







 本文深入介绍了MySQL存储过程的背景、创建、参数、程序体、查看、调用、修改和删除等核心概念,并通过实例展示了如何创建一个用于计算单品销售统计的存储过程。在实践中,存储过程能提高效率,增强安全性,但开发和调试成本较高。文章还提供了存储过程的调试方法和注意事项。
本文深入介绍了MySQL存储过程的背景、创建、参数、程序体、查看、调用、修改和删除等核心概念,并通过实例展示了如何创建一个用于计算单品销售统计的存储过程。在实践中,存储过程能提高效率,增强安全性,但开发和调试成本较高。文章还提供了存储过程的调试方法和注意事项。
阅读整理自《MySQL 必知必会》- 朱晓峰,详细内容请登录 极客时间 官网购买专栏。
背景
在超市项目中,每天营业结束后,超市经营者都要计算当日的销量,核算成本和毛利等营业数据,这也就意味着每天都要做重复的数据统计工作。其实,这种数据量大,而且计算过程复杂的场景,就非常适合使用存储过程。
简单说,存储过程就是把一系列 SQL 语句预先存储在 MySQL 服务器上,需要执行的时候,客户端只需要向服务器端发出调用存储过程的命令,服务器端就可以把预先存储好的这一系列 SQL 语句全部执行。
不仅执行效率非常高,而且客户端不需要把所有的 SQL 语句通过网络发给服务器,减少了 SQL 语句暴露在网上的风险,也提高了数据查询的安全性。
创建存储过程
create procedure 存储过程名 ([in | out | inout] 参数名称 类型) 程序体
数据准备:
mysql> select * from demo.transactiondetails;
+---------------+------------+----------+------------+------------+
| transactionid | itemnumber | quantity | salesprice | salesvalue |
+---------------+------------+----------+------------+------------+
| 1 | 1 | 2 | 89.00 | 178.00 |
| 1 | 2 | 5 | 5.00 | 25.00 |
| 2 | 1 | 3 | 89.00 | 267.00 |
| 3 | 2 | 10 | 5.00 | 50.00 |
| 3 | 3 | 3 | 15.00 | 45.00 |
+---------------+------------+----------+------------+------------+
5 rows in set (0.01 sec)
mysql> select * from demo.transactionhead;
+---------------+------------------+------------+---------------------+----------+-----------+
| transactionid | transactionno | operatorid | transdate | memberid | cashierid |
+---------------+------------------+------------+---------------------+----------+-----------+
| 1 | 0120201201000001 | 1 | 2020-12-01 00:00:00 | 1 | 1 |
| 2 | 0120201202000001 | 2 | 2020-12-02 00:00:00 | 2 | 1 |
| 3 | 0120201202000002 | 1 | 2020-12-01 01:00:00 | NULL | 1 |
+---------------+------------------+------------+---------------------+----------+-----------+
3 rows in set (0.00 sec)
mysql> select * from demo.goodsmaster;
+------------+---------+-----------+---------------+------+-----------+----------------+
| itemnumber | barcode | goodsname | specification | unit | saleprice | avgimportprice |
+------------+---------+-----------+---------------+------+-----------+----------------+
| 1 | 0001 | 书 | 16开 | 本 | 90.00 | 33.50 |
| 2 | 0002 | 笔 | NULL | 支 | 5.00 | 3.50 |
| 3 | 0003 | 胶水 | NULL | 瓶 | 10.00 | 11.00 |
+------------+---------+-----------+---------------+------+-----------+----------------+
存储过程会用刚刚的三个表中的数据进行计算,并且把计算的结果存储到下面的这个单品统计表中。
mysql> describe demo.dailystatistics;
+-------------+---------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+---------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| itemnumber | int | YES | | NULL | |
| quantity | decimal(10,3) | YES | | NULL | |
