







1. 文章主要内容
本文主要涉及YOLOv11目标检测模型的训练以及推理。YOLOv11模型是ultralytics的官方最新版本,新的模型更加容易发论文。通过本篇文章,可以简单、快速上手YOLOv11模型,先人一步。
2. 相关说明(部署需要的工作)
第一:YOLOv11的官方源代码链接:YOLOv11模型源码,打开github对应的官网,在绿色Code按钮上通过Download ZIP将其下载到本地,当然你也可以通过git clone直接拉取,前提是有相关的配置环境,博主这里使用的是下载到本地。
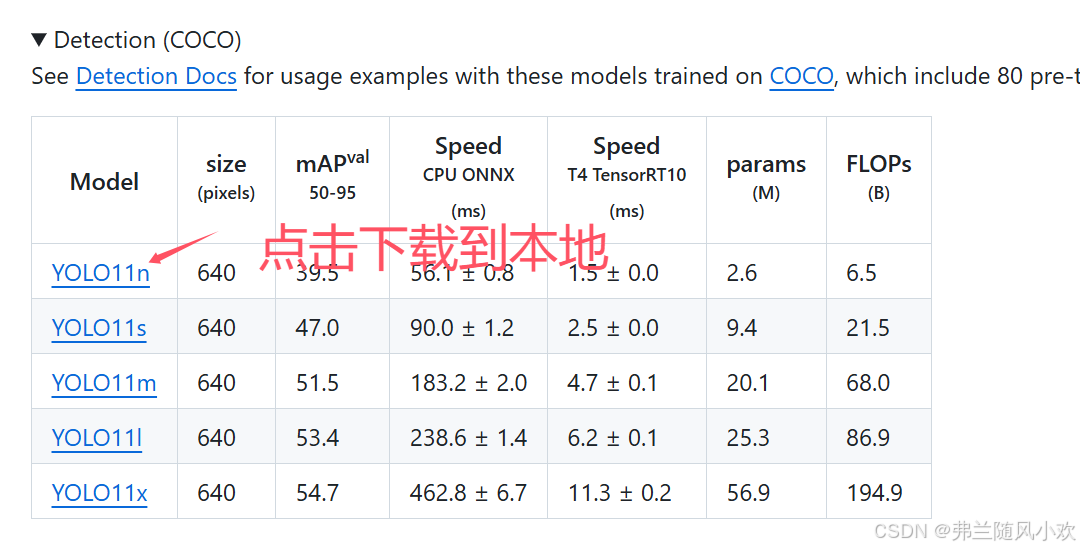
第二:然后,将github对应的官网页面往下面拉,看到一个预训练的表格,这里是YOLOv11不同大小版本对应的预训练权重,一般我们使用最多的权重是YOLOv11n.pt,也是最小的模型权重,如下图所示,点击即可下载到本地。
第三:博主这里使用的是Linux发行版本Ubuntu系统作为运行环境,工具使用的是Pycharm,这里直接通过Pycharm的SSH将本地的YOLOv11连接远程服务器Ubuntu,这样本地就能自动上传到服务器的对应位置。如果不知道如何通过Pycharm连接远程环境的,可以看我之前写的一篇详细博客,非常简单易懂,而且讨论热度高,有任何问题都可以评论区交流,基本上每天都会看。博客地址:Pycharm通过SSH远程同步项目到服务器。
第四:当你跟着上面博客走的时候,肯定已经搭建好相关的conda环境,这个时候需要再安装ultralytics,只需要执行一行代码:在项目的根目录上执行pip install ultralytics即可。另外如果报No module ultralytics 相关错误,请执行 pip install -e .这行编译代码即可解决问题。如果还缺什么相关包,请根据相关缺少包的信息,对应的进行pip install 安装即可。
3. YOLOv11检测模型训练、推理
这一块分为两个部分,第一块是启动运行部分,也就是训练部分。第二块是模型的推理过程,也就是通过训练好生成的权重,输入想检测的图片进行预测)。
