







说明
在上一篇文章中,我们对PPT网站的模板进行了爬取,该网站中,每个模板的详情网页直接包含目标资源的链接,因此只需遍历列表中的模板,依次提取链接即可,是一种十分简单的爬虫程序。对于某些稍微复杂些的网页,他们的资源链接并不会直接显示在HTML代码中,本次介绍这种略复杂网页的资源爬取。
核心思路
其实对于这种网页中资源链接的查找,我认为也并不复杂。众所周知,一个网络资源的下载是通过网络间的通讯实现的,即计算机网络中的三次握手,request和response。而我们要找到的就是代码中的request请求,其中必然包含了目标资源的链接。找出request请求是我们的主要任务,其他环节则与上一章所述基本相同。
找到网页中隐藏的目标资源链接
我们以“巨潮资讯网”为例,网站链接为:http://www.cninfo.com.cn/new/index
任意输入一个企业的代码,如600018(上港集团),获得如下界面:
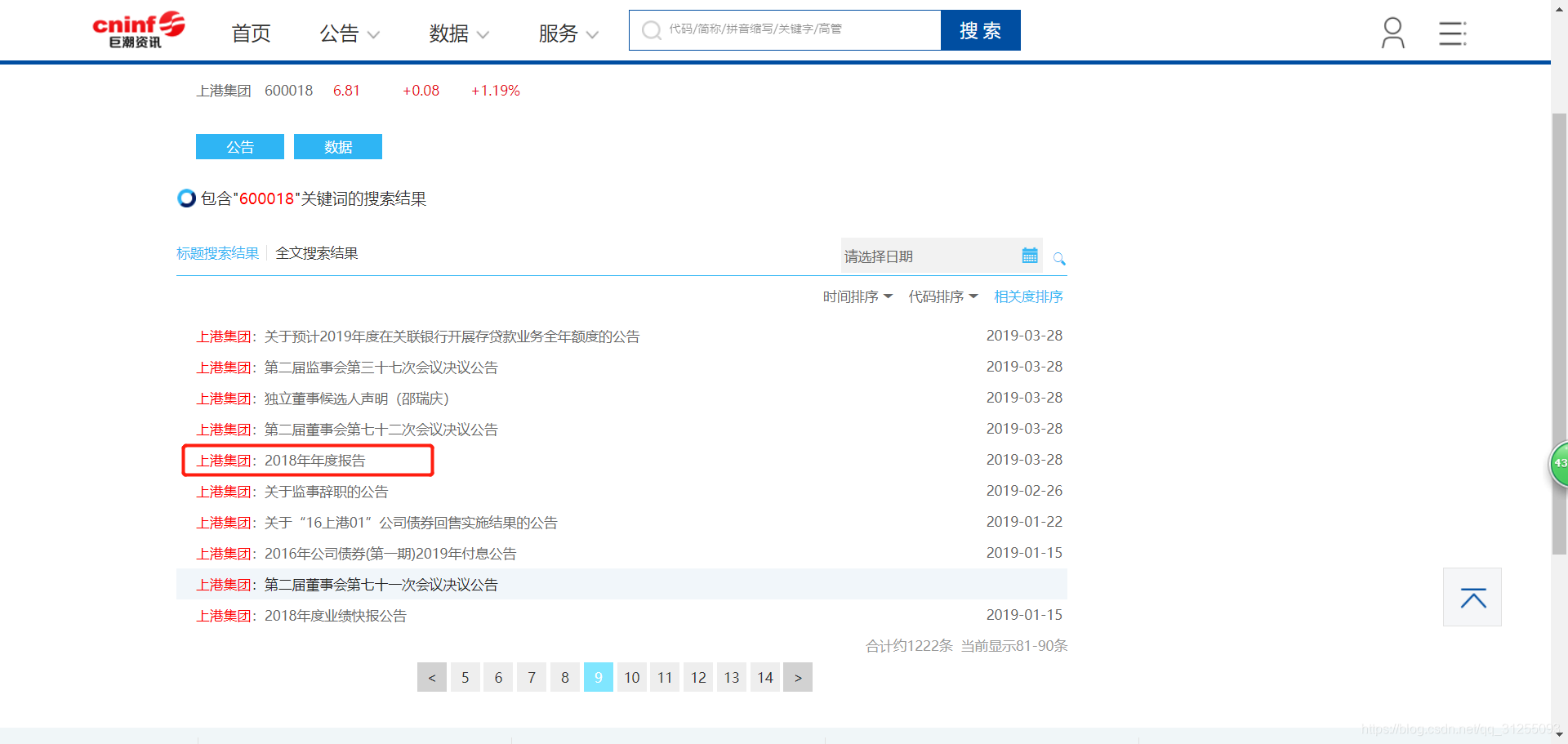
本次实践的目标是:从巨潮资讯网爬取给定代码列表所代表的企业的2018年年度报告。
具体分析过程如下:
1.查看该详情网页源代码,重点关注HTML代码中是否出现“2018年年度报告”的字样。最终定位到HTML代码中的如下部分:

可以看到,网页中上港集团的公告列表是通过分页插件实现的,包括我们想要的2018年年度报告在内的公告信
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









