



 本文探讨了人工智能的发展。从起源看,其范围宽泛。早期采用规则思路,经历两次寒冬。机器学习从数据总结规则,让自然语言处理获新生。深度学习是机器学习分支,曾被冷落,后引发人工智能热潮。目前深度学习成果显著,但未知仍多。
本文探讨了人工智能的发展。从起源看,其范围宽泛。早期采用规则思路,经历两次寒冬。机器学习从数据总结规则,让自然语言处理获新生。深度学习是机器学习分支,曾被冷落,后引发人工智能热潮。目前深度学习成果显著,但未知仍多。
AI杂谈
复制自我的知乎文章:https://zhuanlan.zhihu.com/p/665478698
-
前言
-
人工智能的提出:机器能“思考”吗?
-
早期的人工智能:规则与两次人工智能寒冬
-
机器学习:从规则到统计。
-
深度学习:十年寒窗无人问,一举成名天下知
-
后语
1.前言
众所周知,近年来AI(artificial inteligence,人工智能)领域取得了令人瞩目的成就。
不久前还被嘲笑生硬的聊天机器人,依托ChatGPT打了漂亮的翻身仗。大模型生成的文案(AI作图)已经令不少画师叹为观止。几年前还被认为非常困难的长文本翻译、语音识别等技术也早已无声无息的渗透到生活中。(比如谷歌或百度的整篇论文翻译、微信的语音转文本聊天等)。
AI技术的普及在为公司带来实实在在的商业利益的同时,也成为媒体大肆炒作的对象。“人工智能”、“机器学习”、“神经网络”、“深度学习”等字眼出现在不计其数的文章中,这些文章大都出自非专业人士之手。
不到几年时间,被媒体宣判因AI而成为夕阳职业的已达数十种,从电话销售员到货车司机,甚至从事AI的研发人员。如今,ChatGPT的作文能力让这种危机也终于降临到了媒体行业自己头上。
各路大佬加入论战,则让前景显得更加扑朔迷离。偶尔出现的一些对AI的质疑声,也迅速淹没在了各种震惊体里。
如今,新研发一款产品,不带AI功能都不好意思发布。
那么,未来的人工智能究竟会成为让我们社会更加美好的工具,还是如媒体所描述的那样,变成奴役人类的恶龙?
要回答这些问题,我们需要从一些基本概念谈起。
比如,当我们在谈论AI时,我们到底在谈论什么。什么是人工智能?什么是机器学习?什么是深度学习?什么是神经网络?模型又是什么?
让我们先从人工智能谈起。
2.人工智能的提出:机器能“思考”吗?
如果古代的科幻作品不算在内的话,,可能最接近现实的对于人工智能的谈论要回溯到1843年。
当时的伯爵夫人对巴贝奇设想的分析机(有点类似于计算机)评论道:“分析机谈不上能创造什么东西,他的本分是帮我们实现我们已知的事情”。
换句话就是:机器永远是机器。
但显然,人工智能的先驱图灵并不这样认为。
1950年,图灵在《思想》杂志上发表了著名的论文《可计算的机器与智能》。论文开篇提出了“机器能思考吗”这个经典问题,并设计了一个他认为和这个问题等价的游戏–著名的图灵测试。
如图1所示,如果测试者无法分辨出遮挡物后面和他对话的是人还是机器,则可以认为机器拥有了智能。
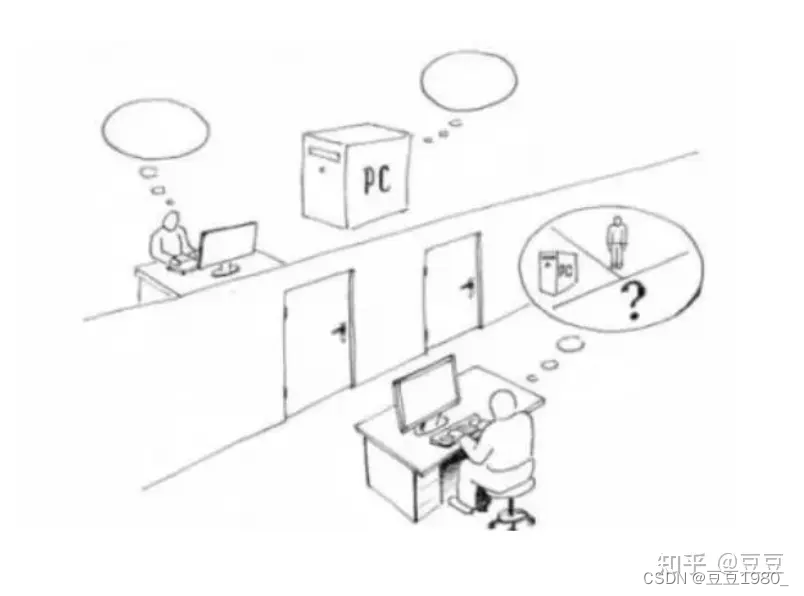
图1
以这个标准来看,ChatGPT似乎已经接近通过图灵测试(如果不是完全通过的话)
1956年,麦卡锡在达特茅斯学院发起了著名的人工智能夏季研讨会,并邀请香农、明斯基等一流科学家参加。会议的起因基于如下设想:
第一,所有类似于学习或智能的东西都能被精确描述。第二,机器能够模仿这个过程。
如果一群优秀的科学家聚在一起讨论一段时间,应该会碰撞出点什么吧?
