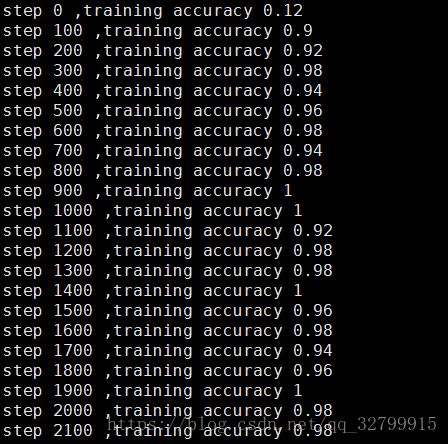
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
#定义变量
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial)
#定义偏置变量
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
#定义卷积操作
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
#定义池化操作
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#load dataset
mnist=input_data.read_data_sets("MNIST_data/",one_hot=True)
#定义输入图片变量x
x=tf.placeholder(tf.float32,[None,784])
#定义label变量y_
y_=tf.placeholder("float",[None,10])
x_image=tf.reshape(x,[-1,28,28,1])
#the first layer
W_conv1 = weight_variable([5,5,1,32])b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
#the second layer
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#the first full connection layer
W_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
#dropout
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob)
#the second full connection layer
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)
#compute loss
cross_entropy=-tf.reduce_sum(y_*tf.log(y_conv))
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction=tf.equal(tf.argmax(y_conv,1),tf.argmax(y_,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,"float"))
#初始化变量
init=tf.initialize_all_variables()
sess=tf.InteractiveSession()sess.run(init)
#迭代20000次,每100次,输出一次accuracy,batch=50
for i in range(20000):
batch=mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={ x:batch[0],y_:batch[1],keep_prob: 1.0})
print "step %d ,training accuracy %g"%(i,train_accuracy)
train_step.run(feed_dict={x:batch[0],y_:batch[1],keep_prob:0.5})#训练时keep_prob=0.5,测试时keep_prob=1.0#输出在测试集上的准确率
print "test accuracy %g" %accuracy.eval(feed_dict={x:mnist.test.images,y_:mnist.test.labels,keep_prob:0.5})










 本文介绍了一种使用TensorFlow实现的手写数字识别系统。该系统通过构建一个多层卷积神经网络来处理MNIST数据集,并详细展示了从数据加载到模型训练及评估的全过程。
本文介绍了一种使用TensorFlow实现的手写数字识别系统。该系统通过构建一个多层卷积神经网络来处理MNIST数据集,并详细展示了从数据加载到模型训练及评估的全过程。

















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