3.1 模型训练(运行)
根据上面流程走下来,相关环境已经搭建好。这时候我们打开Pycharm的软件,这里我将权重文件放在了项目的根目录。
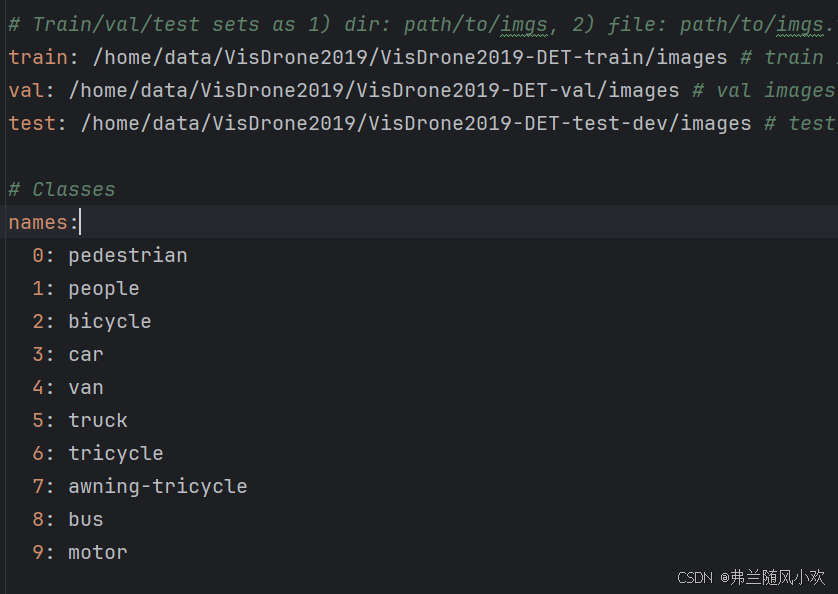
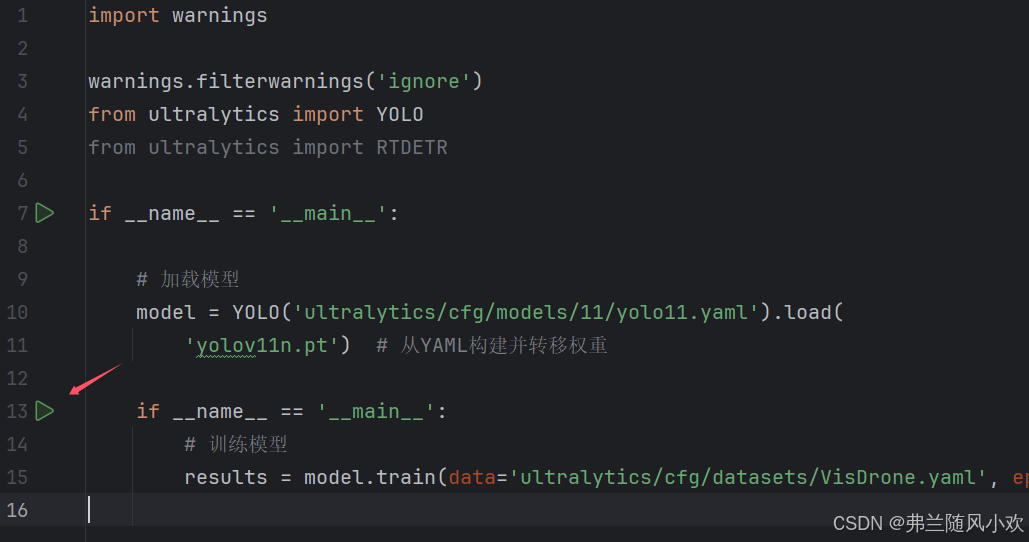
然后我自己新建了一个train.py文件,这个文件是用来启动、训练YOLOv11检测模型,源码如下所示。需要解释的是,yolov11.yaml即为YOLOv11模型的网络结构配置,默认走的是YOLOv11n的模型。另外load函数中的是权重文件,data则代表我们要训练数据集的配置文件路径。如第二幅图所示,names则代表每个类别,train、val和test则分别代码数据集存放在服务器中的路径,需要特别注意,数据集得提前存放到服务器对应的位置(自定义位置即可)
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
from ultralytics import RTDETR
if __name__ == '__main__':
# 加载模型
model = YOLO('ultralytics/cfg/models/11/yolo11.yaml').load(
'yolov11n.pt') # 从YAML构建并转移权重
if __name__ == '__main__':
# 训练模型
results = model.train(data='ultralytics/cfg/datasets/VisDrone.yaml', epochs=120, batch=16, device=[0, 1])
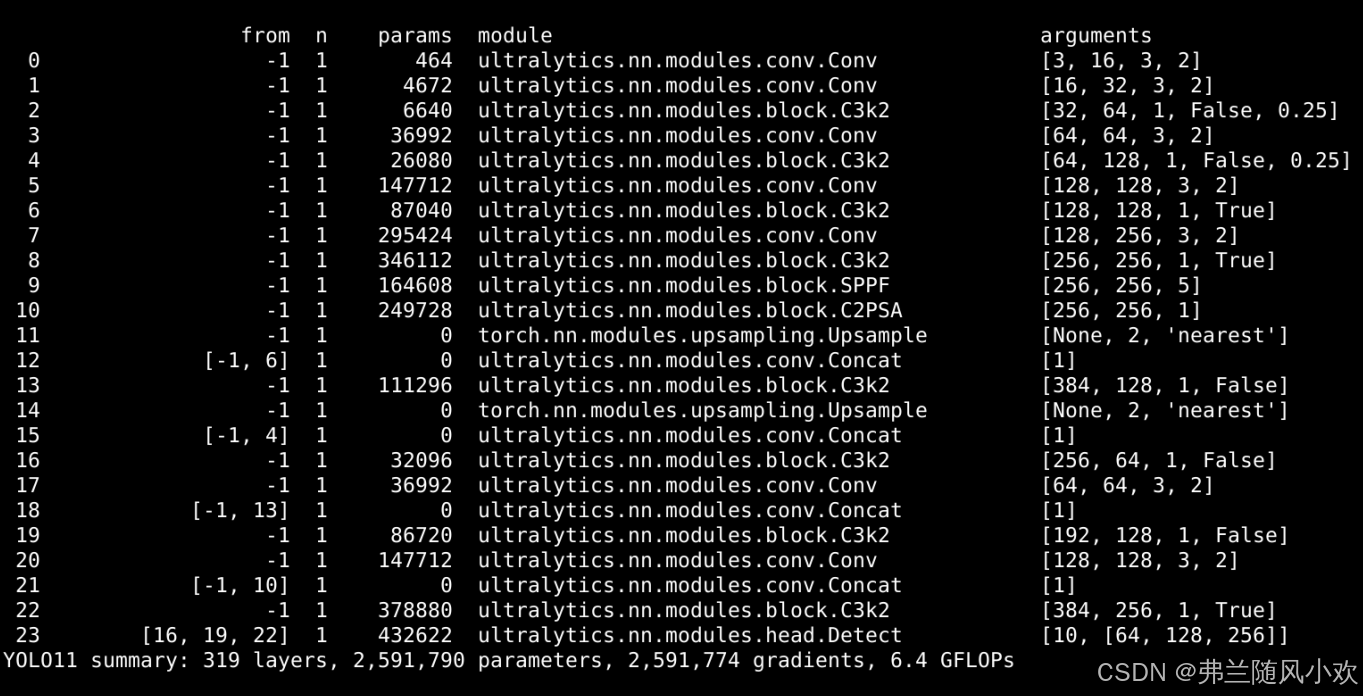
我们点击运行train.py文件左边的绿色三角形按钮即可运行YOLOv11,运行成功的示例图如下:

3.2 模型推理(预测)
模型推理即为模型预测,也就是调用predict方法,让我们训练好的模型去预测一张或者几十张图片,让其识别出图片中的目标。这里博主给出了自己写的一个predict.py文件,存放于项目的根目录中。代码如下所示:
