






 本文分享了Spark推荐系统的实践经验,介绍了如何设计数据表结构以满足不同业务需求,包括新增人数、取消关注人数等关键指标,并通过具体案例展示了数据分析的过程。
本文分享了Spark推荐系统的实践经验,介绍了如何设计数据表结构以满足不同业务需求,包括新增人数、取消关注人数等关键指标,并通过具体案例展示了数据分析的过程。

Spark推荐系统,干货,心得
点击上方蓝字关注~
hello,大家好,我是习惯性拖稿的小皮拖~
这篇推文确实拖的有点久了,echoy找我写的时候 我也是犹豫了很久,我究竟会什么???
于是,我悄咪咪的点进了公众号后台查看了下。哎唷,不得了的呀,明天我就能看到自己的痕迹啊。
这个分析要怎么做出来呢?
首先,我要拥有几个指标:新增人数、取消关注人数、净增人数、累积人数。
同样,我也需要几个维度:时间维度A、时间维度B、来源、按时间对比(月度环比)。
根据指标、维度 设计出满足需求的表结构:
[由于新关注人数、取消关注人数、净增人数、累积人数四个指标拥有一个共同维度——时间]
<表1
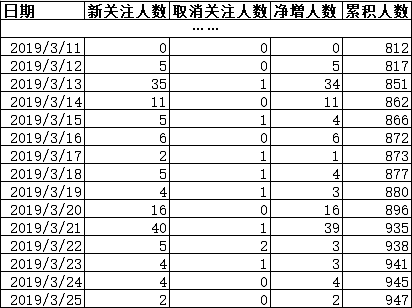
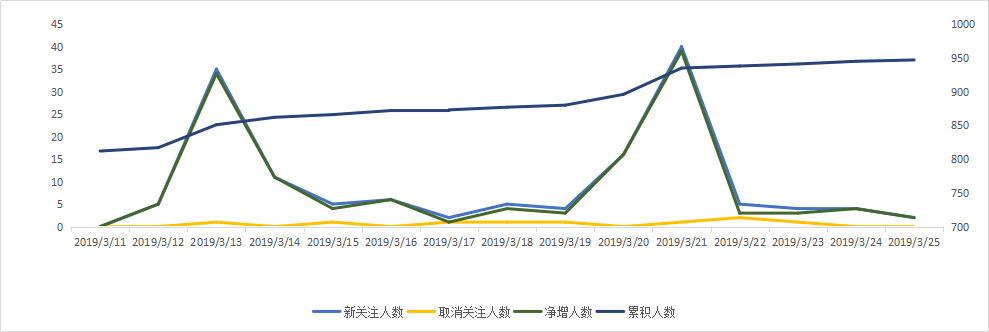
excel做出的效果图
[由于来源字段 只存在于选择新增人数指标时,
所以选取2019/3/11、2019/3/12两天来源为搜一搜和扫描二维码的数据
比表1的粒度更细一些]
<表2
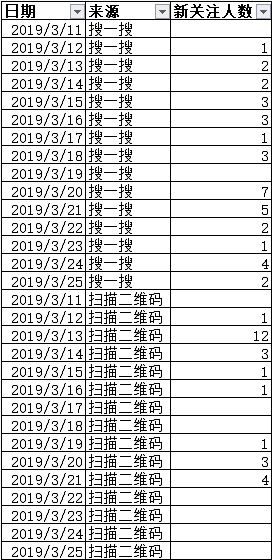
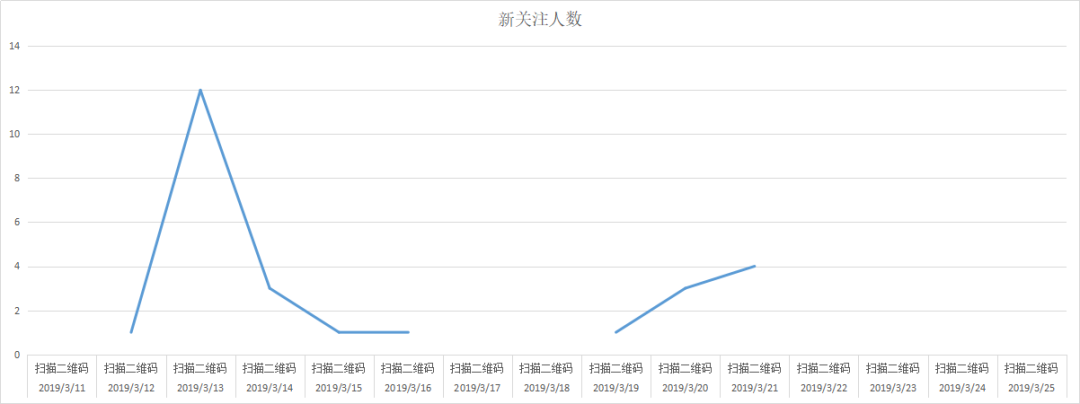
excel单独筛选扫描二维码效果图
表2=表3+表4
<表3 <表4
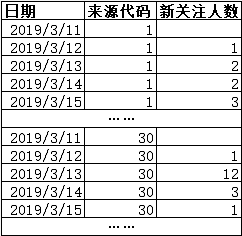
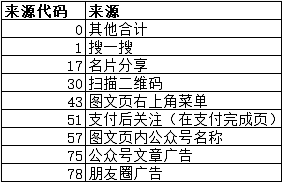
表3即事实表
表4即维表
为了演示形象一些,我们在事实表中新增了 城市代码 , 像这样
<
| 日期 | 来源代码 | 城市代码 | 新关注人数 |
对应的表间关系图为
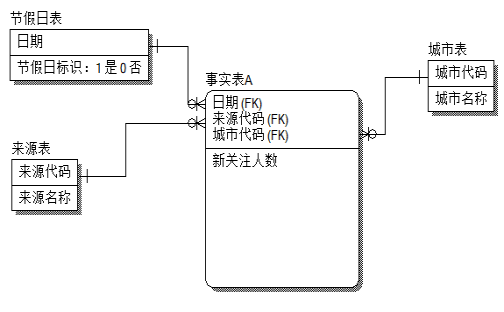
星型结构
如果城市代码再有了层级 加上所属省份
