






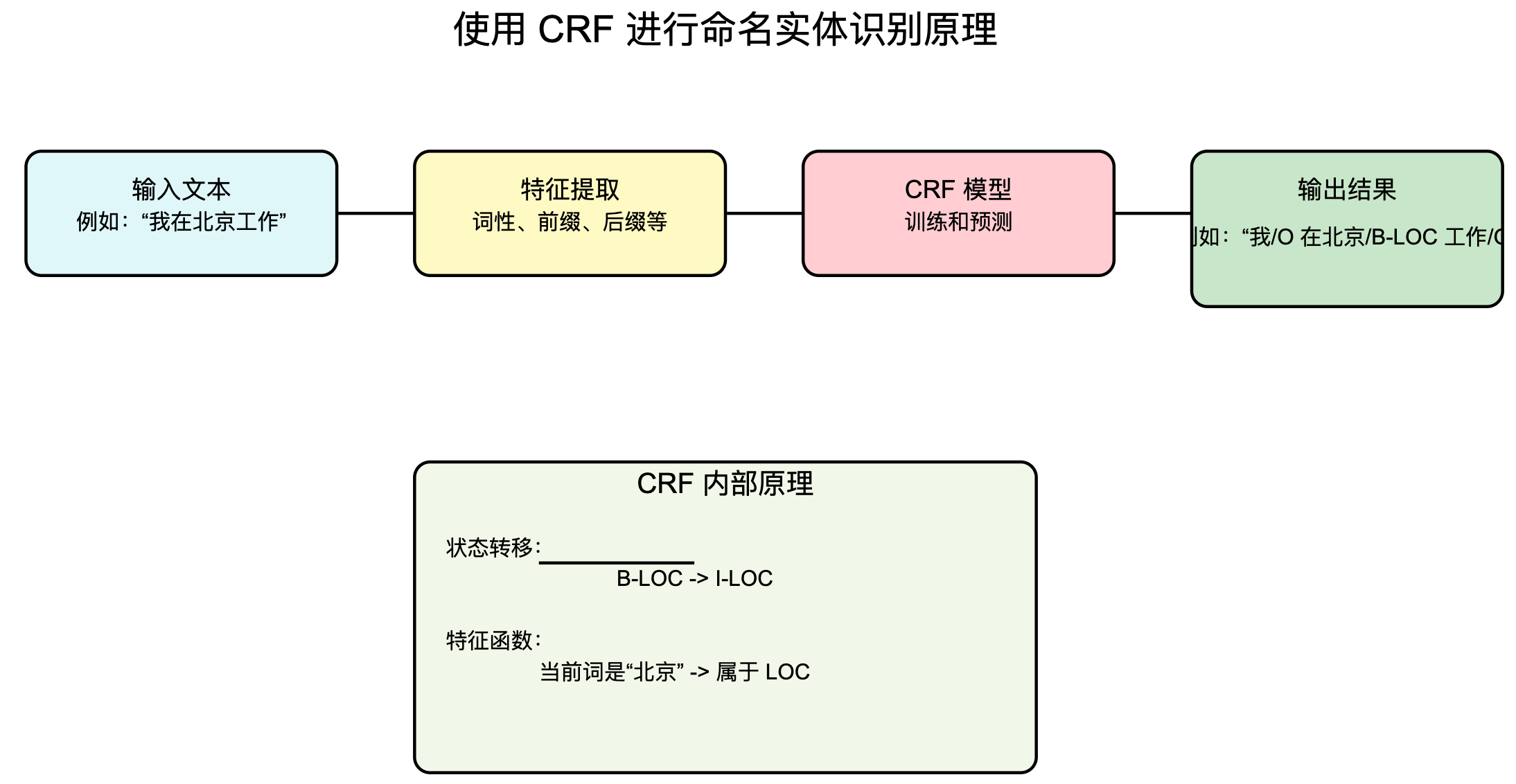
基于新闻事件的命名实体抽取
目标
本文基于给定的词表,将输入的文本基于jieba分词分割为若干个词,然后基于词表将词序列化处理,之后经过若干网络层,最后输出在已知命名实体标注类别标签上的概率分布,从而实现一个简单新闻事件的命名实体识别。
数据准备
词表文件chars.txt
类别标签文件schema.json
{
"B-LOCATION": 0,
"B-ORGANIZATION": 1,
"B-PERSON": 2,
"B-TIME": 3,
"I-LOCATION": 4,
"I-ORGANIZATION": 5,
"I-PERSON": 6,
"I-TIME": 7,
"O": 8
}
本文主要提取新闻事件中时间(TIME)、地点(LOCATION)、机构(ORGANIZATION)、人名(PERSON)这四类实体,实体的开始大写字母以B 表示,实体的中间部分及结尾以大写字母I表示。标签文件中的每个key表示实体标注的类别,总共9个类别,因此本次任务分类类别为9,而value对应的索引值可作为分类的标签使用,新闻事件文本中的文本可作为词向量的输入文本。如果文本字符串中出现一个同类别的B后面跟着多个同类别的I,则表示存在着一个实体。比如,B-PERSON I-PERSON I-PERSON表示一个人名,如果后面跟着不是同类别的则不是一个实体,比如,B-PERSON I-LOCATION I-LOCATION,具体的可看数据集。这个在后续词向量预测的标签解码时可用到。
训练集数据train.txt训练集数据
测试集数据test.txt测试集数据
参数配置
config.py
# -*- coding: utf-8 -*-
"""
配置参数信息
"""
Config = {
"model_path": "model_output",
"schema_path": "ner_data/schema.json",
"train_data_path": "ner_data/train.txt",
"valid_data_path": "ner_data/test.txt",
"vocab_path":"chars.txt",
"max_length": 100,
"hidden_size": 256,
"num_layers": 2,
"epoch": 20,
"batch_size": 16,
"optimizer": "adam",
"learning_rate": 1e-3,
"use_crf": True,
"class_num": 9,
"bert_path": r"../../../bert-base-chinese"
}
配置文件主要是针对一个 命名实体识别(NER) 模型的训练和验证过程,包含了很多超参数设置、文件路径配置和模型相关的参数。通过调整这些参数,可以控制模型的结构、训练过程、优化方法以及输入数据的处理方式。
数据处理
loader.py
# -*- coding: utf-8 -*-
import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader
"""
数据加载
"""
class DataGenerator:
def __init__(self, data_path, config):
self.config = config
self.path = data_path
self.vocab = load_vocab(config["vocab_path"])
self.config["vocab_size"] = len(self.vocab)
self.sentences = []
self.schema = self.load_schema(config["schema_path"])
self.load()
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
segments = f.read().split("\n\n")
for segment in segments:
sentenece = []
labels = []
for line in segment.split("\n"):
if line.strip() == "":
continue
char, label = line.split()
sentenece.append(char)
labels.append(self.schema[label])
self.sentences.append("".join(sentenece))
input_ids = self.encode_sentence(sentenece)
labels = self.padding(labels, -1)
self.data.append([torch.LongTensor(input_ids), torch.LongTensor(labels)])
return
def encode_sentence(self, text, padding=True):
input_id = []
if self.config["vocab_path"] == "words.txt":
for word in jieba.cut(text):
input_id.append(self.vocab.get(word, self.vocab["[UNK]"]))
else:
for char in text:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
if padding:
input_id = self.padding(input_id)
return input_id
#补齐或截断输入的序列,使其可以在一个batch内运算
def padding(self, input_id, pad_token=0):
input_id = input_id[:self.config["max_length"]]
input_id += [pad_token] * (self.config["max_length"] - len(input_id))
return input_id
