







红酒质量探索
# 加载你最终使用的所有组件
# 在这个代码块的分析中。
# 注意,在这个代码块中,将参数 "echo" 设为假。
# This prevents the code from displaying in the knitted HTML output.这可以避免代码混入 HTML 输出显示。
# 应当在文件中,对所有代码块设为 echo=FALSE 。
# 导入包
library(ggplot2)
library(dplyr)
library(knitr)
library(gridExtra)
library(gpairs)
library(RColorBrewer)
这份报告探索了一个包含大约1600条红酒质量和其属性的数据集。在整个流程中,我们的目标是了解哪个化学成分影响红葡萄酒的品质。
# 加载数据
pf <- read.csv("wineQualityReds.csv")
#查看变量及数据类型并进行汇总
str(pf)
summary(pf)

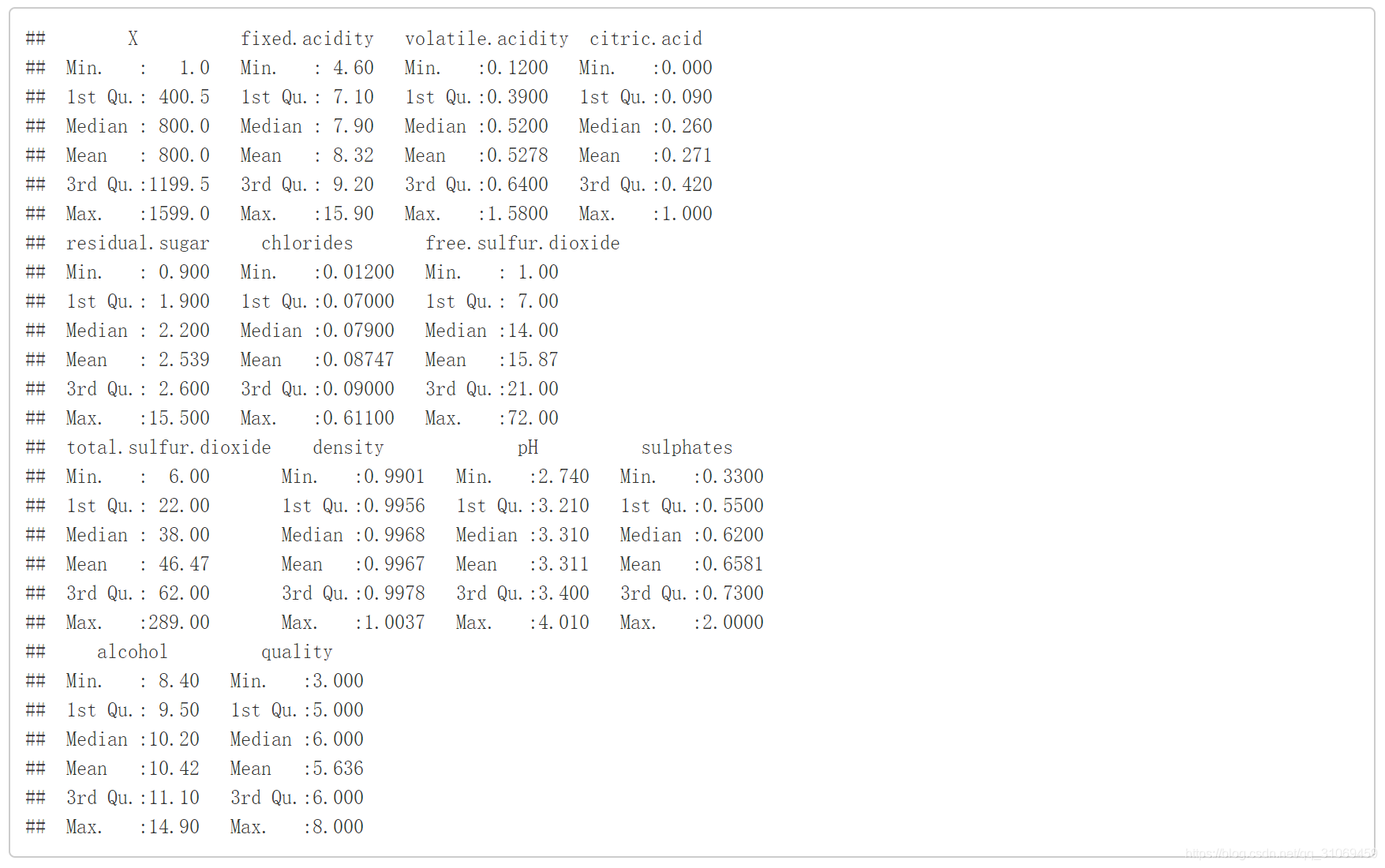
# 通过观察数据集发现X只是数据的index, 对后续的数据分析没有实际意义
# 我们将移除X列
pf <- subset(pf,select = -c(X))
单变量绘图选择
quality探索
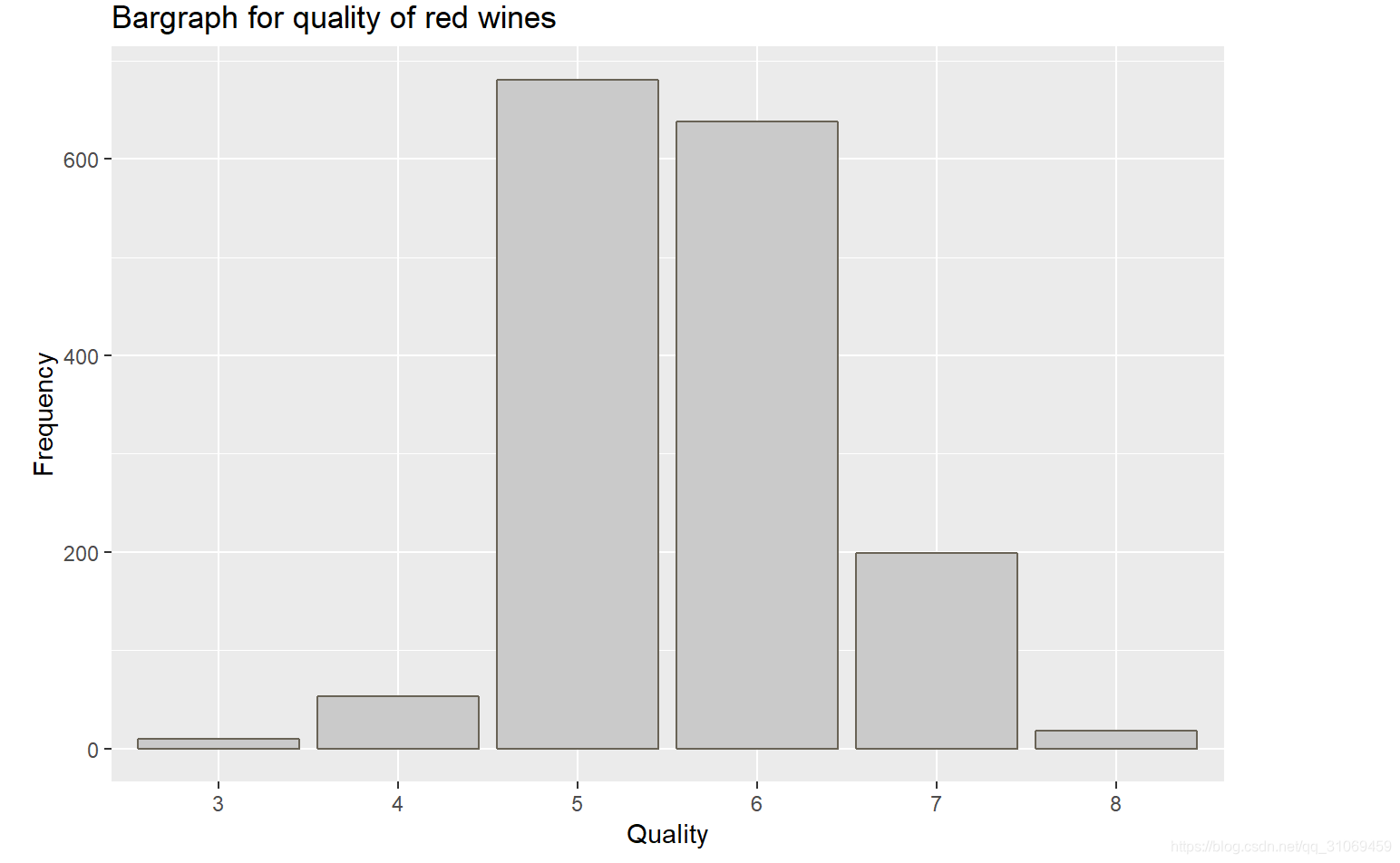
# 通过ggplot函数来绘制变量quality的条形图
ggplot(data = pf, aes(x=factor(quality))) +
# 填充颜色
geom_bar(color = "#696356",
fill = "#CACACA")+
# 设置标签及标题
labs(x = 'Quality', y = 'Frequency',
title = 'Bargraph for quality of red wines')
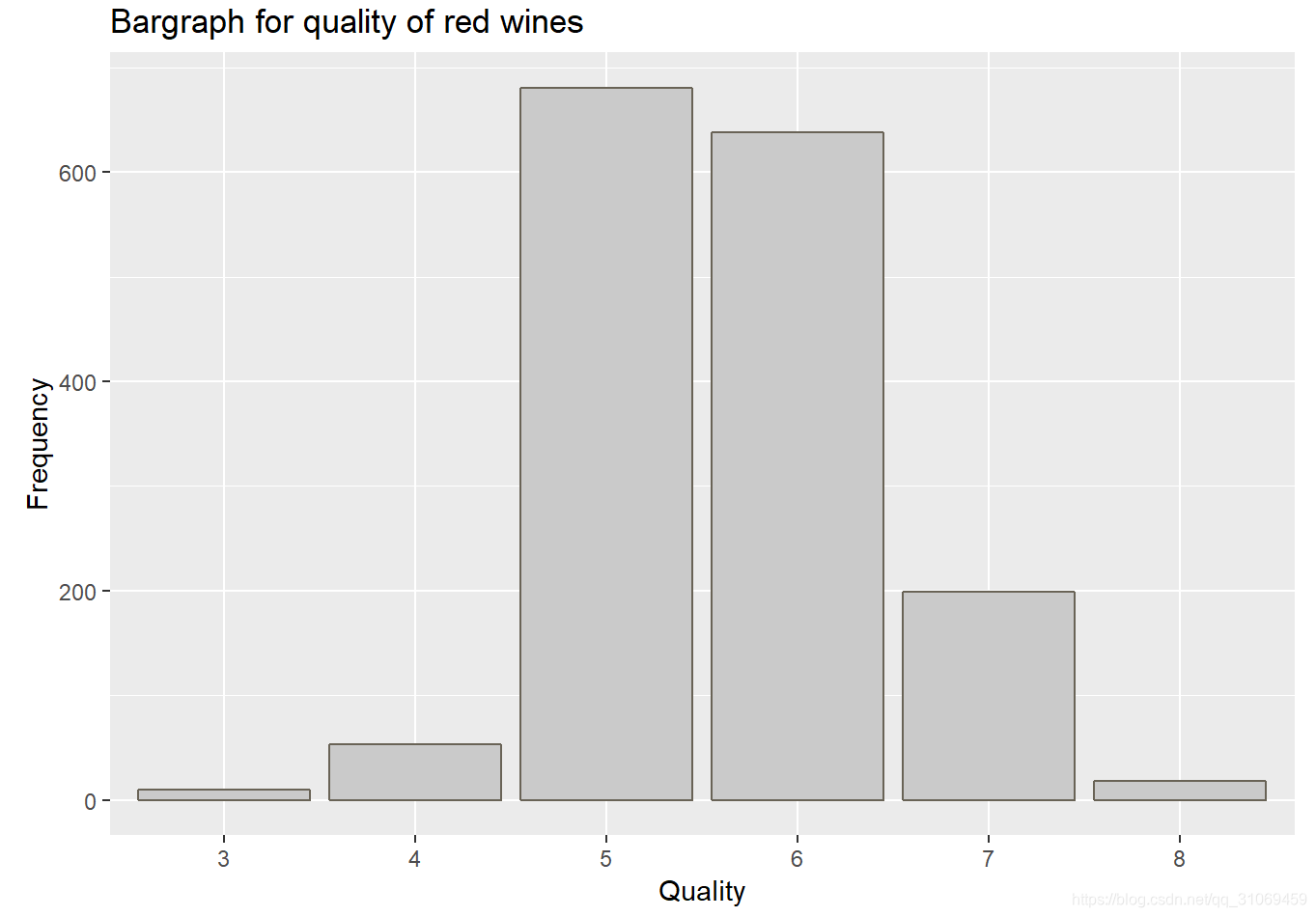
红酒质量的评分集中在5~6分,75%的评分小于6分,最低值为3分,最高值为8分,平均值为5.6分。
fixed.acidity探索
# 绘制变量fixed.acidity的直方图
# 并将其保存到变量p1中
p1 <- ggplot(aes(x = fixed.acidity),
data = pf)+
# 调整组距,填充颜色
geom_histogram(binwidth = 0.5,
color = "#696356",
fill = "#CACACA")+
# 添加scale_x_continuous层
# 并设置limits & breaks
scale_x_continuous(limits = c(4.5,16),
breaks = seq(4.5,16,1))
# 添加scale_x_log10()层,对长尾数据进行对数转换
# 并保存到变量p2中
p2 <- ggplot(aes(x = fixed.acidity),data = pf)+
geom_histogram(color = "#696356",fill = "#CACACA")+
scale_x_log10()
# 将p1,p2两个变量分别传递给grid.arrange()
# 并设置两图形以一列的形式展示
grid.arrange(p1,p2,ncol = 1)
# 使用summary命令对变量fixed.acidity进行汇总统计
summary(pf$fixed.acidity)

