







直跳下一节:第二节-模型训练
第一节-数据采集
使用ocr的使用对硬件设备有比较高的依赖。网上下的模型没有GPU的加持识别效率不高,完成自有模型的训练在相同硬件设备的基准上能大大提高识别效率,加速脚本执行效率。看一组数据:
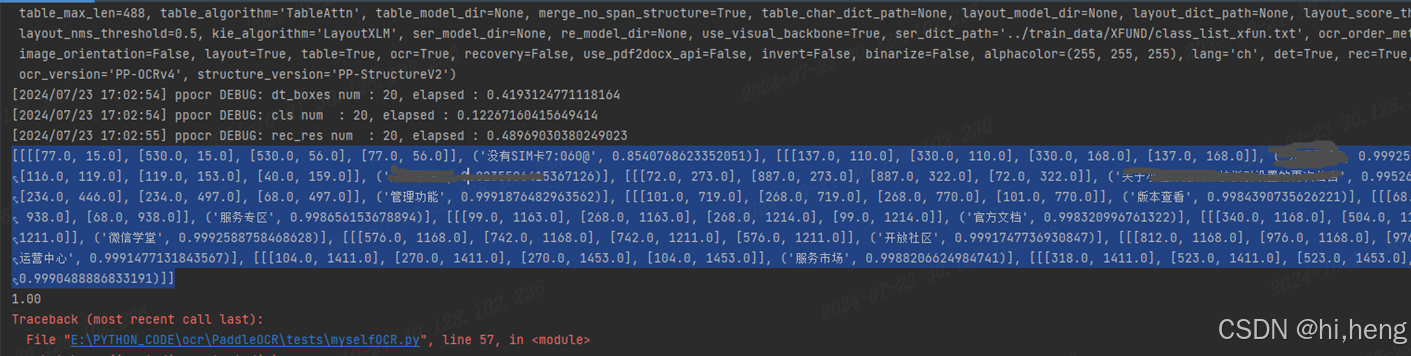
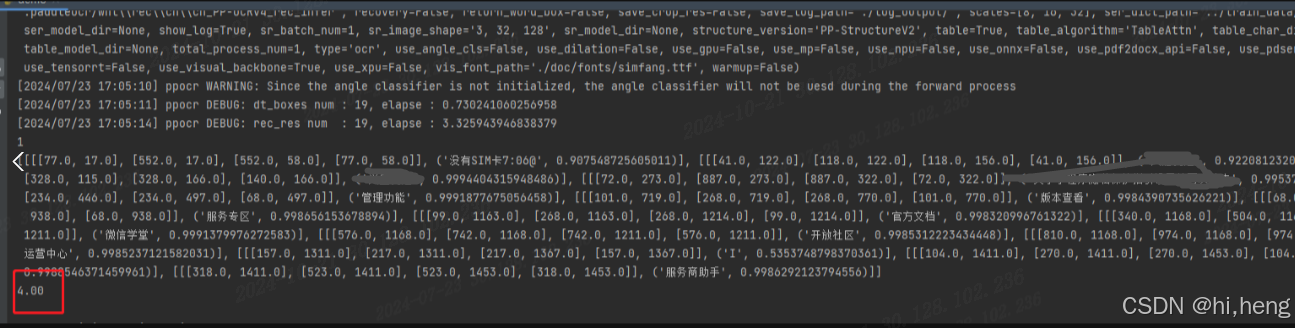
训练了自己的模型识别耗时1000ms,相同的图片网上随便下的模型4000ms
接下来可以根据下面的操作手册,一步步跟着完成模型数据的准备。当日如果想急着使用,该模块的内容可以后面骨架完成搭建后再去训练自己的模型,可以先使用网上训练好的模型、自带的模型。
一、基础环境准备-制作数据集
python 3.10 --python环境安装不过多赘述
*.先安装PaddlePaddle再安装PaddleOCR
pip install PaddlePaddle
pip install PaddleOCR
*. 安装图形标注工具:pip install PPOCRLabel 或在官网下载
https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7
安装过程如果出现:error: Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools“ 错误。可参考:点击查看解决方案地址
1.1PPOCRLabel 拷贝到操作项目路径


