







Spark推荐系统,干货,心得
点击上方蓝字关注~
目录:
1.Jupyter Notebook
1.1Jupyter Notebook 安装
1.2Jupyter Notebook 使用
1.3Jupyter Notebook 的快捷键
2. pandas
2.1 series
2.2DataFrame
2.3 pandas中的Index
3.pandas中的数据选取
3.1 一维
3.2 二维
1.1Jupyter Notebook 安装
JupyterNotebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
简而言之为web型python代码交互编辑器
安装JupyterNotebook的前提是需要安装了Python(3.3版本及以上,或2.7版本、建议安装python3.6 后面用Tensorflow方便)。
1)安装jupyter模块
pip installjupyter
2)创建一个文件夹,比如名字叫pandas,命令窗口进入该文件夹目录中,执行
jupyternotebook
1.2Jupyter Notebook 使用
如果想新建一个notebook,只需要点击 New,选择你希望启动的notebook 类型即可。
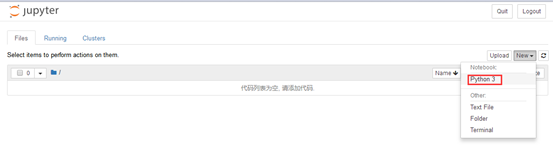

以[ ]开头。在这种类型的单元格中,可以输入任意代码并执行。例如,输入 777 + 88 并按
下 Shift +Enter。之后,单元格中的代码就会被计算,光标也会被移动动一个新的单元格中。
你会得到如下结果:

1.3Jupyter Notebook 的快捷键

2.pandans
pandas 是基于 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas
纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas
提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使 Python
成为强大而高效的数据分析环境的重要因素之一。
Series:一维数组,与 Numpy 中的一维 array 类似。二者与 Python 基本的数据结构 List
也很相近,其区别是:List中的元素可以是不同的数据类型,而 Array 和 Series中则只允许
存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
DataFrame:二维的表格型数据结构。很多功能与 spark sql 中的 data.frame 类似。做过spark sql的同学不会陌生 ,也可以将DataFrame 理解为 Series 的容器
2.1 series
eg :使用列表创建
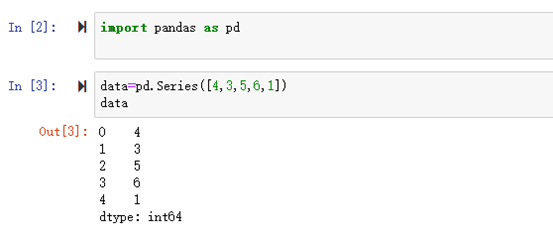
series 对象包装的是 numpy 中的一维数组,实际上是将一个一维数组与一个索引名称捆
绑在一起了。
pandas 中两个重要的属性 values 和 index,values:是 Series 对象的原始数据。index:对
应了 Series 对象的索引对象
eg:Series中两个重要的属性values 和index