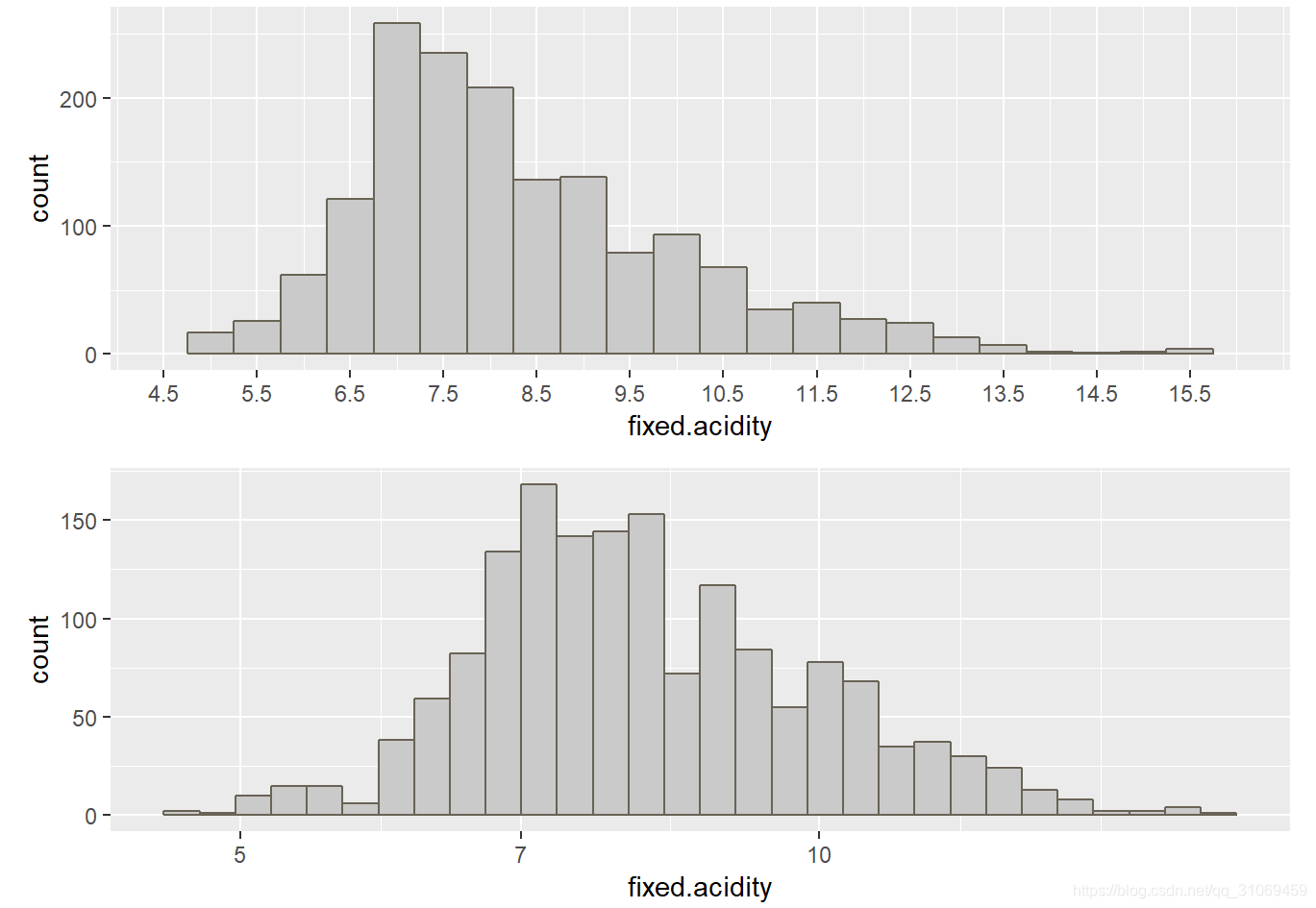
固定酸度数据集呈右偏太分布,对数据进行log10转换,转换后的数据基本呈正太分布,数据集中在6.5~9g/dm^3 之间。
75%的数据是小于9.2g/dm^3 。我想知道红葡萄酒的固定酸与其品质之间的关系。
# 在变量fixed.acidity的直方图基础上添加facet_wrap层
# 通过变量quality将直方图分割为6个直方图
ggplot(aes(x = fixed.acidity),
data = pf)+
# 为每个直方图设置组距并填充颜色
geom_histogram(binwidth = 0.5,
color = "#696356",
fill = "#CACACA")+
# 为每个直方图设置limits & breaks
scale_x_continuous(limits = c(4.5,16),
breaks = seq(4.5,16,1))+
# 设置标度scale为“free”,各直方图坐标轴数据可以不相同
facet_wrap(~quality,
scales = "free",
ncol = 2) # 按照两列来展示图形
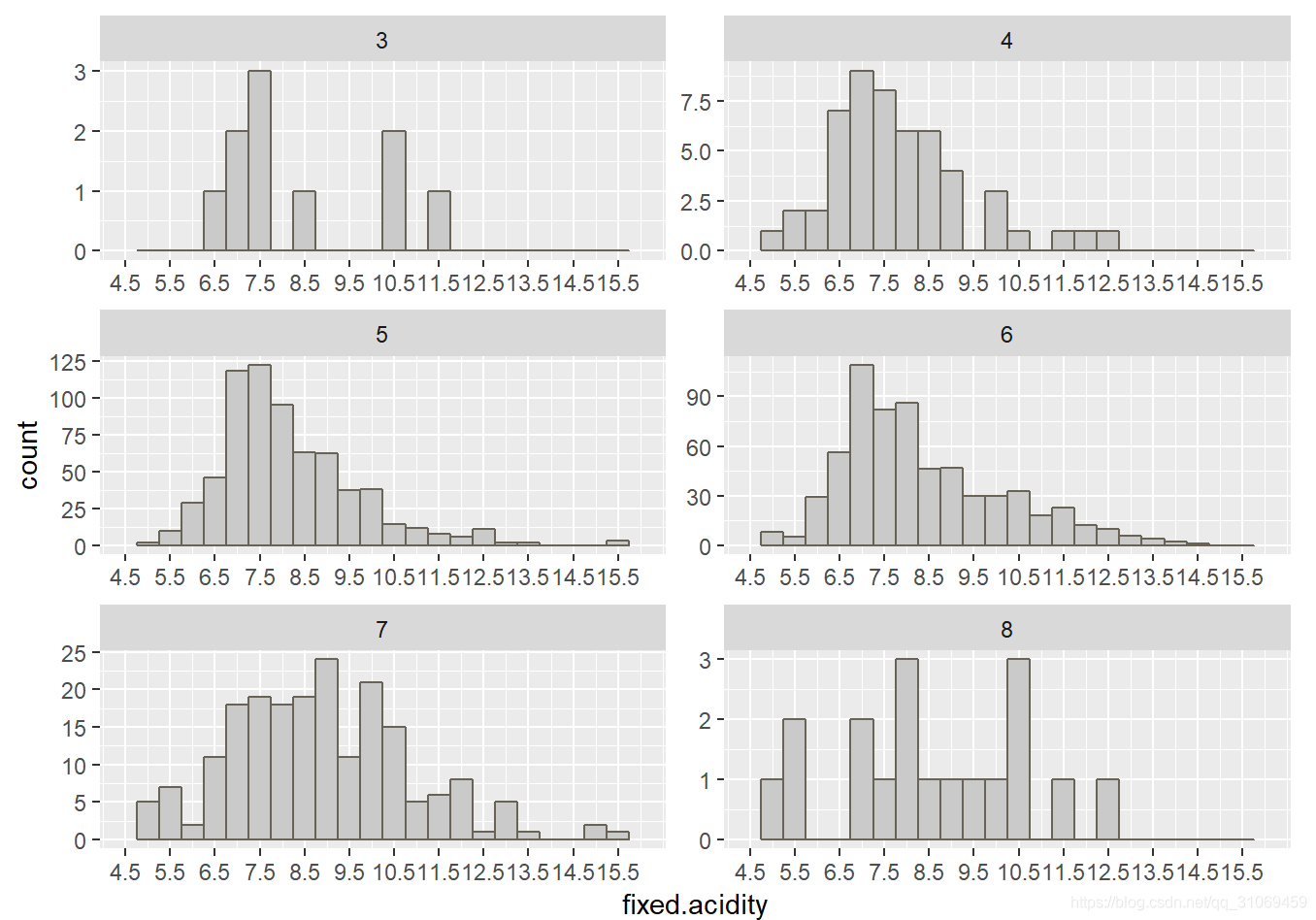
添加分面图层后,我们将直方图基于分类变量quality分成了六个直方图。
图中数据代表红葡萄酒质量评分3 ~ 8分分别对应其固定酸的直方图。
质量评分为3 的计数较少,固定酸数据从6.5g/dm^3 ~ 11.5g / dm^3 分布较零散.
质量评分是5 ~ 7分的固定酸数据主要分布在6.5 ~ 10g/dm^ 3,三者中均有固定酸达到14g / dm ^3 以上的高酸度数据.
质量评分为8分的计数量也较小,其固定酸分布较离散,大部分集中分布于7 ~ 10.5g / dm^3 之间。
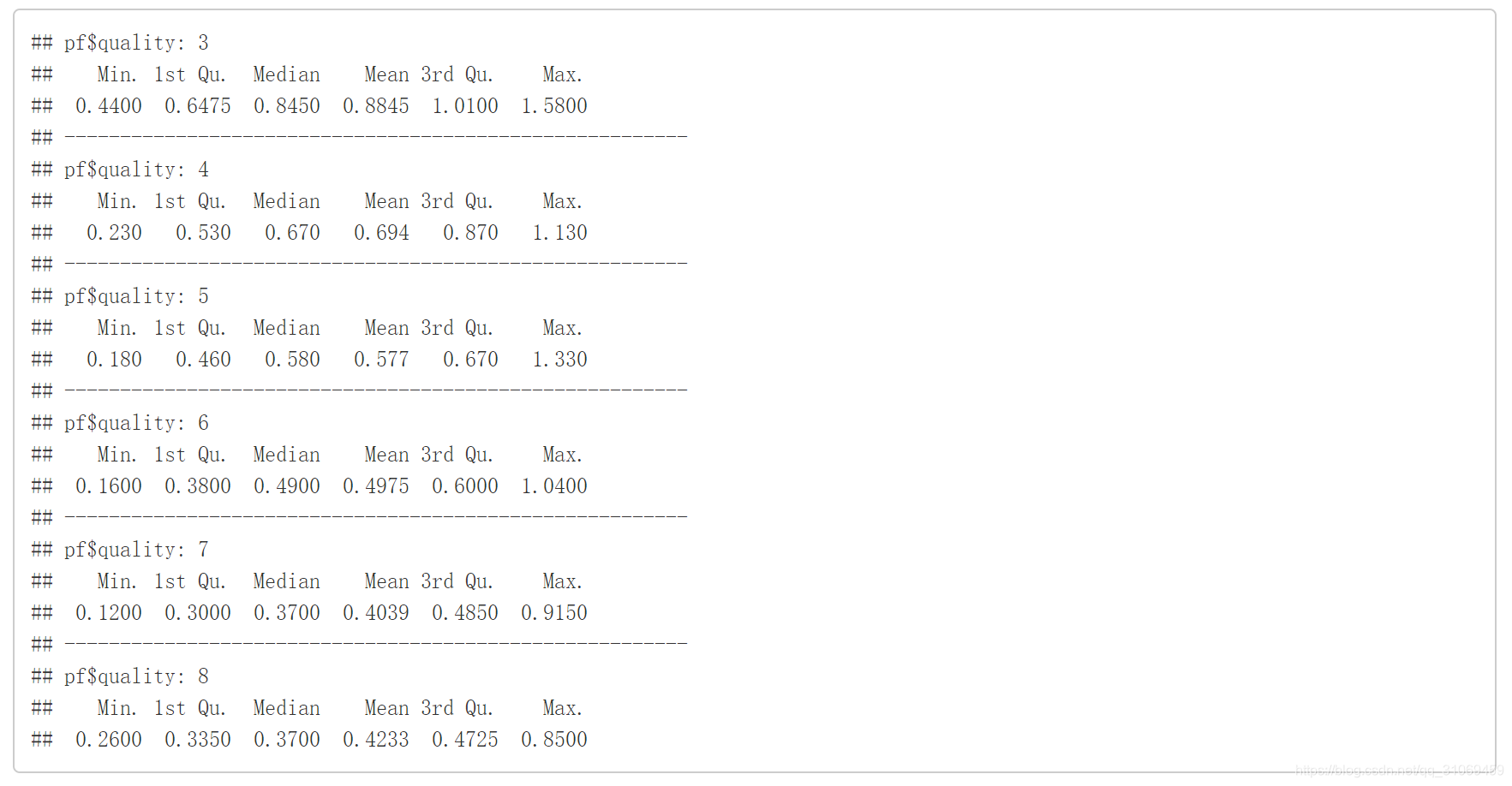
# 通过by命令统计出不同quality的fixed.acidity汇总
by(pf$fixed.acidity,pf$quality,summary)
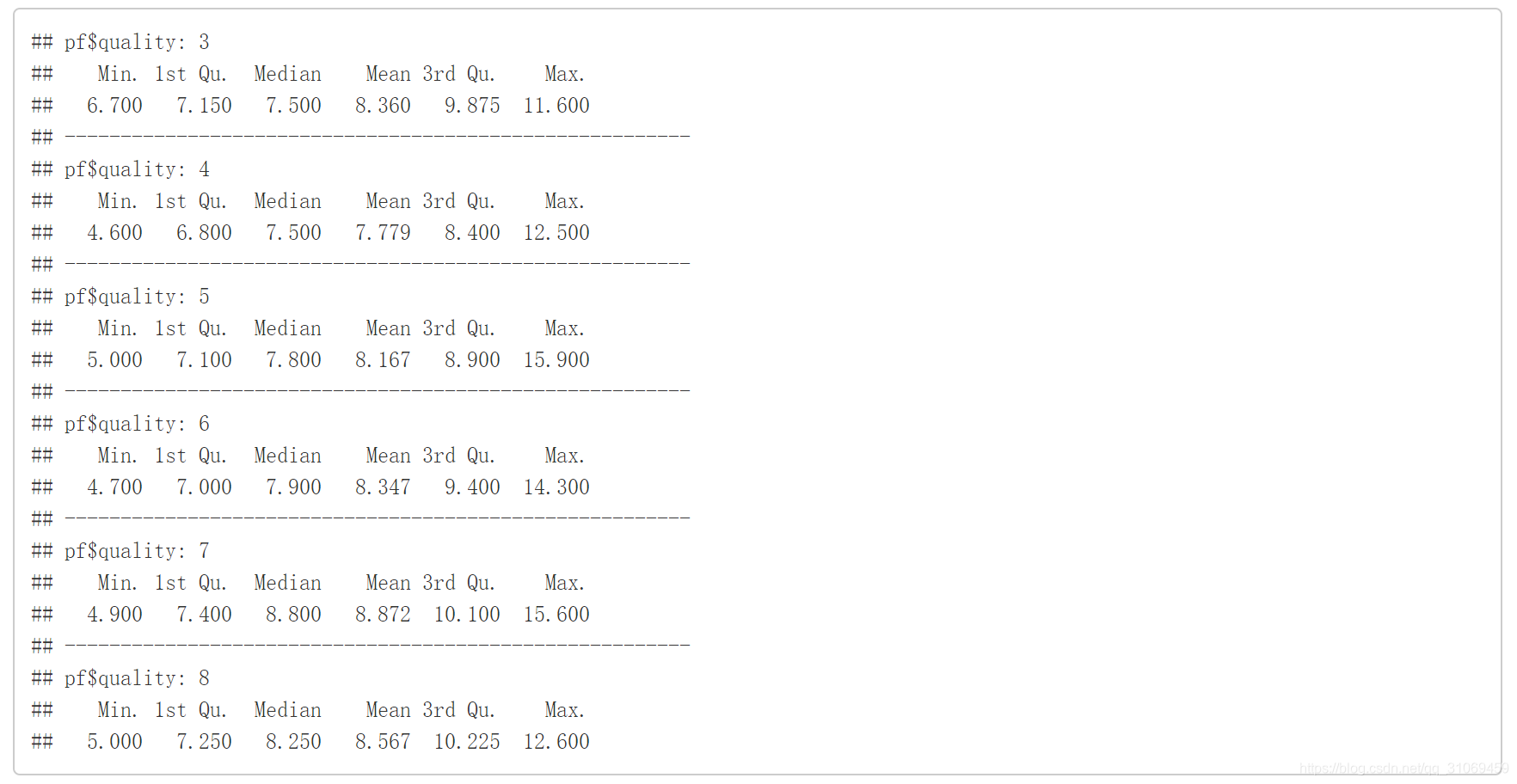
使用汇总命令对不同质量下固定酸数据进行汇总统计。
# 通过ggplot绘制变量quality与变量fixed.acidity的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = fixed.acidity),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)+
# 添加coord_trans图层限制y轴
coord_trans(limy = c(4.5,13.5))
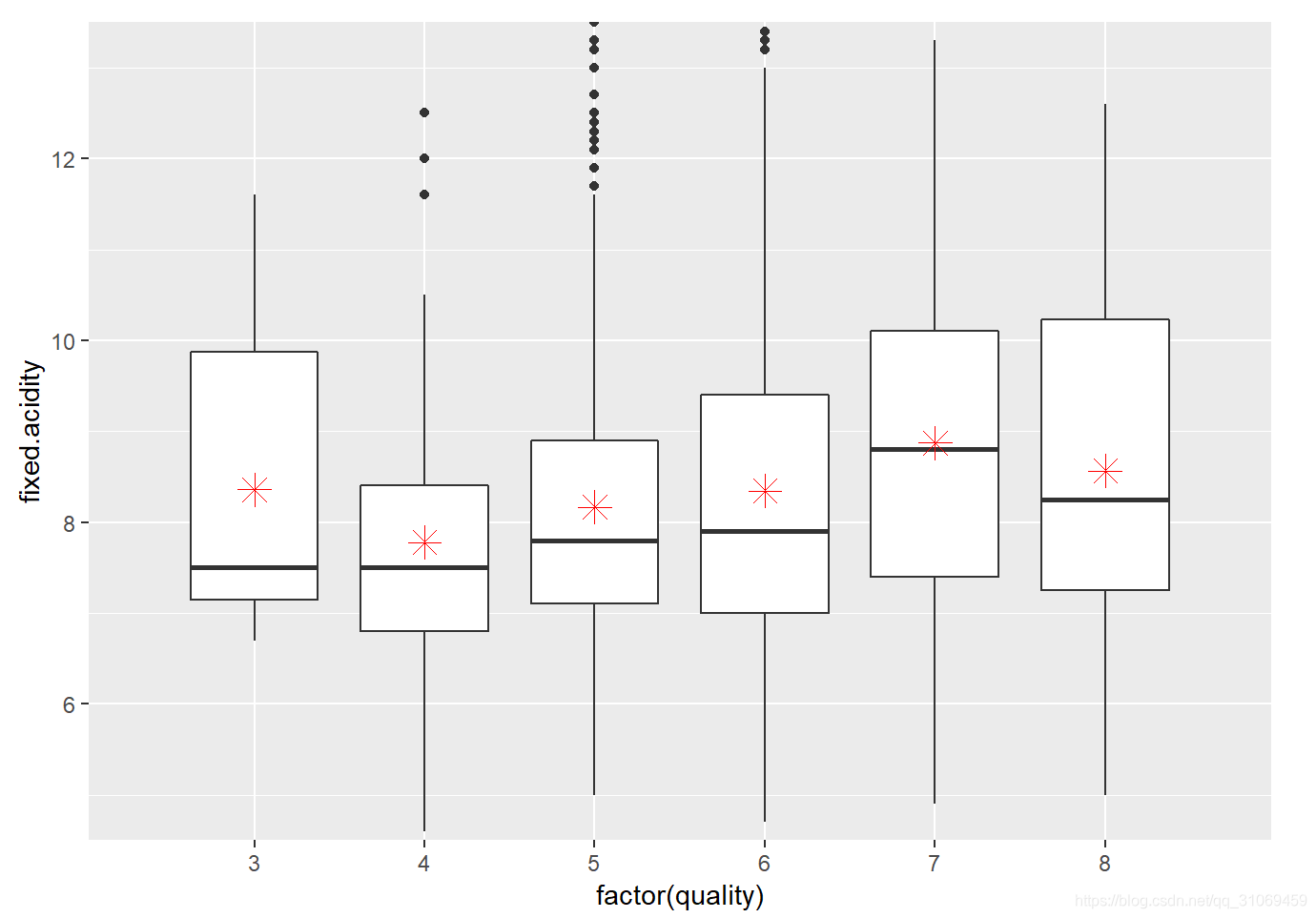
我们按照质量生成固定酸度箱线图,这样可以快速看到分布之间的差异,特别是六个组中位数之间的差异.
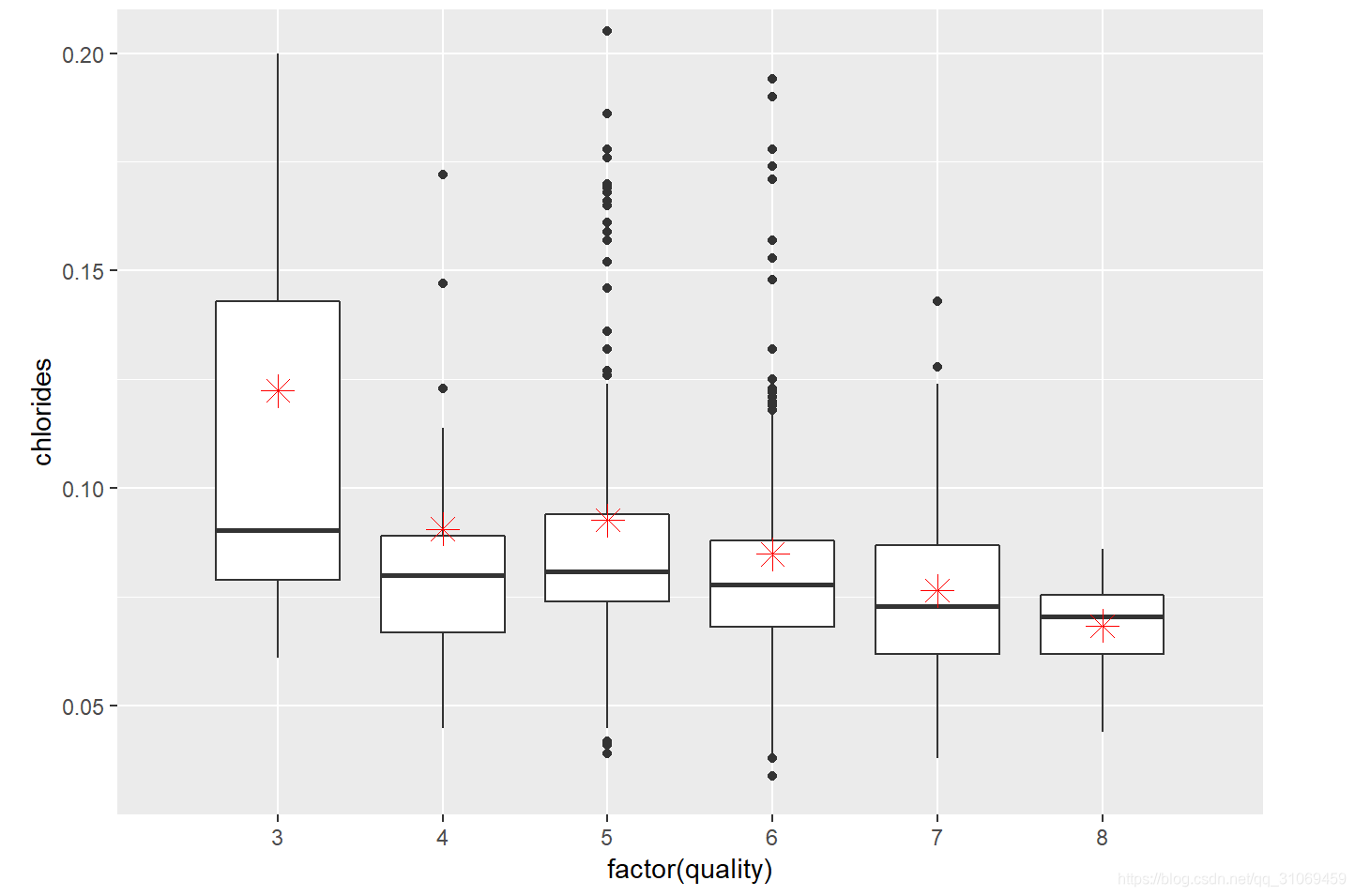
去掉异常值,取小于13.5g/dm^ 3的固定酸数据。质量评分是3 ~ 4分的固定酸中位数相同均为7.5 g / dm^ 3,
质量评分为5 ~ 6分的固定酸中位数不相上下,分别为7.8 g / dm^3 , 7.9g/dm^3,
评分为7 ~ 8分的固定酸中位数分别为8.8 g / dm^ 3 ,8.25 g / dm^ 3。
图中红色点代表基于quality分组下的固定酸平均值。从以上的汇总统计数据及中位数与箱线图的分布来看,随着红葡萄酒质量的提升,固定酸有一定的提升,但是当葡萄酒质量达到比较好的状态时,固定酸会处于一个恒定水平,不会再增长。
volatile.acidity探索
# 通过ggplot函数来绘制变量volatile.acidity的直方图
# 并将其保存到变量p1中
p1 <- ggplot(aes(x = volatile.acidity),
data = pf)+
# 调整组距,填充颜色
geom_histogram(binwidth = 0.05,
color = "#696356",
fill = "#CACACA")+
# 添加scale_x_continuous层,并设置limits&breaks
scale_x_continuous(limits = c(0.1,1.6),
breaks = seq(0.1,1.6,0.1))
# 添加scale_x_log10()层,对长尾数据进行对数转换
# 并保存到变量p2中
p2 <- p1 + scale_x_log10()
# 将p1,p2两个变量分别传递给grid.arrange()
# 并设置两图形以一列的形式展示
grid.arrange(p1,p2,ncol = 1)
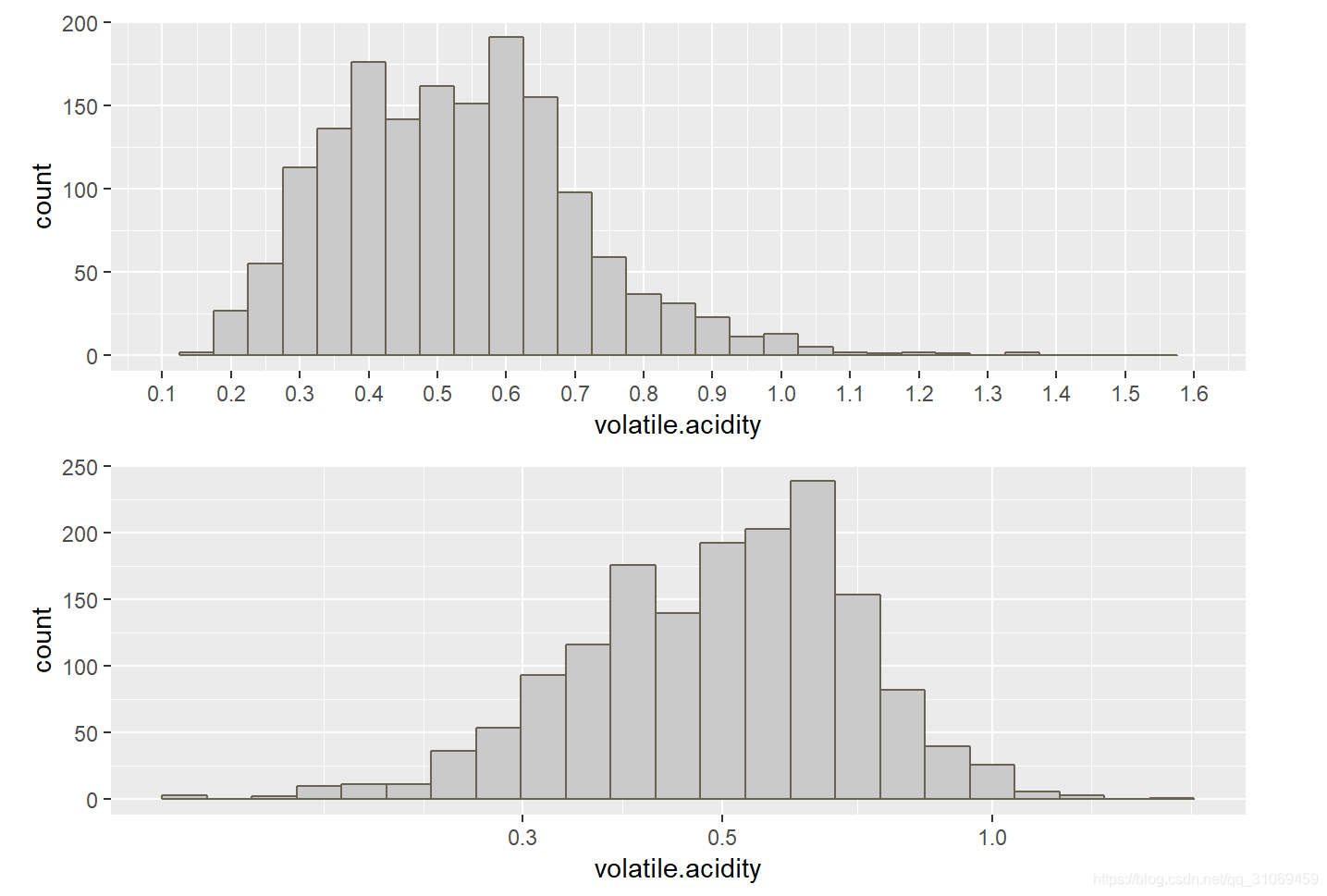
# 使用summary命令对变量volatile.acidity进行汇总统计
summary(pf$volatile.acidity)

