







LightRAG是港大Data Lab提出一种基于知识图谱结构的RAG方案,相比GraphRAG具有更快更经济的特点。
架构
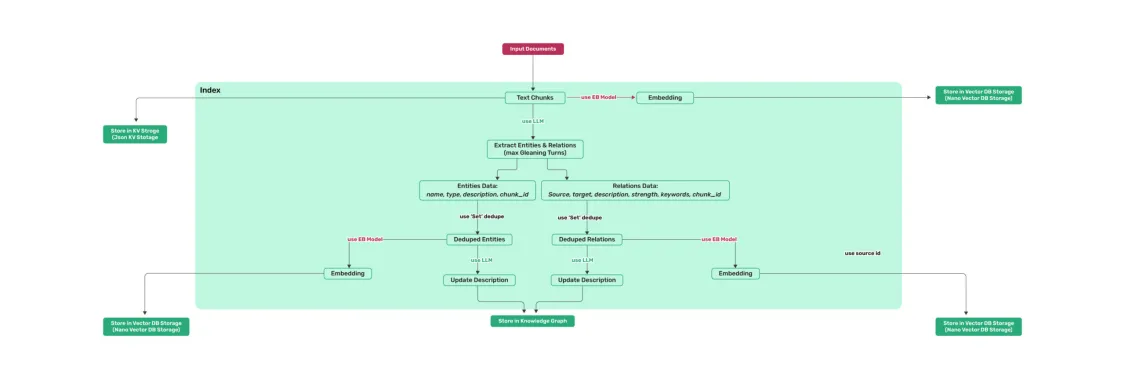
1 索引阶段:对文档进行切分处理,提取其中的实体和边分别进行向量化处理,存放在向量知识库
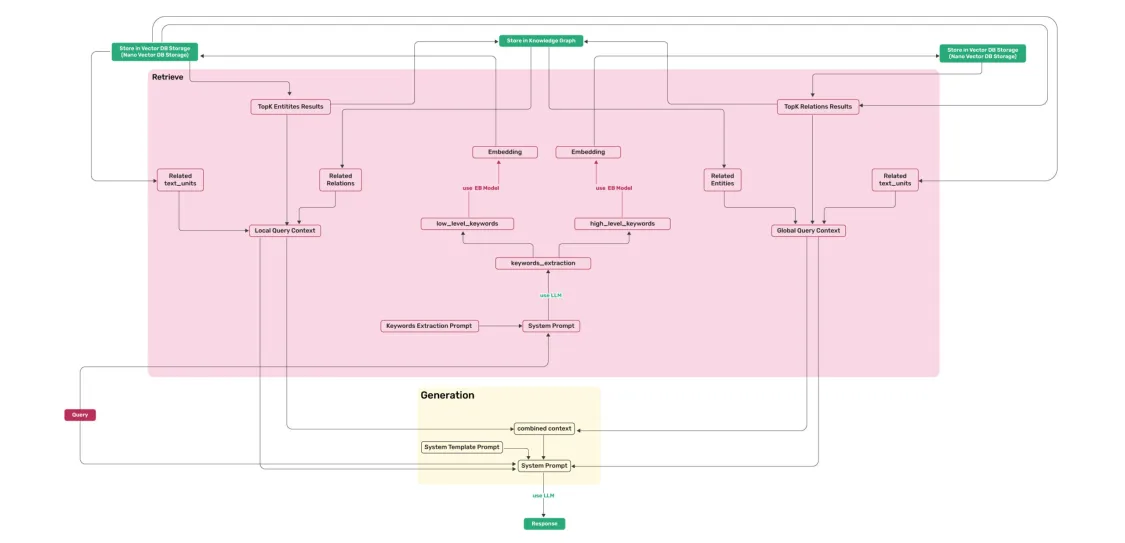
2 检索阶段:对用于输入分别提取局部和全局关键词,分别用于检索向量知识库中的实体和边关系,同时结合相关的chunk进行总结
下载方式
1 源码安装
cd LightRAG
pip install -e .
2 pypi源安装
pip install lightrag-hku
需要额外手动安装多个包,不太方便。建议从源码安装,可以直接下载所有依赖
模型支持
1 支持兼容openai规范的接口
async def llm_model_func(
prompt, system_prompt=None, history_messages=[], keyword_extraction=False, **kwargs
) -> str:
return await openai_complete_if_cache(
"solar-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key=os.getenv("UPSTAGE_API_KEY"),
base_url="https://api.upstage.ai/v1/solar",
**kwargs
)
async def embedding_func(texts: list[str]) -> np.ndarray:
return await openai_embedding(
texts,
model 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1321
1321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