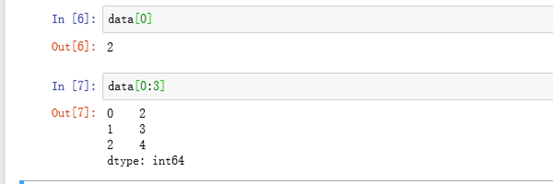
eg: Pandas也可以按照Numpy的索引值方式来取值
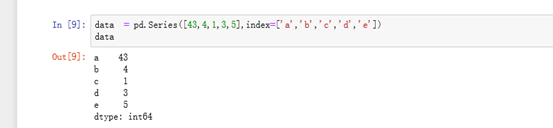
eg: 创建Series时候,指定index对象
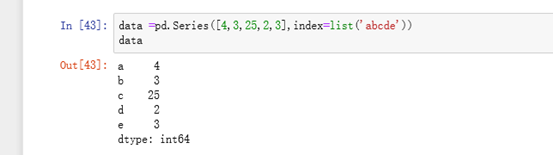
同样也可以使用列表的方式指定index =》 换成index = list("abcde")
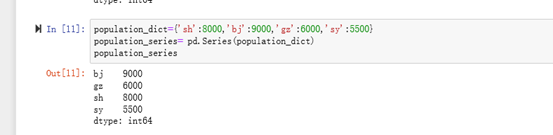
eg:传入字典创建,默认将key作为index (默认按照value值排序)
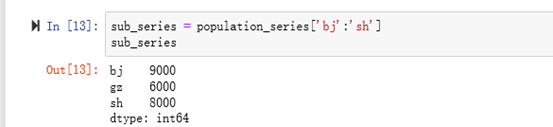
eg: Series对象可以按照字典的方式进行索引 左闭右闭
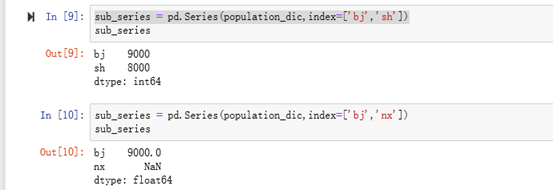
eg:如果既用了字典创建了Series对象,又显示的指定了index,如果key不存在,则值为NaN
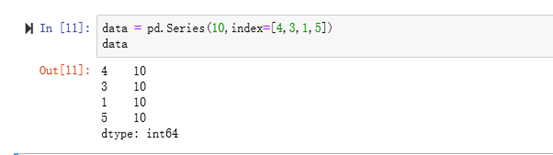
eg:将一个标量与index对象一起传入创建
2.2 DataFrame
将两个series对象作为dict的value传入,就可以创建一个DataFrame对象
eg:创建DataFrame对象
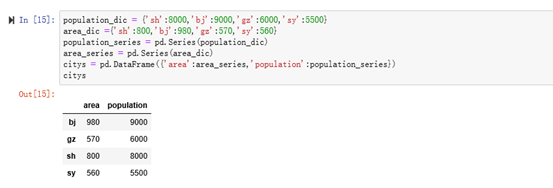
eg:查看DataFrame对象的values和index
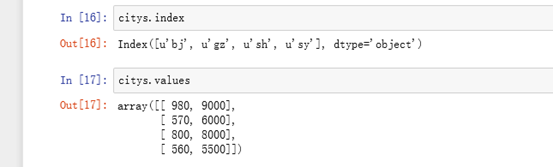
eg:像字典根据key获取值进行获取
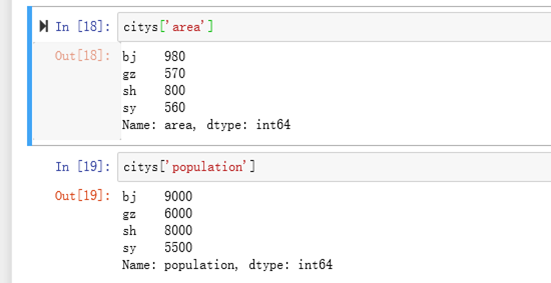
eg: 列表创建
将bj,gz,sh,sy作为表头
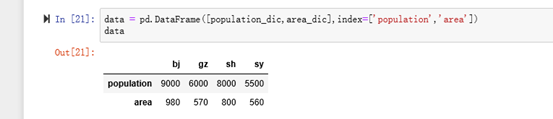
eg:使用行索引index创建
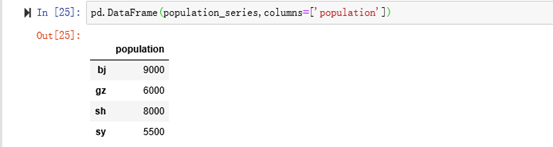
eg:使用列索引columns创建
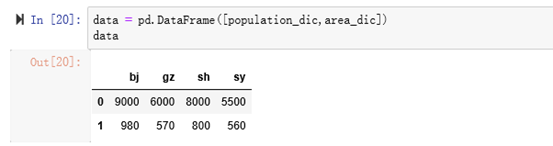
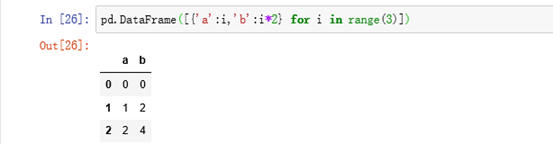
eg: 列表创建方式创建
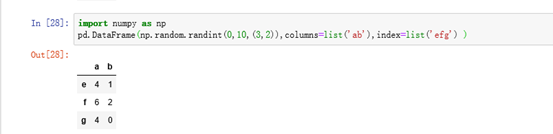
eg:传入一个二维数组指定columns和index创建
2.3 pandas中的Index
eg:pandas中的index,其实是不可变的一维数组
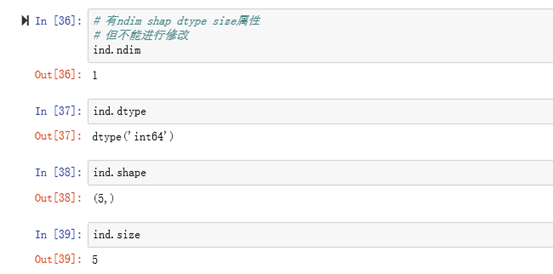
3.pandas中的数据选取
3.1 一维
eg : 一维的数据选取