挥发性酸数据分布偏右太,对其进行对数转换,大部分数据集中在0.3 ~ 0.7 g / dm^3 之间,75%的数据处于0.64g / dm^3 以下。
# 在变量volatile.acidity的直方图基础上添加facet_wrap层
# 通过变量quality将直方图分割为6个直方图
ggplot(aes(x = volatile.acidity),
data = pf)+
# 为每个直方图设置组距并填充颜色
geom_histogram(binwidth = 0.1,
color = "#696356",
fill = "#CACACA")+
# 为每个直方图设置limits & breaks
scale_x_continuous(limits = c(0.1,1.6),
breaks = seq(0.1,1.6,0.2))+
# 设置标度scale为“free”,各直方图坐标轴数据可以不相同
facet_wrap(~quality,
scales = "free",
ncol =2) # 按照两列来展示图形
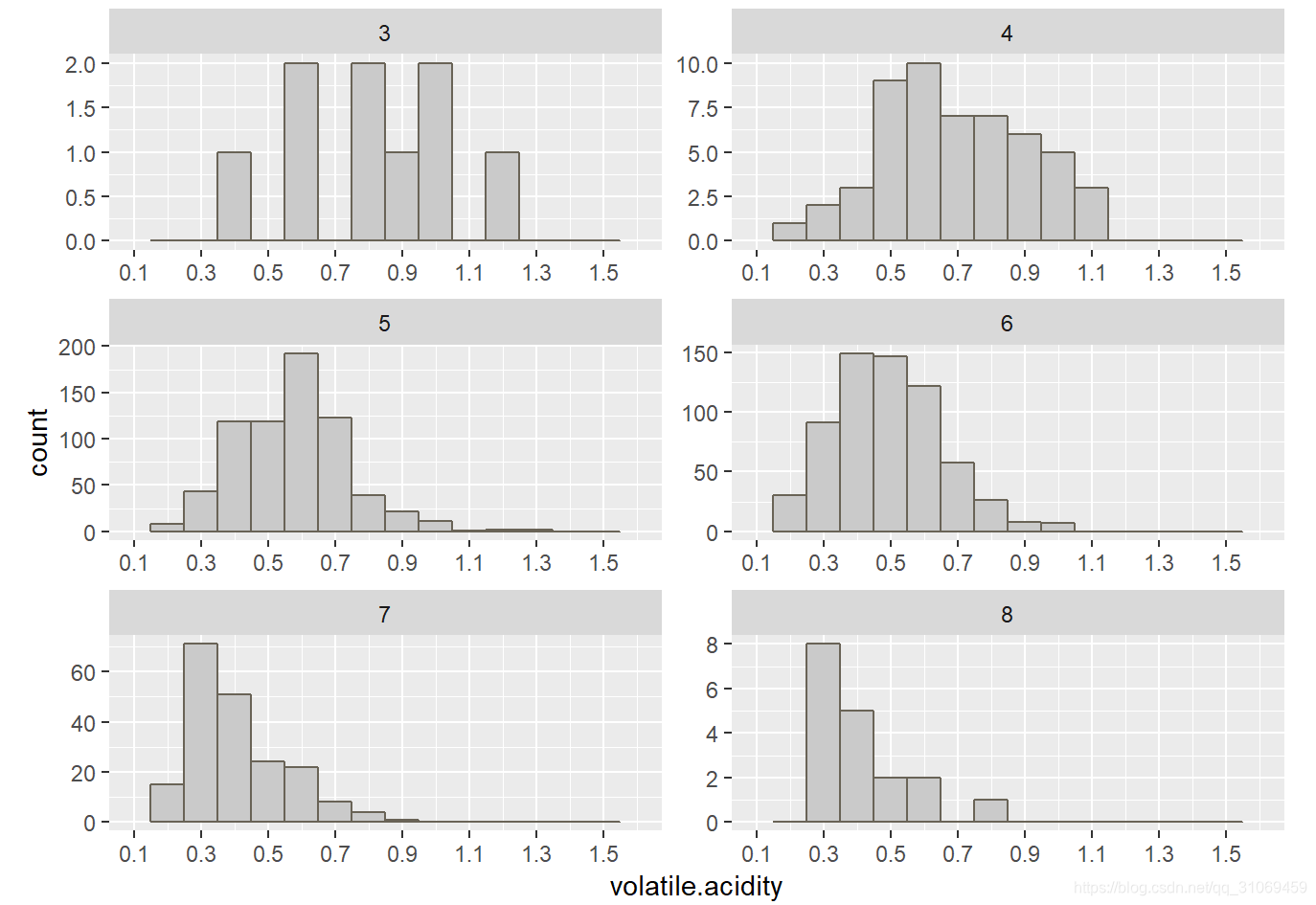
评分较低3 ~ 4分酒的挥发性酸分布从0.3 ~ 1.2 g / dm^3,其中3分酒的挥发性酸分布较分散;
评分为5 ~ 6分酒的挥发性酸,集中分布于0.4 ~ 0.7 g / dm^3.
而评分较高酒的挥发性酸分布呈右偏态,且含挥发性酸在逐渐减少。
# 通过by命令统计出不同quality的volatile.acidity汇总
by(pf$volatile.acidity,pf$quality,summary)
# 通过ggplot绘制变量quality与变量volatile.acidity的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = volatile.acidity),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)+
# 添加coord_trans图层限制y轴
coord_trans(limy =c(0.1,1.2))
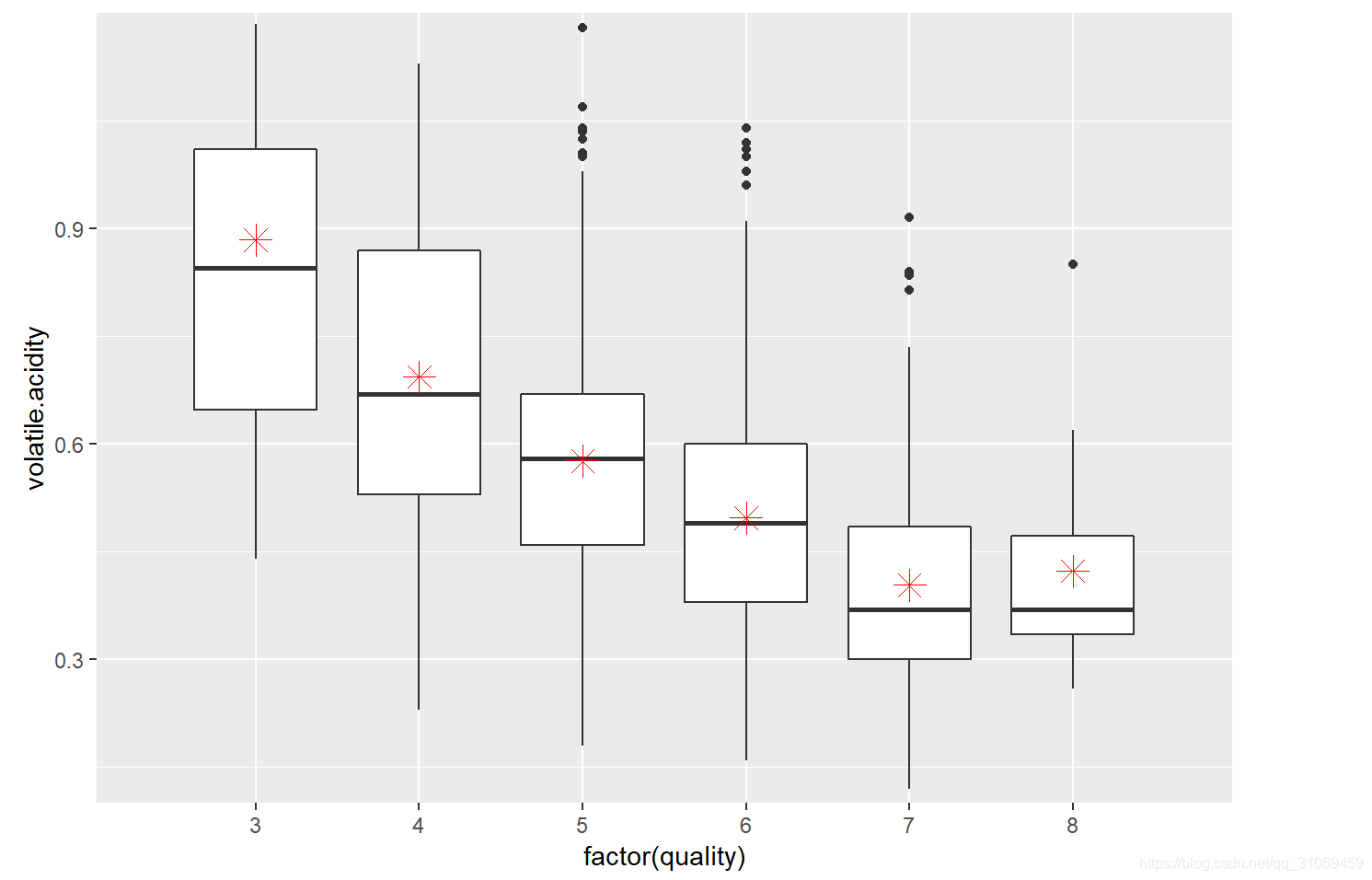
我们通过箱线图来进一步观察,限制y轴。通过以上的汇总数据及挥发酸中位数与平均数的分布情况看出,随着酒质量的提升,挥发性酸的中位数及平均数在逐渐减少。图中红色点代表基于quality分组下的挥发性酸平均值。
citric.acid探索
# 通过ggplot函数来绘制变量citric.acid的直方图
# 并将其保存到变量p1中
p1 <- ggplot(aes(x = citric.acid),
data = pf)+
# 填充颜色
geom_histogram(color = "#696356",
fill = "#CACACA")
# 调整直方图的组距后并将其保存到变量p2中
p2 <- ggplot(aes(x = citric.acid),
data = pf)+
geom_histogram(binwidth = 0.005,
color = "#696356",
fill = "#CACACA")
# 添加scale_x_log10()层,对长尾数据进行对数转换
# 并将其保存到变量p3中
p3 <- p1 + scale_x_log10()
# 将p1,p2,p3三个变量分别传递给grid.arrange()
# 并设置两图形以一列的形式展示
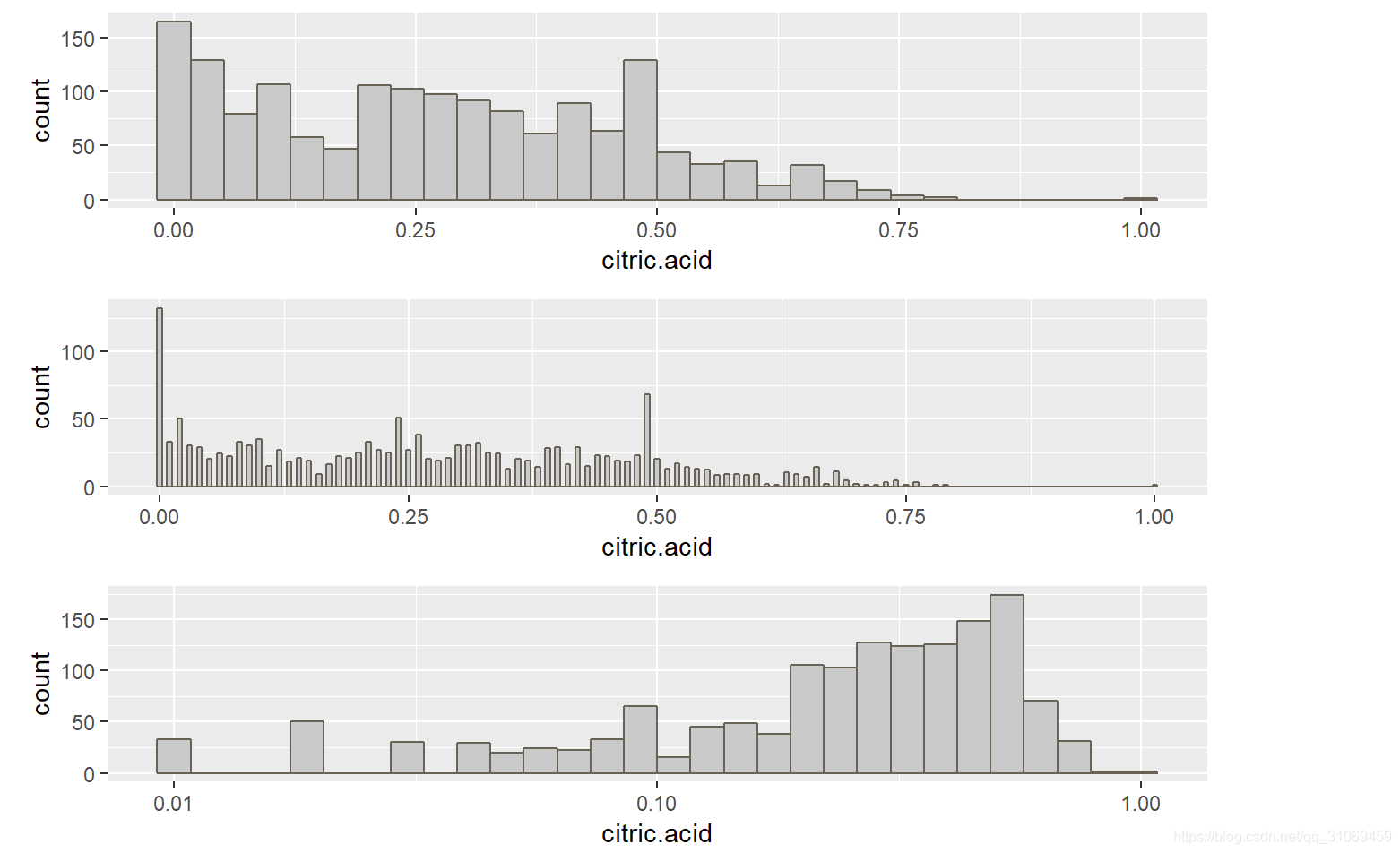
grid.arrange(p1,p2,p3,ncol = 1)
# 使用summary命令对变量citric.acid进行汇总统计
summary(pf$citric.acid)
# 使用table命令对变量citric.acid中每个值计数
table(pf$citric.acid)
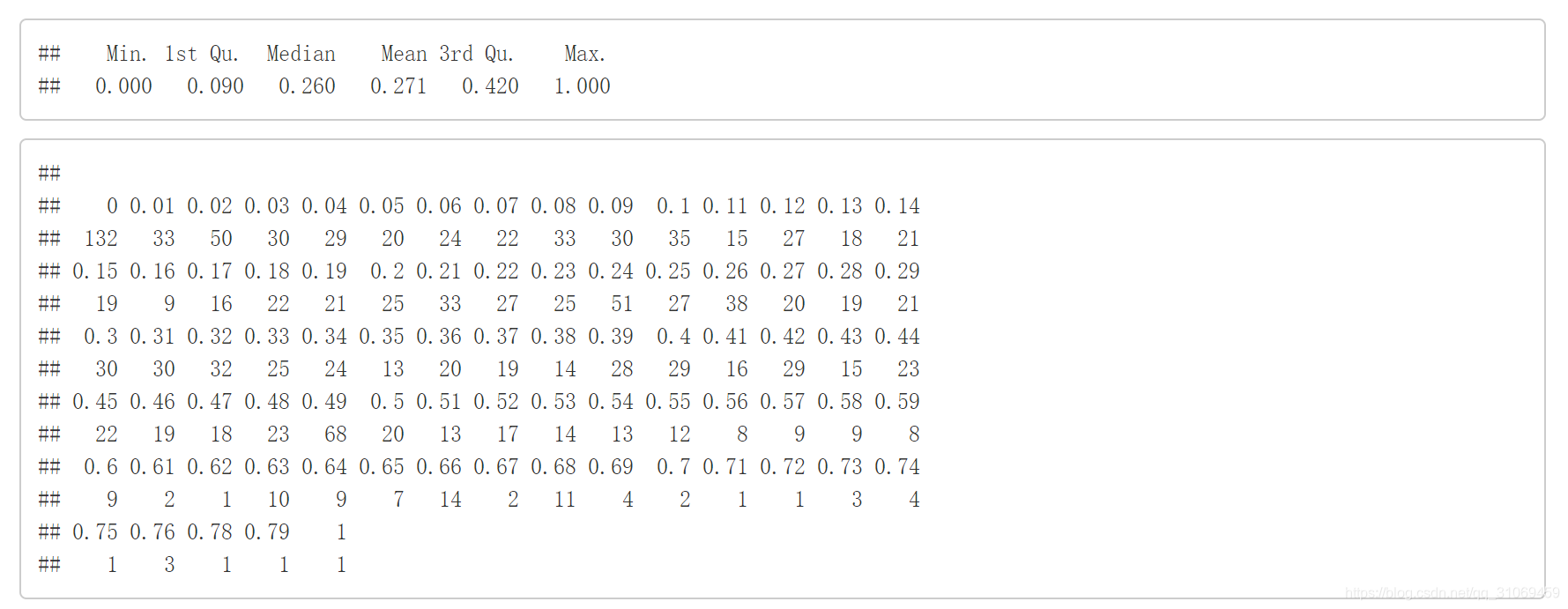
柠檬酸数据的分布为长尾数据。通过转换长尾数据,从其分布来看,仍比较分散。柠檬酸75%的数据是低于0.42g/dm^3,从柠檬酸的数据分布来看,最小值为0,且有132条记录为0,最大值为1。葡萄酒的酸有许多种,最为主要的便是酒石酸,醋酸和柠檬酸,其中酒石酸含量最高是葡萄酒酸味的主要来源,而柠檬酸则较为少量甚至没有。
# 在变量citric.acid的直方图基础上添加facet_wrap层
# 通过变量quality将直方图分割为6个直方图
ggplot(aes(x = citric.acid),
data = pf)+
# 为每个直方图设置组距并填充颜色
geom_histogram(binwidth = 0.05,
color = "#696356",
fill = "#CACACA")+
# 为每个直方图设置limits & breaks
scale_x_continuous(limits = c(0,1),
breaks = seq(0,1,0.1))+
# 设置标度scale为“free”,各直方图坐标轴数据可以不相同
facet_wrap(~quality,
scales = "free",
ncol =2) # 按照两列来展示图形
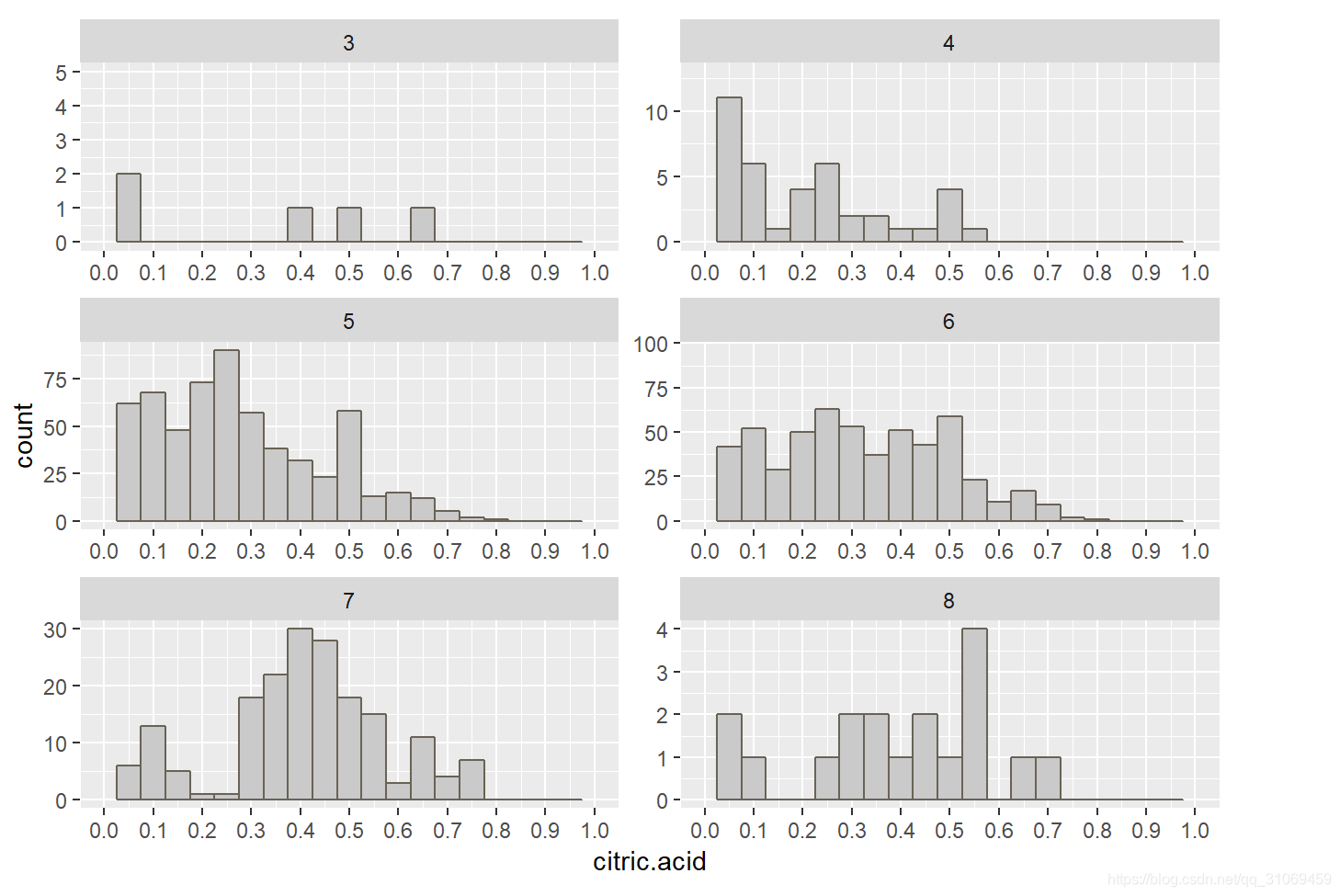
从上边的直方图分布来看,评分为3分酒的柠檬酸分布与0 ~ 0.6 g / dm^3 范围,且分布较分散。
评分4 ~ 6酒的柠檬酸分布与0 ~ 0.5 g / dm^3 之间。评分7 ~8 分酒的柠檬酸集中分布于0.3 ~ 0.6 g / dm^3.
# 通过by命令统计出不同quality的citric.acid汇总
by(pf$citric.acid,pf$quality,summary)
# 通过ggplot绘制变量quality与变量citric.acid的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = citric.acid),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)+
# 添加coord_trans图层限制y轴
coord_trans(limy =c(0,0.8))
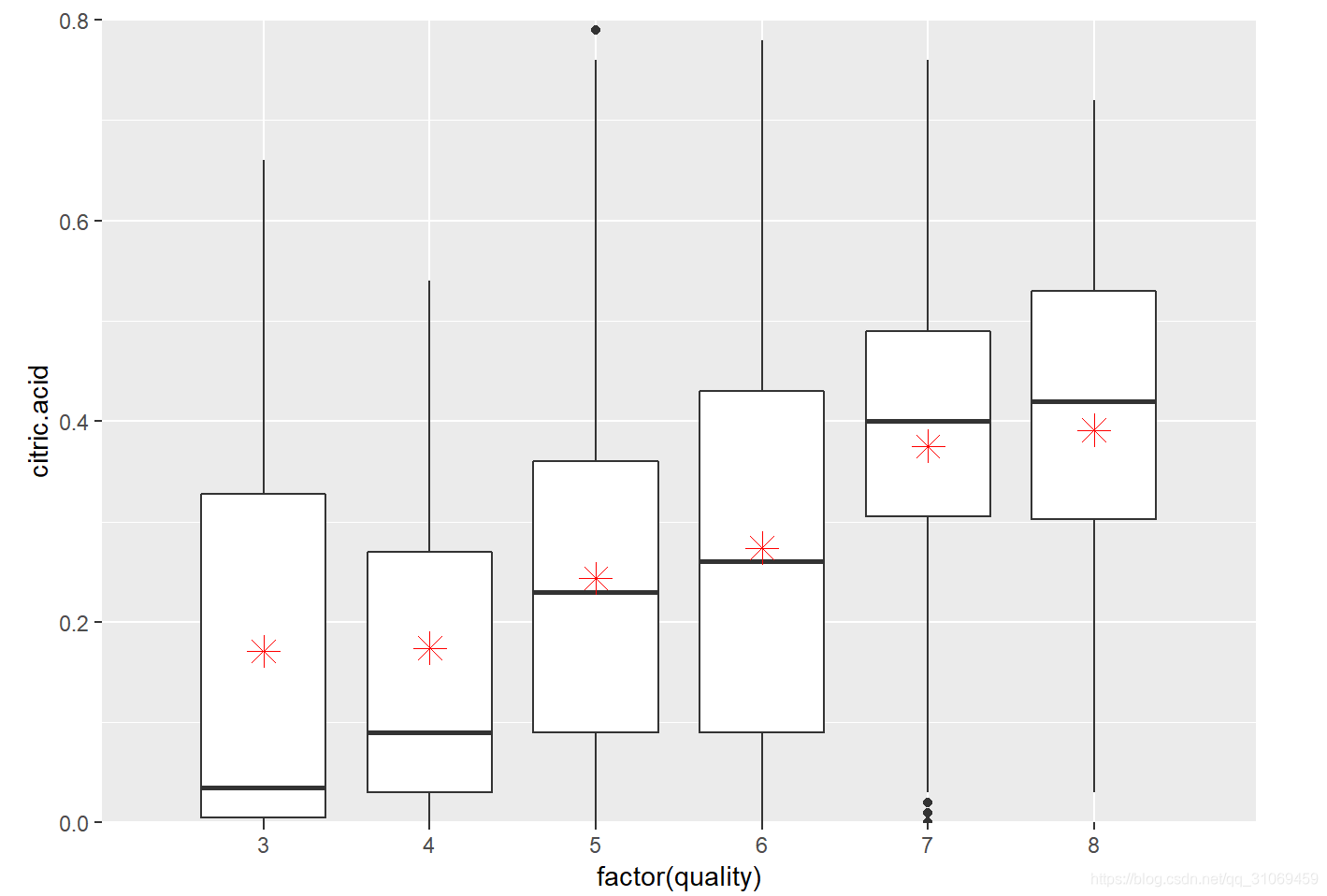
从统计汇总及箱线图的分布来看,随着酒质量的提升,柠檬酸的中位数及平均数逐渐增加。图中红色点代表基于quality分组下的柠檬酸平均值。
residual.sugar探索
# 通过ggplot函数来绘制变量residual.sugar的直方图
# 并将其保存到变量p1中
p1 <- ggplot(aes(x = residual.sugar),
data = pf)+
# 调整组距,填充颜色
geom_histogram(color = "#696356",
fill = "#CACACA")+
# 添加scale_x_continuous层,并设置limits&breaks
scale_x_continuous(limits = c(0.5,16),
breaks = seq(0.5,16,2))
# 添加scale_x_log10()层,对长尾数据进行对数转换
# 并保存到变量p2中
p2 <- p1 +
scale_x_log10()
# 将p1,p2两个变量分别传递给grid.arrange()
# 并设置两图形以一列的形式展示
grid.arrange(p1,p2,ncol = 1)
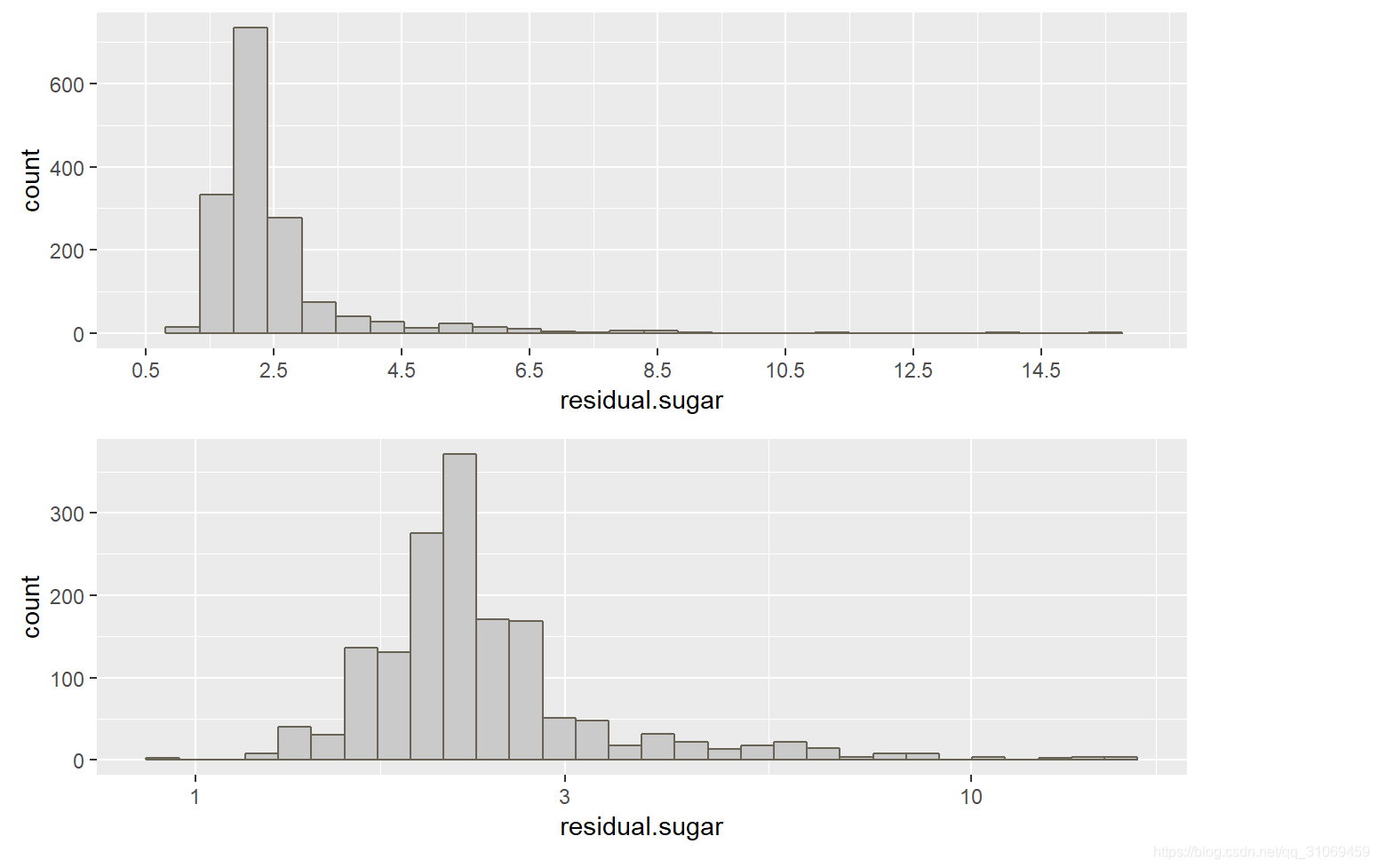
# 使用summary命令对变量residual.sugar进行汇总统计
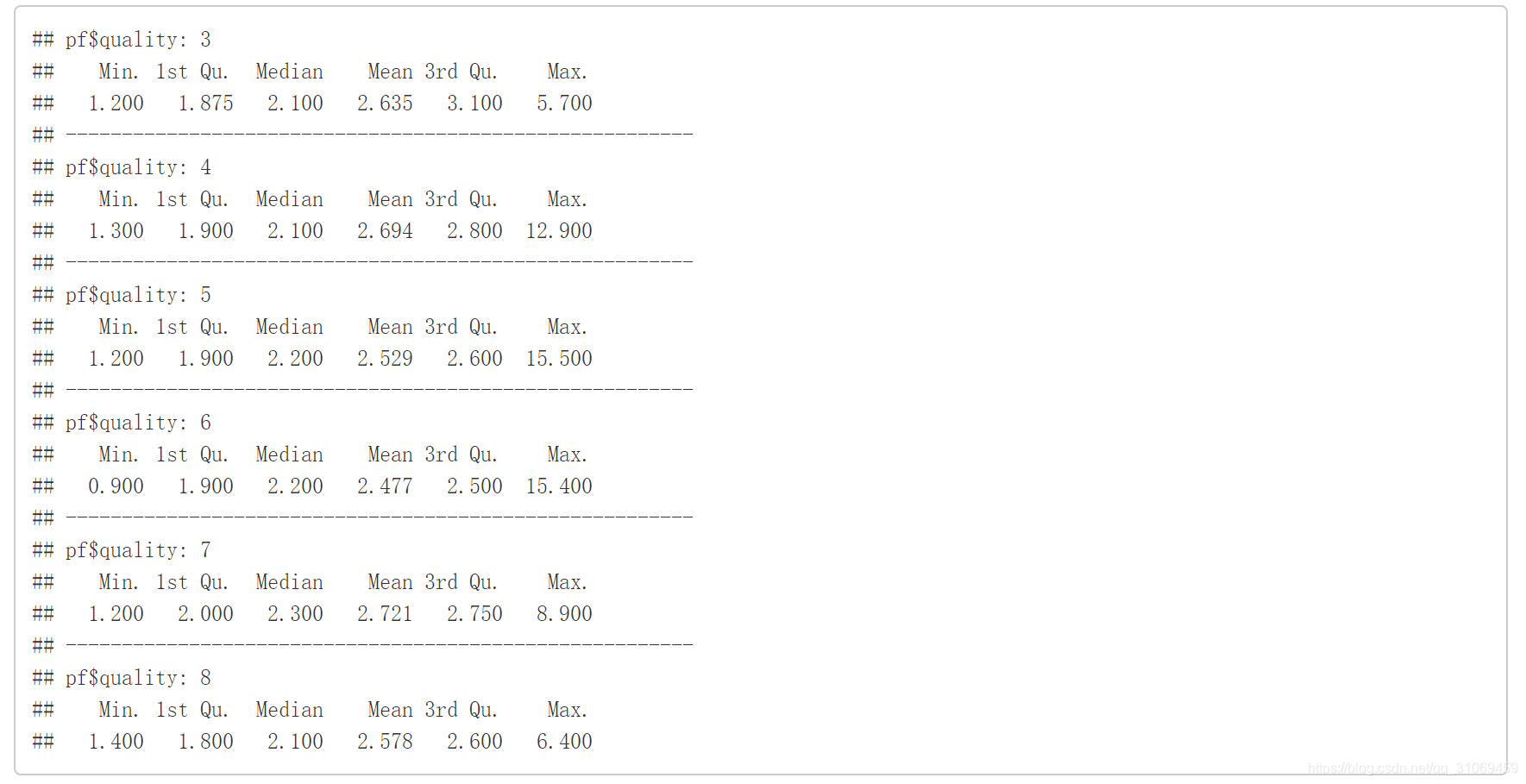
summary(pf$residual.sugar)