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
def load_schema(self, path):
with open(path, encoding="utf8") as f:
return json.load(f)
#加载字表或词表
def load_vocab(vocab_path):
token_dict = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
token = line.strip()
token_dict[token] = index + 1 #0留给padding位置,所以从1开始
return token_dict
#用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):
dg = DataGenerator(data_path, config)
dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dl
DataGenerator类实现了一个数据加载器,负责从文件中读取数据,进行必要的处理(如分词、编码、填充等),并将其转化为torch.LongTensor格式,最终返回给模型进行训练。load_vocab函数和load_schema函数分别负责加载词汇表和标签映射文件,确保在模型训练过程中可以正确地进行字符或词汇到索引的转换。load_data函数将DataGenerator封装进DataLoader,以便进行批次处理,适配模型训练的需要。
以下是对文件中各个部分的详细解释:
DataGenerator 类负责从数据文件中加载文本和标签,并进行处理,最终生成适合用于模型训练的数据。
类初始化
- 作用:初始化
DataGenerator实例,加载配置和词汇表,设置句子列表以及标签映射。 data_path: 数据文件路径,包含了要加载的训练数据。config: 配置字典,包含各种超参数设置和路径配置。vocab: 通过调用load_vocab函数加载的词汇表。sentences: 存储所有句子的列表。schema: 存储标签映射(从标签到数字值的映射),通过调用load_schema加载。self.load(): 调用load()方法加载数据。
数据读取load
- 作用:读取数据文件并将每个句子和标签对加载到内存中。
- 步骤:
- 通过
open(self.path, encoding="utf8")打开数据文件,读取数据。 - 将数据按双换行分割成多个段落(每个段落表示一个句子及其标签)。
- 对每一行,提取字符和其对应的标签,并将标签转换为数字。
- 通过
encode_sentence方法将每个字符转换为词汇表中的索引。 - 使用
padding方法对标签进行填充或截断,使其符合模型输入要求。 - 每个句子及其对应的标签对存储为一个
LongTensor,存放到self.data列表中。
- 通过
文本编码encode
- 作用:将输入的文本(句子)转换为词汇表中对应的索引列表。
- 步骤:
- 如果词汇表是按词切分(
vocab_path == "words.txt"),则使用jieba.cut将句子分词。 - 如果词汇表是按字符切分,则逐字符遍历文本。
- 每个词或字符根据词汇表转换为对应的索引。如果词汇表中没有该词/字符,则使用
[UNK](未知符号)作为默认值。 - 如果
padding为True,则调用padding方法对输入序列进行填充,使得所有输入具有相同的长度。
- 如果词汇表是按词切分(
序列对齐padding
- 作用:对输入的序列进行填充或截断,确保其长度符合
max_length的要求。 - 步骤:
- 截断序列,确保其长度不超过
max_length。 - 如果序列长度小于
max_length,则使用pad_token填充直到长度为max_length。
- 截断序列,确保其长度不超过
__len__(self)
- 作用:返回数据集的大小,即数据中包含的样本数。
__getitem__(self, index)
- 作用:返回指定索引的数据项,每个数据项是一个包含输入数据和标签的元组(
LongTensor)。
标签映射load_schema
- 作用:加载标签映射文件,将标签从字符串映射到整数值。
- 步骤:从指定的 JSON 文件加载标签的映射,通常用于将每个标签(如
PER,LOC等)映射到一个整数值。
加载词汇表load_vocab
- 作用:加载词汇表,将每个词或字符映射到一个唯一的整数索引。
- 步骤:
- 打开词汇表文件,逐行读取词汇表中的词语。
- 将每个词汇映射到一个唯一的索引,索引从 1 开始,0 留给 padding 位置。
- 返回一个字典
token_dict,将每个词汇映射到对应的索引。
加载数据封装
- 作用:用
DataGenerator类加载数据,并返回一个DataLoader实例。 - 步骤:
- 创建一个
DataGenerator实例来加载数据。 - 使用
DataLoader封装DataGenerator,并设置批次大小(batch_size)和是否打乱数据(shuffle)。 - 返回封装好的
DataLoader,用于模型训练时按批次加载数据。
- 创建一个
模型构建
model.py
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from torchcrf import CRF
"""
建立网络模型结构
"""
class TorchModel(nn.Module):
def __init__(self, config):
super(TorchModel, self).__init__()
hidden_size = config["hidden_size"]
vocab_size = config["vocab_size"] + 1
max_length = config["max_length"]
class_num = config["class_num"]
num_layers = config["num_layers"]
self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)