2个月过去了,这些世界上最聪明的头脑并没有提出出色的解决方案。但是会议的意义在于,他们开辟了一个对人类影响深远的新的研究领域—人工智能。达特茅斯学院的夏季研讨会第一次正式提出了人工智能的概念,通常这一年,也被认为是人工智能元年。
从起源来看,人工智能的范围非常宽泛:所有将智力活动自动化的都属于人工智能。
从这个意义说,Excel表格,以及广联达早期的造价软件也都属于人工智能。
3.早期人工智能:规则与两次人工智能寒冬。
早期的人工智能采用的模仿人的学习机制这个路线,这被称为符号主义:只要精心设计足够多的规则,机器就能够达到和人一样的智能。
此时的人工智能模型如图2所示。人制定好规则,输入数据,机器根据规则对数据进行变换,给出结果。

图2
当时的人们对人工智能极度乐观。顶级专家相信,用不了多久,机器就能像人一样思考。
然而,直至今日,这个目标仍未实现。
过高的期望最终变成了失望。第一次人工智能冬天来临了。政府撤资,研究人员改换方向。
80年代出现的“专家系统”仍然是基于规则的,最初在几个项目上获得了成功,这再次引起了人们对于人工智能的期待,并引发了第二次人工智能的夏天。
然而到了90年代人们发现这些系统既难以扩展,又难以维护,解决的问题也有限。人工智能的第二次冬天来临了。
采用规则的思路对于某些类型应用(比如棋类)还可以应对,但是对于图像、语言这种模糊的问题就难以处理了。
以自然语言处理(自然语言的机器处理)为例。
早期采用的主流方法都是制定语法规则,然后把句子解析为语法树,如图3所示。
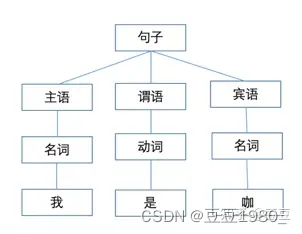
图3
看起来非常合理。
但是句子稍微一复杂,就容易出错,比如:”校服上别别别的东西”。
到后来人们发现,即使只支持实际中不到1/5的语句,用到的规则也会达到上万条。再之后,几乎每新支持一个句子,就要新加入一些规则。而且后加入的规则还会和以前的规则产生矛盾。这样就陷入了无法解决的困境。
后来,这条路终于走到了尽头。
四、机器学习:从规则到统计。
机器学习是人工智能的一个分支。
规则方法的局限性使得一些人开始另辟蹊径:能不能设计一种算法,从数据中去总结规则(知识),然后再把总结出的规则用到新的数据中?
这个从数据中总结规则的过程就是所谓的“学习”,如图4所示。

图4
仍以自然语言处理为例。
通过引入统计的方法进行机器学习,停滞已久的自然语言处理获得了新生。现代自然语言处理的鼻祖贾里尼克领导的IBM华生实验室,用统计的方法,把语音识别的指标从70%多一口气提高到90%,震惊了学界。
而他的基本思路也很简单:一个句子是人话的程度和句子出现的概率成正比。
比如:
正常一句话:“研究表明,汉字顺序并不定一影响阅读”,没有任何问题。
稍微打乱次序:“研表究明,汉字序顺并不定一影阅响读”,虽然略觉异常,但意思仍然明确。
但是如果改为“阅顺究汉, 明字影序响表不读定一研并”就完全不知所云了。
为什么?