剩余糖分分布图为长尾数据,对其进行对数转换,75%以下数据处于2.6 g / dm^3 以下
# 在变量residual.sugar的直方图基础上添加facet_wrap层
# 通过变量quality将直方图分割为6个直方图
ggplot(aes(x = residual.sugar),
data = pf)+
# 为每个直方图设置组距并填充颜色
geom_histogram(binwidth =0.5,
color = "#696356",
fill = "#CACACA")+
# 为每个直方图设置limits & breaks
scale_x_continuous(limits = c(0,16),
breaks = seq(0,16,1))+
# 设置标度scale为“free”,各直方图坐标轴数据可以不相同
facet_wrap(~quality,
scales = "free",
ncol =2) # 按照两列来展示图形
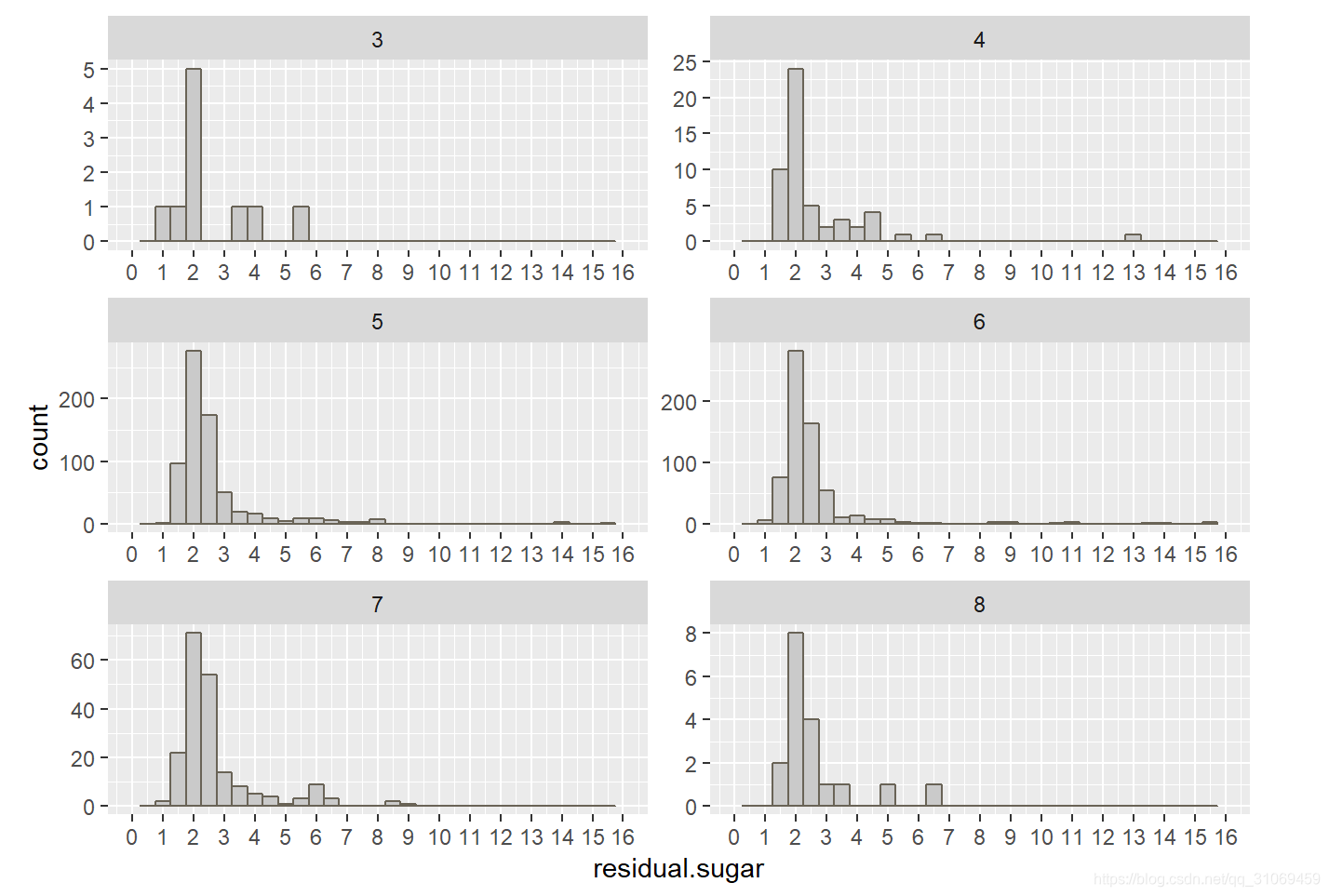
从上图可看出,评分高与评分低的酒剩余糖分分布都较分散,但是所有不同质量的酒含有的剩余糖分都比较固定,大部分分布与1 ~ 4 g / dm^3 之间。
# 通过by命令统计出不同quality的residual.sugar汇总
by(pf$residual.sugar,pf$quality,summary)
# 通过ggplot绘制变量quality与变量residual.sugar的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = residual.sugar),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)+
# 添加coord_trans图层限制y轴
coord_trans(limy =c(1,4.5))
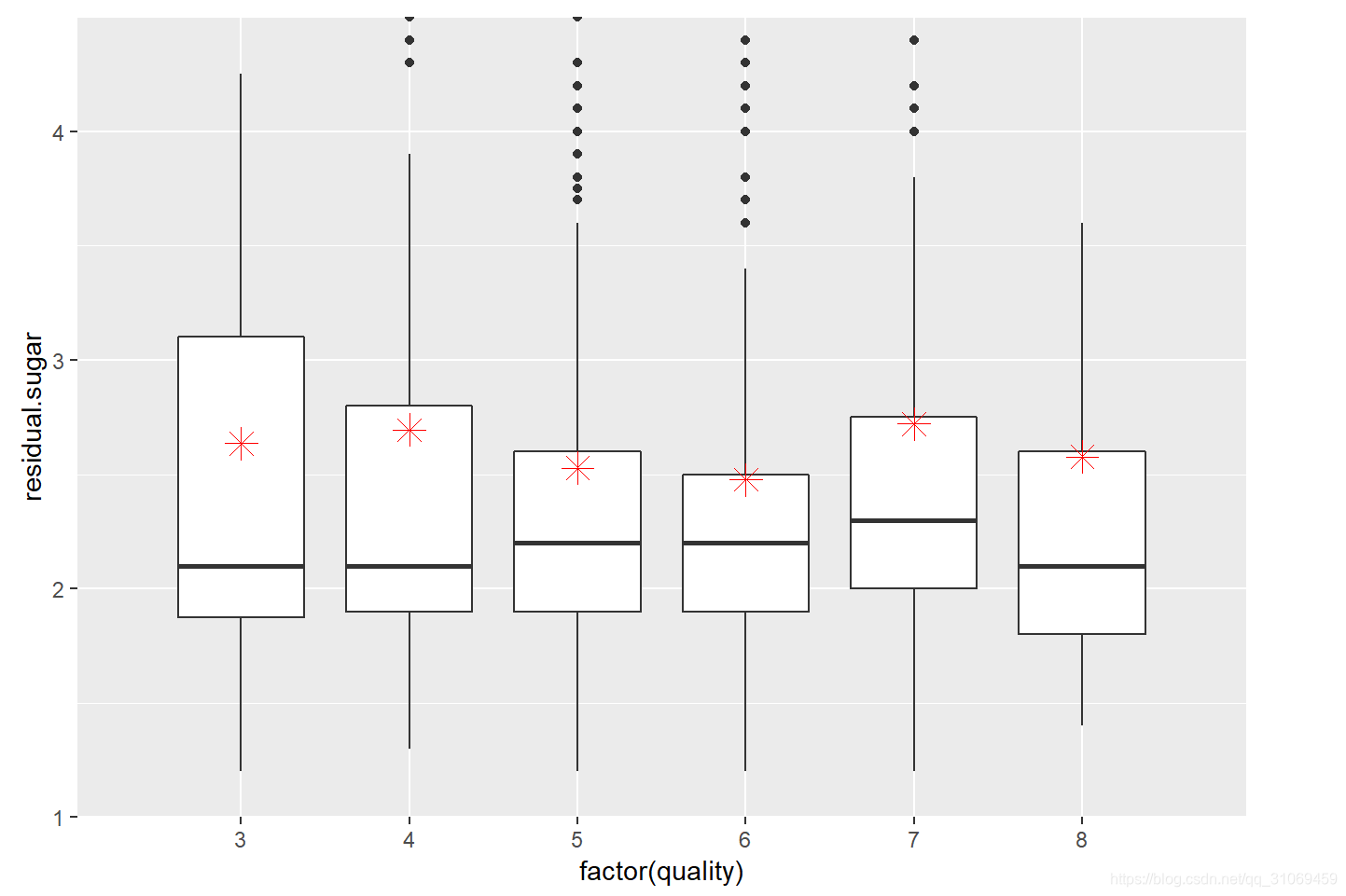
通过箱线线图进一步探索,从统计数据及分布来看,不同质量的酒中含有的剩余糖分趋于稳定,波动很小,图中红色点代表基于quality分组下的剩余糖分平均值。
chlorides探索
# 通过ggplot函数来绘制变量chlorides的直方图
# 并将其保存到变量p1中
p1 <- ggplot(aes(x = chlorides),
data = pf)+
# 填充颜色
geom_histogram(color = "#696356",
fill = "#CACACA")+
# 添加scale_x_continuous层
# 并设置limits & breaks
scale_x_continuous(limits = c(0,0.62),
breaks = seq(0,0.62,0.1))
# 限制x轴数据,
# 并保存到变量p2中
p2 <- p1 + xlim(0,0.15)
# 将p1,p2两个变量分别传递给grid.arrange()
# 并设置两图形以一列的形式展示
grid.arrange(p1,p2,ncol = 1)
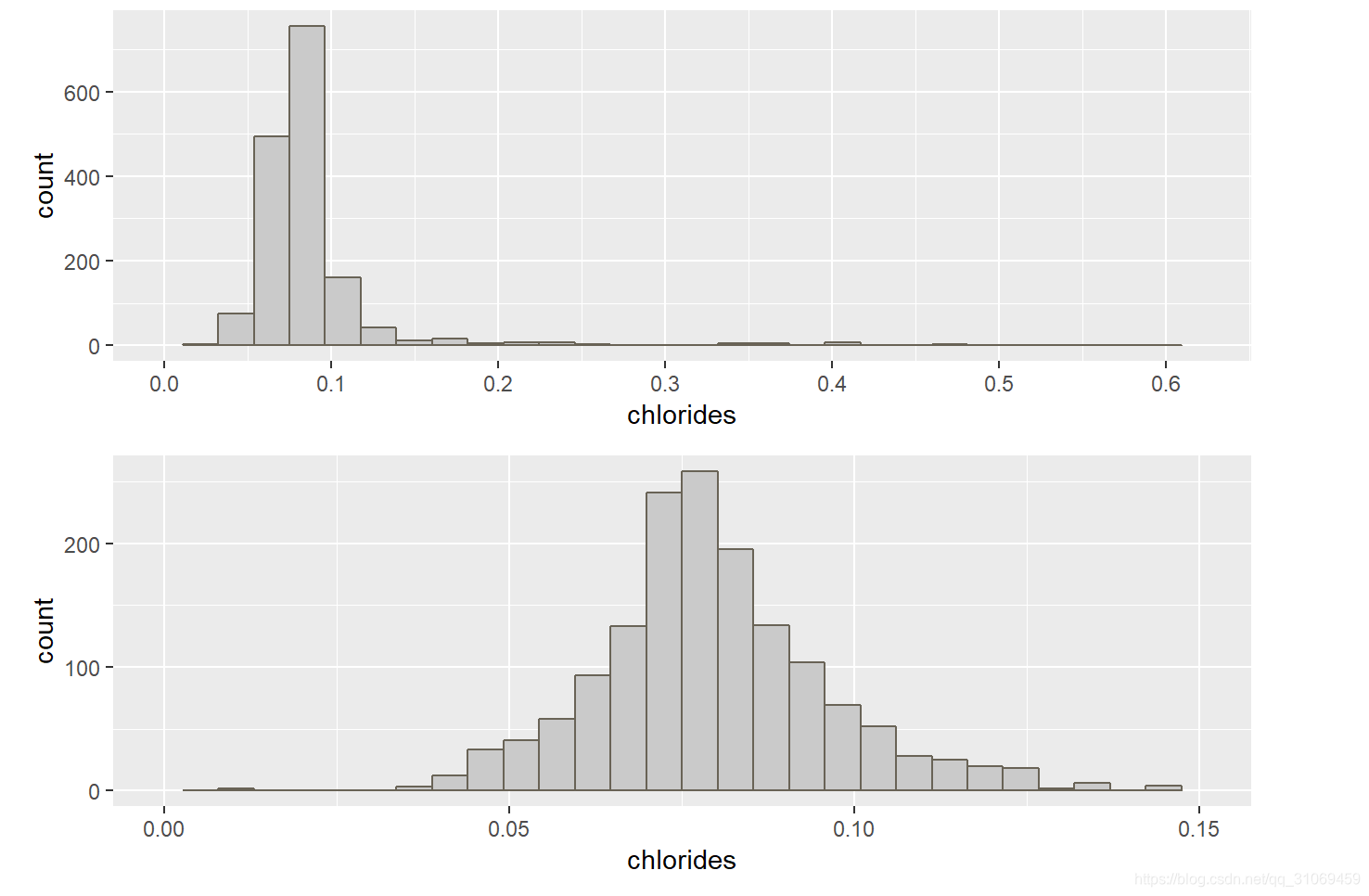
# 使用summary命令对变量chlorides进行汇总统计
summary(pf$chlorides)

从氯化物直方图看,是长尾数据,去掉异常值,放大其分布,近似正太分布,数据集中分布与0.05 ~ 0.10 g / dm^3. 75%的数据处于0.09 g / dm^3 以下。
# 在变量chlorides的直方图基础上添加facet_wrap层
# 通过变量quality将直方图分割为6个直方图
ggplot(aes(x = chlorides),
data = pf)+
# 为每个直方图设置组距并填充颜色
geom_histogram(binwidth = 0.01,
color = "#696356",
fill = "#CACACA")+
# 为每个直方图设置limits & breaks
scale_x_continuous(limits = c(0,0.62),
breaks = seq(0,0.62,0.1))+
# 设置标度scale为“free”,各直方图坐标轴数据可以不相同
facet_wrap(~quality,
scales = "free",
ncol = 2) # 按照两列来展示图形
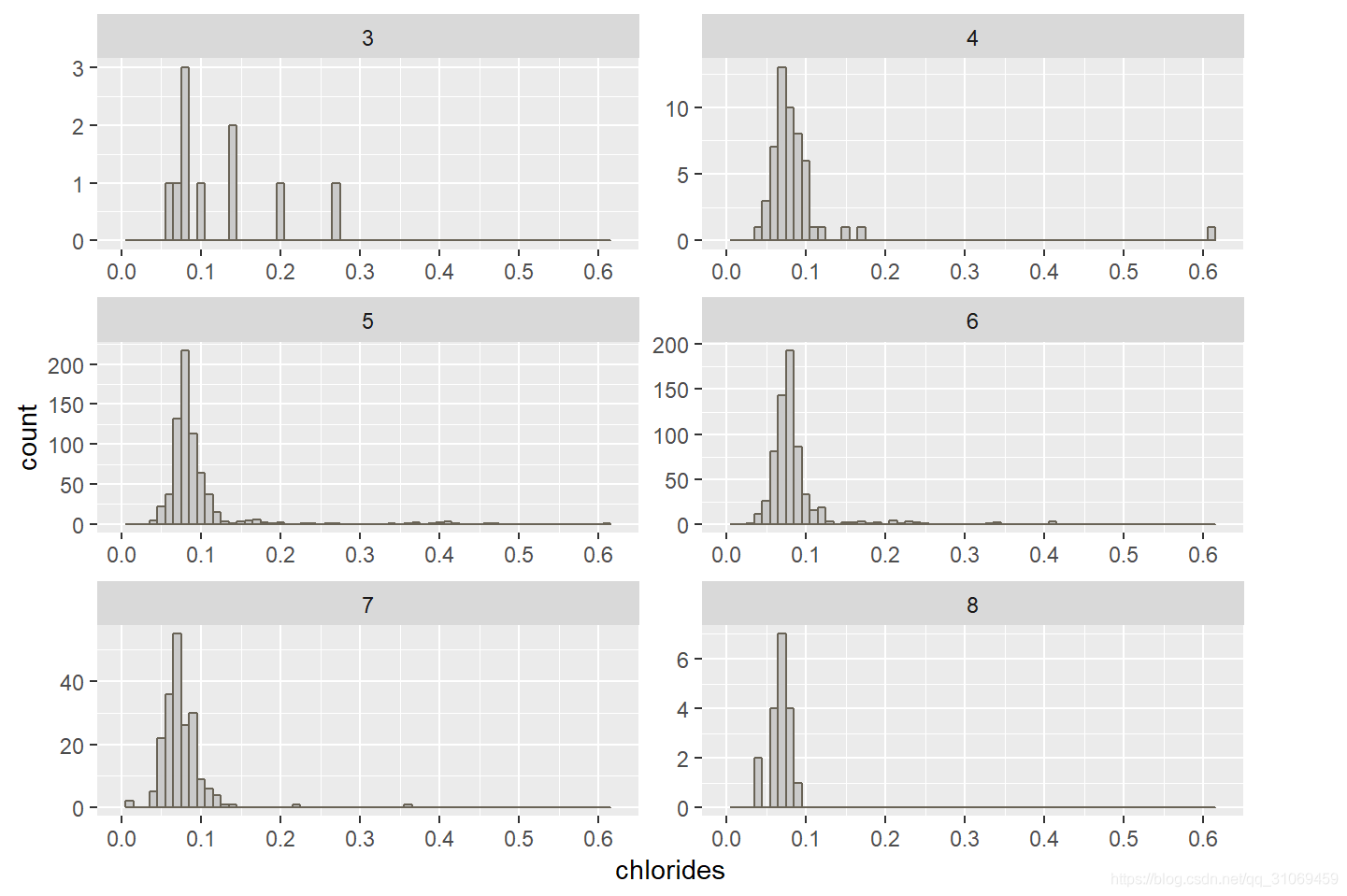
从上方直方图可以看出,不论是质量偏低的酒还是偏高的酒,其氯化物大部分分布在0.05 ~ 0.1 g/ dm^3 之间。
# 通过by命令统计出不同quality的chlorides汇总
by(pf$chlorides,pf$quality,summary)

# 通过ggplot绘制变量quality与变量chlorides的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = chlorides),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)+
# 添加coord_trans图层限制y轴
coord_trans(limy = c(0.025,0.21))
从汇总统计及箱线图分布来看,氯化物中位数随着酒质量的提升也逐步提升,但是提升幅度很小。而平均数相对来说有点波动,尤其是质量评分为3的酒,这是由于异常值导致的。图中红色点代表基于quality分组下的氯化物平均值。
free.sulfur.dioxide&total.sulfur.dioxide探索
# 绘制变量free.sulfur.dioxide的直方图
# 并将其保存到变量p1中
p1 <- ggplot(aes(x = free.sulfur.dioxide),
data = pf)+
# 填充颜色
geom_histogram(color = "#696356",
fill = "#CACACA")
# 添加scale_x_log10()层,对长尾数据进行对数转换
# 并保存到变量p2中
p2 <- p1+scale_x_log10()
# 绘制变量total.sulfur.dioxide的直方图
# 并将其保存到变量p3中
p3 <- ggplot(aes(x = total.sulfur.dioxide),
data = pf)+
# 填充颜色
geom_histogram(color = "#696356",
fill = "#CACACA")
# 添加scale_x_log10()层,对长尾数据进行对数转换
# 并保存到变量p4中
p4 <- p3+scale_x_log10()
# 将p1,p2,p3,p4四个变量分别传递给grid.arrange()
# 并设置两图形以两列的形式展示
grid.arrange(p1,p2,p3,p4,ncol=2)
# 使用summary命令分别对对变量free.sulfur.dioxide,total.sulfur.dioxide进行汇总统计
summary(pf$free.sulfur.dioxide)
summary(pf$total.sulfur.dioxide)

