









 本项目聚焦于2019新型冠状病毒肺炎的全球疫情数据爬取与分析,利用Python爬虫技术从腾讯疫情追踪获取实时数据,进行数据清洗、分析与可视化展示,包括全球与全国疫情分布、历史确诊与疑似病例对比等关键信息。
本项目聚焦于2019新型冠状病毒肺炎的全球疫情数据爬取与分析,利用Python爬虫技术从腾讯疫情追踪获取实时数据,进行数据清洗、分析与可视化展示,包括全球与全国疫情分布、历史确诊与疑似病例对比等关键信息。
2019-nCov 数据爬虫与可视化
项目详情: 这是一个项目传送门哦 _.
【背景】
新年伊始,全国人民就参加了一场没有硝烟的战斗——2019-nCov, 关于这场“战疫”, 我们每个人都是战斗士。感谢医生和护士还有来自各界各地一直奋战在一线的人们,而我们这些老百姓能做的就是他们最坚实的后盾。相信在党和国家的带领下,大家都会在最暖的阳光下,做自己喜欢的事。
话不多说,而这次的主角便是普通老百姓最关注的每日实时数据,参考了一些博客,使用 Python 进行爬虫获取数据,并选择重点数据进行可视化分析。
本项目是针对2019新型冠状肺炎的各地疫情(全球)的数据获取及可视化,针对数据集为爬虫抓取新冠肺炎疫情数据集。
众多浏览器如何选取数据源:《新型肺炎实时疫情追踪专题,各浏览器怎么做的》.
数据来源 : 腾讯疫情追踪.
这个数据集的特征如下表所示:
| 特征名称 | 说明 |
|---|---|
| areaTree | 这个节点下面包含全世界数据,中国数据到市级的数据,是最详细的 |
| lastUpdateTime | 最后更新时间 |
| chinaTotal | 国内累计值 |
| chinaAdd | 国内每日新增 |
| confirm | 确诊 |
| heal | 治愈 |
| dead | 死亡 |
| nowConfirm | 现有确诊 |
| suspect | 疑似 |
| nowSevere | 重症 |
| chinaDayList | 每日人数汇总历史数据 |
| chinaDayAddList | 每日新增人数历史数据 |
| dailyNewAddHistory | 每日新增人数历史数据,分湖北、非湖北、全国三个维度 |
| articleList | 每日新发布新闻 |
【分析与可视化思路】
数据爬取
- 加载所需数据分析与可视化的包