我这里是新建了个ocr_ui_test的目录,将PPOCRLable拷贝了进来
1.2PPOCRLabel根目录下,终端运行: python PPOCRLabel.py --lang ch
python PPOCRLabel.py --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
python PPOCRLabel.py --lang ch --kie True # 启动【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签
运行后,稍等一会儿会有gui窗口出来
这个过程可能需要几分钟的时间,编译这个gui窗口。


二、标注数据准备
2.1图片标注确认

自动标注完后,检查标注内容是否异常,这个时候还可以继续调整标注,接着依次确认标注图片

2.2导出标记
打标操作完后,点击文件->导出标记结果和点击文件->导出识别结果,完成后文件夹里多出四个文件crop_img、fileState、Label、rec_gt。
*crop_img中的图片用来训练文字识别模型
*fileState记录图片的打标完成与否
*Label为训练文字检测模型的标签
*rec_gt为训练文字识别模型的标签

2.3整理数据集
PPOCRLabel根目录下,终端运行:python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 –-datasetRootPath 打标导出的文件的绝对路径
参数说明:
trainValTestRatio 是训练集、验证集、测试集的图像数量划分比例,根据实际情况设定,默认是6:2:2
datasetRootPath 是PPOCRLabel标注的完整数据集存放路径。 ./train_data/
detRootPath 训练文字检测的数据集存放路径。 ./train_data/det
recRootPath 训练文字识别的数据集存放路径。 ./train_data/rec
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 –-datasetRootPath F:\ocr_ui_test\image

报错的是这个文件,根据错误提示在这个文件的main函数中把os包手动引入一下

执行成功了 这个就是执行后的输出结果
这个就是执行后的输出结果


rec是用来训练文字识别的数据集,det是用来训练文字检测的数据集,
三、总结整理
遇到了几个问题:
1.PPOCRLabel 安装报错:error: Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools“ 错误
2.整理数据集的时候,gen_ocr_train_val_test.py报错
第一个问题,我单独输出一个内容,可以直接参考,也可以在网上自行找更快的方法。直达链接
第二个问题:是os包没有办法应用,可能是路径问题,我们直接修改gen_ocr_train_val_test 文件代码即可,该文件在\PPOCRLabel目录下。在代码中可以看到detRootPath,recRootPath,recLabelFileName,recImageDirName都是有默认值的,如果需要调整的,可以自行调整。
if __name__ == "__main__":
# 功能描述:分别划分检测和识别的训练集、验证集、测试集
# 说明:可以根据自己的路径和需求调整参数,图像数据往往多人合作分批标注,每一批图像数据放在一个文件夹内用PPOCRLabel进行标注,
# 如此会有多个标注好的图像文件夹汇总并划分训练集、验证集、测试集的需求
import os #增加了它
import shutil
import random
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(
"--trainValTestRatio",
type=str,
default="6:2:2",
help="ratio of trainset:valset:testset")
parser.add_argument(
"--datasetRootPath",
type=str,
default="../train_data/",
help="path to the dataset marked by ppocrlabel, E.g, dataset folder named 1,2,3..."
)
parser.add_argument(
"--detRootPath",
type=str,
default="../train_data/det",
help="the path where the divided detection dataset is placed")
parser.add_argument(
"--recRootPath",
type=str,
default="../train_data/rec",
help="the path where the divided recognition dataset is placed"
)
parser.add_argument(
"--detLabelFileName",
type=str,
default="Label.txt",
help="the name of the detection annotation file")
parser.add_argument(
"--recLabelFileName",
type=str,
default="rec_gt.txt",
help="the name of the recognition annotation file"
)
parser.add_argument(
"--recImageDirName",
type=str,
default="crop_img",
help="the name of the folder where the cropped recognition dataset is located"
)
args = parser.parse_args()
genDetRecTrainVal(args)



















 2357
2357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