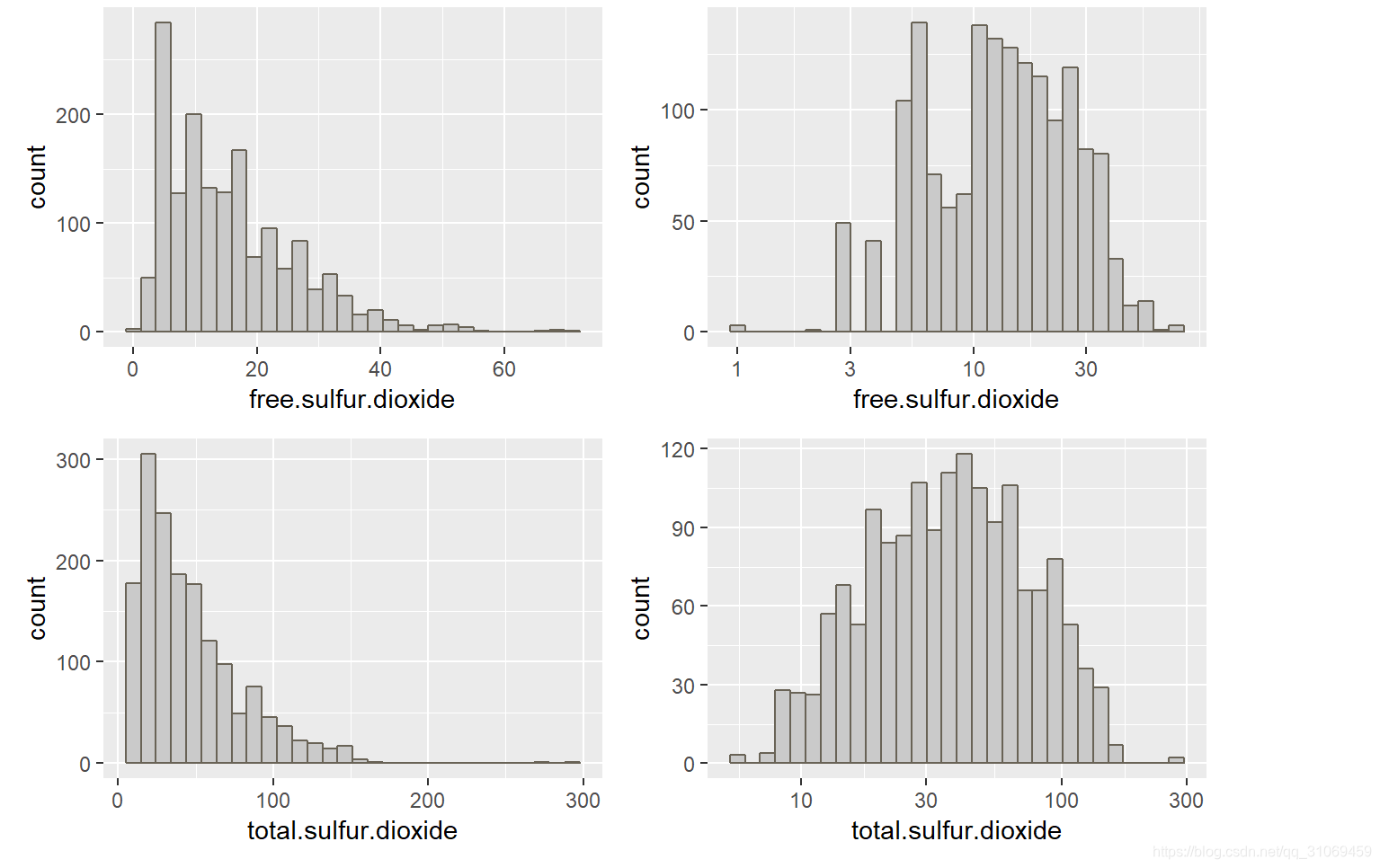
游离二氧化硫与总的二氧化硫分布相似,呈右偏态,对其进行对数转换。游离二氧化硫75%的数据在21 mg / dm^3 以下,总二氧化硫75%的数据在62 mg / dm^3 以下。
# 在变量free.sulfur.dioxide的直方图基础上添加facet_wrap层
# 通过变量quality将直方图分割为6个直方图
ggplot(aes(x = free.sulfur.dioxide),
data = pf)+
# 为每个直方图设置组距并填充颜色
geom_histogram(binwidth = 2,
color = "#696356",
fill = "#CACACA")+
# 为每个直方图设置limits & breaks
scale_x_continuous(limits = c(1,72),
breaks = seq(1,72,5))+
# 设置标度scale为“free”,各直方图坐标轴数据可以不相同
facet_wrap(~quality,
scales = "free",
ncol = 2) # 按照两列来展示图形
# 在变量total.sulfur.dioxide的直方图基础上添加facet_wrap层
# 通过变量quality将直方图分割为6个直方图
ggplot(aes(x = total.sulfur.dioxide),
data = pf)+
# 为每个直方图设置组距并填充颜色
geom_histogram(binwidth = 10,
color = "#696356",
fill = "#CACACA")+
# 为每个直方图设置limits & breaks
scale_x_continuous(limits = c(6,289),
breaks = seq(6,289,30))+
# 设置标度scale为“free”,各直方图坐标轴数据可以不相同
facet_wrap(~quality,
scales = "free",
ncol = 2) # 按照两列来展示图形
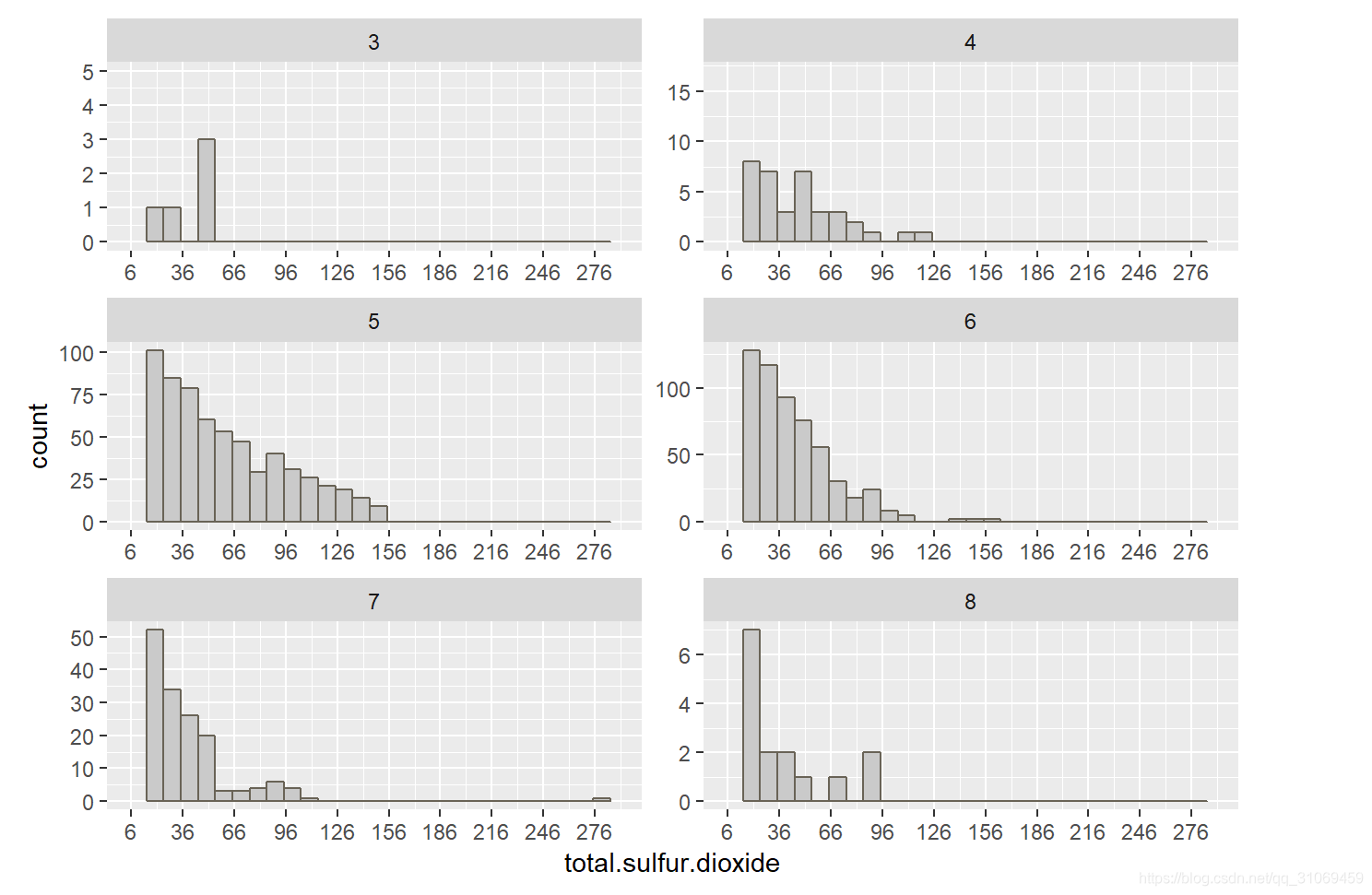
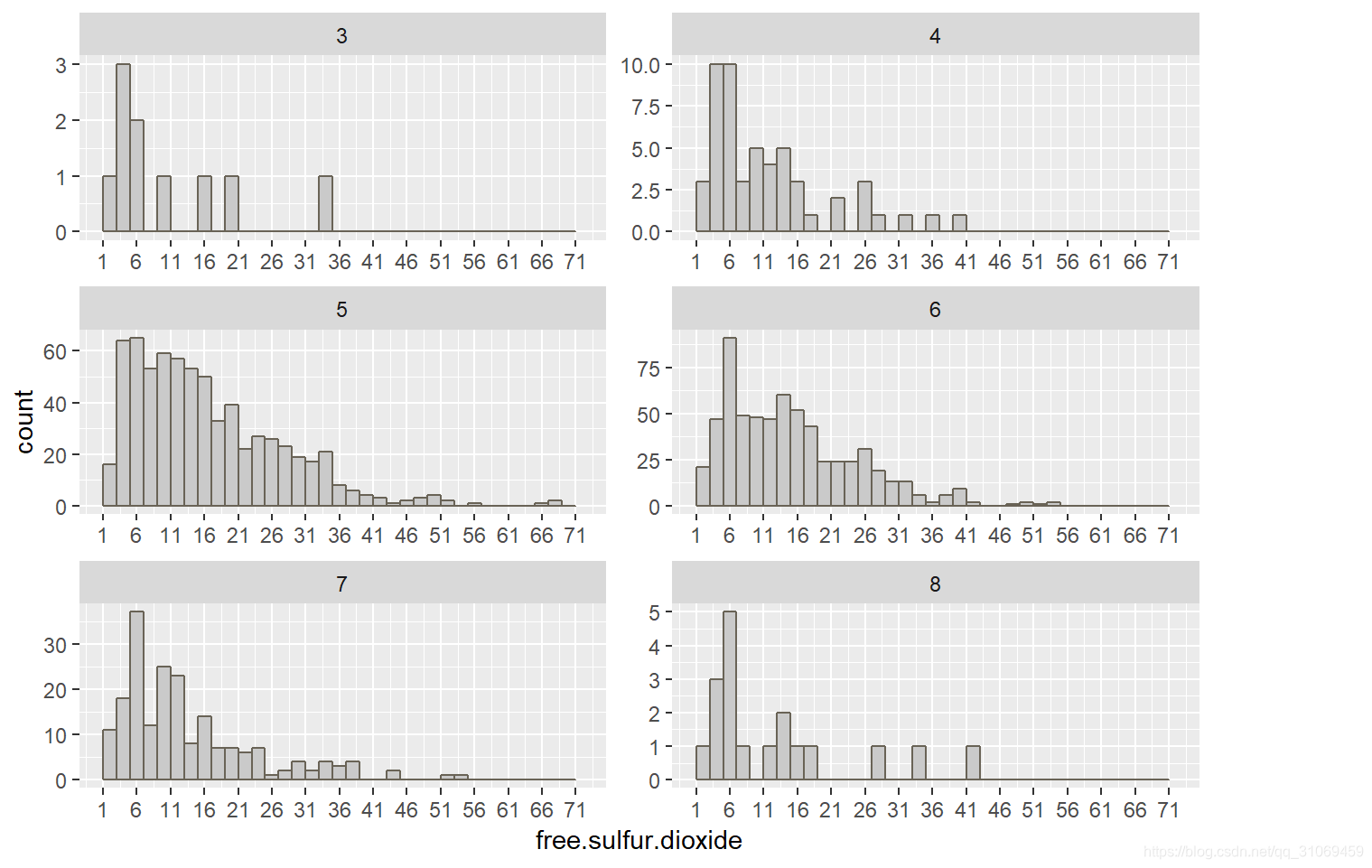
游离二氧化硫的6个直方图分布中,大部分酒的游离二氧化硫分布在1 ~ 36 mg / dm^3,其中评分为3分及8分的分布较分散。
从总二氧化硫的分布中看到,除了评分较低的3分酒总二氧化硫分布较散且低于66 mg / dm^3 外,其余酒的总二氧化硫含量大部分处于6 ~ 96 mg / dm^3 范围。
# 通过by命令统计出不同quality的free.sulfur.dioxide和total.sulfur.dioxide汇总
by(pf$free.sulfur.dioxide,pf$quality,summary)
by(pf$total.sulfur.dioxide,pf$quality,summary)
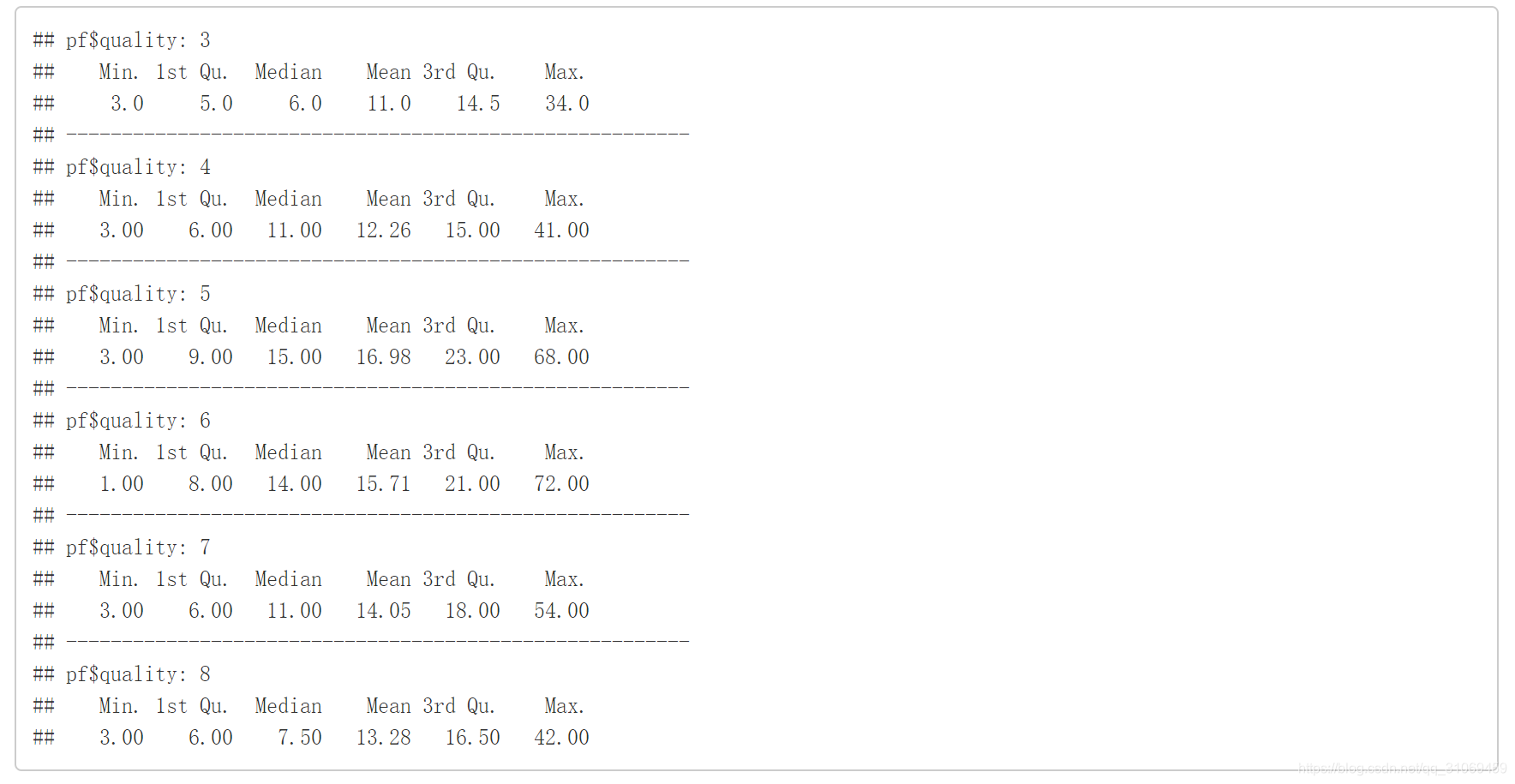
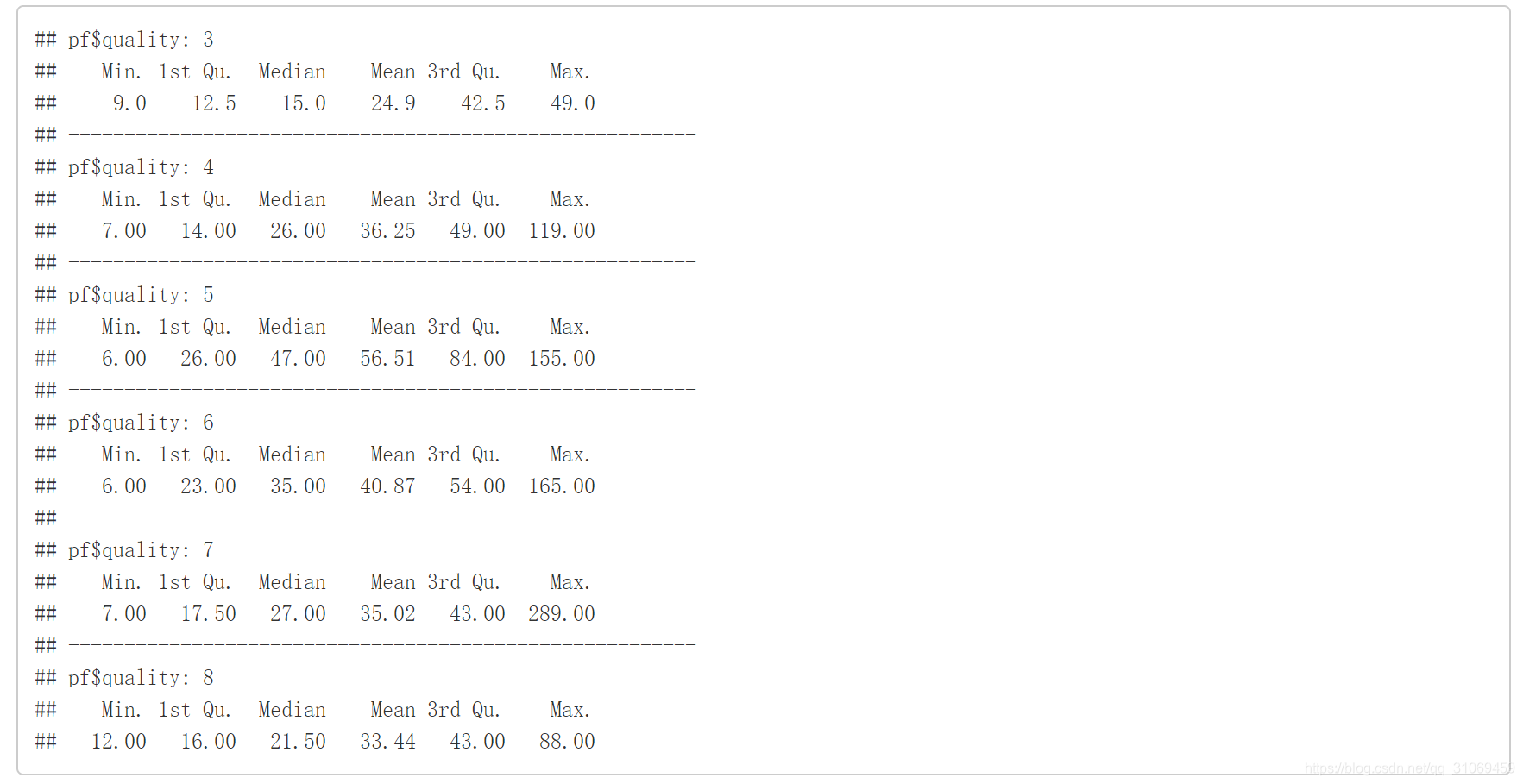
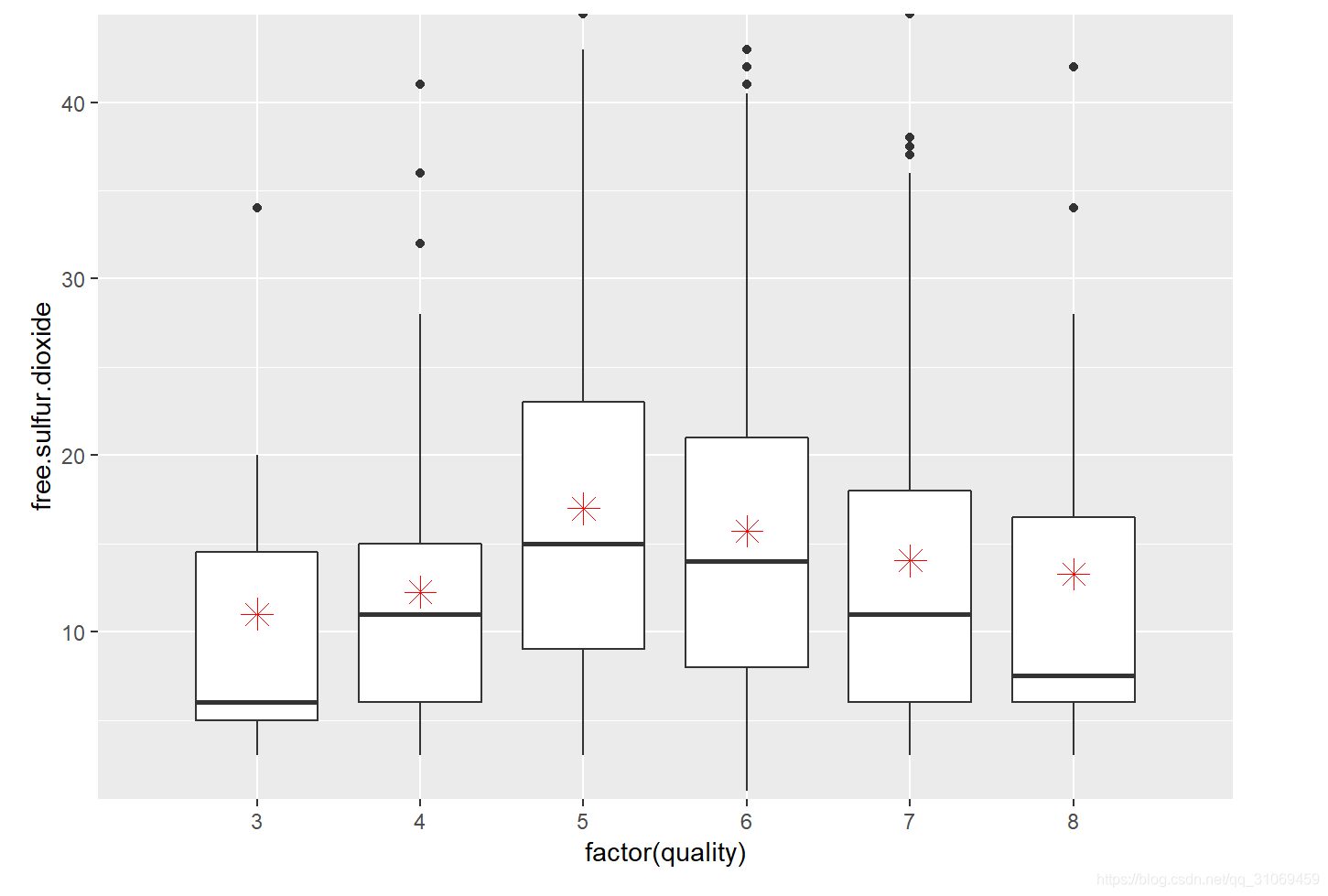
# 通过ggplot绘制变量quality与变量free.sulfur.dioxide的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = free.sulfur.dioxide),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)+
# 添加coord_trans图层限制y轴
coord_trans(limy = c(0.5,45))
# 通过ggplot绘制变量quality与变量total.sulfur.dioxide的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = total.sulfur.dioxide),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)+
# 添加coord_trans图层限制y轴
coord_trans(limy = c(6,175))
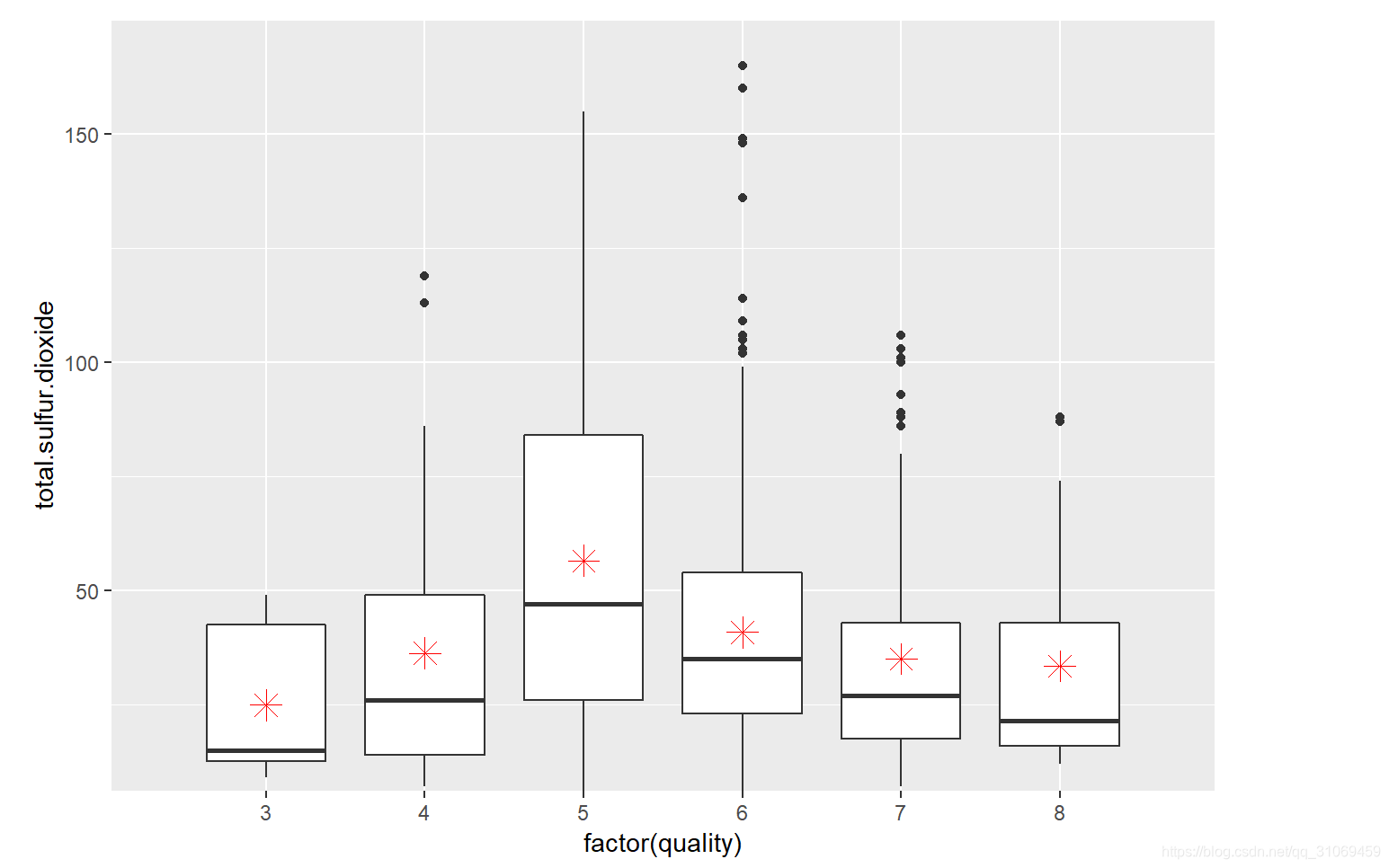
从统计汇总及箱线图来观察,其中位数忽高忽低,无法判断与酒质量的关联性。箱线图中红色点分别代表基于quality分组下的游离二氧化硫与总二氧化硫的平均值。
density探索
# 绘制变量density的直方图
# 并将其保存到变量p1中
p1 <- ggplot(aes(x = density),
data = pf)+
# 填充颜色
geom_histogram(color = "#696356",
fill = "#CACACA")
# 绘制变量pH的直方图
# 并将其保存到变量p2中
p2 <- ggplot(aes(x = pH),
data = pf)+
# 填充颜色
geom_histogram(color = "#696356",
fill = "#CACACA")
# 将p1,p2两个变量分别传递给grid.arrange()
# 并设置两图形以一列的形式展示
grid.arrange(p1,p2,ncol = 1)
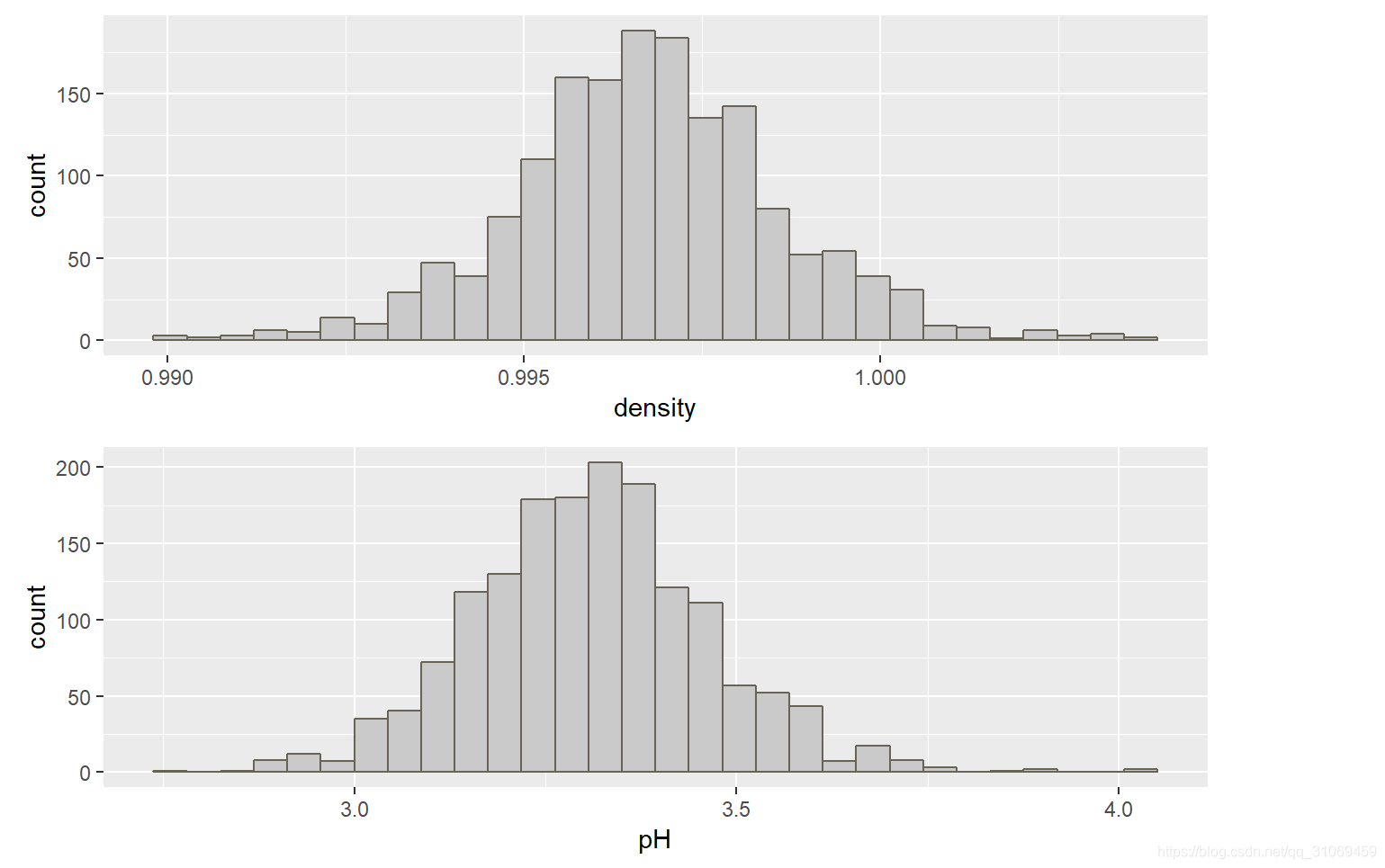
# 使用summary命令分别对对变量density,pH进行汇总统计
summary(pf$density)
summary(pf$pH)

密度与pH值的分布呈正太分布,大部分酒的密度处于0.995 ~ 1 g / cm^3 之间。大部分酒的ph值处于3 ~ 3.5之间。
# 在变量density的直方图基础上添加facet_wrap层
# 通过变量quality将直方图分割为6个直方图
ggplot(aes(x = density),
data = pf)+
# 为每个直方图设置组距并填充颜色
geom_histogram(binwidth = 0.001,
color = "#696356",
fill = "#CACACA")+
# 为每个直方图设置limits & breaks
scale_x_continuous(limits = c(0.990,1.01),
breaks = seq(0.990,1.01,0.004))+
# 设置标度scale为“free”,各直方图坐标轴数据可以不相同
facet_wrap(~quality,
scales = "free",
ncol = 2) # 按照两列来展示图形
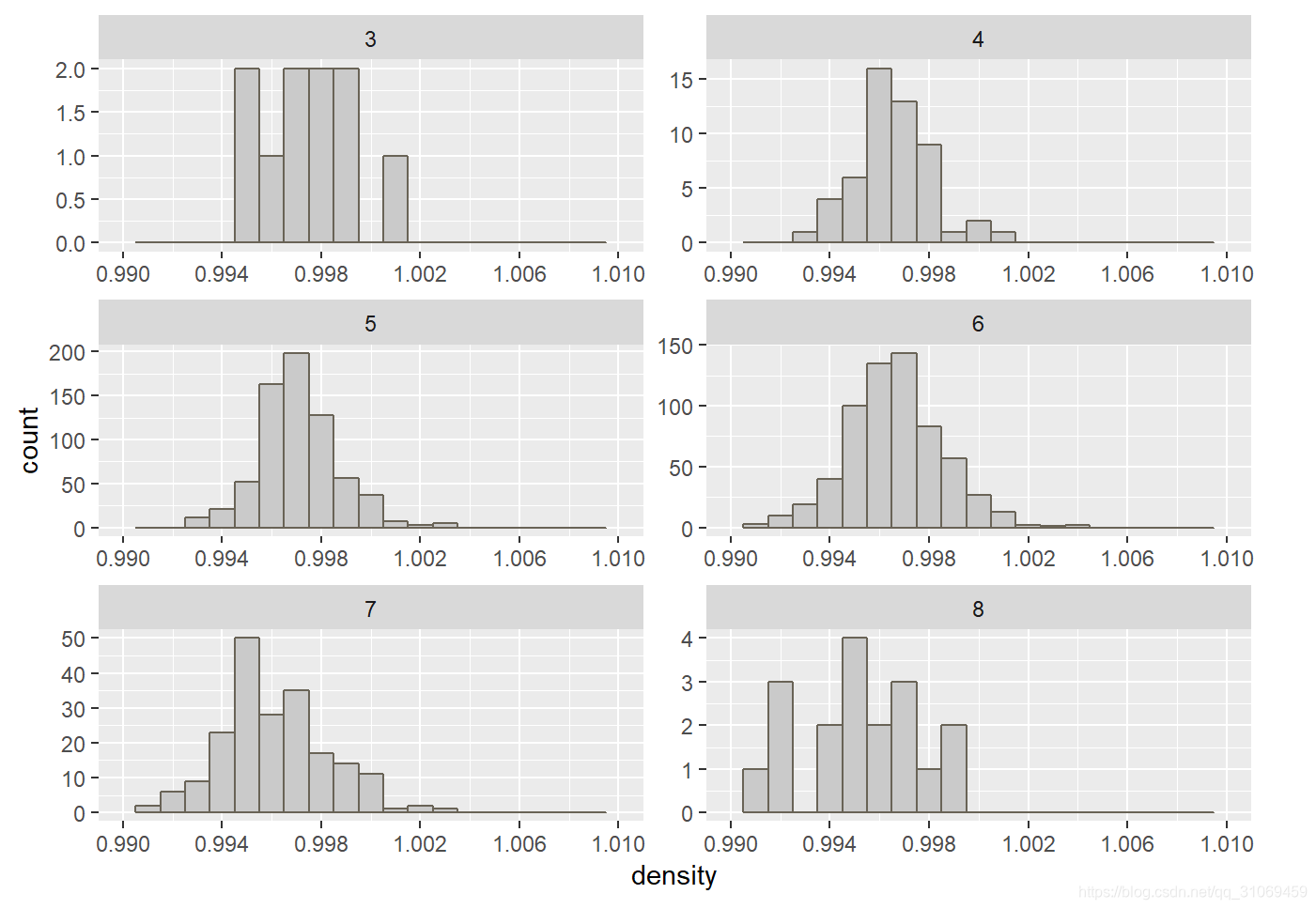
质量评分为4 ~ 7分的酒,其密度分布近似正太.
数据集中在0.994 ~ 0.998 g / cm^3 之间,评分为3和8的酒有点分散,但是分布还是蛮均匀的.
3分的酒密度处于0.994 ~ 1.002 g / cm^3 之间,8分的酒密度处于0.992 ~ 1 g / cm^3 之间。
# 在变pH的直方图基础上添加facet_wrap层
# 通过变量quality将直方图分割为6个直方图
ggplot(aes(x = pH),data = pf)+
# 为每个直方图设置组距并填充颜色
geom_histogram(binwidth = 0.1,
color = "#696356",
fill = "#CACACA")+
# 为每个直方图设置limits & breaks
scale_x_continuous(limits = c(2.7,4.1),
breaks = seq(2.7,4.1,0.5))+
# 设置标度scale为“free”,各直方图坐标轴数据可以不相同
facet_wrap(~quality,
scales = "free",
ncol = 2) # 按照两列来展示图形
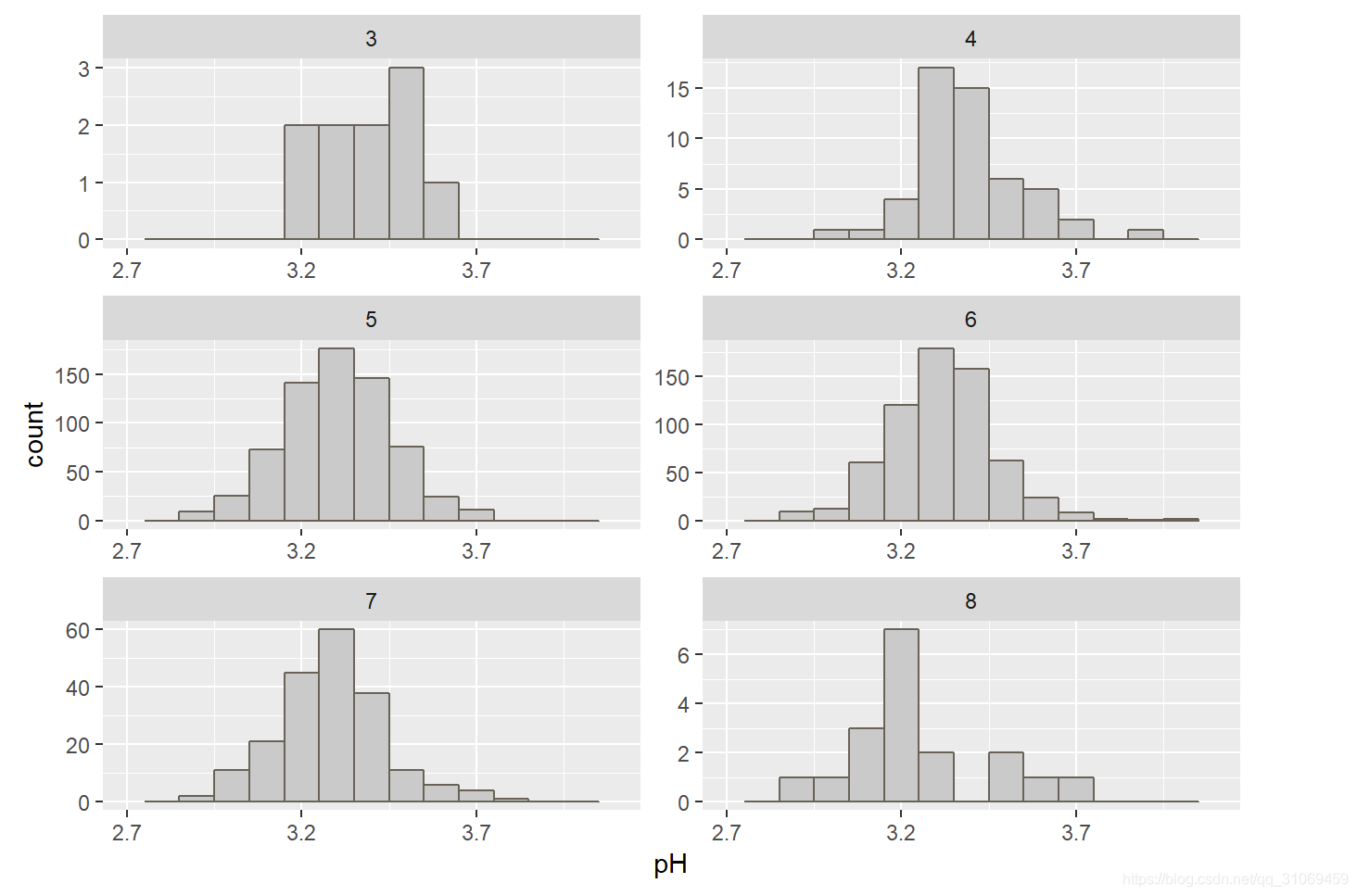
评分4 ~ 6的酒其ph值分布近似正太,3 ~ 4分的酒其ph值主要分布在3.2 ~ 3.7之间,5 ~ 8分的酒其ph值主要分布在3.1 ~ 3.5之间。
# 通过by命令统计出不同quality的density和pH汇总
by(pf$density,pf$quality,summary)
by(pf$pH,pf$quality,summary)

