







前言
经常有这样的一些需求,需要在linux系统后台调用命令获取特定的输出。subprocess就是这样一个专门用作执行shell命令的模块。笔者在工作中经常需要用到这个模块,遇到了一些问题,在此和大家讨论一下。
一、死锁现象
接到反馈,开发的一个检测工具卡住了,一直没有结束,于是查看进程,追溯到卡死的进程以及执行的命令,然后手动执行该命令,发现也是卡住了,手动输入ctrl + c后发现最后一直卡在读取输出。于是,简单一搜索,说是wait存在死锁问题,用communicate函数即可。于是,笔者照做顺利解决了问题。但是,笔者尝试查询原因时,遇到了一些问题。
二、分析步骤
1.管道大小导致死锁
代码如下(python2示例):
import subprocess
def shell_cmd(cmd):
process = subprocess.Popen(
cmd,
shell=True,
# 注意,标准输出指向管道,错误输出也是
stdout = subprocess.PIPE,
stderr = subprocess.PIPE
)
# 屏蔽下述两行会导致卡住
stdout = process.stdout.read()
stderr = process.stderr.read()
process.wait()
code = process.returncode
return stdout, stderr, code
shell_cmd("dd if=/dev/zero bs=1 count=%d" % 65 * 1024)
dd 可以产生大量输出,命令dd if=/dev/zero bs=1 count=1 表示产生1bytes的输出
第一种卡死的原因(python文档):
备注 当 stdout=PIPE 或者 stderr=PIPE 并且子进程产生了足以阻塞 OS 管道缓冲区接收更多数据的输出到管道时,将会发生死锁。当使用管道时用 Popen.communicate() 来规避它。
查询到linux的管道最大值是64KB,于是构造超过64KB的输出,也即单独执行上述代码应该是卡住的,但是实际不会卡住。原因是什么呢?我们注意到read方法,是不是read方法读取了管道内容导致不会阻塞?
于是,我们去掉read方法后再次执行,发现真的卡住了。
结论:如果父进程不去读取管道内容,那么等到子进程的输出写满了管道(linux 64KB)就会产生死锁。但是,本文中的代码存在read()方法,按理说是不应该卡住的。
2.异步导致的死锁
第二种可能卡死的原因(来自python文档):
警告 使用 communicate() 而非 .stdin.write, .stdout.read 或者 .stderr.read 来避免由于任意其他 OS 管道缓冲区被子进程填满阻塞而导致的死锁。
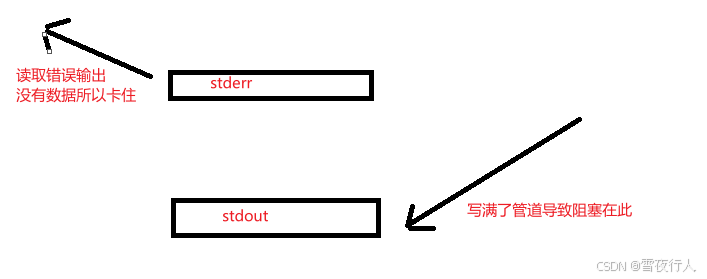
本文中的代码存在一个特殊的地方,即标准输出和错误输出都重定向到了PIPE管道,二者都会向管道中写内容,假如执行的命令首先输出超过64KB的错误内容,那么子进程会阻塞等待读取标准错误管道中的内容。然而代码中是先去读取标准输出的内容,但是不存在标准输出,子进程也在运行,那么父进程就会阻塞在此处等待标准输出管道的内容。二者同时等待不可能发生的事情,于是就发生了死锁。
验证代码如下(示例):
def shell_cmd(cmd):
process = subprocess.Popen(
cmd,
shell=True,
stdout = subprocess.PIPE,
stderr = subprocess.PIPE
)
# 和上面的代码相比就是交换二者,先读错误输出,后读标准输出
stderr = process.stderr.read()
stdout = process.stdout.read()
process.wait()
code = process.returncode
return stdout, stderr, code
shell_cmd("dd if=/dev/zero bs=1 count=%d" % 65 * 1024)
等等,一个读,一个写,中间是管道,这个不就是大名鼎鼎的生产者消费者模式吗?这么一想,一下子豁然开朗了。存在两组生产者消费者,非别是标准输出和错误输出,父进程这边的消费者是同步的,按顺序读取的,但是子进程那边的生产者是异步的,二者有可能产生死锁。
可能有读者会有疑问?既然标准错误输出没有内容,为什么不往里面写EOF结束符,这样子process.stderr.read()就可以顺利运行下去了。但是如果不看代码,标准输出都还没有全部写入管道(即代码都没执行完毕),怎么能够确定不会有错误写入到标准错误输出中,因此,是不可能写EOF结束符到错误管道中的。
上述代码中,如果将执行的命令的输出小于64KB,那么代码不会被卡住,这说明子进程将所有标准输出写入输出管道后(代码执行完毕后),就会去将EOF写入标准错误输出,然后父进程读取到错误输出的EOF后就会往下执行标准输出的读取,从而顺利读取内容。
3.修复
那么该如何修复这个问题呢?一个直观的想法就是,能不能在一个输出管道阻塞的时候,去读另一个输出的管道内容,答案是肯定的。python3给了我们答案,让我们来看一下:
def _readerthread(self, fh, buffer):
buffer.append(fh.read())
fh.close()
def _communicate(self, input, endtime, orig_timeout):
# Start reader threads feeding into a list hanging off of this
# object, unless they've already been started.
if self.stdout and not hasattr(self, "_stdout_buff"):
self._stdout_buff = []
self.stdout_thread = \
threading.Thread(target=self._readerthread,
args=(self.stdout, self._stdout_buff))
self.stdout_thread.daemon = True
self.stdout_thread.start()
if self.stderr and not hasattr(self, "_stderr_buff"):
self._stderr_buff = []
self.stderr_thread = \
threading.Thread(target=self._readerthread,
args=(self.stderr, self._stderr_buff))
self.stderr_thread.daemon = True
self.stderr_thread.start()
if self.stdin:
self._stdin_write(input)
# Wait for the reader threads, or time out. If we time out, the
# threads remain reading and the fds left open in case the user
# calls communicate again.
if self.stdout is not None:
self.stdout_thread.join(self._remaining_time(endtime))
if self.stdout_thread.is_alive():
raise TimeoutExpired(self.args, orig_timeout)
if self.stderr is not None:
self.stderr_thread.join(self._remaining_time(endtime))
if self.stderr_thread.is_alive():
raise TimeoutExpired(self.args, orig_timeout)
# Collect the output from and close both pipes, now that we know
# both have been read successfully.
stdout = None
stderr = None
if self.stdout:
stdout = self._stdout_buff
self.stdout.close()
if self.stderr:
stderr = self._stderr_buff
self.stderr.close()
# All data exchanged. Translate lists into strings.
if stdout is not None:
stdout = stdout[0]
if stderr is not None:
stderr = stderr[0]
return (stdout, stderr)
前文也提到了本文是基于python2分析而成,python3中将Popen类做了封装,可以直接调用run方法,更加安全。上述的代码就是communicate方法的核心代码,总接起来就是一句话:用两个线程分别读取标准输出和错误输出。
总结
以上就是今天要讲的内容,本文分析了产生死锁的两个原因:分别是管道大小限制和异步机制。本次问题就是异步导致的死锁。

















 2780
2780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