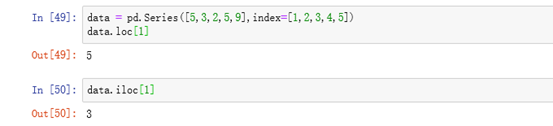
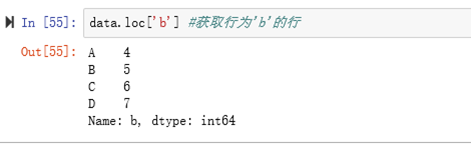
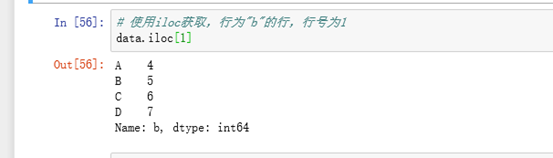
如果索引与行名相同都是1,这时候就不知道是按照哪个来获取,索引获取时候使用loc、iloc
loc函数:通过行索引‘index’ 中的具体值来取行数据(如取"Index'为"A"的行)
iloc函数:通过行号来取行数据(如取第二行的数据) 行号从0开始,逐次加1
eg: loc与iloc
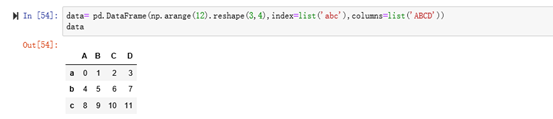
3.2 二维
eg: loc与iloc获取
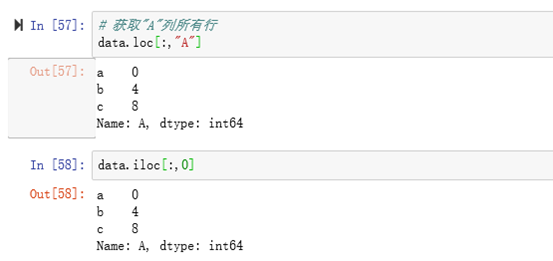
eg: loc与iloc获取'A'列所有行
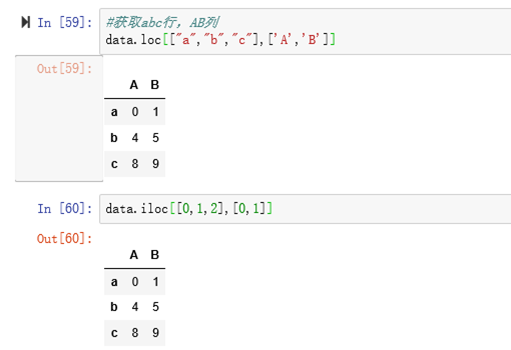
eg: loc与iloc获取部分行 部分列

推荐阅读:
spark协同过滤
Spark推荐系统

长按识别二维码关注我们

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









