






一、问题出现的场景
使用原模型没有问题,但是改成我新fine-tune的模型后出现如题所示的问题。详细情况如下:
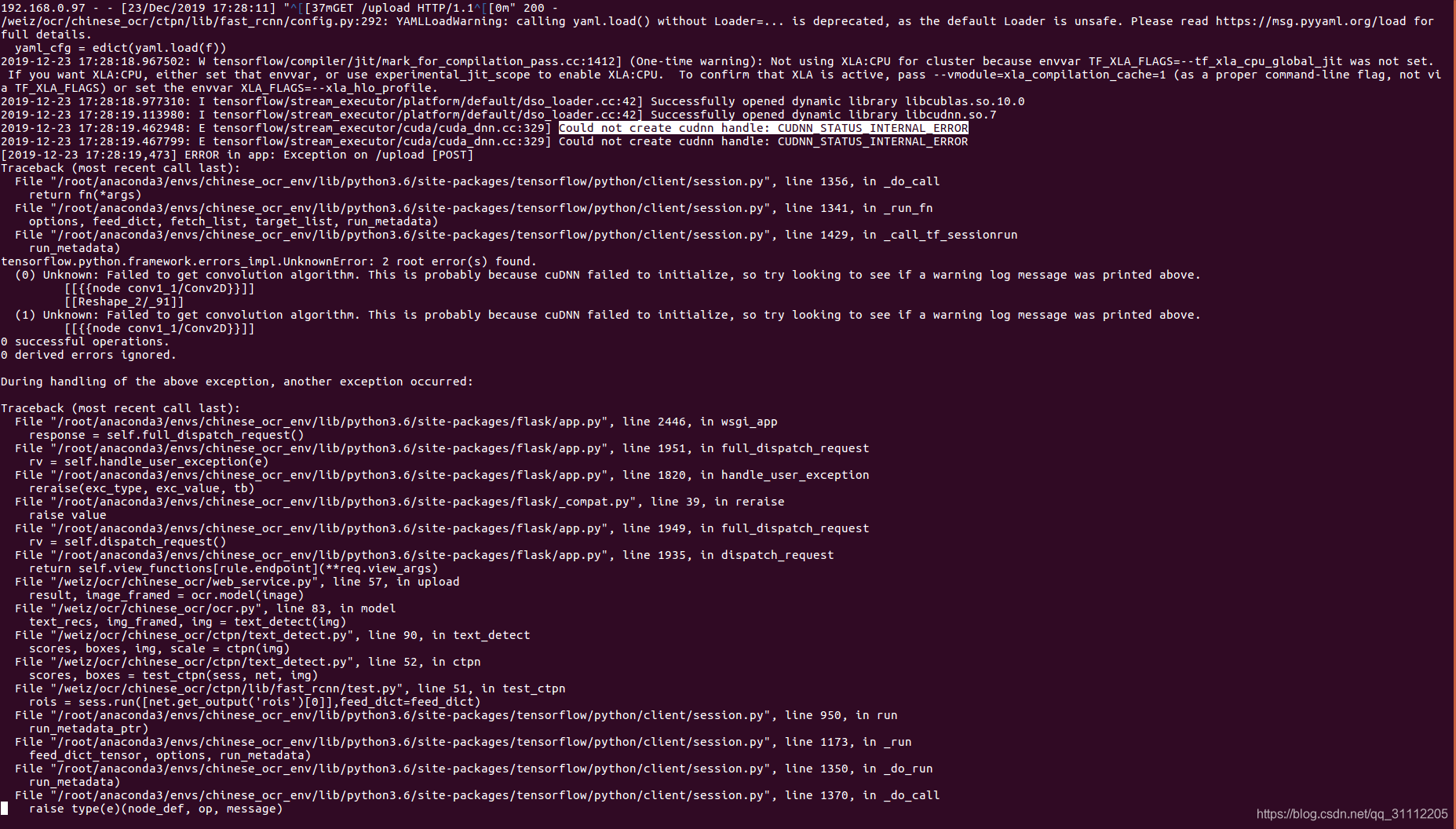
二、问题根源
从网上查找可知,该问题出现的情况还蛮多的,主要可能的原因如下:
- cuda和cudnn版本不匹配
如果电脑是第一次安装cuda和cudnn,出现这样的问题,那首先需要确定的是不是这个原因导致的了。安装好了cuda和cudnn后,安装tensorflow时最好是指定有成功案例的版本进行安装,这样成功率高一些。 - RTX显卡不兼容它生前的接口有关
如果是以前安装过cuda和cudnn并且可以使用,只是升级了显卡、升级了tensorflow啥的,最先考虑的问题就应该是这个了。解决办法就是在程序的开始处加上如下代码:from tensorflow.compat.v1 import ConfigProto # 根据tensorflow版本而定 from tensorflow.compat.v1 import InteractiveSession config = ConfigProto() config.gpu_options.allow_growth = True session = InteractiveSession(config=config) - 这个情况不知道具体原因,只能提供具体的解决方法。在任意终端执行如下命令或者重启电脑。
# 命令的后面一定边不要漏掉“/”,否则会提示“.nv”是目录, 另外“~”前边有空格 # ~/.nv/文件夹下是一些缓存信息,所以这一步的目的就是删除~/.nv/内的缓存信息 sudo rm -rf ~/.nv/ - 显存不够或者本来是够的但是使用不当而导致。我遇到的场景如下:原本能够正常使用5990个字符识别,但是改成经过fine-tune后能够识别5993个字符模型后就出现如题所示的问题。解决方法如下(中文注释出):
def load_tf_model(): # load config file cfg.TEST.checkpoints_path = './ctpn/checkpoints' # 原本的参数是:per_process_gpu_memory_fraction=1.0 gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.4) config = tf.ConfigProto(allow_soft_placement=True, gpu_options=gpu_options) sess = tf.Session(config=config) # load network net = get_network("VGGnet_test") # load model print('Loading network {:s}... '.format("VGGnet_test")) saver = tf.train.Saver() try: ckpt = tf.train.get_checkpoint_state(cfg.TEST.checkpoints_path) print('Restoring from {}...'.format(ckpt.model_checkpoint_path)) saver.restore(sess, ckpt.model_checkpoint_path) print('done') except: raise 'Check your pretrained {:s}'.format(ckpt.model_checkpoint_path) return sess, net


















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