self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True, num_layers=num_layers)
self.classify = nn.Linear(hidden_size * 2, class_num)
self.crf_layer = CRF(class_num, batch_first=True)
self.use_crf = config["use_crf"]
self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) #loss采用交叉熵损失
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, target=None):
x = self.embedding(x) #input shape:(batch_size, sen_len)
x, _ = self.layer(x) #input shape:(batch_size, sen_len, input_dim)
predict = self.classify(x) #ouput:(batch_size, sen_len, num_tags) -> (batch_size * sen_len, num_tags)
if target is not None:
if self.use_crf:
mask = target.gt(-1)
return - self.crf_layer(predict, target, mask, reduction="mean")
else:
#(number, class_num), (number)
return self.loss(predict.view(-1, predict.shape[-1]), target.view(-1))
else:
if self.use_crf:
return self.crf_layer.decode(predict)
else:
return predict
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)
网络结构主要定义了一个用于序列标注任务的神经网络模型 TorchModel,并提供了一个选择优化器的函数 choose_optimizer。下面是各个部分的详细解释:
自定义模型
该类继承自 torch.nn.Module,用于定义一个深度学习模型,模型的结构包括嵌入层、LSTM 层、分类层和 CRF 层,具体的作用如下:
类初始化
- 作用:初始化模型的各个层和相关配置。
- 参数:
config: 配置字典,包含了各个超参数设置,如隐藏层大小、词汇表大小、类别数目等。
- 操作:
self.embedding: 嵌入层(nn.Embedding),用于将词汇表中的每个单词映射为一个固定大小的向量。其大小为vocab_size(词汇表大小)和hidden_size(隐藏层的大小)。padding_idx=0表示0索引的位置为填充符号(padding),即输入序列较短时使用的填充值。self.layer: 双向 LSTM 层(nn.LSTM),将输入的嵌入向量进行编码。batch_first=True表示输入的第一个维度是批次大小,bidirectional=True表示 LSTM 为双向 LSTM,num_layers控制 LSTM 的层数。self.classify: 全连接层(nn.Linear),将 LSTM 输出的隐藏状态映射到标签类别空间。由于是双向 LSTM,输入的维度为hidden_size * 2(双向),输出的维度为class_num(类别数)。self.crf_layer: CRF 层(torchcrf.CRF),用于进行条件随机场(CRF)解码,帮助提高序列标注的准确性,特别是处理标签之间的依赖关系。self.use_crf: 一个布尔值,表示是否使用 CRF 层。如果True,则在训练过程中使用 CRF;否则使用传统的交叉熵损失。self.loss: 损失函数,使用交叉熵损失(torch.nn.CrossEntropyLoss),并且忽略标签为-1的位置(通常用于 padding 的位置)。
条件随机场
- 条件随机场(CRF):条件随机场是一种用于标注和分割序列数据的模型,它能够建模标签之间的依赖关系。在传统的序列标注任务中,每个标签通常是独立预测的,这忽略了标签之间的潜在关系。而 CRF 层能够通过建模标签间的依赖性来优化整体标签序列,从而提高序列标注的准确性。
CRF 的关键矩阵:
-
发射矩阵(Emission Matrix):
- 发射矩阵是从输入到标签的概率分布。它定义了给定输入的每个时间步(如单词或字)的某个标签的发射概率。
- 发射矩阵通常表示为
E
E
E,其中
E
t
,
y
E_{t, y}
Et,y 表示在时间步 ( t ) 时,将输入序列的第
t
t
t 个元素分配给标签
y
y
y 的概率。
- 例如,假设有一个命名实体识别(NER)任务,输入是一个词汇序列,每个词汇有一个发射概率分配给每个可能的标签(如
B-PERSON,I-PERSON,O等)。
- 例如,假设有一个命名实体识别(NER)任务,输入是一个词汇序列,每个词汇有一个发射概率分配给每个可能的标签(如
- 在 CRF 层中,发射矩阵的计算可以通过 LSTM 或其他编码器的输出得到,例如:
E t , y = softmax ( W emission h t ) E_{t, y} = \text{softmax}(W_{\text{emission}} h_t) Et,y=softmax(Wemissionht)
其中 h t h_t ht 是 LSTM 输出的隐藏状态, W emission W_{\text{emission}} Wemission是一个映射到标签空间的矩阵。
-
转移矩阵(Transition Matrix):
- 转移矩阵定义了标签之间的转换概率,表示从一个标签到另一个标签的概率。
- 这个矩阵通常表示为
T
T
T,其中
T
y
′
y
T_{y' y}
Ty′y表示从标签
y
′
y'
y′转换到标签
y
y
y的概率。
- 例如,在命名实体识别任务中,标签序列中
