






目标
基于pytorch的网络编写,实现一个网络完成一个简单nlp任务,判断文本中是否有某些特定字符出现。
实现
#coding:utf8
import torch
import torch.nn as nn
import numpy as np
import random
import json
import matplotlib.pyplot as plt
"""
基于pytorch的网络编写
实现一个网络完成一个简单nlp任务
判断文本中是否有某些特定字符出现
"""
class TorchModel(nn.Module):
def __init__(self, vector_dim, hidden_size, sentence_length, vocab):
super(TorchModel, self).__init__()
self.embedding = nn.Embedding(len(vocab), vector_dim, padding_idx=0) #embedding层
self.pool = nn.AvgPool1d(vector_dim) # 池化层
self.rnn = nn.RNN(sentence_length, hidden_size, batch_first=True) # RNN 层
self.fc = nn.Linear(hidden_size, sentence_length + 1) # 输出层,映射到位置类别
self.loss = nn.functional.cross_entropy
self.sigmoid = nn.functional.sigmoid
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #(batch_size, sen_len) -> (batch_size, sen_len, vector_dim)
x = self.pool(x)
x = x.squeeze()
x, _h = self.rnn(x) #(batch_size, vector_dim) -> (batch_size, 1) 3*5 5*1 -> 3*1
y_pred = self.fc(x) #(batch_size, 1) -> (batch_size, 1)
if y is not None:
return self.loss(y_pred, y) #预测值和真实值计算损失
else:
return self.sigmoid(y_pred) #输出预测结果
#字符集随便挑了一些字,实际上还可以扩充
#为每个字生成一个标号
#{"a":1, "b":2, "c":3...}
#abc -> [1,2,3]
def build_vocab():
chars = "你我他abcdefghijklmnopqrstuvwxyz" #字符集
vocab = {"pad":0}
for index, char in enumerate(chars):
vocab[char] = index+1 #每个字对应一个序号
vocab['unk'] = len(vocab) #26
return vocab
#随机生成一个样本
#从所有字中选取sentence_length个字
#反之为负样本
def build_sample(vocab, sentence_length):
#执行若干次循环,随机从字表选取sentence_length个字,可能重复
x = [random.choice(list(vocab.keys())) for _ in range(sentence_length)]
#判定特定字符在字符的第几个位置
y = np.zeros(len(x) + 1)
try:
y[x.index('你')] = 1
except ValueError:
y[len(x)]= 1
x = [vocab.get(word, vocab['unk']) for word in x] #将字转换成序号(若字典中没找到使用unk),为了做embedding
return x, y
#建立数据集
#输入需要的样本数量。需要多少生成多少
def build_dataset(sample_length, vocab, sentence_length):
dataset_x = []
dataset_y = []
for i in range(sample_length):
x, y = build_sample(vocab, sentence_length)
dataset_x.append(x)
dataset_y.append(y)
return torch.LongTensor(dataset_x), torch.FloatTensor(dataset_y)
#建立模型
def build_model(vocab, hidden_size, char_dim, sentence_length):
model = TorchModel(char_dim, hidden_size, sentence_length, vocab)
return model
#测试代码
#用来测试每轮模型的准确率
def evaluate(model, vocab, sample_length):
model.eval() #将模型设置为评估模式,Dropout 层被禁用,BatchNorm 会使用训练过程中学习到的全局均值和方差
x, y = build_dataset(200, vocab, sample_length) #建立200个用于测试的样本
correct, wrong = 0, 0
with torch.no_grad():
y_pred = model(x) #模型预测
for y_p, y_t in zip(y_pred, y): #与真实标签进行对比
if torch.argmax(y_p) == torch.argmax(y_t):