| actualvalue | decimal(10,2) | YES | | NULL | |
| cost | decimal(10,2) | YES | | NULL | |
| profit | decimal(10,2) | YES | | NULL | |
| profitratio | decimal(10,4) | YES | | NULL | |
| salesdate | datetime | YES | | NULL | |
+-------------+---------------+------+-----+---------+----------------+
创建一个存储过程,完成单品销售统计的计算:
- 把 SQL 语句的分隔符改为“//”。因为存储过程中包含很多 SQL 语句,如果不修改分隔符的话,MySQL 会在读到第一个 SQL 语句的分隔符“;”的时候,认为语句结束并且执行,这样就会导致错误。
- 创建存储过程,把要处理的日期作为一个参数传入。同时用 BEGIN 和 END 关键字把存储过程中的 SQL 语句包裹起来,形成存储过程的程序体。
- 在程序体中,先定义 2 个数据类型为 DATETIME 的变量,用来记录要计算数据的起始时间和截止时间。
- 删除保存结果数据的单品统计表中相同时间段的数据,目的是防止数据重复。
- 计算起始时间和截止时间内单品的销售数量合计、销售金额合计、成本合计、毛利和毛利率,并且把结果存储到单品统计表中。
delimiter // -- 设置分割符为//
create procedure demo.dailyoperation(transdate text)
begin -- 开始程序体
declare startdate, enddate datetime; -- 定义变量
set startdate = date_format(transdate, '%Y-%m-%d'); -- 给起始时间赋值
set enddate = date_add(transdate, interval 1 day); -- 截止时间赋值为1天以后
-- 删除原有数据
delete from demo.dailystatistics where salesdate = startdate;
-- 重新插入数据
insert into demo.dailystatistics
(
salesdate,
itemnumber,
quantity,
actualvalue,
cost,
profit,
profitratio
)
select
left(b.transdate, 10),
a.itemnumber,
sum(a.quantity),
sum(a.salesvalue),
sum(a.quantity*c.avgimportprice), -- 计算成本
sum(a.salesvalue-a.quantity*c.avgimportprice), -- 计算毛利
case sum(a.salesvalue) when 0 then 0 else round(sum(a.salesvalue-a.quantity*c.avgimportprice)/sum(a.salesvalue), 4) end -- 计算毛利率
from demo.transactiondetails as a
join demo.transactionhead as b on (a.transactionid = b.transactionid)
join demo.goodsmaster as c on (a.itemnumber = c.itemnumber)
where b.transdate > startdate and b.transdate < enddate
group by left(b.transdate, 10), a.itemnumber
order by left(b.transdate, 10), a.itemnumber;
end
//
delimiter ; -- 恢复分隔符为;
存储过程参数
存储过程可以有参数,也可以没有参数。一般来说,当我们通过客户端或者应用程序调用存储过程的时候,如果需要与存储过程进行数据交互,比如,存储过程需要根据输入的数值为基础进行某种数据处理和计算,或者需要把某个计算结果返回给调用它的客户端或者应用程序,就需要设置参数。否则,就不用设置参数。
参数有 3 种,分别是 IN、OUT 和 INOUT。
- IN 表示输入的参数,存储过程只是读取这个参数的值。如果没有定义参数种类,默认就是 IN,表示输入参数。
- OUT 表示输出的参数,存储过程在执行的过程中,把某个计算结果值赋给这个参数,执行完成之后,调用这个存储过程的客户端或者应用程序就可以读取这个参数返回的值了。
- INOUT 表示这个参数既可以作为输入参数,又可以作为输出参数使用。
除了定义参数种类,还要对参数的数据类型进行定义。在这个存储过程中,定义了一个参数 transdate 的数据类型是 text。这个参数的用处是告诉存储过程,我要处理的是哪一天的数据。没有指定参数种类是 IN、OUT 或者 INOUT,这是因为在 MySQL 中,如果不指定参数的种类,默认就是 IN,表示输入参数。
存储过程程序体
在程序体的开始部分,定义了 2 个变量,分别是 startdate 和 enddate。它们都是 datetime 类型,作用是根据输入参数 transdate,计算出需要筛选的数据的时间区间。
后面的代码分 3 步完成起始时间和截止时间的计算,并且分别赋值给变量 startdate 和 enddate。
- 用 date_format() 函数,把输入的参数,按照 YYYY 年 MM 月 DD 日的格式转换成了日期时间类型数据,比如输入参数是“2020-12-01”,那么,转换成的日期时间值是“2020-12-01 00:00:00”,表示 2020 年 12 月 01 日 00 点 00 分 00 秒。