B-PERSON后面可能更倾向于出现I-PERSON,而不太可能出现B-LOCATION。
- 例如,在命名实体识别任务中,标签序列中
- 转移矩阵有助于 CRF 层捕捉标签间的依赖关系,提高模型的预测一致性和准确性。
CRF 的损失函数:
在 CRF 中,损失函数的目标是最大化给定输入序列和对应标签序列的条件概率。具体来说,CRF 层的损失函数涉及到两个部分:分子和 分母。
-
分子:正确标签序列的条件概率:
- 假设我们有一个输入序列
x
=
(
x
1
,
x
2
,
.
.
.
,
x
T
)
x = (x_1, x_2, ..., x_T)
x=(x1,x2,...,xT),对应的正确标签序列为
y
=
(
y
1
,
y
2
,
.
.
.
,
y
T
)
y = (y_1, y_2, ..., y_T)
y=(y1,y2,...,yT),那么模型输出的条件概率为:
P ( y ∣ x ) = exp ( score ( x , y ) ) Z ( x ) P(y | x) = \frac{\exp(\text{score}(x, y))}{Z(x)} P(y∣x)=Z(x)exp(score(x,y))
其中, score ( x , y ) \text{score}(x, y) score(x,y) 是标签序列 y y y 在输入序列 x x x 下的评分, Z ( x ) Z(x) Z(x) 是归一化因子(也叫做分区函数),确保概率的总和为 1。
- 假设我们有一个输入序列
x
=
(
x
1
,
x
2
,
.
.
.
,
x
T
)
x = (x_1, x_2, ..., x_T)
x=(x1,x2,...,xT),对应的正确标签序列为
y
=
(
y
1
,
y
2
,
.
.
.
,
y
T
)
y = (y_1, y_2, ..., y_T)
y=(y1,y2,...,yT),那么模型输出的条件概率为:
-
分子评分函数:标签序列的评分函数:
- 标签序列的评分函数
score
(
x
,
y
)
\text{score}(x, y)
score(x,y) 是由发射矩阵和转移矩阵共同决定的。具体而言,可以通过以下公式计算:
score ( x , y ) = ∑ t = 1 T ( log E t , y t ) + ∑ t = 2 T log T y t − 1 , y t \text{score}(x, y) = \sum_{t=1}^{T} \left( \log E_{t, y_t} \right) + \sum_{t=2}^{T} \log T_{y_{t-1}, y_t} score(x,y)=t=1∑T(logEt,yt)+t=2∑TlogTyt−1,yt
其中, E t , y t E_{t, y_t} Et,yt是第 t t t个时间步,标签 y t y_t yt的发射概率, T y t − 1 , y t T_{y_{t-1}, y_t} Tyt−1,yt是从标签 y t − 1 y_{t-1} yt−1到标签 y t y_t yt的转移概率。
- 标签序列的评分函数
score
(
x
,
y
)
\text{score}(x, y)
score(x,y) 是由发射矩阵和转移矩阵共同决定的。具体而言,可以通过以下公式计算:
-
分母:所有可能标签序列的条件概率之和:
- 为了对概率进行归一化,我们需要计算所有可能标签序列的总评分,即计算分区函数
Z
(
x
)
Z(x)
Z(x):
Z ( x ) = ∑ y ′ exp ( score ( x , y ′ ) ) Z(x) = \sum_{y'} \exp(\text{score}(x, y')) Z(x)=y′∑exp(score(x,y′))
其中 y ′ y' y′ 遍历所有可能的标签序列。由于标签序列的数量非常庞大(尤其是在标签空间大的情况下),计算 Z ( x ) Z(x) Z(x)是一个相当昂贵的操作,通常使用 前向后向算法(Forward-Backward Algorithm)来高效地计算。
- 为了对概率进行归一化,我们需要计算所有可能标签序列的总评分,即计算分区函数
Z
(
x
)
Z(x)
Z(x):
-
负对数似然损失:
- 在训练过程中,我们通过最大化正确标签序列的条件概率,最小化负对数似然损失(
Negative Log-Likelihood Loss)。损失函数定义为:
L = − log P ( y ∣ x ) = − log exp ( score ( x , y ) ) Z ( x ) = − score ( x , y ) + log Z ( x ) \mathcal{L} = - \log P(y | x) = - \log \frac{\exp(\text{score}(x, y))}{Z(x)} = - \text{score}(x, y) + \log Z(x) L=−logP(y∣x)=−logZ(x)exp(score(x,y))=−score(x,y)+logZ(x)
其中,第一项 − score ( x , y ) - \text{score}(x, y) −score(x,y) 是正确标签序列的评分,第二项 log Z ( x ) \log Z(x) logZ(x)是归一化常数,确保概率的总和为 1。这个损失函数通过优化标签序列的评分来提高模型的预测能力。
- 在训练过程中,我们通过最大化正确标签序列的条件概率,最小化负对数似然损失(
CRF 层的作用:
-
在序列标注任务中,如命名实体识别(NER)或词性标注(POS)等,CRF 层通过考虑标签之间的转移概率,帮助模型输出更加一致的标签序列。例如,标签
B-PERSON后通常会跟随I-PERSON,而不是B-LOCATION,CRF 可以有效地捕捉到这种标签间的关系。 -
CRF 层将输入的每个时间步的标签与相邻标签之间的依赖关系建模,并且通过最大化条件概率来优化标签的序列预测。在有 CRF 层的模型中,损失函数不仅考虑了单个标签的预测结果,还综合考虑了整个标签序列的合理性。
-
训练时的区别:
- 当
self.use_crf设置为True时,模型将使用 CRF 层进行解码,这意味着在训练过程中,模型不仅依赖于 LSTM 的输出,还通过 CRF 层学习标签之间的关系,并通过最大化全局条件概率来优化标签序列。 - 如果