correct += 1 #负样本判断正确
else:
wrong += 1
print("正确预测个数:%d, 正确率:%f"%(correct, correct/(correct+wrong)))
return correct/(correct+wrong)
def train():
#配置参数
epoch_num = 30 #训练轮数
batch_size = 20 #每次训练样本个数
train_sample = 500 #每轮训练总共训练的样本总数
char_dim = 20 #每个字的维度
hidden_size = 8
sentence_length = 6 #样本文本长度
learning_rate = 0.005 #学习率
# 建立字表
vocab = build_vocab()
# 建立模型
model = build_model(vocab, hidden_size, char_dim, sentence_length)
# 选择优化器
optim = torch.optim.Adam(model.parameters(), lr=learning_rate)
log = []
# 训练过程
for epoch in range(epoch_num):
model.train() #将模型设置为训练模式, Dropout 和 BatchNorm 等层会根据训练时的特定需求工作
watch_loss = []
for batch in range(int(train_sample / batch_size)):
x, y = build_dataset(batch_size, vocab, sentence_length) #构造一组训练样本
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
acc = evaluate(model, vocab, sentence_length) #测试本轮模型结果
log.append([acc, np.mean(watch_loss)])
#画图
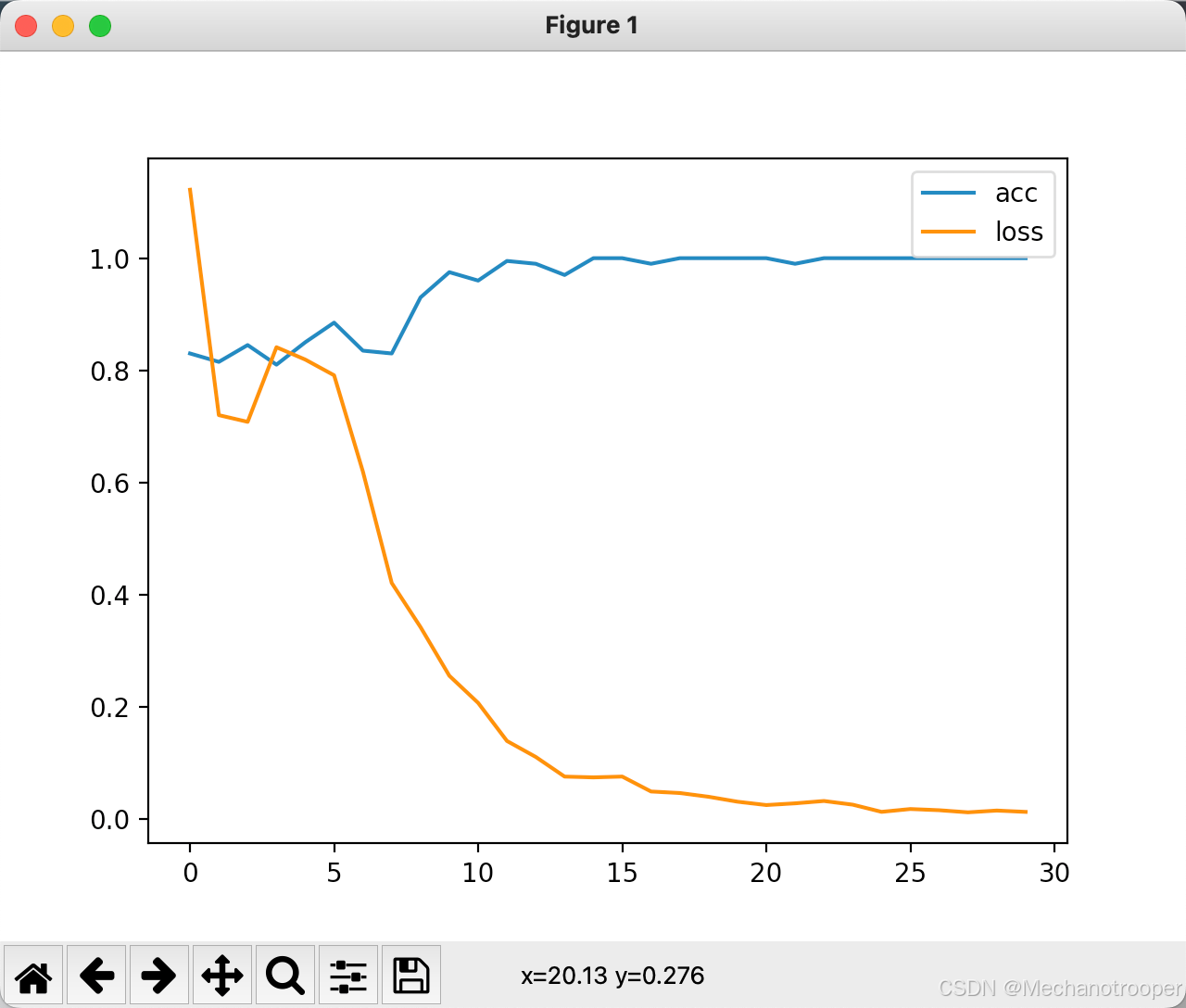
plt.plot(range(len(log)), [l[0] for l in log], label="acc") #画acc曲线
plt.plot(range(len(log)), [l[1] for l in log], label="loss") #画loss曲线
plt.legend()
plt.show()
#保存模型
torch.save(model.state_dict(), "model.pth")
# 保存词表
writer = open("vocab.json", "w", encoding="utf8")
writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))
writer.close()
return
#使用训练好的模型做预测
def predict(model_path, vocab_path, input_strings):
char_dim = 20 # 每个字的维度
hidden_size = 8
sentence_length = 6 # 样本文本长度
vocab = json.load(open(vocab_path, "r", encoding="utf8")) #加载字符表
model = build_model(vocab, hidden_size, char_dim, sentence_length) #建立模型
model.load_state_dict(torch.load(model_path)) #加载训练好的权重
x = []
for input_string in input_strings:
x.append([vocab[char] for char in input_string]) #将输入序列化
model.eval() #将模型设置为评估模式
with torch.no_grad(): #不计算梯度
result = model.forward(torch.LongTensor(x)) #模型预测
for i, input_string in enumerate(input_strings):
yp_prob, yp_class = torch.max(result[i], 0)
print("输入:%s, 字符所在位置:%d, 概率值:%f" % (input_string, yp_class, yp_prob)) #打印结果
if __name__ == "__main__":
train()
test_strings = ["fnvf你e", "wz你dfg", "rqw你eg", "hjkad你", "n我kwww", "你abcd他"]
predict("model.pth", "vocab.json", test_strings)
字表数据
vocab.json
{
"pad": 0,
"你": 1,
"我": 2,
"他": 3,
"a": 4,
"b": 5,
"c": 6,
"d": 7,
"e": 8,
"f": 9,
"g": 10,
"h": 11,
"i": 12,
"j": 13,
"k": 14,
"l": 15,
"m": 16,
"n": 17,
"o": 18,
"p": 19,
"q": 20,
"r": 21,
"s": 22,
"t": 23,
"u": 24,
"v": 25,
"w": 26,
"x": 27,
"y": 28,
"z": 29,
"unk": 30
}
训练过程
运行结果


















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









