









目录
tf.multiply()
定义:两个矩阵中对应元素各自相乘
使用方法
tf.multiply(x,y,name=None)
参数:
x:一个数据类型为:half,float32,....的张量
y:一个类型跟张量x相同的张量
返回值:x*y element-wise
注意:两个元素的数必须有相同的数据类型,不然就会报错。
tf.matmul()
tf.matmul(a,b,transpose_a=False,transpose_b=False,adjoint_a=False,adjoint_b=False,a_is_sparse=False,b_is_sparse=False)
- a: 一个类型为 float16, float32, float64, int32, complex64, complex128 且张量秩 > 1 的张量。
- b: 一个类型跟张量a相同的张量。
- transpose_a: 如果为真, a则在进行乘法计算前进行转置。
- transpose_b: 如果为真, b则在进行乘法计算前进行转置。
- adjoint_a: 如果为真, a则在进行乘法计算前进行共轭和转置。
- adjoint_b: 如果为真, b则在进行乘法计算前进行共轭和转置。
- a_is_sparse: 如果为真, a会被处理为稀疏矩阵。
- b_is_sparse: 如果为真, b会被处理为稀疏矩阵。
注意:
(1)输入必须是矩阵(或者秩>2的张量),并且其在转置之后有想匹配的矩阵尺寸。
(2)两个矩阵必须都是相同的类型,支持的类型如下:float16,float32,float64,int32,complex64,complex128
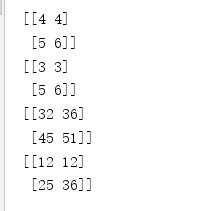
import tensorflow as tf
a = tf.constant([[4,4],[5,6]])
b = tf.constant([[3,3],[5,6]])
sess = tf.Session()
print(sess.run(a))
print(sess.run(b))
c = tf.matmul(a,b)
d = tf.multiply(a,b)
print(sess.run(c))
print(sess.run(d))
运行结果

















 3286
3286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









