但如果我们通过上面的方法的话,树遍历没有走死胡同,就会被误判为可以找到,就会返回错误的结果,
如果我们使用end来判断一个单词的结尾,假如我们录入单词apple,我们只有最后一个单词e所在节点的end值为1,所以我们再一次搜索单词app,在最后一个单词p所在的节点的end属性为0,所以没有单词app
path用处比end小,起到一个辅助的作用,一个用处是用来统计有多少单词是以xxx开头的,另一个左右是用来节省空间的,在删除节点的时候,如果某个节点的path值变为0了,就表示有0个单词以xxx开头了,所以这个节点是没用的,就让其父节点放开这个孩子,从而被垃圾回收。
剩下的其他细节看注释
总结
如果您的单词包含除了小写字符意外的字符的话建议把上面的数组的length扩张到256,涵盖所有的字符。或者您也可以自己编写ArrayList来更加灵活地增删节点!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