from ultralytics import YOLO
import cv2
if __name__ == '__main__':
model_path = "/home/project/ultralytics-main/runs/detect/train/weights/best.pt"
detect_img_path = "/home/project/ultralytics-main/ultralytics/assets"
model = YOLO(model=model_path)
results = model.predict(source=detect_img_path, save=True, show=False)
for result in results:
cv2.imshow('Prediction', result.plot())
if cv2.waitKey(0) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
代码中有几个要解释的点,首先从整体来说明代码的功能:
整体含义: 将要推理的图片放入到已经训练好的模型中进行预测,运行代码后模型会产生带有标注框的图片,在键盘上按任意键(除掉q键)就可以查看下一张预测的图片,如果按了q键,则退出可视化页面,模型预测的图片保存路径一般是在runs/predict下面。
model_path: 模型训练好的权重,这里我们选择的是best.pt
detect_img_path : 想要推理的图片路径,这里我选择的是文件夹,也就是预测assest文件夹下的所有图片,当然也可以精确到每张图片,只需要将路径定位到某张图片即可。
4. 总结
本文主要讲解了YOLOv11的训练以及推理过程,希望大家能有收获,如果有任何疑问,可以评论区交流!如果可以的话,希望大家多多点赞,收藏,后续会更新相关代码和论文的解读!


















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