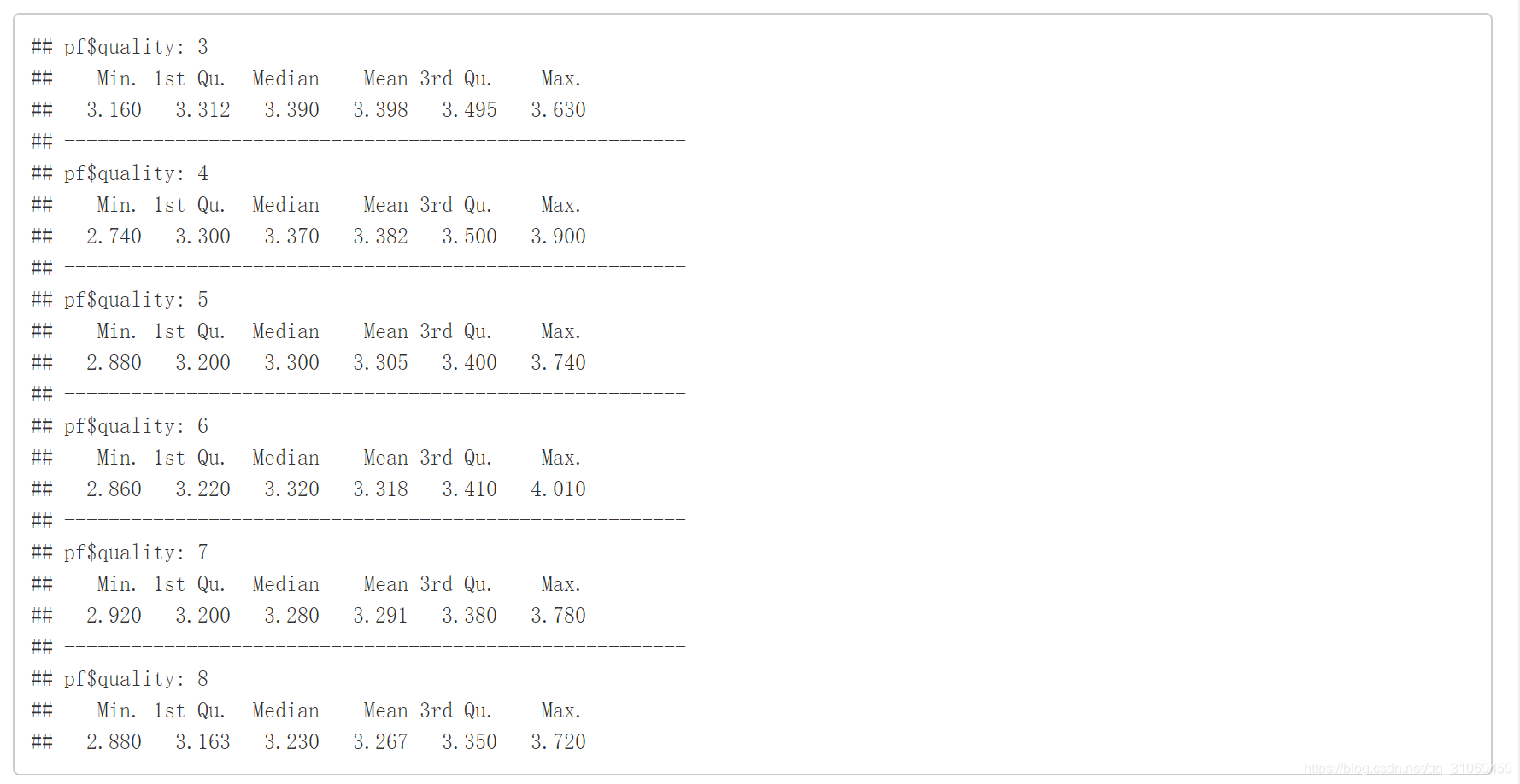
# 通过ggplot绘制变量quality与变量density的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = density),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)+
# 添加coord_trans图层限制y轴
coord_trans(limy = c(0.9901,1.0025))
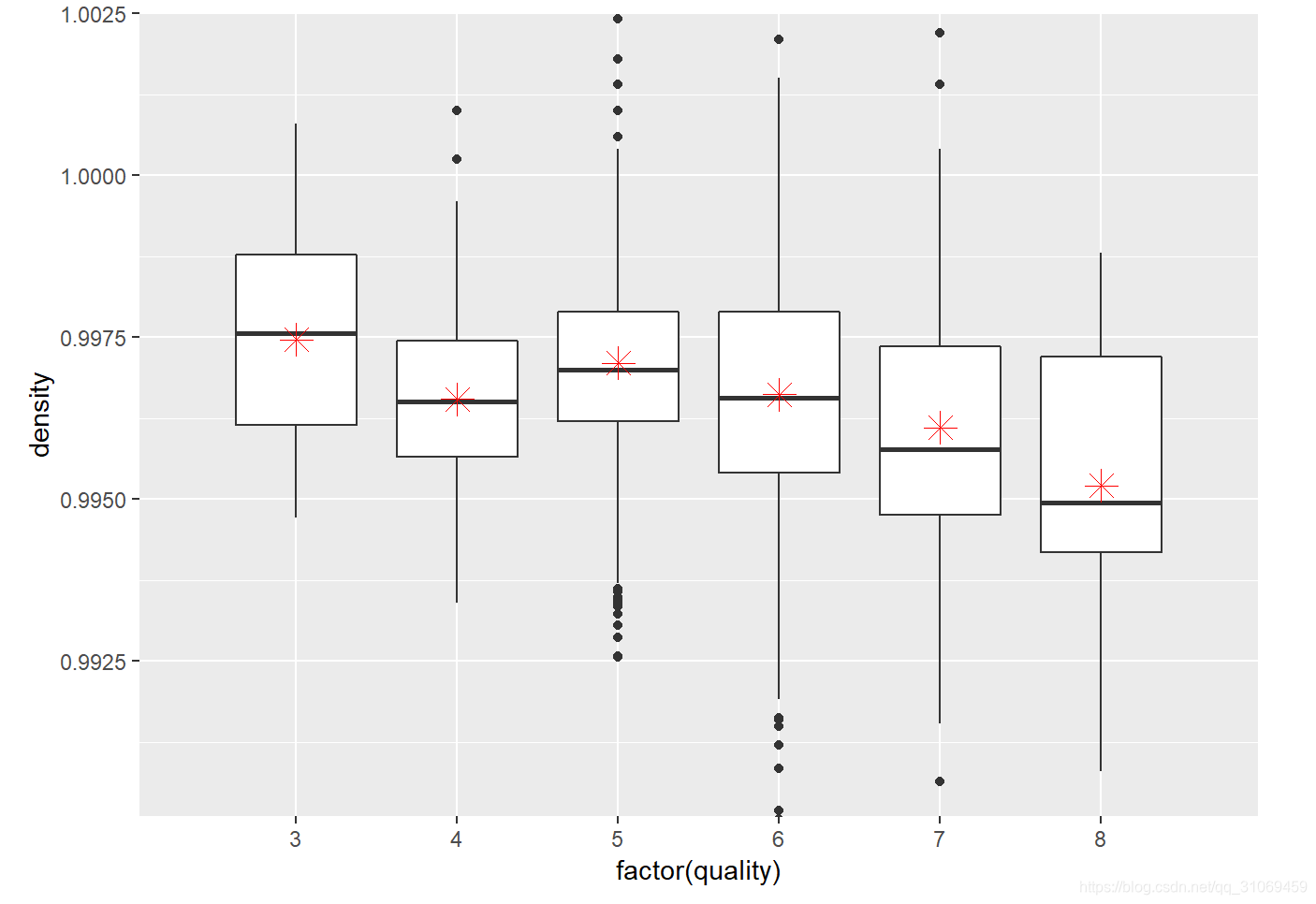
# 通过ggplot绘制变量quality与变量pH的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = pH),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)+
# 添加coord_trans图层限制y轴
coord_trans(limy = c(2.9,3.8))
从统计数据及箱线图看出,酒的密度中位数及平均数随着酒质量的提高有增有减,无法判断其与酒质量之间的关联性,酒的ph值同理。
sulphates探索
# 绘制变量sulphates的直方图
# 并将其保存到变量p1中
p1 <- ggplot(aes(x = sulphates),
data = pf)+
# 填充颜色
geom_histogram(color = "#696356",
fill = "#CACACA")+
# 添加scale_x_continuous层
# 并设置limits & breaks
scale_x_continuous(limits = c(0.3,2),
breaks = seq(0.3,2,0.2))
# 添加scale_x_log10()层,对长尾数据进行对数转换
# 并保存到变量p2中
p2 <- p1+
scale_x_log10()
# 将p1,p2两个变量分别传递给grid.arrange()
# 并设置两图形以一列的形式展示
grid.arrange(p1,p2,ncol = 1)
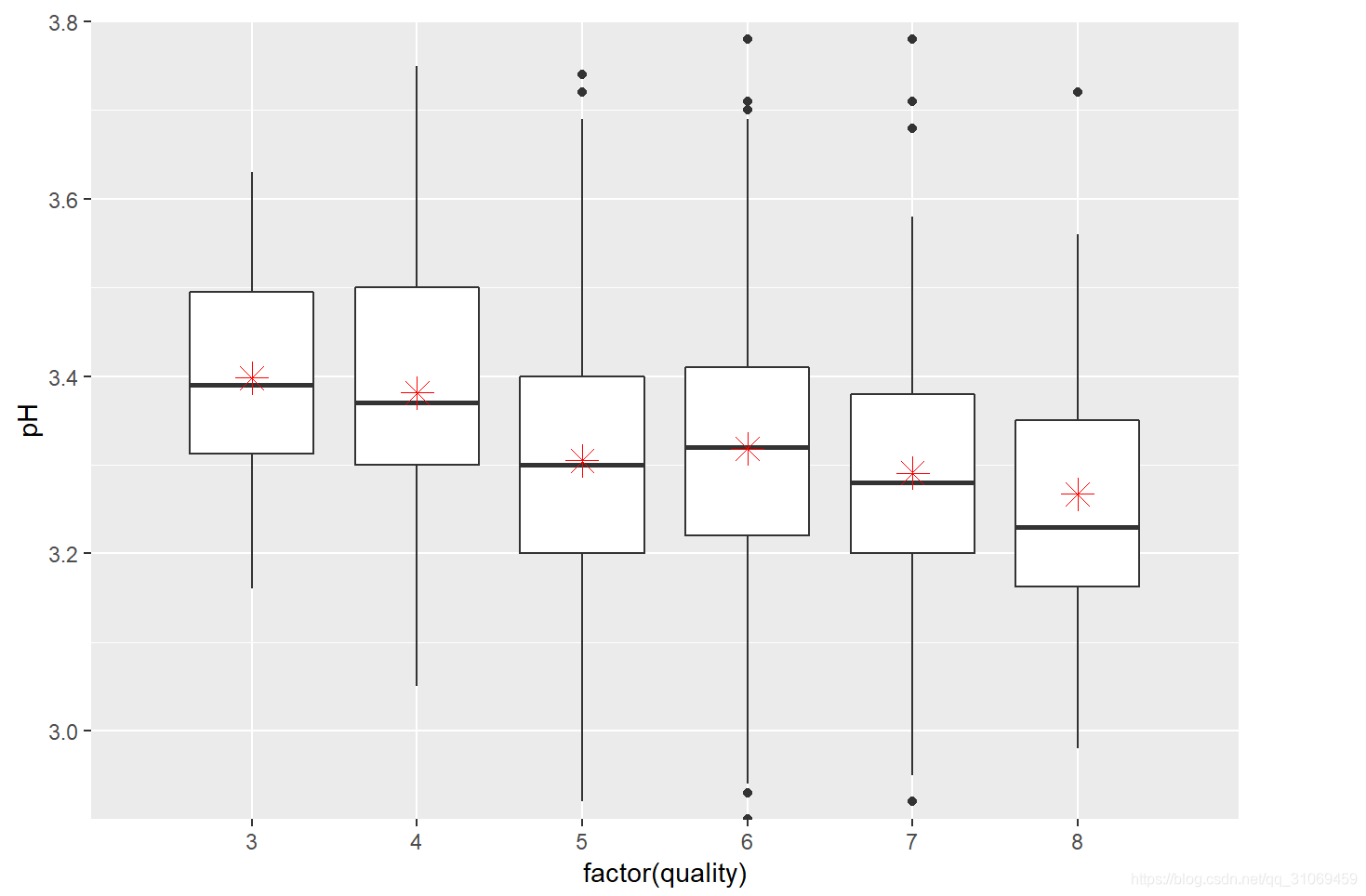
# 使用summary命令对变量sulphates进行汇总统计
summary(pf$sulphates)

酒的硫酸盐分布偏右太,对其进行对数转换,转换之后分布近似正太。数据集中在0.5 ~ 0.9 g /dm3 之间。
# 通过by命令统计出不同quality的sulphates汇总
by(pf$sulphates,pf$quality,summary)
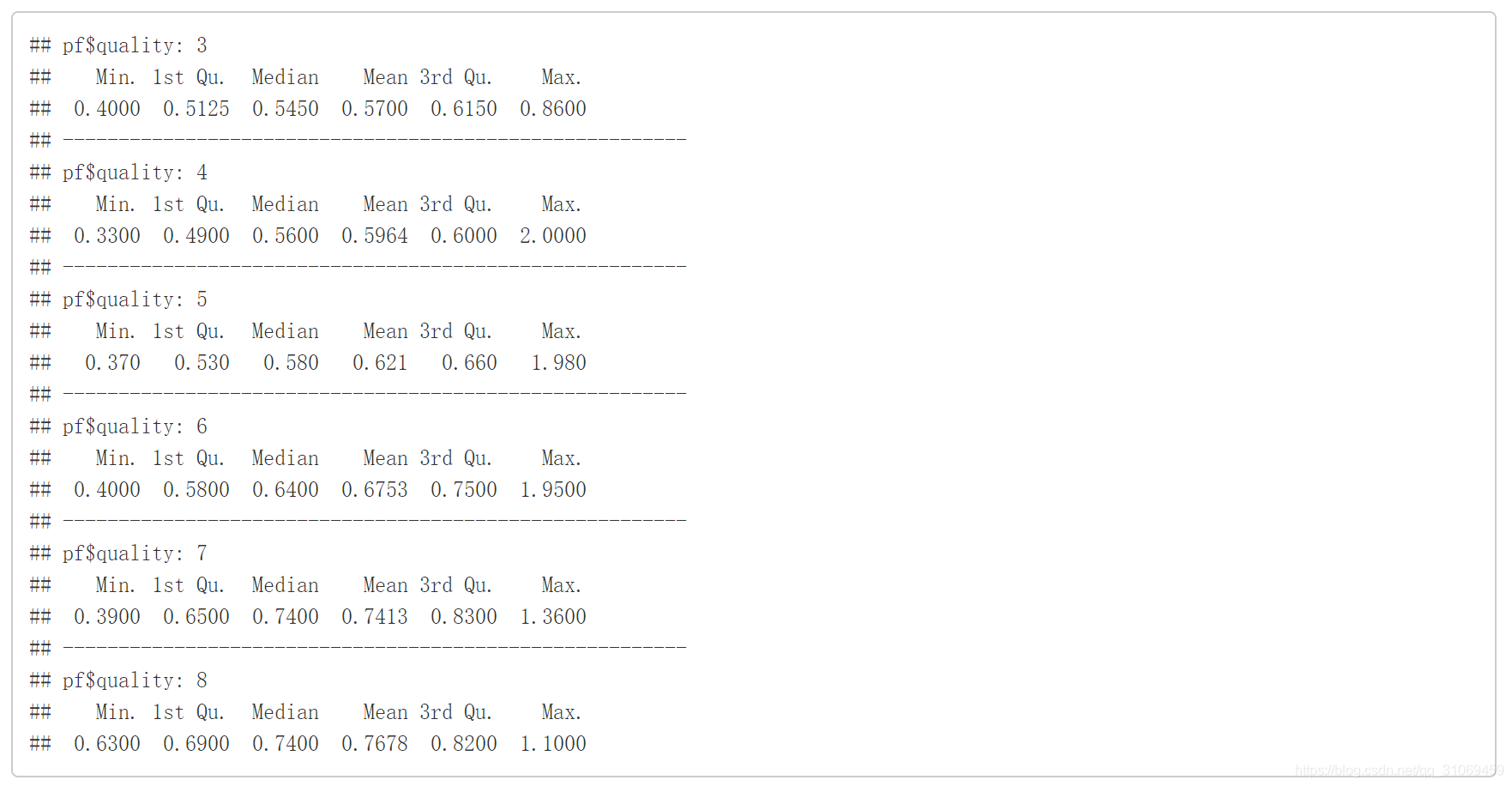
# 通过ggplot绘制变量quality与变量sulphates的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = sulphates),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)+
# 添加coord_trans图层限制y轴
coord_trans(limy = c(0.3,1.2))
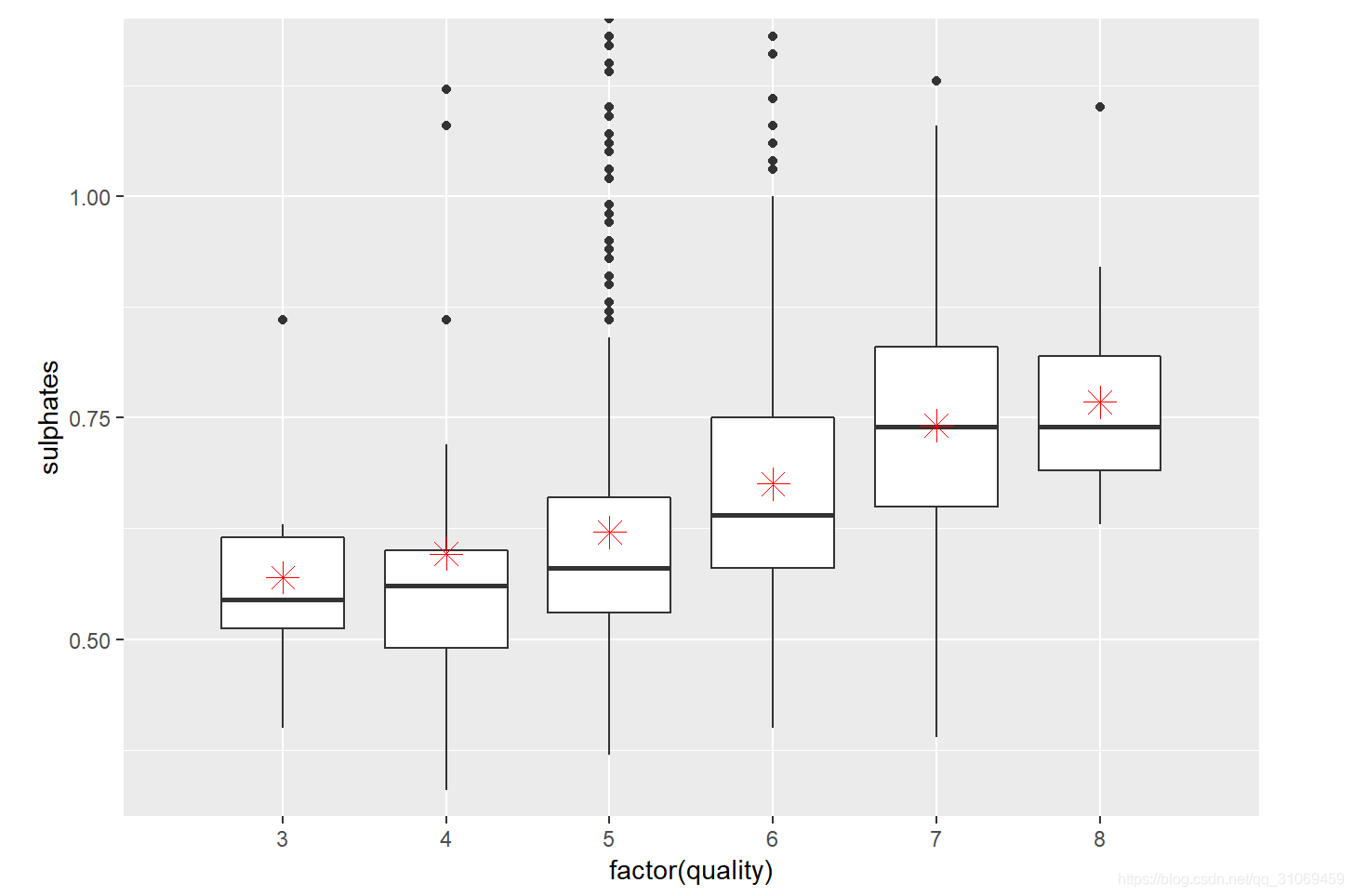
从汇总统计及箱线图来看,随着酒质量的提高,酒的硫酸盐中位数与平均数也相应提高,硫酸盐与酒质量关系需要进一步探索。
alcohol探索
# 通过ggplot函数来绘制变量alcohol的直方图
ggplot(aes(x = alcohol),
data = pf)+
# 填充颜色
geom_histogram(color = "#696356",
fill = "#CACACA")+
# 添加scale_x_continuous层
# 并设置limits & breaks
scale_x_continuous(limits = c(8,15),
breaks = seq(8,15,1))
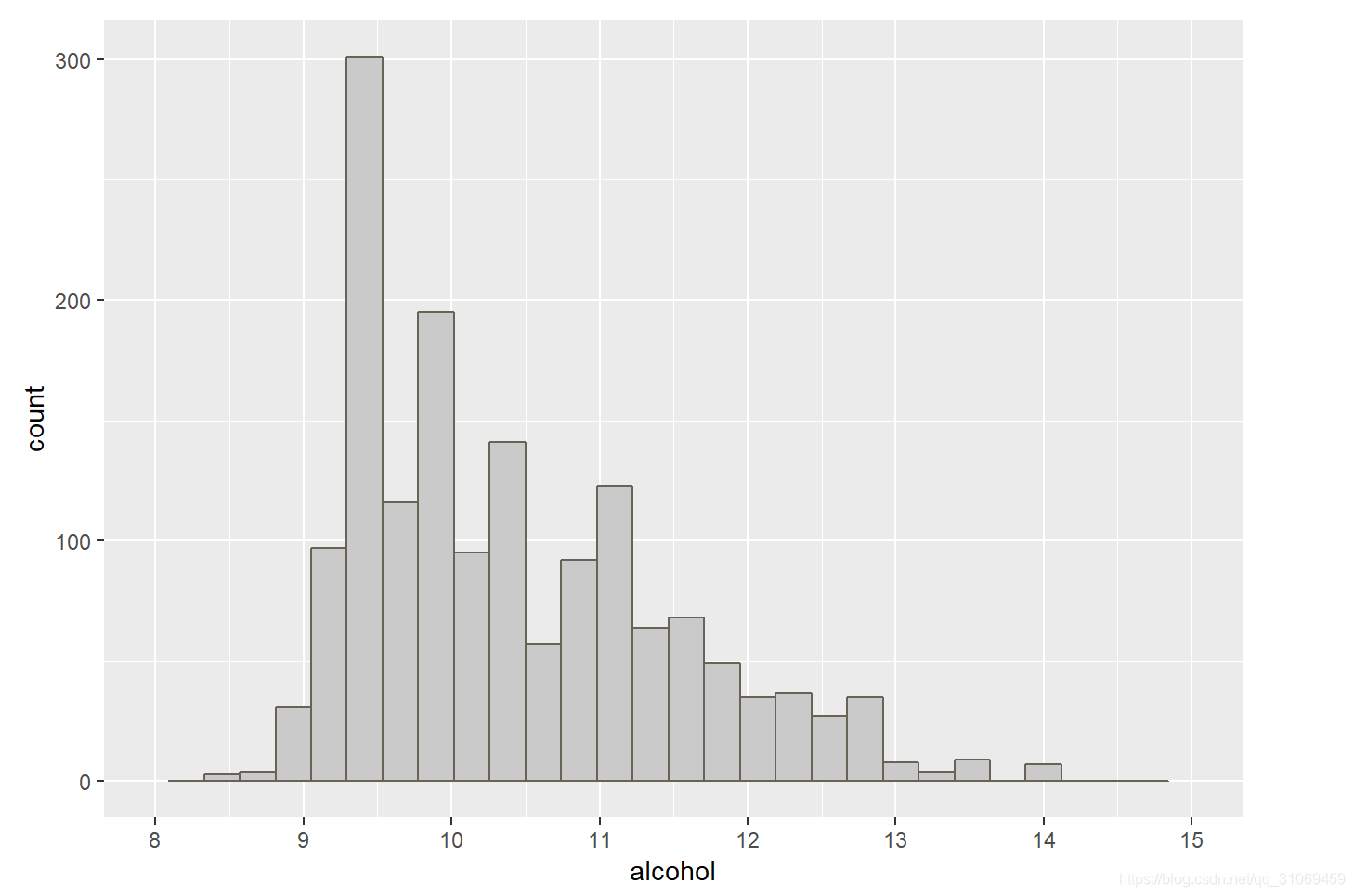
酒精分布也偏右太,大部分数据集中于9~11%之间。
# 使用summary命令对变量alcohol进行汇总统计
summary(pf$alcohol)

