







 这篇博客介绍了正则表达式中的关键概念,包括零宽断言的正预测先行断言和正回顾再发断言的区别,后向引用的概念及其在重复搜索匹配文本中的应用,以及平衡组和递归匹配的原理,提供了相关示例帮助理解。
这篇博客介绍了正则表达式中的关键概念,包括零宽断言的正预测先行断言和正回顾再发断言的区别,后向引用的概念及其在重复搜索匹配文本中的应用,以及平衡组和递归匹配的原理,提供了相关示例帮助理解。
正则表达式 -部分 目录:
正则表达式 - 部分
语法:
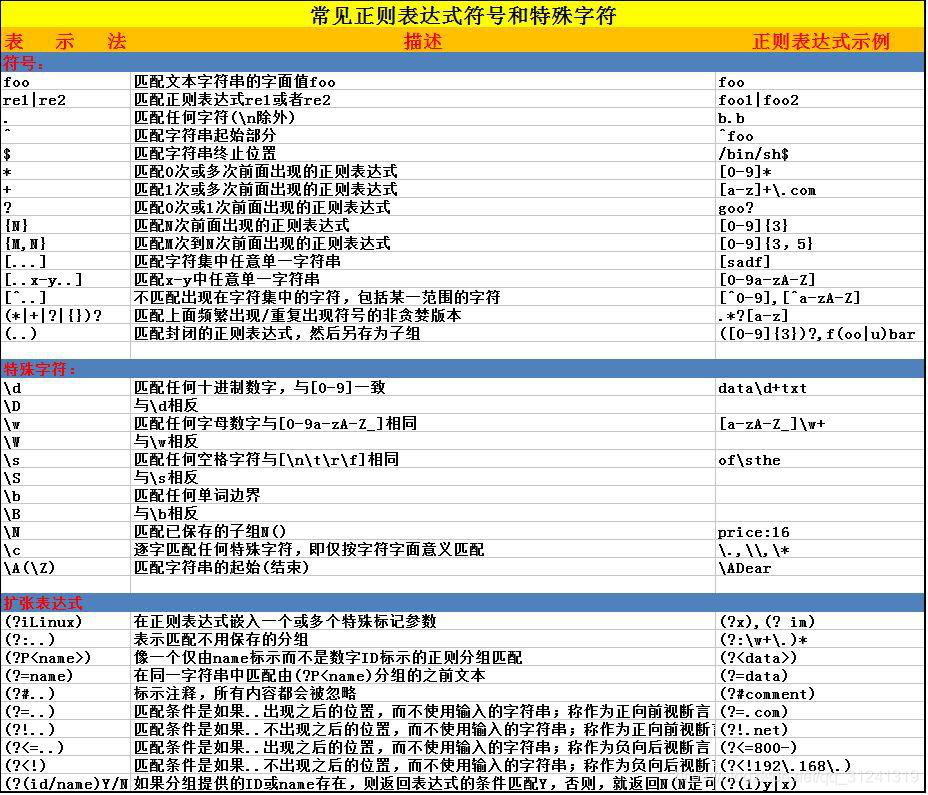
1. 零宽断言:
零宽度正预测先行断言 示例:
.*(?=</title>)
零宽度正回顾再发断言:
.(?<=<title>).*
如何区别?(仅供参考)
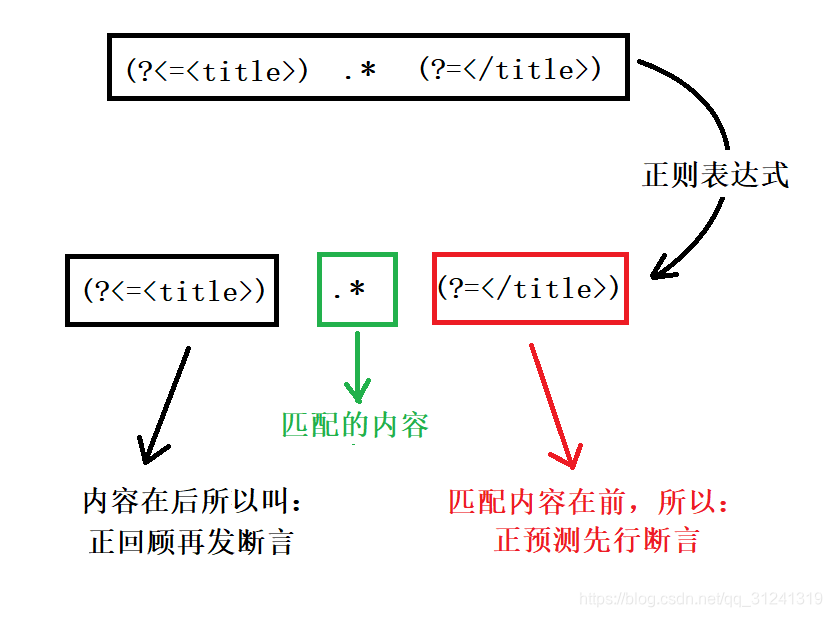
2. 后向引用:
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个 组号 ,规则是:
从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
组号是如何分配的呢?
分组0对应整个正则表达式
实际上组号分配过程是要从左向右扫描两遍的:
- 第一遍只给
未命名组分配- 第二遍只给
命名组分配-因此所有命名组的组号都大于未命名的组号
当然,你可以使用
(?:exp)这样的语法来剥夺一个分组对组号分配的参与权;
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。
后向引用 示例:
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, 或者kitty kitty。这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符\s+,最后是分组1中捕获的内容(也就是前面匹配的那个单词)\1。
你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:
?<Word>\w+(或者把尖括号换成'也行:?'Word'\w+)
这样就把\w+的组名指定为 Word 了。要反向引用这个分组捕获的内容,你可以使用\k<Word>,所以
上一个例子也可以写成这样:
\b(?<Word>\w+)\b\s+\k<Word>\b
使用小括号的时候,还有很多特定用途的语法。下面列出了最常用的分组语法:
| 分类 | 代码/语法 | 说明 |
|---|---|---|
| 捕获 | (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| (?exp) | 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name’exp) | |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 | |
| 零宽断言 | (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 | |
| (?!exp) | 匹配后面跟的不是exp的位置 | |
| (?<!exp) | 匹配前面不是exp的位置 | |
| 注释 | (?#comment) | 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
3. 平衡组/递归匹配
(?'group')把捕获的内容命名为group,并压入堆栈(Stack)(?'-group')从堆栈上弹出最后压入堆栈的名为group的捕获内容,如果堆栈本来为空,则本分组的匹配失败(?(group)yes|no)如果堆栈上存在以名为group的捕获内容的话,继续匹配yes部分的表达式,否则继续匹配no部分(?!)零宽负向先行断言,由于没有后缀表达式,试图匹配总是失败
平衡组常见应用示例:
<div[^>]*>[^<>]*(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*(?(Open)(?!))</div>
匹配HTML,这个例子可以匹配嵌套的<div>标签


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









