




本文是参考知乎上的文章做一个简单的总结:
https://zhuanlan.zhihu.com/p/40047760
https://zhuanlan.zhihu.com/p/40020809
这篇博客作为阅读我get到的重点内容总结。
首先物体检测发展主要集中在两个方向:two stage算法如R-CNN系列和one
stage算法如YOLO、SSD等。
两者的主要区别在于two stage算法需要先生成proposal(一个有可能包含待检物体的预选框),然后进行细粒度的物体检测。而one stage算法会直接在网络中提取特征来预测物体分类和位置。
下面这个图是我觉得最清晰的一张图:
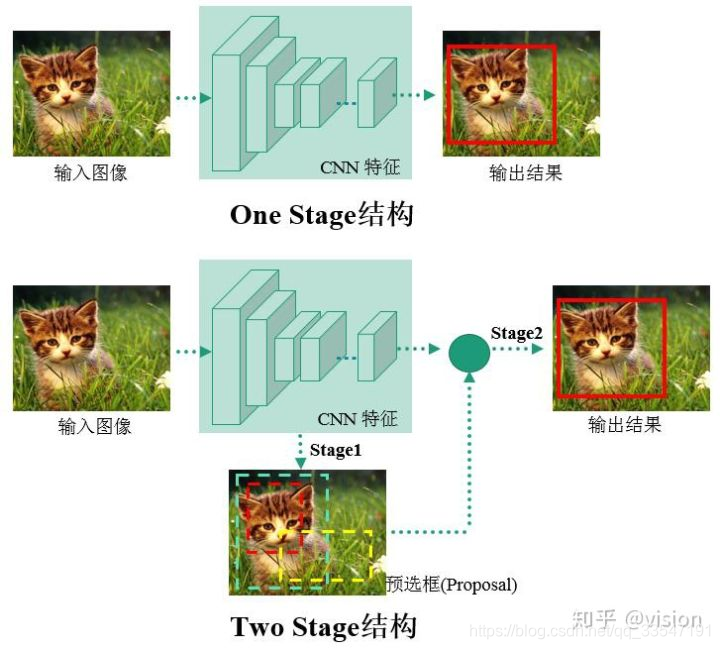
在one-stage的结构中就会涉及到anchor-box的问题,在Two-stage中是直接的proposal.
先介绍two-stage方法:
在Faster R-CNN基础上改进的几篇论文:R-FCN、R-FCN3000和Mask R-CNN。
1. R-FCN:Object Detection via Region-based Fully Convolutional Networks CVPR2017
核心idea:通过提出的位置敏感分数图(position sensitive score maps)来增强网络对于位置信息的表达能力,提高检测效果。
2. R-FCN-3000 :R-FCN-3000 at 30fps: Decoupling Detection and Classification
核心:主要是解决速度的问题,r-fcn-3000是对r-fcn的改进。上文提到,r-fcn的ps卷积核是per class的,假设有C个物体类别,有K*K个ps核,那么ps卷积层输出K*K*C个通道,导致检测的运算复杂度很高,尤其当要检测的目标物体类别数较大时,检测速度会很慢,难以满足实际应用需求。
r-fcn-3000提出,将ps卷积核作用在超类上,每个超类包含多个物体类别,假设超类个数为SC,那么ps卷积层输出K*K*SC个通道。由于SC远远小于C,因此可大大降低运算复杂度。特别地,论文提出,当只使用一个超类时,检测效果依然不错。
3. Mask R-CNN CVPR2017
论文目标
1. 解决RoIPooling在Pooling过程中对RoI区域产生形变,且位置信息提取不精确的问题。
2. 通过改进Faster R-CNN结构完成分割任务。
核心思想:
1. 使用RoIAlign代替RoIPooling,得到更好的定位效果。
2. 在Faster R-CNN基础上加上mask分支,增加相应loss,完成像素级分割任务。
主要实现是在faster R-CNN 基础上增加了MASK分支。
针对小物体检测的论文:
1.FPN: Feature Pyramid Networks for Object Detection