语言学家会说第三个句子不合语法。但贾里尼克认为这种现象可以从句子出现的概率角度来解释。比如通过统计,假设第一个句子出现的概率为0.01,第二个句子也许概率就成了0.005,第三个句子概率没准就降到了0.000000000001。自然,大家就觉得第三个句子有问题了。
贾里尼克教授的玩笑“每开除一名语言学家,我的语音识别系统就提高一个百分点”在业界广为流传。而那些语言学家正是制定语法规则的主力。
时至今日的ChatGPT,原理层面仍然没有逃出这个框架。
机器学习在90年代之后蓬勃发展,并且在工业界落地了很多应用。
五、深度学习:十年寒窗无人问,一举成名天下知
深度学习又是机器学习的一个分支。
深度学习中的“深度”一词并不是指它比别的算法对问题理解更深刻,而是指这种算法用很多层来对数据进行表示。所以深度学习可能叫做分层学习更合理。
虽然对深度学习的研究已经可以追溯到上世纪50年代,但是长期以来,深度学习都扮演着被冷落的角色。
当朴素贝叶斯、支持向量机在学术界大行其道时,深度学习只配放到相关的书籍中的某一章来介绍。
然而,时代的主角最终选中了深度学习。
深度学习最早成功的应用在于1989年,贝尔实验室的严乐春(Yann LeCun)用卷积神经网络实现了邮件上面手写数字的读取,并成功应用到了美国邮政系统中。
翻过21世纪前十年,深度学习突然火爆起来,并几乎以一己之力引发了人工智能的第三个夏天。
图像识别、机器翻译、语音合成等困扰业界已久的难题逐个被突破,里程碑一个接一个出现。
普遍认为,这是硬件、数据、算法共同作用的结果。
我们平常所说的神经网络几乎等同于深度学习。不过这个容易让人误解的名字,除了最早期的一点点灵感,它与神经几乎没有任何关系。它的的基础是数学,和仿生学尤其是人的学习机理相去甚远(比疾病机理更复杂的人的学习机理,目前应该仍未搞清楚)。
6.后语
总结来说,机器学习是人工智能的分支,深度学习是机器学习的分支。他们的关系如图5。
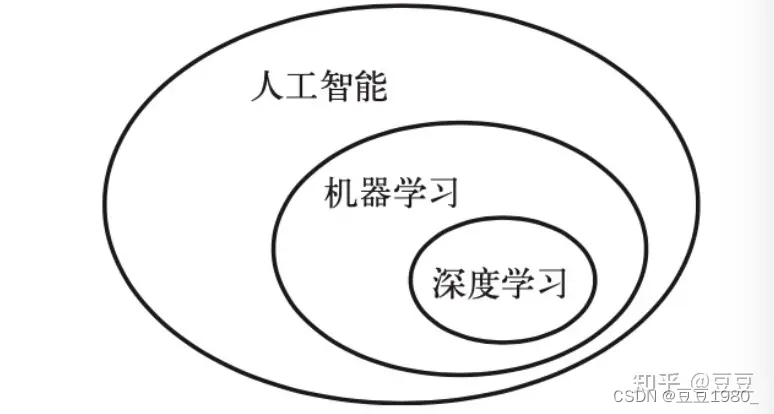
图5
神经网络约等于深度学习。模型就是从数据中学习到的规则。
人工智能以模仿人类智力活动为最初目标,但最终逐渐的走向了数学。
目前,深度学习已经在各行各业引发了革命,尽管它还未完全走向人们生活的中心。基于深度学习(当然还有部分强化学习)的ChatGPT甚至被比尔盖茨誉为1980年以来最具革命性的技术进步。
人类已经经历了两次人工智能从夏天到冬天的循环,目前正处于第三次热潮中。
不过和前两次不同的是,深度学习的确已经引起了世界的变革,而且这变革还将继续下去。
人工智能,尤其是深度学习已经取得并将继续取得更多令人惊艳的成果,但这仍然改变不了它是以数学(尤其是统计学、微积分、优化)为基础的一个工具的事实。
基于这个事实,讨论机器是否具有人类情感显得不合时宜,担忧机器会统治人类更是为时尚早。
对人工智能来说,未知远大于已知。第三次人工智能冬天是否会来临?基于统计的方法足够达到通用人工智能吗?符号主义能否卷土重来?以及人工智能最终形态是啥样?这些都没有答案。(可能唯一确定的是AI的发展确实会造成失业,而不加以规划的话,新的职业也不会凭空产生)
虽然有论文声称ChatGPT已经达到了AGI(通用人工智能)标准,不过从实现机理来看,它更像是基于统计学的“大力出奇迹”。我们不必惊讶它会犯一些看来非常明显的常识性错误,因为本质来说,它并没有任何逻辑_。
不过,说不好就像人类学会飞翔最终并不是通过仿生学(模仿鸟类制造大翅膀),而是
通过空气动力学(制造飞机)一样,深度学习也许会以一种不同于人类认知的方式来实现机器智能(可能机器智能比人工智能更贴切),并最终把我们带入智能时代。
这个时代已经开始到来。
参考目录:
《数学之美》吴军
《可计算的机器与智能》图灵
《python深度学习》弗朗索瓦·肖莱
《机器学习》周志华
《AGI的火花》微软
欢迎使用Markdown编辑器
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
查找:Ctrl/Command + F
替换:Ctrl/Command + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片: 
带尺寸的图片: ![]()
居中的图片: 
居中并且带尺寸的图片: ![]()
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' | ‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" | “Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash | – is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图:
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎

















 8803
8803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









