







 本文深入探讨了逻辑回归的概念,包括Logit函数如何将线性回归预测转化为(0,1]间概率值。介绍了最大似然估计用于求解模型参数的方法,并通过性别和肿瘤大小的例子说明其应用。同时,讨论了评估模型性能的指标,如准确率、正例覆盖率和负例覆盖率,以及ROC曲线和AUC的重要性。最后提到了在Python中运用sklearn库进行逻辑回归建模的步骤。"
88128955,8254430,二维矩阵子矩形元素总和与连续子数组最大和,"['动态规划', '数组操作', '矩阵计算', '算法问题']
本文深入探讨了逻辑回归的概念,包括Logit函数如何将线性回归预测转化为(0,1]间概率值。介绍了最大似然估计用于求解模型参数的方法,并通过性别和肿瘤大小的例子说明其应用。同时,讨论了评估模型性能的指标,如准确率、正例覆盖率和负例覆盖率,以及ROC曲线和AUC的重要性。最后提到了在Python中运用sklearn库进行逻辑回归建模的步骤。"
88128955,8254430,二维矩阵子矩形元素总和与连续子数组最大和,"['动态规划', '数组操作', '矩阵计算', '算法问题']
逻辑回归
Logit函数
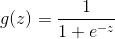
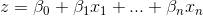
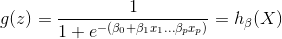
h(x)被称为logistic回归模型
将线性回归模型的预测值经过非线性的logistic函数转换为(0,1]之间的概率值,因变量取1和0的条件概率分别用h(x)和1-h(x)表示
将logistic回归模型还原成线性回归:
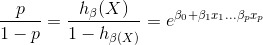
优势odds,发生比
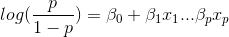
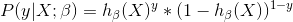
概率值是关于h(X)的函数,即事件发生的概率函数,当某个事件发生时,y=1,h(X)
1.最大似然估计
为了求解\beta,构建似然函数,统计背景:如果数据集中的每个样本都是相互独立的,则n个样本发生的联合概率就是各样本事件发生的概率乘积。
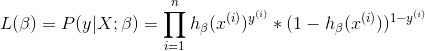
求解使目标函数达到最大的未知参数\beta
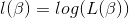
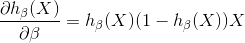
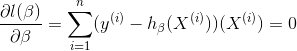
2.梯度下降
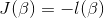
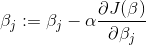
例子:
影响是否患癌有性别和肿瘤大小两个变量
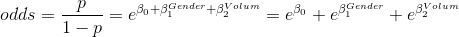
性别变量发生比率:
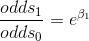
肿瘤体积发生比率:
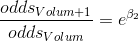
肿瘤体积每增加一个单位,使患癌发生比变化e\beta2。
混淆矩阵:
| 预测值实际值 | 良性0 | 恶性1 |
|---|---|---|
| 良性0 | A | B |
| 恶性1 | C | D |
准确率Accuracy:正确预测 / 所有
正例覆盖率Sensitivity:正确预测正例 / 实际正例
负例覆盖率Specificity:争取预测负例 / 实际负例
使用Pandas中的crosstab或者使用sklearn.metrics中的confusion_matrix
ROC曲线
x轴:1-Specificity=负例误判率
y轴:Sensitivity=正例覆盖率
折线下的面积成为AUC
使用sklearn中的roc_curve
K-S曲线
①计算score值,从大到小排列
②取出10%,20%作为score阙值,计算Sensitivity和1-Specificity
③将10%分位点绘图作为x轴,Sensitivity和1-Specificity作为y轴绘图
运用sklearn.linear_model,调用LogisticsRegression。
LogisticsRegression(penalty='l2',dual=False,tol=0.0001,c=1.,fit_intercept=True,
intercept_scaling,class_weight,random_state,solver,max_iter,
multi_class,verbose,warm_start,n_jobs 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