引入Top-Down 结构提升小物体检测效果。
FPN解决的问题:
只用网络高层特征去做检测,虽然语义信息比较丰富,但是经过层层pooling等操作,特征丢失太多细节信息,对于小目标检测这些信息往往是比较重要的。所以,作者想要将语义信息充分的高层特征映射回分辨率较大、细节信息充分的底层特征,将二者以合适的方式融合来提升小目标的检测效果。
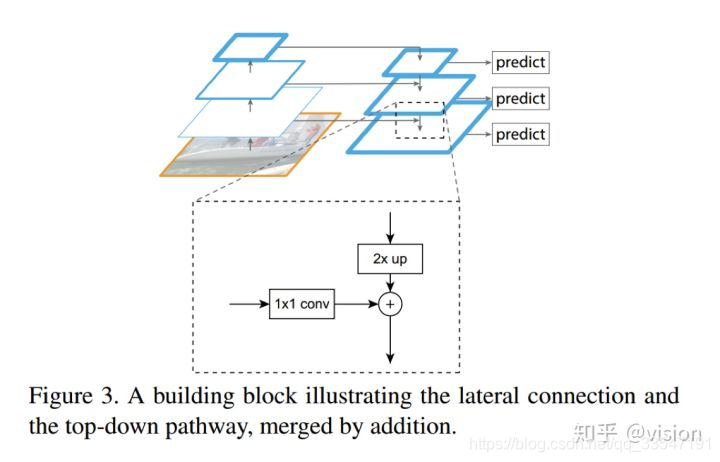
FPN网络进行了特征融合,融合的方式是高位特征进行二倍上采样,低层的特征通过一个1×1的卷积做将维操作,然后两个特征做像素像素极相加进行特征融合。融合之后的特征经过逸一个3x3的卷积预测输出。
2.Beyond Skip Connections Top Down Modulation for Object Detection CVPR2017
在该算法中,高底层的信息融合不是像FPN一样像素级叠加,而是通过卷积进行融合。由神经网络自主的选择选择哪些特征进行融合,实现这一“调制”过程。
在网络结构设计上有两点值得借鉴的地方:
2. 侧向连接和bottom-up的连接应该减少特征维度。(特征维度比较高的时候,进行特征融合可以通过1x1卷积进行降维处理)
3. 网络训练需要采取一层一层增加,冻结之前层的方式。这样可以保证训练收敛稳定。(还有一种就是设置前面层学习率小,后面的层学习率大。)
针对不规则形状物体的检测:
1. Deformable Convolutional Networks ICCV2017
论文目标:
提升可变性物体的检测效果。卷积神经网络由于其固定的几何结构限制了其几何变换的建模能力。传统方法通常使用数据增强(如仿射变换等)、SIFT特征以及滑动窗口算法等方法来解决几何形变的问题。但这些数据增强方法都需假设几何变换是固定的,无法适应未知的几何形变,手工设计特征和算法也非常困难和复杂。所以需要设计新的CNN结构来适应空间几何形变。
核心思想:
论文主要是引进可形变卷积和可形变RoI pooling来弥补CNN在几何变换上的不足。同时实验也表明在深度CNN中学习密集空间变换对于复杂的视觉任务(如目标检测和语义分割)是有效的。
解决正负样本不均衡的问题
Focal Loss for Dense Object Detection ICCV2017
论文作者认为,one stage检测精度之所以低于two stage方案的一个重要原因是检测样本不均衡:easy negative samples数量大大超过其他正样本类别。这使得训练过程中,easy negative samples的训练loss主导了整个模型的参数更新。(个人觉得这个对于目标检测的one-stage比two-stage的思考分析比较有意思)
为解决这个问题,论文提出了focal loss。在计算交叉熵损失时,引入调制因子,降低概率值较大的easy negative samples的loss值的权重,而对于概率值较小的误分类样本的loss值,权重保持不变。以此提高占比较低的误分类别的样本在训练时对loss计算的作用。