self.use_crf为False,则模型将不使用 CRF 层,而是使用传统的交叉熵损失进行训练,预测标签时不考虑标签之间的依赖关系。
- 当
CRF 层的优势:
- 增强标签依赖关系建模:CRF 层通过全局优化标签序列,使得输出标签序列在局部和全局范围内更加一致和准确。
- 解决标注冲突问题:对于一些复杂的标注任务,传统的交叉熵损失可能无法有效解决标签冲突或不一致问题,而 CRF 层能够通过建模标签间的转移概率来避免这种情况。
通过在模型中集成 CRF 层,我们可以更好地利用序列数据中的标签依赖关系,提高模型在序列标注任务中的表现。
前向传播
- 作用:定义前向传播的计算过程。
- 参数:
x: 输入数据,形状为(batch_size, sen_len),即一个批次的句子,每个句子由若干个词汇或字符的索引组成。target: 真实标签,形状为(batch_size, sen_len),包含每个单词或字符的标签索引。target只有在训练时需要传入,进行计算损失时使用。
- 操作:
x = self.embedding(x):通过嵌入层将输入的词汇索引转换为嵌入向量。x, _ = self.layer(x):通过LSTM层处理输入数据,x变成形状(batch_size, sen_len, hidden_size * 2)(双向 LSTM 的输出)。predict = self.classify(x):通过全连接层将LSTM的输出映射到标签空间,得到形状为(batch_size, sen_len, class_num)的输出。
接下来根据是否提供了真实标签来决定返回值:
- 如果有真实标签
target:- 如果使用了 CRF (
self.use_crf=True),则计算 CRF 层的损失,mask是一个布尔型张量,标记哪些位置需要计算损失(通常是忽略 padding 部分)。 - 如果没有使用 CRF,则通过交叉熵损失计算模型输出与目标标签之间的差异。
- 如果使用了 CRF (
- 如果没有真实标签
target(即在预测时):- 如果使用了 CRF,则返回通过 CRF 解码得到的预测结果。
- 否则,返回模型的原始预测结果。
优化器配置
- 作用:根据配置选择合适的优化器。
- 参数:
config: 配置字典,包含优化器类型和学习率。model: 需要优化的模型。
- 操作:
- 从
config中获取优化器类型(optimizer)和学习率(learning_rate)。 - 如果选择的是
adam,则使用Adam优化器。 - 如果选择的是
sgd,则使用SGD优化器。 - 返回相应的优化器实例。
- 从
网络模型总结
- 模型结构:
- 词嵌入层将词汇索引转换为向量表示。
- 双向 LSTM 层处理序列信息,捕捉前后依赖关系。
- 全连接层将 LSTM 的输出映射到标签空间。
- 可选的 CRF 层(条件随机场)进一步增强序列标注的准确性,特别是考虑标签之间的依赖关系。
- 交叉熵损失用于训练,若使用 CRF,则通过 CRF 进行损失计算。
- 选择优化器:根据配置选择合适的优化器(Adam 或 SGD)。
这种模型结构通常用于序列标注任务,如命名实体识别(NER),依赖句法分析等,需要处理标签之间有依赖关系的任务。
主程序
main.py
# -*- coding: utf-8 -*-
import torch
import os
import random
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
"""
模型训练主程序
"""
def main(config):
#创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])
#加载训练数据
train_data = load_data(config["train_data_path"], config)
#加载模型
model = TorchModel(config)
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()
#加载优化器
optimizer = choose_optimizer(config, model)
#加载效果测试类
evaluator = Evaluator(config, model, logger)
#训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
optimizer.zero_grad()
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data
loss = model(input_id, labels)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
evaluator.eval(epoch)
model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)
torch.save(model.state_dict(), model_path)
return model, train_data
if __name__ == "__main__":
model, train_data = main(Config)
main函数是程序的入口点,通过 main(Config) 启动训练过程。Config 类包含模型训练所有必要的超参数和文件路径。整个训练流程包括以下主要步骤:
- 数据加载:准备训练数据。
- 模型创建:初始化模型,准备训练。
- 训练过程:包括前向传播、损失计算、反向传播、优化。
- 评估:每个 epoch 后评估模型效果。
- 模型保存:每个 epoch 后保存模型的权重。
主程序详解
-
创建模型保存目录:
- 该步骤通过
os.makedirs(config.save_path, exist_ok=True)确保模型的保存路径存在。如果目录不存在,makedirs会创建它。exist_ok=True参数确保如果路径已存在,不会抛出错误。
- 该步骤通过
-
加载数据:
- 使用
load_data(config)函数加载训练数据。这通常会返回训练集和验证集,可能包括数据的预处理步骤(如数据增强、归一化等)。config中会包含数据路径、批次大小等配置。