- 把第一步中计算出的值,作为起始时间赋值给变量 startdate。
- 把第一步中计算出的值,通过 date_add() 函数,计算出 1 天以后的时间赋值给变量 enddate。
计算出了起始时间和截止时间之后,先删除需要计算日期的单品统计数据,以防止数据重复。接着,我们重新计算单品的销售统计,并且把计算的结果插入到单品统计表。
需要注意的是,这里使用 case 函数来解决销售金额为 0 时计算毛利的问题。这是为了防止计算出现被 0 除而报错的情况。不要以为销售金额就一定大于 0,在实际项目运行的过程中,会出现因为优惠而导致实际销售金额为 0 的情况。在实际工作中,把这些极端情况都考虑在内,提前进行防范,这样你的代码才能稳定可靠。
查看存储过程
show create procedure demo.dailyoperation \G
mysql> show create procedure demo.dailyoperation \G
*************************** 1. row ***************************
Procedure: dailyoperation
sql_mode: STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION
Create Procedure: CREATE DEFINER=`root`@`localhost` PROCEDURE `dailyoperation`(transdate text)
begin
declare startdate, enddate datetime;
set startdate = date_format(transdate, '%Y-%m-%d');
set enddate = date_add(transdate, interval 1 day);
-- 删除原有数据
delete from demo.dailystatistics where salesdate = startdate;
-- 重新插入数据
insert into demo.dailystatistics
(
salesdate,
itemnumber,
quantity,
actualvalue,
cost,
profit,
profitratio
)
select
left(b.transdate, 10),
a.itemnumber,
sum(a.quantity),
sum(a.salesvalue),
sum(a.quantity*c.avgimportprice),
sum(a.salesvalue-a.quantity*c.avgimportprice),
case sum(a.salesvalue) when 0 then 0 else round(sum(a.salesvalue-a.quantity*c.avgimportprice)/sum(a.salesvalue), 4) end
from demo.transactiondetails as a
join demo.transactionhead as b on (a.transactionid = b.transactionid)
join demo.goodsmaster as c on (a.itemnumber = c.itemnumber)
where b.transdate > startdate and b.transdate < enddate
group by left(b.transdate, 10), a.itemnumber
order by left(b.transdate, 10), a.itemnumber;
end
character_set_client: utf8mb4
collation_connection: utf8mb4_0900_ai_ci
Database Collation: utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
调用存储过程
调用一下这个存储过程,并且给它传递一个参数“2020-12-01”,也就是计算 2020 年 12 月 01 日的单品统计数据:
mysql> update demo.transactiondetails set quant^Chere transactionid=3 and itemnumber=3;
mysql> CALL demo.dailyoperation('2020-12-01');
Query OK, 2 rows affected (0.01 sec)
存储过程执行结果提示“Query OK”,表示执行成功了。“2 rows affected”表示执行的结果影响了 2 条数据记录。
mysql> select * from demo.dailystatistics;
+----+------------+----------+-------------+-------+--------+-------------+---------------------+
| id | itemnumber | quantity | actualvalue | cost | profit | profitratio | salesdate |
+----+------------+----------+-------------+-------+--------+-------------+---------------------+
| 4 | 2 | 10.000 | 50.00 | 35.00 | 15.00 | 0.3000 | 2020-12-01 00:00:00 |
| 5 | 3 | 3.000 | 45.00 | 33.00 | 12.00 | 0.2667 | 2020-12-01 00:00:00 |
