







本次练习使用到的知识点
- Requsts 库的基本使用
- 正则表达式的使用
- Python3写入CSV
1、项目流程分析
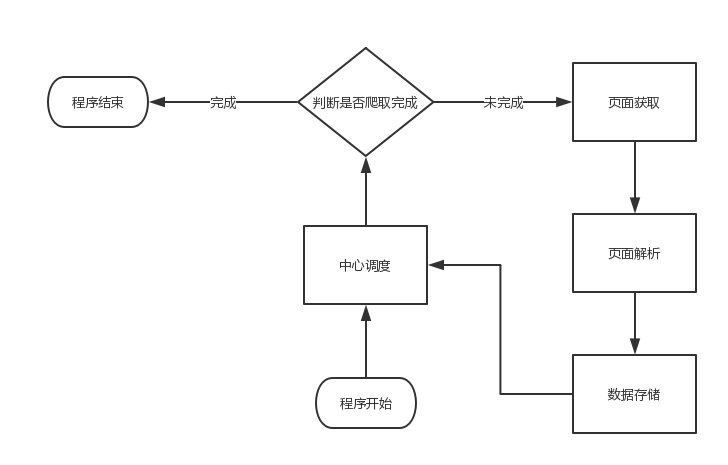
2、中心调度
# 主调度程序
defmain():
#
起始URL
start_url ='http://maoyan.com/board/4'
for
i in range(0,100,10):
#
获取响应文本内容
html = get_one_page(url=start_url, offset=i)
if
html isNone:
print('链接:%s?offset=%s异常'.format(start_url,i))
continue
for
item in parse_one_page(html=html):
store_data(item)
download_thumb(item['title'],item['thumb'])
3、页面内容获取
# 请求一个页面返回响应内容
defget_one_page(url,
offset):
try:
response = requests.get(url=url,params={'offset':offset})
if
response.status_code == 200:
return
response.text
else:
returnNone
except
RequestException as e:
returnNone
4、页面解析
#解析一个页面
defparse_one_page(html):
pattern ='<dd>.*?board-index.*?">(\d+)</i>.*?data-src="(.*?)".*?/>.*?movie-item-info.*?title="(.*?)".*?star">'+\
'(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(\d+)</i>.*?</dd>'
#
re.S匹配多行
regex
= re.compile(pattern,re.S)
items = regex.findall(html)
foriteminitems:
yield{
'index':item[0],
'thumb':get_large_thumb(item[1]),
'title':item[2],
'actors':item[3].strip()[3:],
'release_time':get_release_time(item[4].strip()[5:]),
'area':get_release_area(item[4].strip()[5:]),
'score':item[5]+item[6]
}
5、数据处理函数
#获取上映时间
defget_release_time(data):
pattern ='^(.*?)(\(|$)'
regex
= re.compile(pattern)
w = regex.search(data)
returnw.group(1)
#获取上映地区
defget_release_area(data):
pattern ='.*\((.*)\)'
regex
= re.compile(pattern)
w = regex.search(data)
ifwisNone:
return'未知'
returnw.group(1)
#获取封面大图
defget_large_thumb(url):
pattern ='(.*?)@.*?'
regex
= re.compile(pattern)
w = regex.search(url)
returnw.group(1)
6、数据存储
#存储数据
defstore_data(item):
withopen('movie.csv','a',newline='',encoding='utf-8')asdata_csv:
#
dialect为打开csv文件的方式,默认是excel,delimiter="\t"参数指写入的时候的分隔符
try:
csv_writer = csv.writer(data_csv)
csv_writer.writerow([item['index'],
item['thumb'],
item['title'],
item['actors'],item['release_time'],item['area'],item['score']])
exceptExceptionase:
print(e)
print(item)
# 下载封面图
defdownload_thumb(title,url):
try:
response = requests.get(url=url)
#
获取二进制数据
with
open('thumb/'+title+'.jpg','wb')as
f:
f.write(response.content)
f.close()
except
RequestException as e:
print(e)
pass
7、完整运行代码
#!/usr/bin/python
# -*- coding: utf-8 -*-
importrequests
importre
importcsv
fromrequests.exceptionsimportRequestException
#请求一个页面返回响应内容
defget_one_page(url,
offset):
try:
response = requests.get(url=url,params={'offset':offset})
ifresponse.status_code
==200:
returnresponse.text
else:
returnNone
exceptRequestExceptionase:
returnNone
#解析一个页面
defparse_one_page(html):
pattern ='<dd>.*?board-index.*?">(\d+)</i>.*?data-src="(.*?)".*?/>.*?movie-item-info.*?title="(.*?)".*?star">'+\
'(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(\d+)</i>.*?</dd>'
#
re.S匹配多行
regex
= re.compile(pattern,re.S)
items = regex.findall(html)
foriteminitems:
yield{
'index':item[0],
'thumb':get_large_thumb(item[1]),
'title':item[2],
'actors':item[3].strip()[3:],
'release_time':get_release_time(item[4].strip()[5:]),
'area':get_release_area(item[4].strip()[5:]),
'score':item[5]+item[6]
}
#获取上映时间
defget_release_time(data):
pattern ='^(.*?)(\(|$)'
regex
= re.compile(pattern)
w = regex.search(data)
returnw.group(1)
#获取上映地区
defget_release_area(data):
pattern ='.*\((.*)\)'
regex
= re.compile(pattern)
w = regex.search(data)
ifwisNone:
return'未知'
returnw.group(1)
#获取封面大图
defget_large_thumb(url):
pattern ='(.*?)@.*?'
regex
= re.compile(pattern)
w = regex.search(url)
returnw.group(1)
#存储数据
defstore_data(item):
withopen('movie.csv','a',newline='',encoding='utf-8')asdata_csv:
#
dialect为打开csv文件的方式,默认是excel,delimiter="\t"参数指写入的时候的分隔符
try:
csv_writer = csv.writer(data_csv)
csv_writer.writerow([item['index'],
item['thumb'],
item['title'],
item['actors'],item['release_time'],item['area'],item['score']])
exceptExceptionase:
print(e)
print(item)
#下载封面图
defdownload_thumb(title,url):
try:
response = requests.get(url=url)
#获取二进制数据
withopen('thumb/'+title+'.jpg','wb')asf:
f.write(response.content)
f.close()
exceptRequestExceptionase:
print(e)
pass
#主调度程序
defmain():
#起始URL
start_url
= 'http://maoyan.com/board/4'
foriinrange(0,100,10):
#获取响应文本内容
html
= get_one_page(url=start_url,offset=i)
ifhtmlisNone:
print('链接:%s?offset=%s异常'.format(start_url,i))
continue
foriteminparse_one_page(html=html):
store_data(item)
download_thumb(item['title'],item['thumb'])
if__name__=='__main__':
main()
8、运行结果



















 1873
1873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