- 使用
-
初始化模型:
model = TorchModel(config)创建了一个深度学习模型的实例。TorchModel是一个自定义的类,通常会继承自 PyTorch 的nn.Module,并根据配置config来初始化模型的结构、超参数等。
-
检查 GPU 并迁移模型:
- 判断是否有 GPU 可用,如果有,则将模型迁移到 GPU 上。具体通过
torch.device("cuda" if torch.cuda.is_available() else "cpu")来判断,并使用model.to(device)将模型移到 GPU 或 CPU 上。
- 判断是否有 GPU 可用,如果有,则将模型迁移到 GPU 上。具体通过
-
加载优化器:
- 选择优化器并进行初始化。通常是使用
torch.optim提供的优化器,如 Adam 或 SGD。优化器需要模型的参数以及学习率等超参数,在main(config)中,通过配置文件中的参数来选择优化器。 optimizer = torch.optim.Adam(model.parameters(), lr=config.lr)这种形式通常用来初始化一个 Adam 优化器。
- 选择优化器并进行初始化。通常是使用
-
初始化评估器:
- 创建评估器
evaluator = Evaluator(config),用于在每个 epoch 结束时评估模型的性能。评估器可能计算诸如准确率、精度、召回率等指标来评估模型的效果。
- 创建评估器
-
训练过程:
- 进入训练循环,每个 epoch 会经历以下步骤:
- 遍历训练批次:对于每个训练批次,模型会进行前向传播计算预测值,计算损失(通常是交叉熵或 MSE),并进行反向传播以更新参数。
- 计算损失并优化:每个批次的损失值会被累积,用于后续优化步骤,优化器会使用损失计算更新模型的权重。
- 输出损失信息:如果当前批次处理到一半,会输出当前的损失值,用于追踪训练进度。
- 每个 epoch 结束时评估:每经过一个 epoch,使用
evaluator.evaluate()方法来评估当前模型的性能,如验证集的损失、准确率等。
- 进入训练循环,每个 epoch 会经历以下步骤:
-
保存模型:
- 在每个 epoch 结束后,通过
torch.save(model.state_dict(), model_save_path)将模型的参数(权重)保存到指定路径config.save_path。这样可以在训练过程中定期保存模型,以便在训练中断后恢复或者用于后续的推理。
- 在每个 epoch 结束后,通过
-
返回训练结果:
- 最后,函数返回训练好的模型和训练数据。这通常用于后续的推理阶段或者进一步分析。
训练情况
2025-04-15 23:42:04,564 - __main__ - INFO - 开始测试第20轮模型效果:
2025-04-15 23:42:11,191 - __main__ - INFO - PERSON类实体,准确率:0.642384, 召回率: 0.500000, F1: 0.562314
2025-04-15 23:42:11,192 - __main__ - INFO - LOCATION类实体,准确率:0.707965, 召回率: 0.669456, F1: 0.688167
2025-04-15 23:42:11,192 - __main__ - INFO - TIME类实体,准确率:0.878205, 召回率: 0.769663, F1: 0.820354
2025-04-15 23:42:11,192 - __main__ - INFO - ORGANIZATION类实体,准确率:0.533333, 召回率: 0.505263, F1: 0.518914
2025-04-15 23:42:11,192 - __main__ - INFO - Macro-F1: 0.647437
2025-04-15 23:42:11,192 - __main__ - INFO - Micro-F1 0.665157
2025-04-15 23:42:11,192 - __main__ - INFO - --------------------
测试与评估
evaluate.py
# -*- coding: utf-8 -*-
import torch
import re
import numpy as np
from collections import defaultdict
from loader import load_data
"""
模型效果测试
"""
class Evaluator:
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.stats_dict = {"LOCATION": defaultdict(int),
"TIME": defaultdict(int),
"PERSON": defaultdict(int),
"ORGANIZATION": defaultdict(int)}
self.model.eval()
for index, batch_data in enumerate(self.valid_data):
sentences = self.valid_data.dataset.sentences[index * self.config["batch_size"]: (index+1) * self.config["batch_size"]]
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_id, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
with torch.no_grad():
pred_results = self.model(input_id) #不输入labels,使用模型当前参数进行预测
self.write_stats(labels, pred_results, sentences)
self.show_stats()
return
def write_stats(self, labels, pred_results, sentences):