# 通过by命令统计出不同quality的alcohol汇总
by(pf$alcohol,pf$quality,summary)
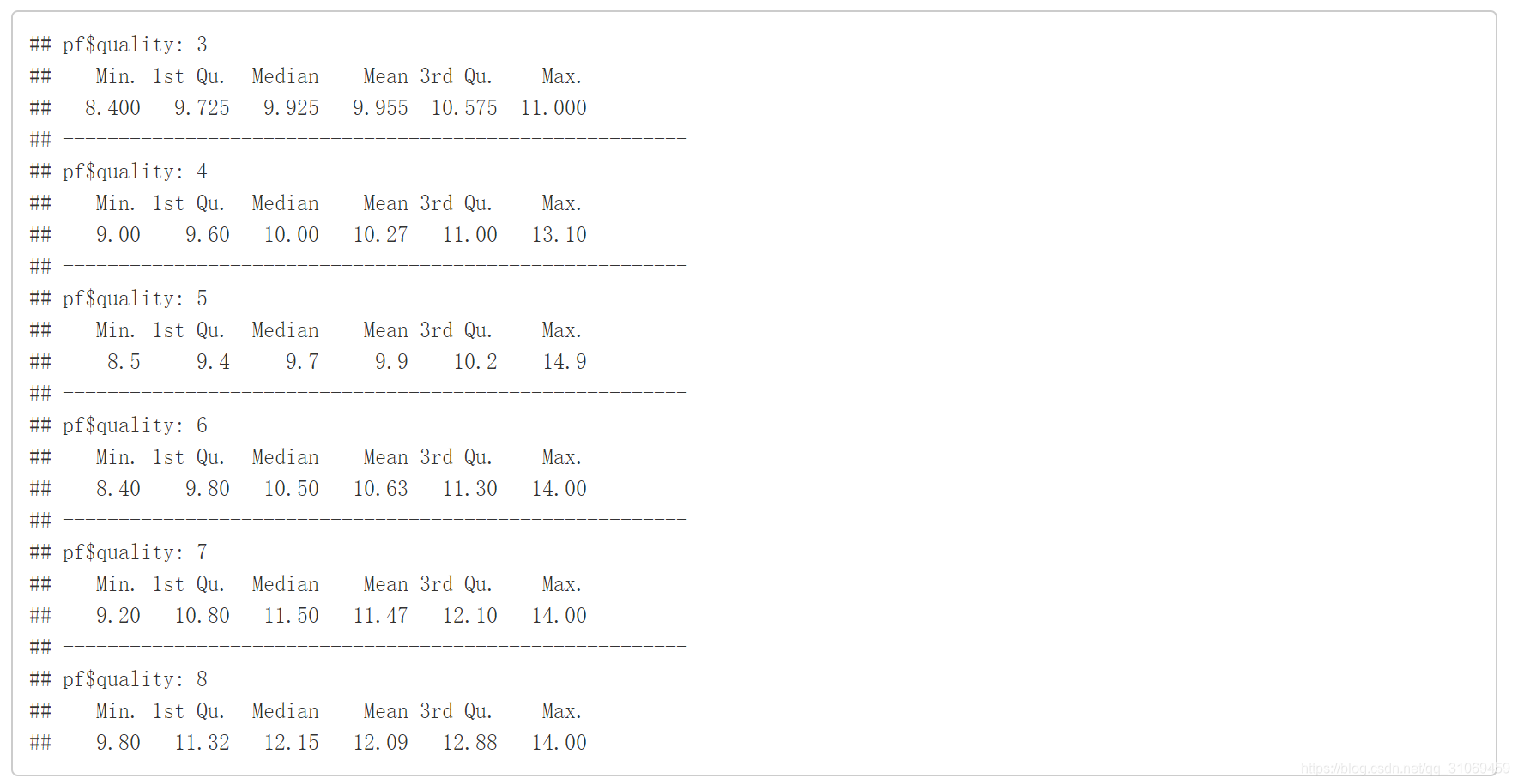
# 通过ggplot绘制变量quality与变量alcohol的箱线图
# 变量quality需要转换为factor类型
ggplot(aes(x = factor(quality),
y = alcohol),
data = pf)+
# 箱线图
geom_boxplot()+
# 通过stat_summary函数添加不同组的平均值
# 同时设置平均值以散点图的形式与箱线图叠加
# 设置点的颜色,形状及大小
stat_summary(fun.y = 'mean',
geom = 'point',
color='red',
shape=8,
size=4)
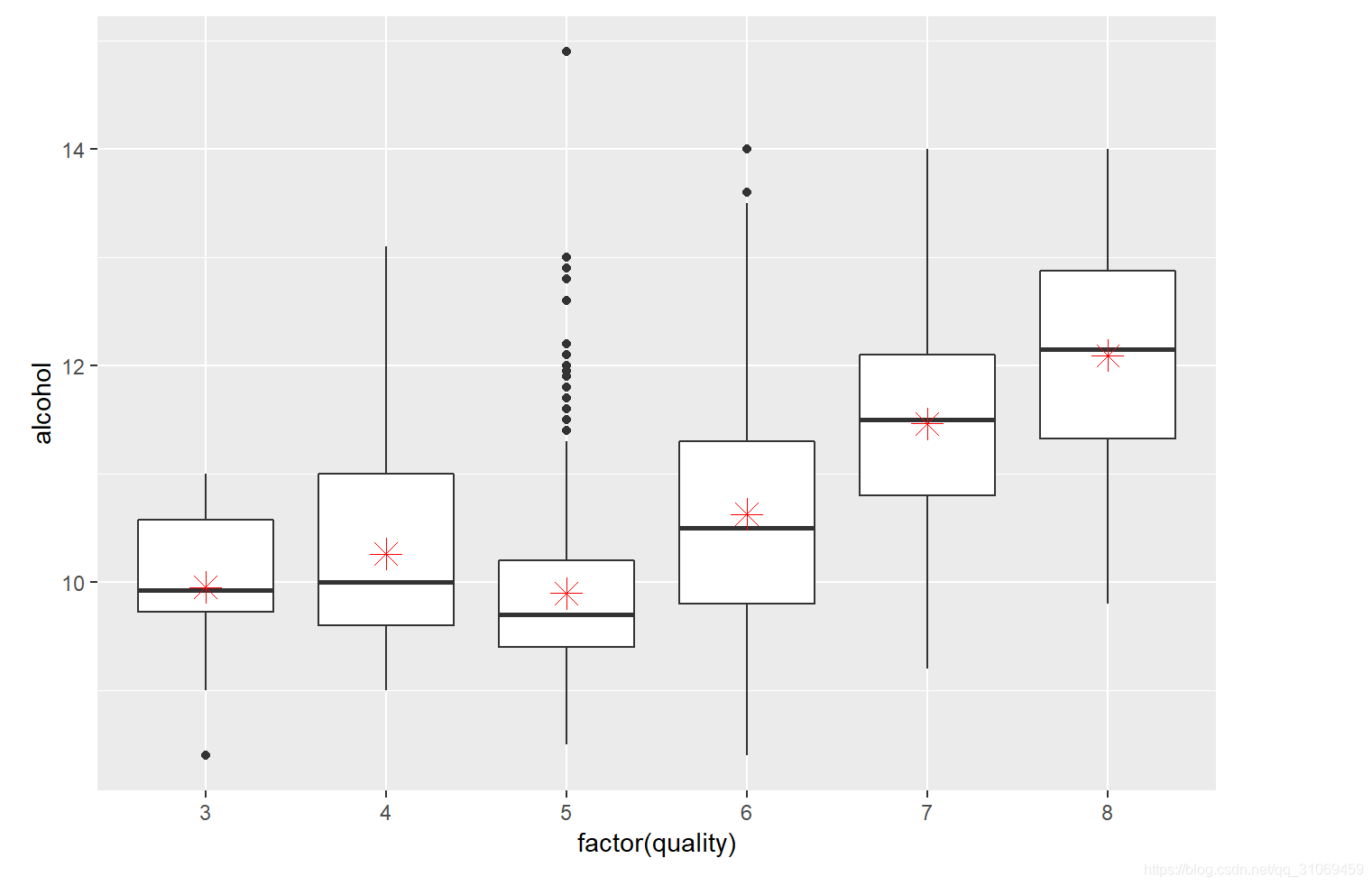
从汇总统计及箱线图分布来看,酒精的中位数与平均值随着酒质量的提高而增加,需要进一步探索酒精与质量间的关系。
单变量分析
你的数据集结构是什么?
数据集中有1599条红葡萄酒记录,有13个变量,其中x为红葡萄酒编号,11个红葡萄酒理化特征(固定酸、挥发性酸、柠檬酸、剩余糖分、氯化物、游离二氧化硫、总二氧化硫、密度、pH值,硫酸盐和酒精)1个基于感觉判断的输出变量–质量。
你的数据集内感兴趣的主要特性有哪些?
最感兴趣的特征是红葡萄酒的质量,我想确定哪些化学成分最能影响红葡萄酒的质量。
你认为数据集内哪些其他特征可以帮助你探索兴趣特点?
从直方图的分布来看,我认为挥发性酸、柠檬酸、氯化物、硫酸盐、酒精与质量应该有关联,需要进一步探索。
根据数据集内已有变量,你是否创建了任何新变量?
基于现有数据,可以满足探索需求。
在已经探究的特性中,是否存在任何异常分布?你是否对数据进行一些操作,如清洁、调整或改变数据的形式?如果是,你为什么会这样做?
除了密度,ph值及酒精外,其余数据为长尾数据,我对其进行了对数转换。
双变量绘图选择
我们使用gpairs来创建散点图矩阵。
gpairs(pf,
# 令矩阵的上三角为统计量,统计相关系数
upper.pars = list(scatter = 'stats'),
# 设置统计量的显示属性
stat.pars = list(fontize = 9, # 字体大小为9
signif = 0.05, # 显著性水平0.05
verbose = F, # verbose取值为F时
# 只显示pearson相关系数
use.color = T), # use.color取值为T时
#上三角格子的背景色与pearson相关系数有关,正数为蓝色,负数为红色,绝对值越大颜色越深。
# 令矩阵的下三角为光滑回归
lower.pars = list(scatter = "loess"),
diagonal = "default", # 对角线上显示变量名
#设置对角线属性
diag.pars = list(fontsize = 9,# 字体大小为9
show.hist = TRUE, # 显示直方图
hist.color = '#17BECF'),# 直方图颜色为黑色
# 设置轴的属性
axis.pars = list(n.ticks = 5, # 轴刻度数量为5
fontsize = 9)) # 轴刻度标签字体大小为9
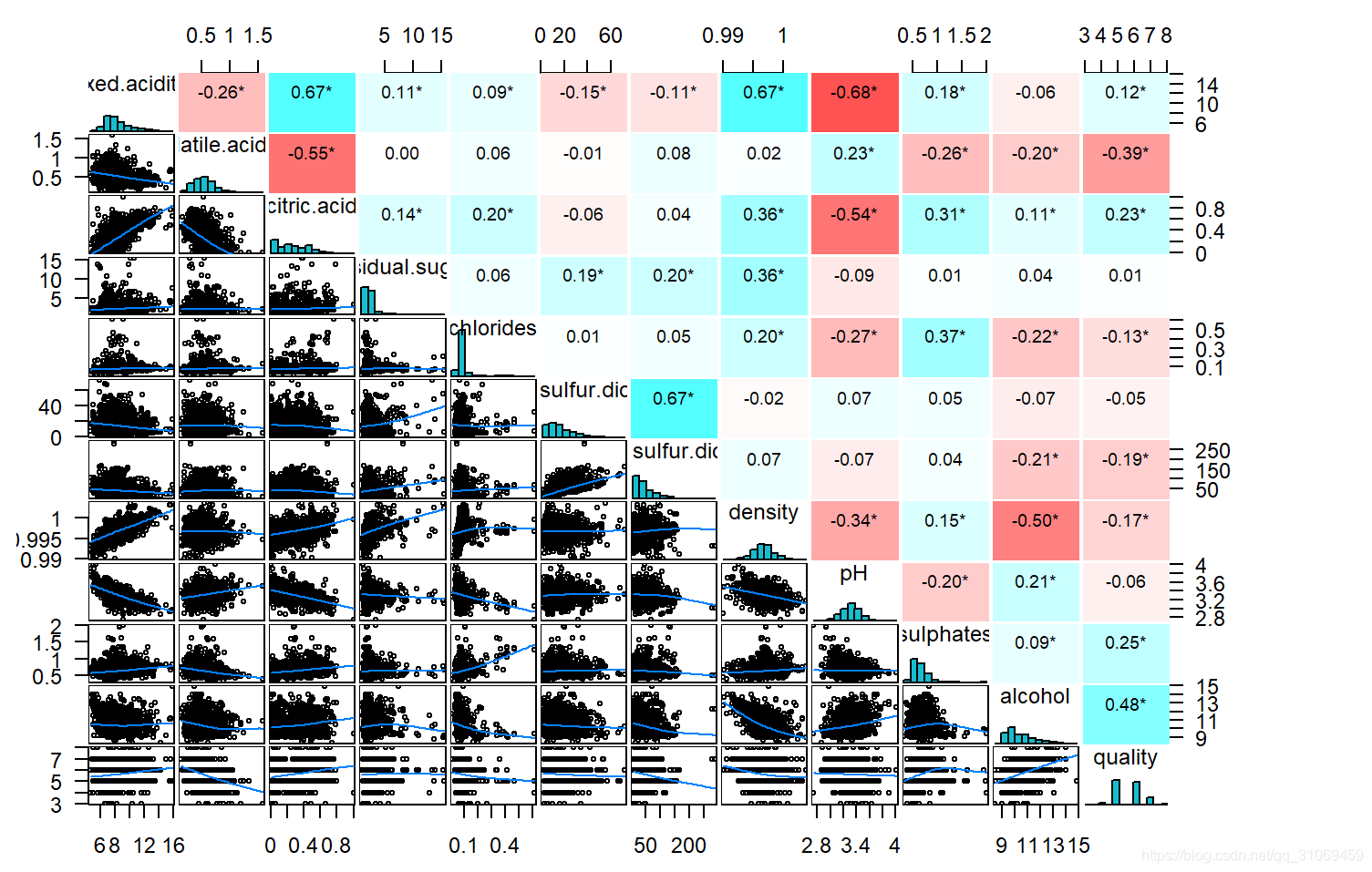
这是我们的散点图矩阵,可从矩阵的上半部分看到变量对的相关系数,下半部分是变量对散点图矩阵的图表。对角线上是变量分布。我们的目标是了解哪些成分影响红葡萄酒的质量,从各变量与质量的相关系数可以看到,酒精,硫酸盐,剩余糖分,柠檬酸,固定酸与质量呈正相关,其余变量与质量呈负相关。按照经验法则,关联大于0.3或小于-0.3表示有意义但是较小。0.5附近为中等,0.7或以上为很大.所以我们主要关注酒精,挥发性酸与质量的相关性。因为这两队变量的相关系数大于0.3或小于-0.3.
另外,关于pH与固定酸及酒精与密度之间的关系,同样比较感兴趣,可以进一步探索。
挥发性酸与质量的关系探索
# 通过ggplot函数绘制挥发性酸与质量的散点图
ggplot(aes(x = quality ,
y = volatile.acidity),
data = pf)+
# 通过geom_jitter添加抖动,并填充颜色
geom_jitter(color = "#73B4D2")+
# 将箱线图与散点图进行叠加,以变量quality进行分组,设置透明度
geom_boxplot(aes(group = quality),alpha = 0.4)+
# 将折线图与散点图叠加,将geom_line添加到图形中来实现
geom_line(stat = "summary", # 将传递参数stat,并设置它等于汇总
fun.y = mean)+ # 将汇总给y的一个函数,此处传递平均值,并将其应用于y
# 向图形中添加90%分位数
geom_line(stat = "summary",
fun.y= quantile, # 添加分位数函数
fun.args = list(probs = .9), # 90%分位数
linetype = 2, # 线型为2
color = "blue")+ # 颜色为蓝色
# 向图形中添加10%分位数
geom_line(stat = "summary",
fun.y= quantile, # 添加分位数函数
fun.args = list(probs = .1), # 10%分位数
linetype = 2, # 线型为2
color = "purple")+ # 颜色为紫色
# 向图形中添加50%分位数,即中位数
geom_line(stat = "summary",
fun.y= quantile,# 添加分位数函数
fun.args = list(probs = .5), # 50%分位数
linetype = 2, # 线型为2
color = "red")+ # 颜色为紫色
# 添加平滑器
geom_smooth(method = "lm", #将方法设置为lm,即线性模型
color = "red")+ #着色为红色
# 添加scale_x_continuous,设置breaks
scale_x_continuous(breaks = seq(3,8,1))
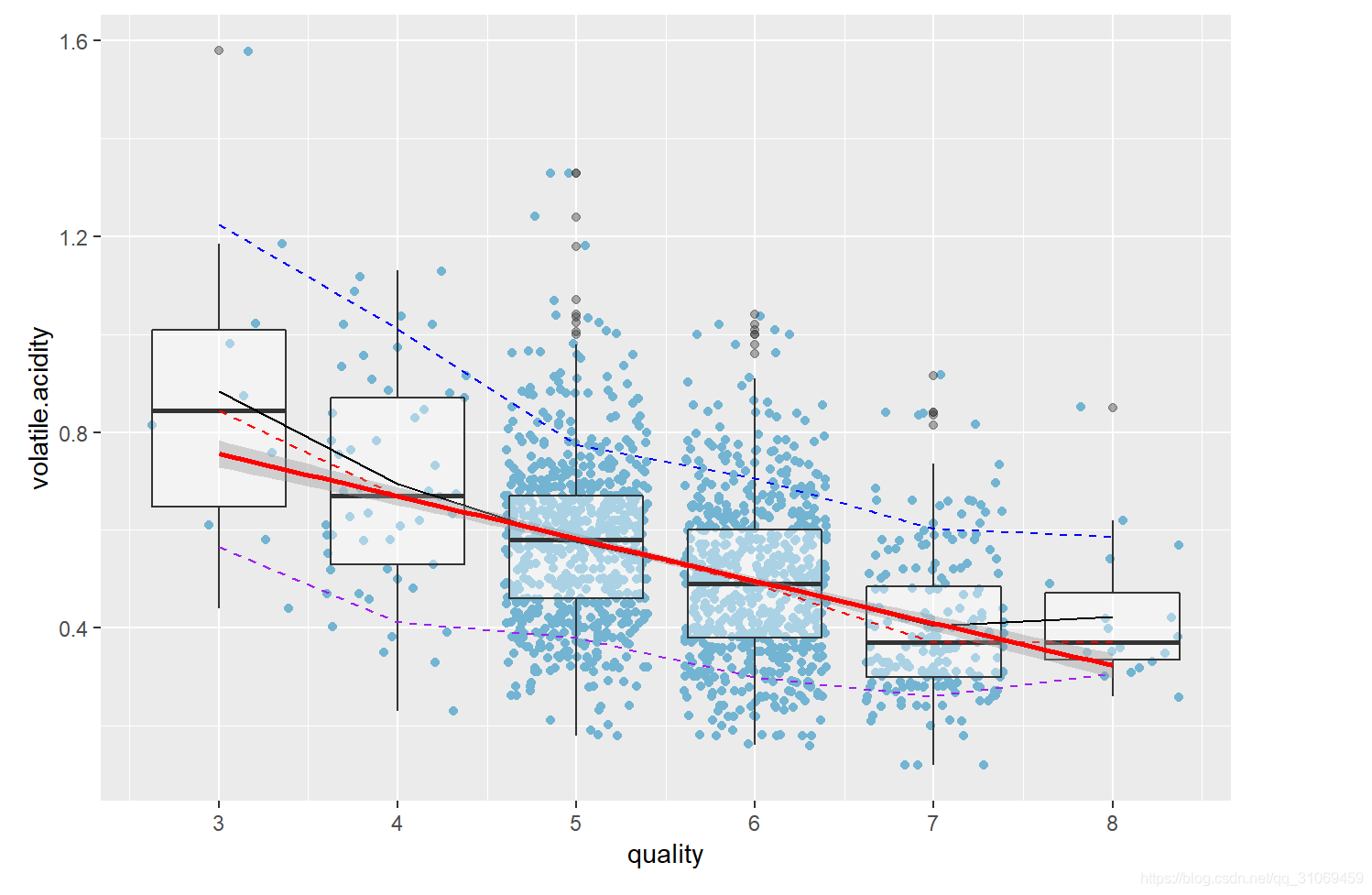
# 通过cor.test用数字来量化两者的相关性
with(pf,
cor.test(quality,
volatile.acidity,
method = "pearson"))

将汇总数据10%,50%,90%分位数,及平均值添加到原始散点图中。我们发现,随着酒质量水平的提升,各汇总数据均表现出减少的趋势。同时,向图形添加一个平滑器,并且也使用了一个数字来量化两者间的关系。发现挥发性酸与质量呈负相关性,并且该相关性有意义。
酒精与质量的关系探索
# 通过ggplot函数绘制酒精与质量的散点图
ggplot(aes(x = quality ,
y = alcohol),
data = pf)+
# 通过geom_jitter添加抖动,并填充颜色
geom_jitter(color = "#73B4D2")+
# 将箱线图与散点图进行叠加,以变量quality进行分组,设置透明度
geom_boxplot(aes(group = quality),alpha = 0.4)+
# 将折线图与散点图叠加,将geom_line添加到图形中来实现
geom_line(stat = "summary", # 将传递参数stat,并设置它等于汇总
fun.y = mean)+ # 将汇总给y的一个函数,此处传递平均值,并将其应用于y
# 向图形中添加90%分位数
geom_line(stat = "summary",
fun.y= quantile, # 添加分位数函数
fun.args = list(probs = .9), # 90%分位数
linetype = 2, # 线型为2
color = "blue")+ # 颜色为蓝色
# 向图形中添加10%分位数
geom_line(stat = "summary",
fun.y= quantile, # 添加分位数函数
fun.args = list(probs = .1), # 10%分位数
linetype = 2, # 线型为2
color = "purple")+ # 颜色为紫色
# 向图形中添加50%分位数,即中位数
geom_line(stat = "summary",
fun.y= quantile,# 添加分位数函数
fun.args = list(probs = .5), # 50%分位数
linetype = 2, # 线型为2
color = "red")+ # 颜色为紫色
# 添加平滑器
geom_smooth(method = "lm", #将方法设置为lm,即线性模型
color = "red")+ #着色为红色
# 添加scale_x_continuous,设置breaks
scale_x_continuous(breaks = seq(3,8,1))
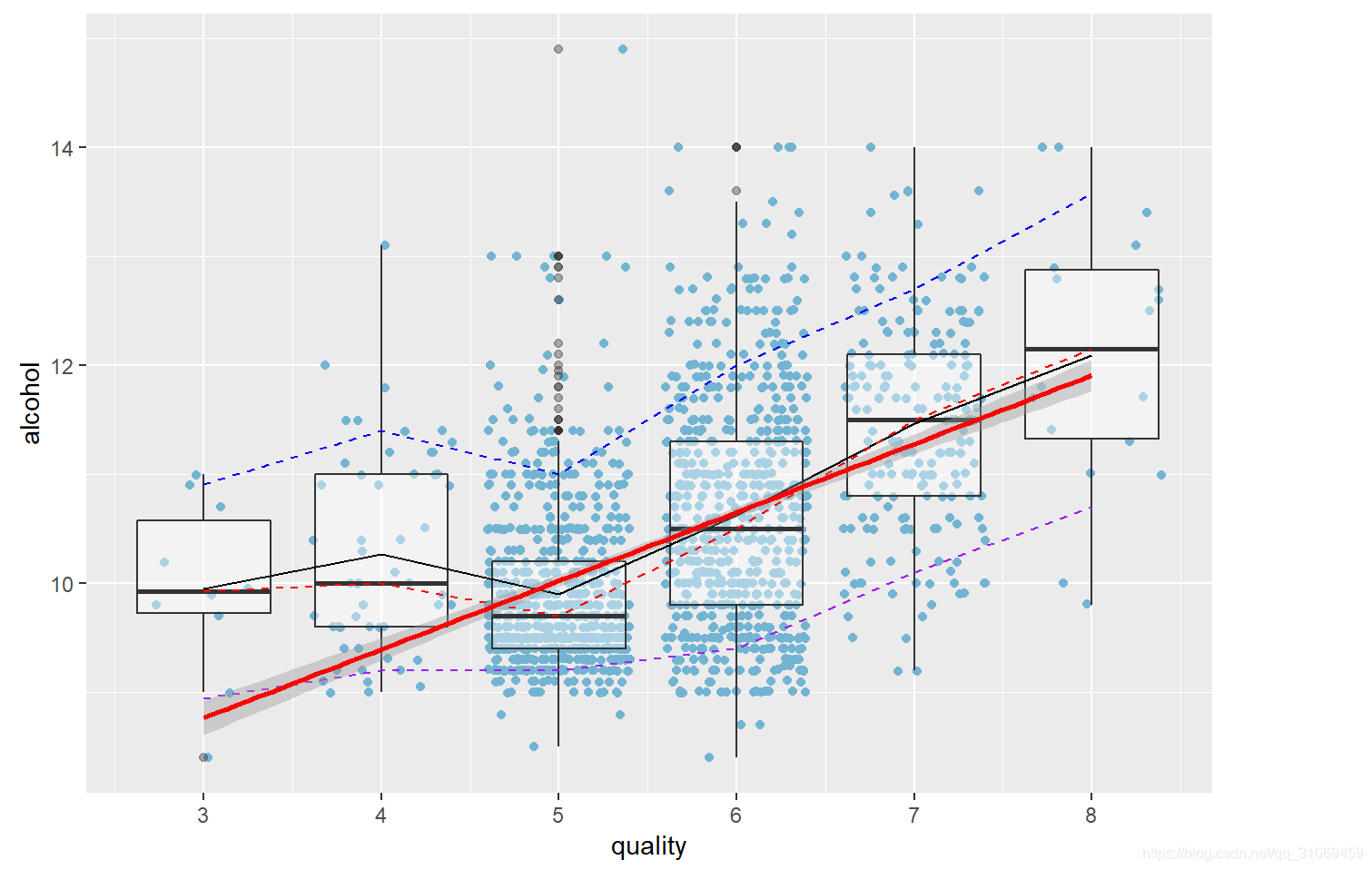
# 通过cor.test用数字来量化两者的相关性
with(pf,
cor.test(quality,
alcohol,
method = "pearson"))