Chained Cascade Network for Object Detection ICCV2017
物体检测任务中背景样本会比前景多很多,在训练中会造成正负样本不均衡的情况。作者设计出一套级联的方式来去除无用的背景,浅层中的无用信息过滤掉后无需进入更深的网络中计算,后阶段的特征和分类器只负责处理少量更困难的样本。由于需处理样本数量减少(主要减少了简单样本),此级联网络可节省训练预测时间,且更困难样本经过级联后作用会加强,所以检测效果也会有一定提升。
RON-Reverse Connection with Objectness Prior Networks for Object Detection
主要尝试解决两个问题:
- 多尺度目标定位预测的问题。本文提出了RON的检测方法,首先利用一个类似于FPN的Top-Down 的连接方式,融合高层特征和底层特征(其目的在这里不做过多复述),并将融合后的不同分辨率的多层特征用来进行预测。与此同时利用一个objectness prior map过滤掉大量背景区域,提高检测效率。
- 难例挖掘的问题。提出难例挖掘方法,提出了一套自己的选择正负样本的逻辑,以及训练时loss更新的策略,但整体和其他算法的思路差别不是很大。
被遮挡物体检测
Soft-NMS -- Improving Object Detection With One Line of Code ICCV2017
计算NMS时,不是简单的去除值不是最高的物体,而是给IoU较大的框设置较小的得分。
这里面提到了两种加权方式:
1.线性加权
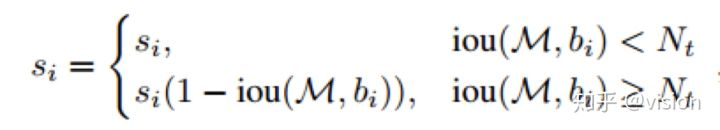
2.高斯加权
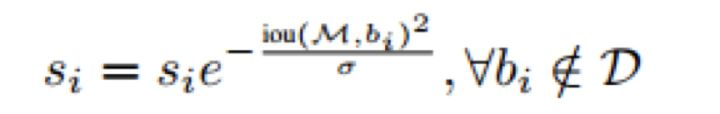
由于soft-NMS主要关注的是互相遮挡的物体,从下图中的结果提升来看,像鸟、船这种容易被遮挡的物体的提升比较明显。从作者的时间结果上来看这两种加权方式精度是一样的,但是带给我们的思考是我们在其他任务中是不是可以试一下不同的加权方式。

RRC: Accurate Single Stage Detector Using Recurrent Rolling Convolution CVPR2017
论文目标:
提升被遮挡物体或小物体的检测效果。
Idea:
SSD虽然在时间消耗和准确度上取得了不错的平衡,但是它对小物体、被遮挡的物体、同类重叠物体、照片过曝光或者欠曝光的物体检测效果不好。其原因主要是这些物体的预测位置与ground truth的IoU(Intersection over Union)有时会低于0.5。从下图的效果图(左侧图)来看虽然分类正确,位置也给出来了,但是与ground truth的偏差会很大,如果通过在训练过程中针对多尺度预测时,把输入的每一个特征图提高对应的anchor boxes的IoU阈值的话,SSD的预测的准确度会大幅度下降。针对于这种情况,本文提出了Recurrent Rolling Convolution这种结构,在生成anchor大于0.5的时候(本文设置为0.7)基于SSD的one stage模型针对于上所说的小物体、被遮挡物体等所预测的物体的位置会有较高的IoU。