assert len(labels) == len(pred_results) == len(sentences)
if not self.config["use_crf"]:
pred_results = torch.argmax(pred_results, dim=-1)
for true_label, pred_label, sentence in zip(labels, pred_results, sentences):
if not self.config["use_crf"]:
pred_label = pred_label.cpu().detach().tolist()
true_label = true_label.cpu().detach().tolist()
true_entities = self.decode(sentence, true_label)
pred_entities = self.decode(sentence, pred_label)
# print("=+++++++++")
# print(true_entities)
# print(pred_entities)
# print('=+++++++++')
# 正确率 = 识别出的正确实体数 / 识别出的实体数
# 召回率 = 识别出的正确实体数 / 样本的实体数
for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]:
self.stats_dict[key]["正确识别"] += len([ent for ent in pred_entities[key] if ent in true_entities[key]])
self.stats_dict[key]["样本实体数"] += len(true_entities[key])
self.stats_dict[key]["识别出实体数"] += len(pred_entities[key])
return
def show_stats(self):
F1_scores = []
for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]:
# 正确率 = 识别出的正确实体数 / 识别出的实体数
# 召回率 = 识别出的正确实体数 / 样本的实体数
precision = self.stats_dict[key]["正确识别"] / (1e-5 + self.stats_dict[key]["识别出实体数"])
recall = self.stats_dict[key]["正确识别"] / (1e-5 + self.stats_dict[key]["样本实体数"])
F1 = (2 * precision * recall) / (precision + recall + 1e-5)
F1_scores.append(F1)
self.logger.info("%s类实体,准确率:%f, 召回率: %f, F1: %f" % (key, precision, recall, F1))
self.logger.info("Macro-F1: %f" % np.mean(F1_scores))
correct_pred = sum([self.stats_dict[key]["正确识别"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])
total_pred = sum([self.stats_dict[key]["识别出实体数"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])
true_enti = sum([self.stats_dict[key]["样本实体数"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])
micro_precision = correct_pred / (total_pred + 1e-5)
micro_recall = correct_pred / (true_enti + 1e-5)
micro_f1 = (2 * micro_precision * micro_recall) / (micro_precision + micro_recall + 1e-5)
self.logger.info("Micro-F1 %f" % micro_f1)
self.logger.info("--------------------")
return
'''
{
"B-LOCATION": 0,
"B-ORGANIZATION": 1,
"B-PERSON": 2,
"B-TIME": 3,
"I-LOCATION": 4,
"I-ORGANIZATION": 5,
"I-PERSON": 6,
"I-TIME": 7,
"O": 8
}
'''
def decode(self, sentence, labels):
labels = "".join([str(x) for x in labels[:len(sentence)]])
results = defaultdict(list)
# 04 + 这个模式表示以'0'开头,后面跟着一个或多个'4'的子串,
# 捕获组 (04+) 将捕获所有符合该模式的部分,使用re.finditer(pattern, string) 会返回一个迭代器,
# 迭代器中的每一项是一个 Match 对象,包含匹配的子串和其位置(例如匹配到的起始和结束位置)
for location in re.finditer("(04+)", labels):
s, e = location.span()
results["LOCATION"].append(sentence[s:e])
for location in re.finditer("(15+)", labels):
s, e = location.span()
results["ORGANIZATION"].append(sentence[s:e])
for location in re.finditer("(26+)", labels):
s, e = location.span()