同理,我们用相同的方法来探索酒精与质量的关系,我们发现,品质好的酒,其酒精度通常要高,相反,品质差的酒,其酒精度要低,从以上的图形及数字衡量来看,酒精与质量呈正相关关系。
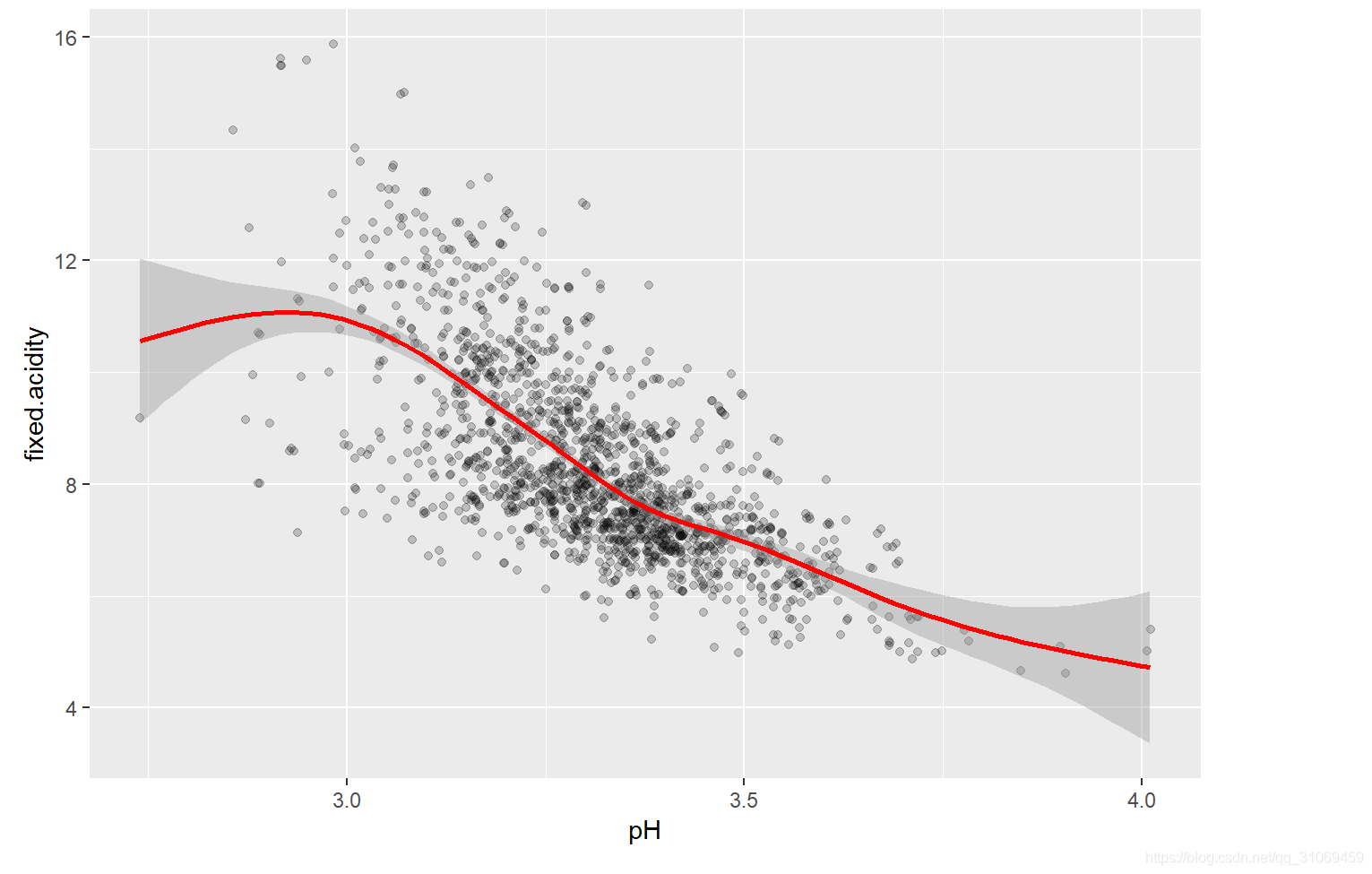
pH与固定酸的探索
# 通过ggplot函数绘制pH与固定酸的散点图
ggplot(aes(x = pH,
y = fixed.acidity),
data = pf)+
# 添加抖动,设置透明度
geom_jitter(alpha = 1/5)+
# 添加平滑器
geom_smooth(methods = "lm", #将方法设置为lm,即线性模型
color = "red") # 着色为红色
# 通过cor.test用数字来量化两者的相关性
with(pf,
cor.test(pH,
fixed.acidity,
method = "pearson"))

从上述的图形分析,我们发现pH与固定酸呈负相关性,pH值越低,葡萄酒中的酸度越高。pH值是衡量葡萄酒中酸度的一个标准,而酸度是体现葡萄酒中含酸量的程度,若是欠缺酸度,酒质就会显得相当松散。之后我们会继续探索,不同酒质的pH值与酸度变化。
双变量分析
探讨你在这部分探究中观察到的一些关系。这些感兴趣的特性与数据集内其他特性有什么区别?
因为我们的目标是研究哪些变量对酒品质有影响,所以重点关注与质量关系密切的变量,比如酒精与质量,挥发性酸与质量之间的关系。
而其它变量间的关系,我们也同样感兴趣并进行了探索,像酒中的pH值与固定酸的关系。
你是否观察到主要特性与其他特性之间的有趣关系?
挥发性酸越低,酒品质越好,反之亦然。酒精度越高,酒的品质越好,反之亦然。而pH值与挥发性酸呈负相关关系。
你发现最强的关系是什么?
酒中的挥发性酸与酒品质呈负相关性,酒精度与酒的品质呈正相关性。
多变量绘图选择
# 绘制pH与固定酸的散点图,并在此基础上添加第三个变量quality
ggplot(data = pf,
aes(x=pH,
y=fixed.acidity,
color=factor(quality)))+
# 设置散点图大小
geom_point(size=2)+
# 添加平滑器
geom_smooth(method = 'lm', #将方法设置为lm,即线性模型
se = FALSE, # 去掉拟合线的阴影
size=2)+ #设置平滑线大小
# 使用颜色扩展包RColorBrewer中的配色方案
scale_color_brewer(type='div', # div,生成用深色强调两端,浅色标示中部的系列颜色
guide = guide_legend(title = 'Quality'))+ # 设置图例
# 加深图形的背景色
theme_dark()+
# 设置图形标题
ggtitle('pH and fixed acidity of red wine based on Quality')+
# 设置Y轴标签
labs(y='fixed acidity (tartaric acid - g/dm^3)')
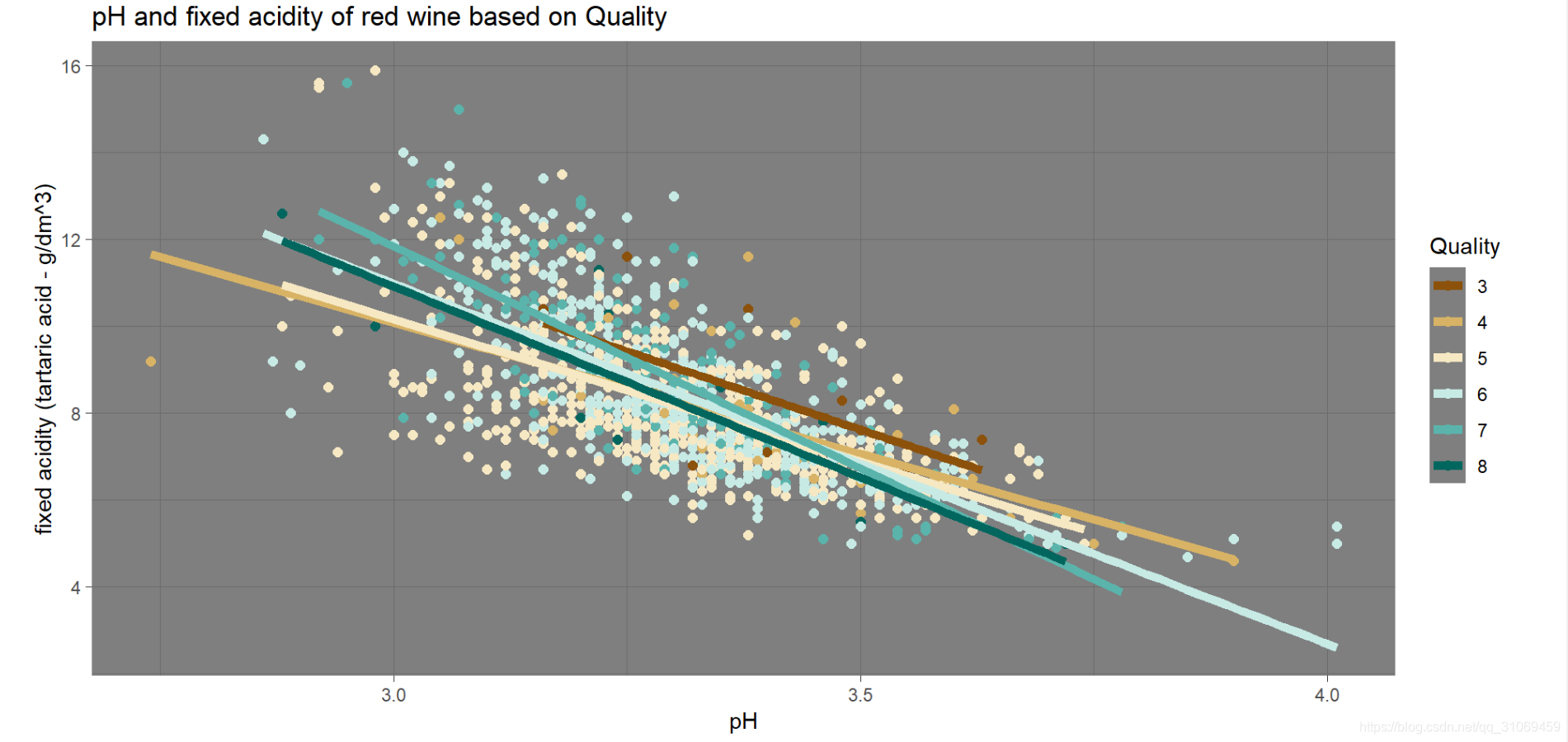
之前我们探讨了pH值与固定酸的关系,二者呈负相关性,我们加入第三个变量质量,。当pH值小于3大于2.75时,好品质的酒其固定酸要高于低品质的酒,当pH值高于3.5时,高品质酒的固定酸低于低品质酒的固定酸。
# 绘制酒精与挥发性酸的散点图,并在此基础上添加第三个变量quality
ggplot(data = pf,
aes(x=alcohol,
y=volatile.acidity,
color=factor(quality)))+
# 设置散点图大小
geom_point(size=2)+
# 添加平滑器
geom_smooth(method = 'lm',#将方法设置为lm,即线性模型
se = FALSE, # 去掉拟合线的阴影
size=2)+ #设置平滑线大小
# 使用颜色扩展包RColorBrewer中的配色方案
scale_color_brewer(type='div', # div,生成用深色强调两端,浅色标示中部的系列颜色
guide = guide_legend(title = 'Quality'))+ # 设置图例
# 加深图形的背景色
theme_dark()+
# 设置图形标题
ggtitle('alcohol and volatile.acidity of red wine based on Quality')+
# 设置Y轴标签
labs(y='volatile.acidity (tartaric acid - g/dm^3)')
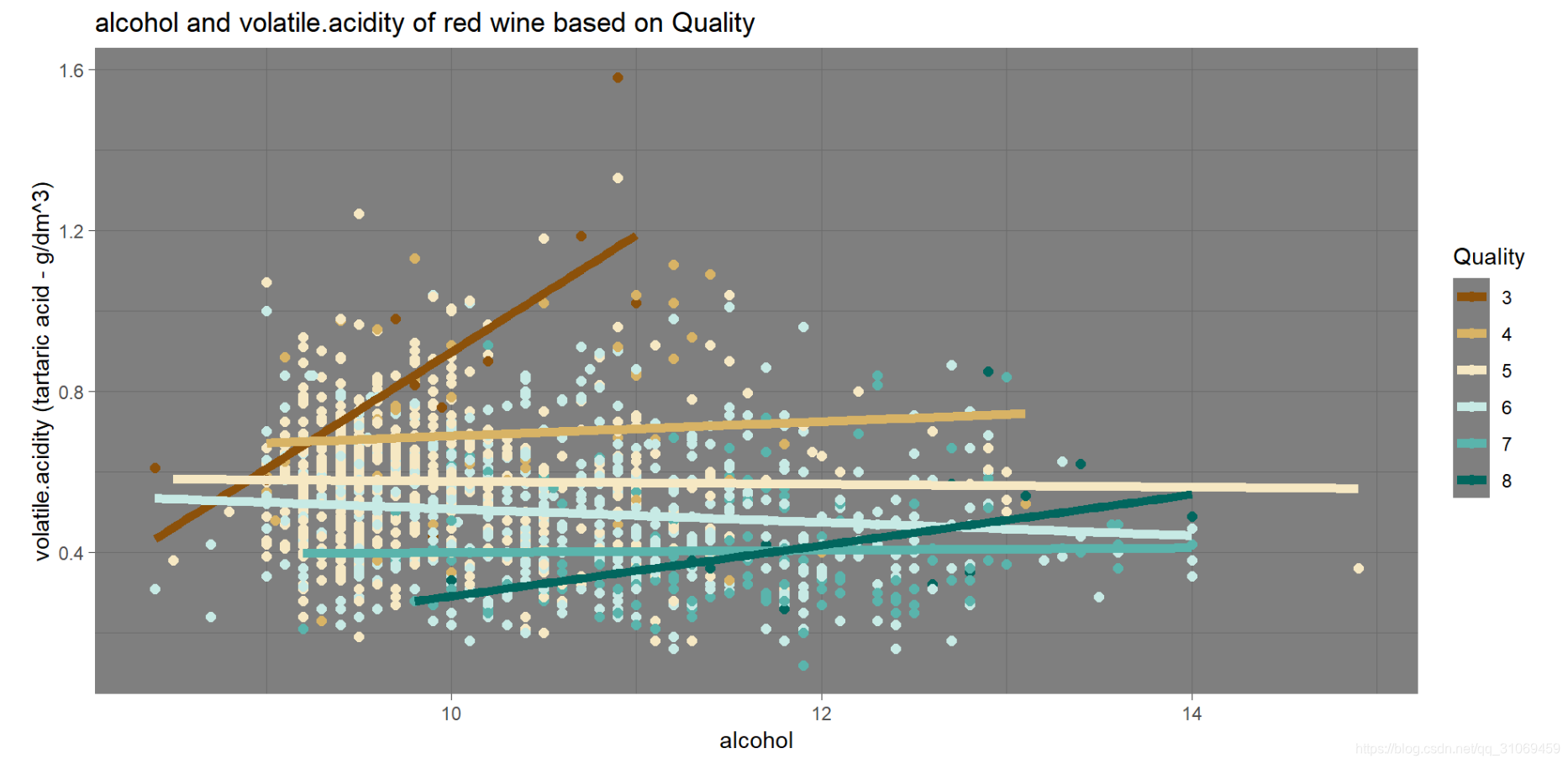
从上图可以看出,较高酒精度与较低挥发酸结合起来可以产生高品质的葡萄酒。
多变量分析
探讨你在这部分探究中观察到的一些关系。通过观察感兴趣的特性,是否存在相互促进的特性?
酒精度与挥发性酸两个变量相互配合,促使好品质的葡萄酒产生。
这些特性之间是否存在有趣或惊人的联系呢?
相较于pH大于3.5的酒,pH值较低的葡萄酒,其酒液中微生物的生长能得到有效的抑制,酒体和风味等能保持相对稳定的状态,故酒质较好。而pH较大的酒中,含酸量可能较小,会影响酒的口感,所以有必要在不同的工艺水平下,调整pH以达到酒质最大化。
选项:你是否创建过数据集的任何模型?讨论你模型的优缺点。
------没有
定稿图与总结
绘图一
# 通过ggplot函数来绘制变量quality的条形图
ggplot(data = pf, aes(x=factor(quality))) +
# 填充颜色
geom_bar(color = "#696356",
fill = "#CACACA")+
# 设置标签及标题
labs(x = 'Quality', y = 'Frequency',
title = 'Bargraph for quality of red wines')
描述一
该数据集中的质量评分是葡萄酒专家至少3次评估的中位数,每个专家都对葡萄酒的质量打分,介于0(非常差)和10(非常好)之间。该条形图展示了该数据集中红葡萄酒的质量评分分布情况,其近似于正太分布,数据集中分布在5~6分,最大值8分,最小值3分。
绘图二
p1 <- # 通过ggplot函数绘制挥发性酸与质量的散点图
ggplot(aes(x = quality ,
y = volatile.acidity),
data = pf)+
# 通过geom_jitter添加抖动,并填充颜色
geom_jitter(color = "#73B4D2")+
# 将箱线图与散点图进行叠加,以变量quality进行分组,设置透明度
geom_boxplot(aes(group = quality),alpha = 0.4)+
# 添加平滑器
geom_smooth(method = "lm", #将方法设置为lm,即线性模型
color = "red")+ #着色为红色
# 添加scale_x_continuous,设置breaks
scale_x_continuous(breaks = seq(3,8,1))+
# 添加标签及标题
labs(x = "Quality",
y = "volatile acidity (acetic acid g/dm^3)",
title = "The linear relationship between volatile acidity and quality")
p2 <- # 通过ggplot函数绘制酒精与质量的散点图
ggplot(aes(x = quality ,
y = alcohol),
data = pf)+
# 通过geom_jitter添加抖动,并填充颜色
geom_jitter(color = "#73B4D2")+
# 将箱线图与散点图进行叠加,以变量quality进行分组,设置透明度
geom_boxplot(aes(group = quality),alpha = 0.4)+
# 添加平滑器
geom_smooth(method = "lm", #将方法设置为lm,即线性模型
color = "red")+ #着色为红色
# 添加scale_x_continuous,设置breaks
scale_x_continuous(breaks = seq(3,8,1))+
# 添加标签及标题
labs(x = "Quality",
y = "Alcohol (% by volume)",
title = "The linear relationship between alcohol and quality ")
grid.arrange(p1,p2,ncol = 1)
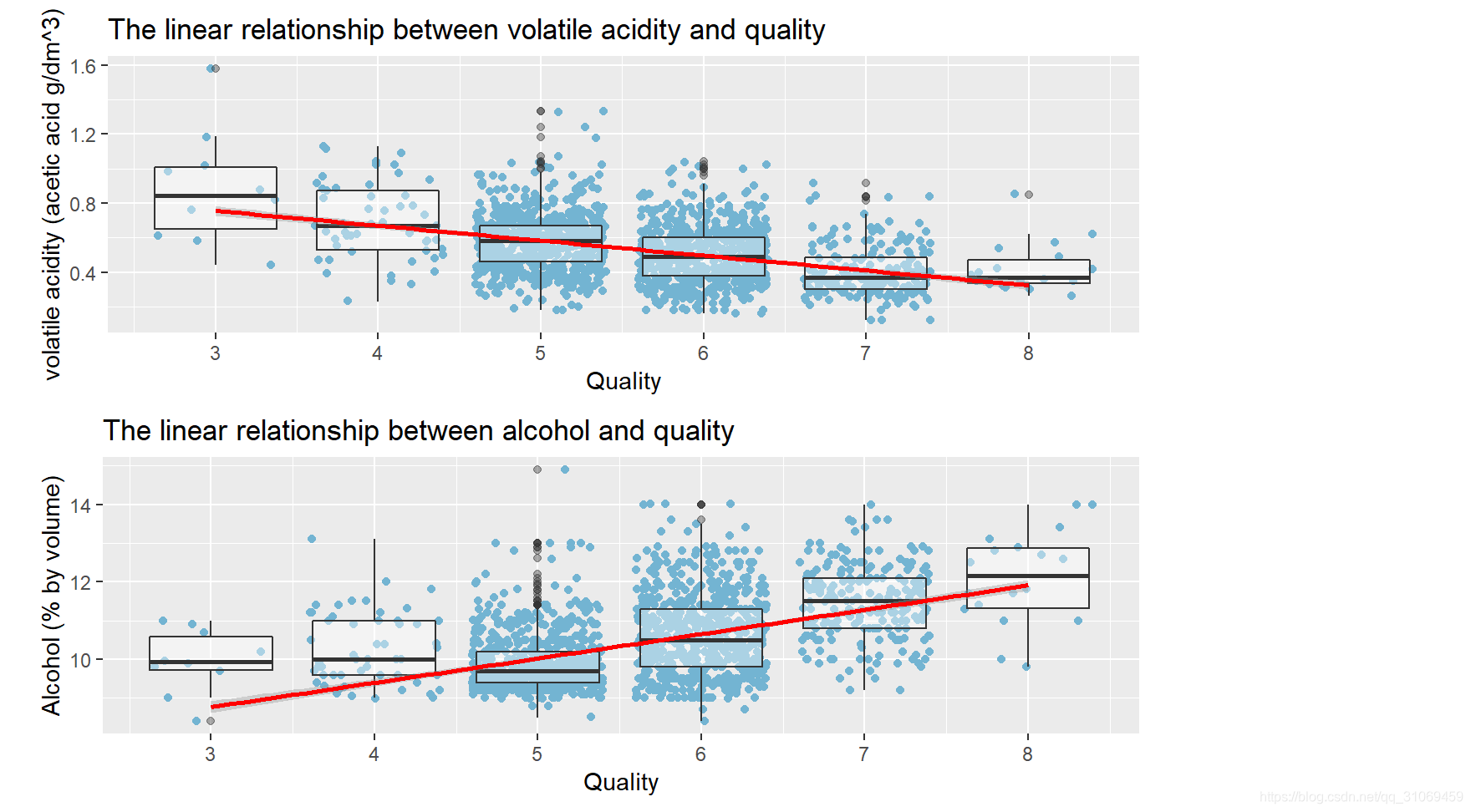
描述二
随着对数据进一步探索,发现在这些理化指标中酒精与挥发性酸对酒品质的影响比较大。挥发性酸与质量呈负相关性,酒精与质量呈正相关性。
绘图三
# 绘制pH与固定酸的散点图,并在此基础上添加第三个变量quality
ggplot(data = pf,
aes(x=pH,
y=fixed.acidity,
color=factor(quality)))+
# 设置散点图大小
geom_point(size=2)+
# 添加平滑器
geom_smooth(method = 'lm', #将方法设置为lm,即线性模型
se = FALSE, # 去掉拟合线的阴影
size=2)+ #设置平滑线大小
# 使用颜色扩展包RColorBrewer中的配色方案
scale_color_brewer(type='div', # div,生成用深色强调两端,浅色标示中部的系列颜色
guide = guide_legend(title = 'Quality'))+ # 设置图例
# 加深图形的背景色
theme_dark()+
# 设置图形标题
ggtitle('pH and fixed acidity of red wine based on Quality')+
# 设置Y轴标签
labs(y='fixed acidity (tartaric acid-g/dm^3)')
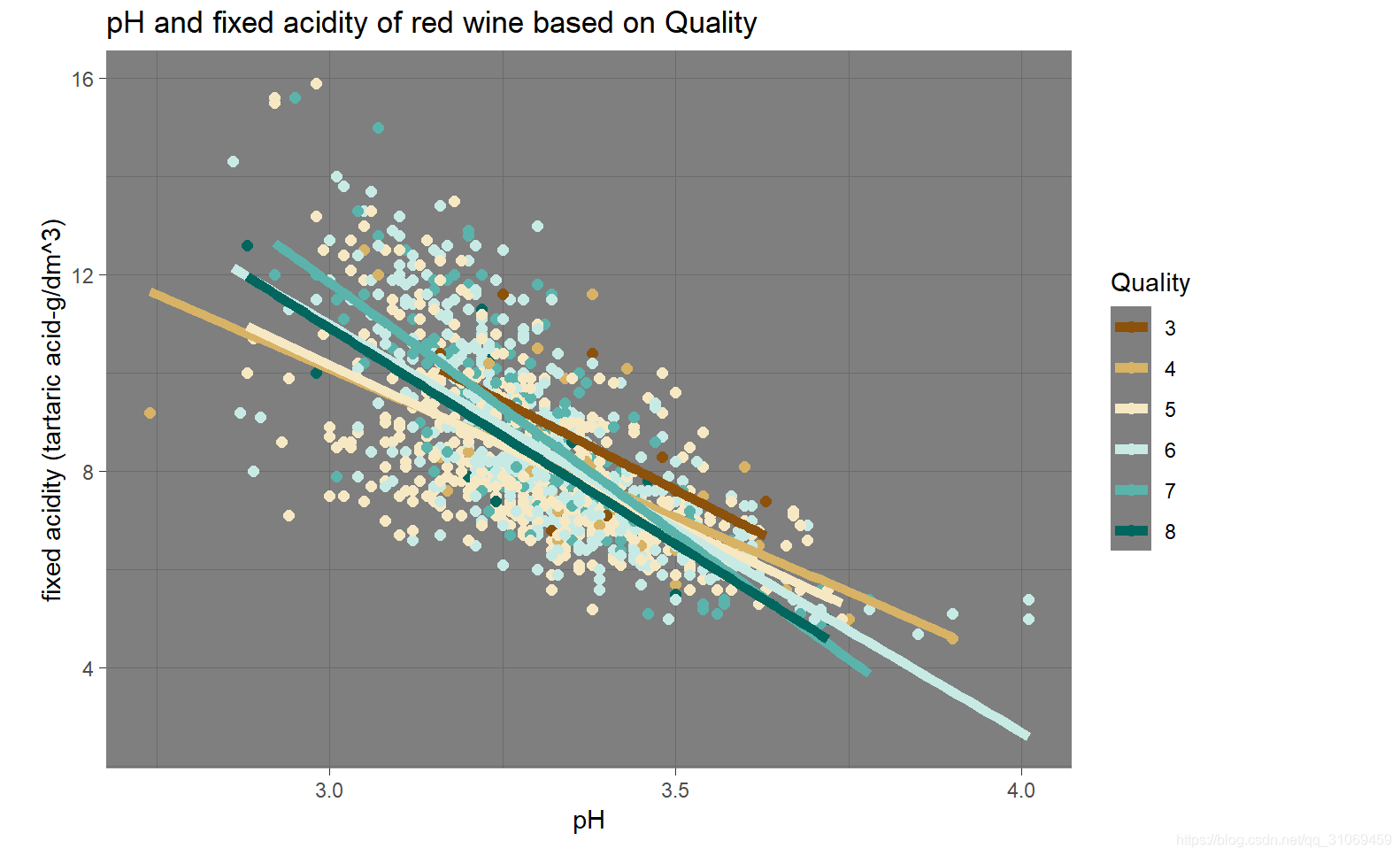
描述三
随着探索的深入,将质量作为分类变量加入到pH值与固定酸的关系中后,发现了一个有趣的现象,当pH值小于3大于2.75时,好品质的酒其固定酸要高于低品质的酒,当pH值高于3.5时,高品质酒的固定酸低于低品质酒的固定酸,在不同的生产工艺及生产过程中,合理的控制pH值,权衡其与酸度间的关系,则可以更好的提升葡萄酒的质量及稳定性。
反思
首先我将本次报告的分析做一个小结:
单变量探索:通过绘制每个变量的直方图来观察数据,但是除了密度与pH的分布近似正太分布之外,其余变量都是右偏太,同时还伴有异常值的存在,于是对这些变量进行了对数转换。除了柠檬酸之外,其余变量都在对数转换后近似正太分布。为了弄明白哪些变量影响酒的品质,从单变量探索中得出的初步结论是硫酸盐,氯化物,柠檬酸,酒精,挥发性酸可能对酒品质有影响。
双变量探索:在这个阶段,通过矩阵散点图生成的散点图及变量对的相关系数,最终确定出对酒品质影响最大的变量是挥发性酸和酒精。挥发性酸与质量呈负相关性,酒精与质量呈正相关性。令人吃惊的是,硫酸盐,氯化物,柠檬酸与质量的相关性几乎可以忽略。同时也对比较感兴趣的pH和固定酸间的关系进行了探索,发现pH值与挥发性酸呈负相关性。
多变量探索:这时我将变量质量加入到了pH值与挥发性酸的关系中,发现了有趣的现象当pH值小于3大于2.75时,好品质的酒其固定酸要高于低品质的酒,当pH值高于3.5时,高品质酒的固定酸低于低品质酒的固定酸。
####对数据集进行探索分析的过程中让我更进一步的了解了葡萄酒的制作工艺及酒的一些特性。同时也伴有惊喜与意外。

















 1953
1953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