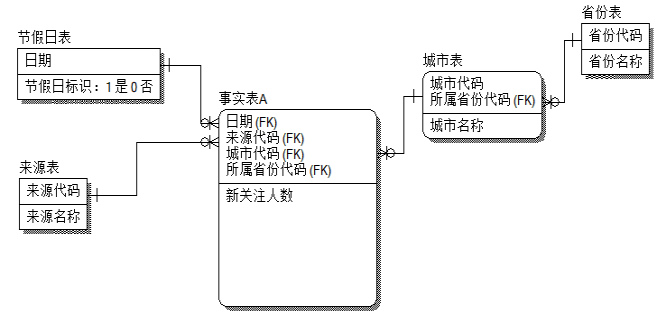
雪花结构
当然,模型结构属于题外话,让我们继续往下推:
我们假设 搜一搜、扫描二维码 在2019/3/11、2019/3/12两天的明细数据是这样的。
(为什么要假设呢?因为真实数据我们拿不到,爬虫只能爬到网页上看到的汇总数据,明细数据想要的话 只能去黑库[违法行为!!我们是社会主义合格小公民 谨记八荣八耻!~
])
<表5
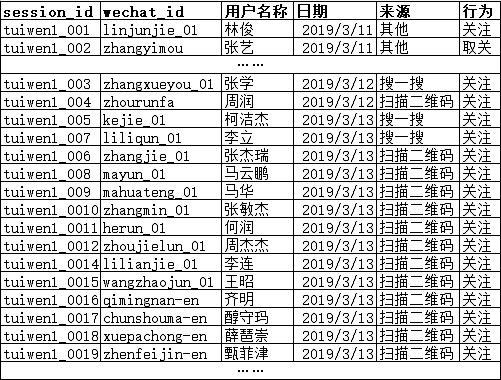
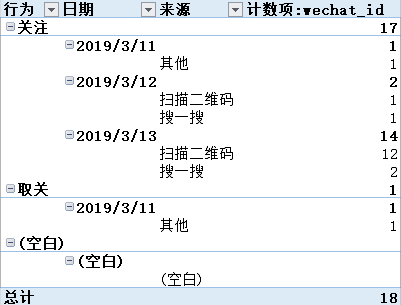
excel数据透视效果图
表5到表2 只需要限定行为='关注' 再根据日期、来源汇总 计数wechat_id
[真正开发中 不要用中文定义表名和字段名 不要 千万不要!!!]
select count(wechat_id) 新关注人数 from 表5 group by 日期,来源 where 行为='关注'大概案例都讲完了
现在让我们来总结一下吧:
视频中看到的呢,就是离线分析的小demo;
整个过程呢,就是数据集市的处(划掉)雏形啦!!说是雏形,是因为业务简单,架构不用太复杂;
这种方法呢,就是kimball自上而下的数仓方法论。
简单来理解,就是业务驱动。老板告诉你,我想要怎样展示,你结合数据情况设计表,以供前台快速有效的使用;
【如果觉得有用的话,就多看看。赞赏就免啦!哎呀,不用,不用 真不用 哎呀呀呀~
(也根本没有赞赏窗口哇 啊哈哈哈哈哈)
毕竟,我的发际线不允许这么膨胀(假装没有假发片)~
如果有问题的话,可以联系我,我会考虑在接下来的某篇中梳理下。
好啦,说了一大堆,你可能觉得上当受骗了。 我是谁?我在哪?在文章里没看到哇???
那我就告诉你一个更简单的办法————推文下方留言,发表你的想法,你看见你,我看见你的吐槽建议贺词喜报等等等等 ღ( ´・ᴗ・` )比心】
==
是不是觉得结束了?
看看 →
这个公众号易主啦 哇哈哈哈哈哈哈哈哈

咋锅阔楞~
节日快乐哈!~
[帅不过3秒.jgp]

长按识别二维码关注我们


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