+----+------------+----------+-------------+-------+--------+-------------+---------------------+
2 rows in set (0.00 sec)
可以看到,存储过程被执行了,它计算出了我们需要的单品统计结果,并且把统计结果存入了单品统计表中。
如果不使用存储过程的语句,查询所有:
mysql> select left(b.transdate, 10), a.itemnumber, sum(a.quantity),
-> sum(a.salesvalue), sum(a.quantity*c.avgimportprice) as 成本,
-> sum(a.salesvalue-a.quantity*c.avgimportprice) as 毛利,
-> case sum(a.salesvalue) when 0 then 0 else round(sum(a.salesvalue- a.quantity*c.avgimportprice)/sum(a.salesvalue), 4) end as 毛利率
-> from demo.transactiondetails as a
-> join demo.transactionhead as b on (a.transactionid = b.transactionid)
-> join demo.goodsmaster as c on (a.itemnumber = c.itemnumber)
-> group by left(b.transdate, 10), a.itemnumber
-> order by left(b.transdate, 10), a.itemnumber;
+-----------------------+------------+-----------------+-------------------+--------+--------+--------+
| left(b.transdate, 10) | itemnumber | sum(a.quantity) | sum(a.salesvalue) | 成本 | 毛利 | 毛利率 |
+-----------------------+------------+-----------------+-------------------+--------+--------+--------+
| 2020-12-01 | 1 | 2 | 178.00 | 67.00 | 111.00 | 0.6236 |
| 2020-12-01 | 2 | 15 | 75.00 | 52.50 | 22.50 | 0.3000 |
| 2020-12-01 | 3 | 3 | 45.00 | 33.00 | 12.00 | 0.2667 |
| 2020-12-02 | 1 | 3 | 267.00 | 100.50 | 166.50 | 0.6236 |
+-----------------------+------------+-----------------+-------------------+--------+--------+--------+
4 rows in set (0.01 sec)
修改存储过程
修改存储过程的内容,建议在 Workbench 中操作。这是因为可以在里面直接修改存储过程,而如果用 SQL 命令来修改存储过程,就必须删除存储过程再重新创建,相比之下,在 Workbench 中修改比较简单。
在左边的导航栏,找到数据库 demo,展开之后,找到存储过程 stored procedure,然后找到刚刚创建的 dailyoperation,点击右边的设计按钮,就可以在右边的工作区进行修改了。修改完成之后,点击工作区右下方的按钮“Apply”,保存修改。
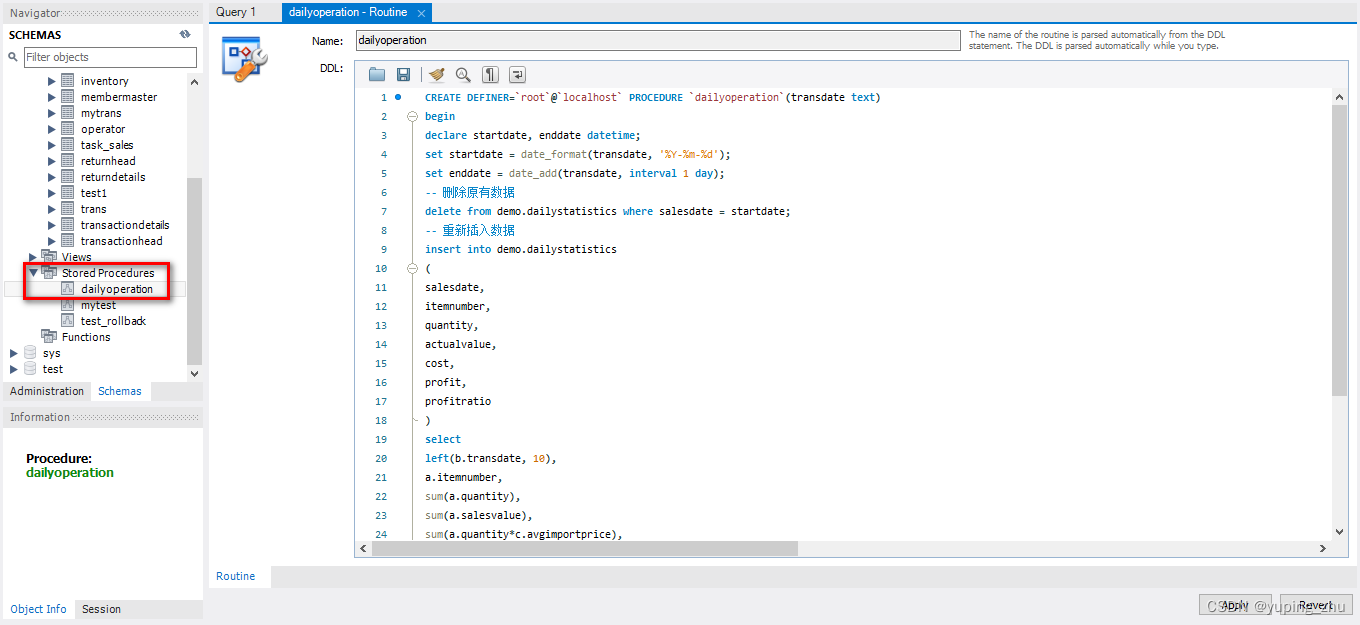
在 MySQL 中,存储过程不像普通的编程语言(比如 VC++、Java 等)那样有专门的集成开发环境。因此,可以通过 SELECT 语句,把程序执行的中间结果查询出来,来调试一个 SQL 语句的正确性。调试成功之后,把 SELECT 语句后移到下一个 SQL 语句之后,再调试下一个 SQL 语句。这样逐步推进,就可以完成对存储过程中所有操作的调试了。当然,也可以把存储过程中的 SQL 语句复制出来,逐段单独调试。
删除存储过程
drop procedure 存储过程名称;
小结
存储过程的优点就是执行效率高,而且更加安全,不过,它也有着自身的缺点,那就是开发和调试的成本比较高,而且不太容易维护。
在存储过程开发的过程中,虽然也有一些第三方工具可以对存储过程进行调试,但要收费。建议通过 SELECT 语句输出变量值的办法进行调试,虽然有点麻烦,但是成本低,而且简单可靠。如果存储过程需要随产品一起分发,可以考虑把脚本放在安装程序中,在产品安装的过程中创建需要的存储过程。
测试题:写一个简单的存储过程,要求是定义 2 个参数,一个输入参数 a,数据类型是 INT;另一个输出参数是 b,类型是 INT。程序体完成的操作是:b = a + 1
delimiter //
create procedure demo.test_add(in a int, out b int)
begin
set b = a + 1;
end
//
delimiter ;
-- 调用方法
mysql> call demo.test_add(1, @a);
Query OK, 0 rows affected (0.02 sec)
mysql> select @a;
+------+
| @a |
+------+
| 2 |
+------+
1 row in set (0.00 sec)

















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









