




1. 测试启动好的服务是否可用:
# ip改为 启动服务那台机器ip
curl http://127.0.0.1:11434/api/tags
# 或者telnet
telnet ip:port
# curl请求:把localhost改为 启动的大模型服务那台ip
curl http://localhost:11434/api/generate -X POST -d '{"model": "deepseek-r1:7b", "prompt": "Hello, how are you?"}' -H 'Content-Type: application/json'
2. ubuntu 放行端口
#查看放开列表: ufw status
# 放行端口 ufw allow 11434
3. ollama配置修改,非本机访问放行
3.1 修改配置地址:
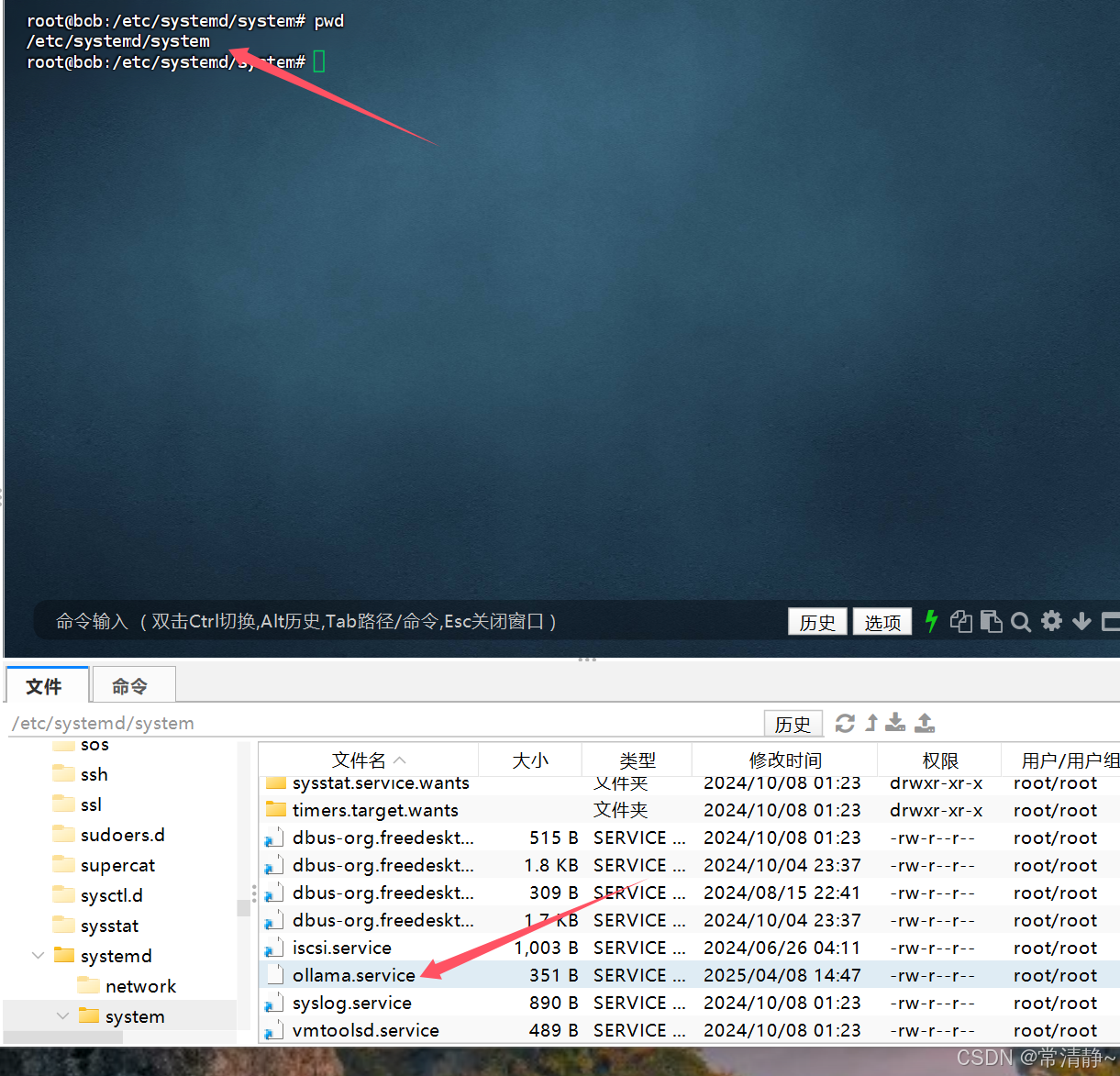
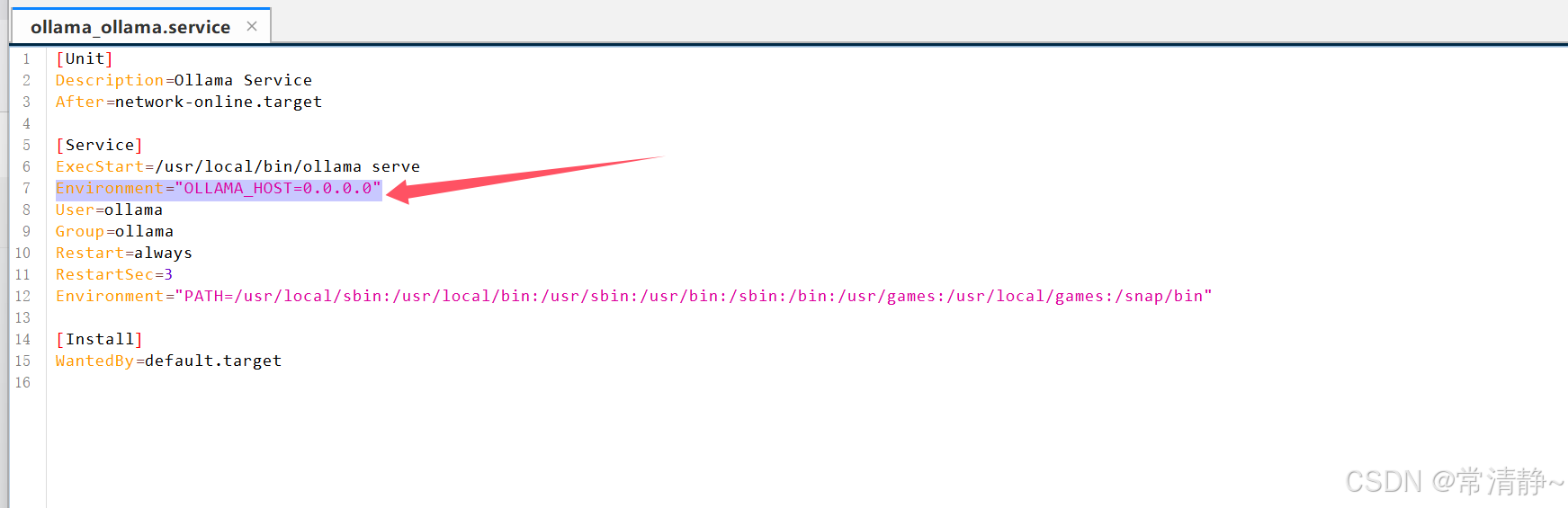
3.2 如图添加一行参数即可:
Environment="OLLAMA_HOST=0.0.0.0"
3.3 刷新配置
systemctl daemon-reload
3.4 重启
systemctl restart ollama
4.如果你得还没有解决,重复排查。或者使用的阿里云服务,需要阿里云控制台也开下端口。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