import requests
import json
import pandas as pd
import warnings
import matplotlib.pyplot as plt
#导入pyecharts的包,用于数据可视化
from pyecharts.charts import Map
from pyecharts import options as opts #
%matplotlib inline
#更改设计风格 R 语言的
plt.style.use('ggplot')
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
warnings.filterwarnings('ignore')
- 爬取数据
json.loads() 用于读取字符串,即,可以把文件打开,使用readline读取一行,然后json.loads()解析一行
https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5.
https://view.inews.qq.com/g2/getOnsInfo?name=disease_other.
url_1 ='https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5' # url
def getData(url):
r = requests.get(url)
if r.status_code == 200:
return json.loads(json.loads(r.text)['data'])
data_dict = getData(url_1)
data_dict
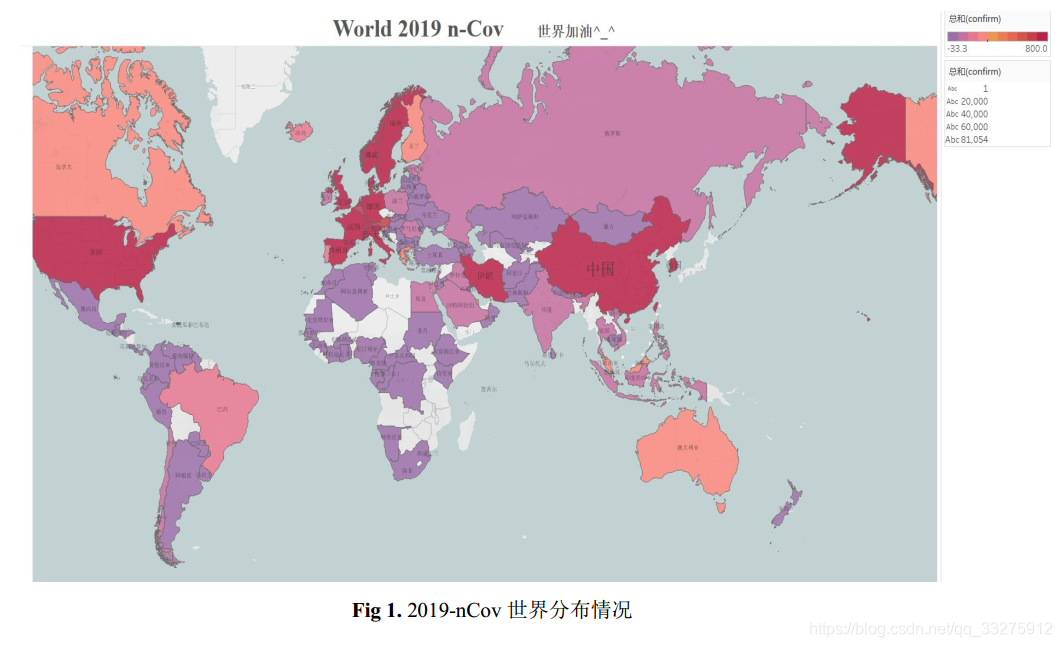
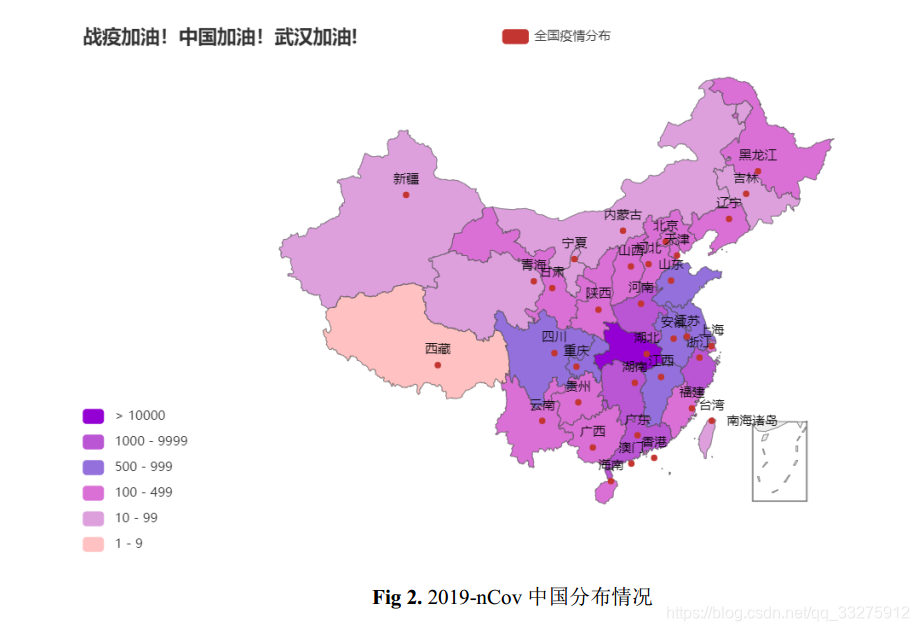
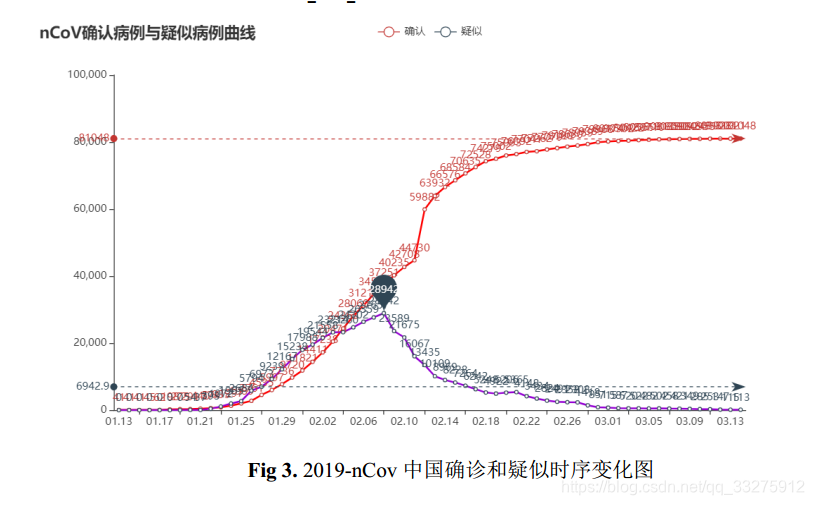
- 历史确诊 vs 历史疑似
- 这是一副 html的图,使用代码可以动态变化。

















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