总结来说就是:针对小物体和被遮挡物体IOU 的与之给的高一些。
解决检测mini-batch过小的问题
MegDet: A Large Mini-Batch Object Detector CVPR 2018
论文目标:
解决大规模Batch Size的训练问题。
缩短训练时间,提高准确率。
小 batch-size有如下缺点:a.训练时间久,b.不能为BN提供准确的数据,c.正负样本比例不均衡,d.梯度不稳定的缺点。然而增加Batch Size需要较大的learning rate,但是如果只是简单地增加learning rate,可能导致网络不收敛,如果用小的lr确保网络收敛,效果又不好。具体改进如下:
1.Variance Equivalence,即使用梯度方差等价代替梯度等价。在之前的工作中经常使用Linear Scaling Rule,即当Batch Size变为原来的k倍时,lr(learning rate)也应该变为原来的k倍。但是在分类里,损失只有Cross-Entropy,然而在检测里,图像之间有不同的Ground-Truth分布。结合两个任务的不同,分类任务的lr规律并不适合检测任务。基于此,论文提出了方差等价来代替梯度等价。
2.Warmup Strategy,即刚开始训练的时候,lr设置的小,随着每次迭代,逐渐增加lr。例如,16-batch的FPN学习率为0.02,在训256的MegDet时,如果设置lr=0.02*16,会导致模型发散,因此需要逐渐增加lr,让模型适应。随后随着训练逐渐减少lr,确保网络精度提高。
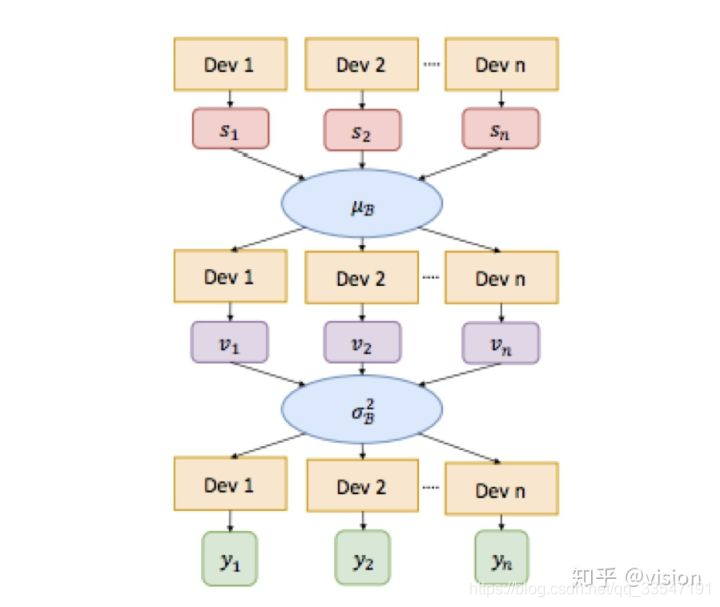
3.Cross-GPU Batch Normalization,在分类里,图片大小通常为224或299,所以一块TitanX可以容纳32张图,或者更多。然而对于检测来说,检测器需要接受各种尺寸的图片,因此会限制一个设备容纳的图片数。所以,需要跨GPU从多个样本提取不同的数据完成BN。
BN操作需要对每个batch计算均值和方差来进行标准化。其中对于多卡的具体做法是,首先聚合算均值,然后将其下发到每个卡,随后再计算minibatch的方差,最后将方差下发到每个卡,结合之前下发的均值进行标准化。如下图:
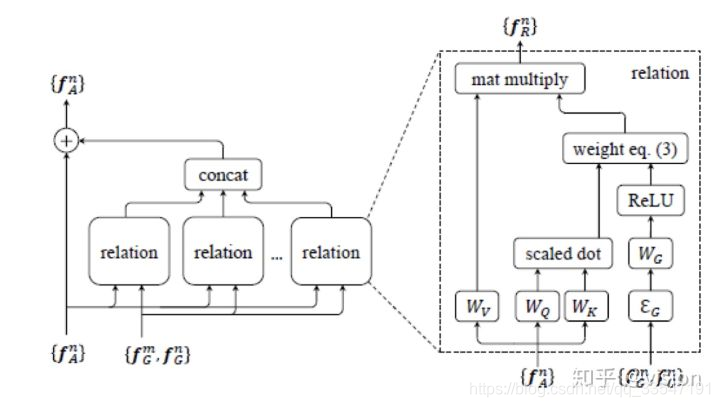
关注物体之间关联性信息


















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