results["PERSON"].append(sentence[s:e])
for location in re.finditer("(37+)", labels):
s, e = location.span()
results["TIME"].append(sentence[s:e])
return results
主要功能是实现一个模型效果测试器(Evaluator 类),用于在训练过程中对模型进行评估,尤其是进行实体识别任务的性能评估。- Evaluator 类是为了评估命名实体识别(NER)模型的性能,使用了准确率、召回率和 F1 分数作为衡量标准。
decode方法通过标签的 BIO 标注格式解析实体。show_stats方法计算并显示各类实体的性能指标,包括宏观和微观 F1 分数。以下是对代码的详细解释:
类初始化init
- 功能: 初始化评估器。
- 参数:
config: 配置字典,包含模型训练和评估的超参数,例如验证数据的路径、批次大小等。model: 训练好的模型。logger: 用于记录日志的对象。
- 流程:
- 加载验证数据:
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)。从valid_data_path路径加载验证数据,shuffle=False表示验证数据不进行打乱。
- 加载验证数据:
测试评估eval
- 功能: 进行一次模型评估。
- 参数:
epoch: 当前训练的轮次,用于在日志中记录。
- 流程:
- 打印出当前评估的轮次信息。
- 初始化统计字典:
self.stats_dict,用于统计每类实体的正确识别数、样本实体数和识别出的实体数。 - 将模型设置为评估模式:
self.model.eval()。这是 PyTorch 的标准做法,表示模型不再进行反向传播,只用于推理。 - 遍历验证数据集:
for index, batch_data in enumerate(self.valid_data),逐批处理验证数据。 - 对于每个批次的数据,将其移动到 GPU 上(如果可用)。
- 使用
torch.no_grad()禁用梯度计算,从而加速推理并节省内存。 - 使用模型进行预测:
pred_results = self.model(input_id),注意在评估时不输入标签,仅使用模型进行预测。 - 将预测结果与真实标签进行比对,并记录统计数据。
统计汇录write_stats
- 功能: 计算并记录每类实体的识别统计信息。
- 参数:
labels: 真实标签(实体标注)。pred_results: 模型预测的结果。sentences: 当前批次的句子。
- 流程:
- 检查
labels、pred_results和sentences的长度是否一致。 - 如果不使用 CRF(条件随机场),则将预测结果取最大值作为标签(即从模型的输出中选出概率最大的位置作为预测标签):
pred_results = torch.argmax(pred_results, dim=-1)。 - 对每个句子的标签和预测标签进行解码,提取出实体(
true_entities和pred_entities)。 - 计算每个实体类别(如
PERSON,LOCATION,TIME,ORGANIZATION)的正确识别数、样本实体数和识别出的实体数。
- 检查
评估显示show_stats
- 功能: 显示评估的统计信息(准确率、召回率、F1 分数等)。
- 流程:
-
对每个实体类别计算其准确率、召回率和 F1 分数:
- 准确率:
正确识别的实体数 / 识别出的实体数 - 召回率:
正确识别的实体数 / 样本的实体数 - F1 分数: F 1 = 2 × precision × recall precision + recall F1 = \frac{2 \times \text{precision} \times \text{recall}}{\text{precision} + \text{recall}} F1=precision+recall2×precision×recall
- 准确率:
-
计算宏观 F1(Macro-F1)和微观 F1(Micro-F1):
- 宏观 F1:对各个实体类别的 F1 分数取平均。
- 微观 F1:基于全局正确识别的实体数、识别出的实体数和样本实体数来计算。
-
标签解码decode
- 功能: 解码模型预测的标签,提取出实体信息。
- 参数:
sentence: 当前句子(文本数据)。labels: 模型预测的标签(如 B-LOCATION, I-PERSON 等)。
- 流程:
- 将标签列表转化为字符串:
labels = "".join([str(x) for x in labels[:len(sentence)]])。 - 使用正则表达式(
re.finditer)来提取每类实体:- B-LOCATION(位置类实体)、B-ORGANIZATION(组织类实体)、B-PERSON(人物类实体)、B-TIME(时间类实体)都对应一个正则表达式。
- 每个实体类别的标签从
labels字符串中提取出对应的文本片段,并将其保存在字典中。
- 将标签列表转化为字符串:
正则表达式RE
- 代码的
decode方法使用正则表达式(re.finditer)从标签中提取出实体,主要根据一个一个特定B后跟着多个连续同类别的I且,本文中都是固定的标签对(04+)、(15+)、(26+)、(37+)。这里的标签与实体类型有固定的映射:B-LOCATION,I-LOCATION:用于提取位置实体,对应的标签对映射为(04+)。B-ORGANIZATION,I-ORGANIZATION:用于提取组织实体,对应的标签对映射为(15+)。B-PERSON,I-PERSON:用于提取人物实体,对应的标签对映射为(26+)。B-TIME,I-TIME:用于提取时间实体,对应的标签对映射为(37+)。
- 这些标签遵循
BIO(Begin, Inside, Outside)标注格式:B-表示实体的开始位置。I-表示实体的内部位置。O表示非实体部分。

















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









