







记一次spark streaming+kafka 运行时间不稳定调优历程
问题现象
首次使用spark streaming进行流式计算的时候遇到的一个问题,即spark streaming读取kafka消息进行流式计算, 但是在数据量比较大的情况下总会出现一些batch的process time比较长,但是大多数batch能在较短的时间内完成,而且全部的batch运行时间呈两个极端分布,要么很长要么很短。

如上图,运行时间曲线出现多处尖峰,而我们期望的一般是连续平滑的曲线。
先说明题主这边的运行环境状况:集群搭建是基于HDP2.6.3版本,其中spark版本是2.11, kafka版本是0.10,其中spark、kafka、HDFS共享集群资源,业务诉求是每5分钟触发一次batch进行统计,需要在5分钟内计算完成,因为从运行图上看卡顿时间大约几十秒,并不会影响最终5分钟内运行完的要求,因此前期阶段只是断断续续在找原因并没有纠缠,但是近期接到项目要求统计1分钟粒度数据,那这个问题就极有可能影响到最后的运行是否按时完成,经过一段颇费周折的排查,终于找到原因,并将过程记录下来希望帮到遇到类似问题的同学。
排障调优历程
1. 单机差异排查
通过streaming的web可看到运行的每个批的详细信息,我们注意到在运行时间上的批次里,基本都是少部分任务时间很长,大多数task还是很快的
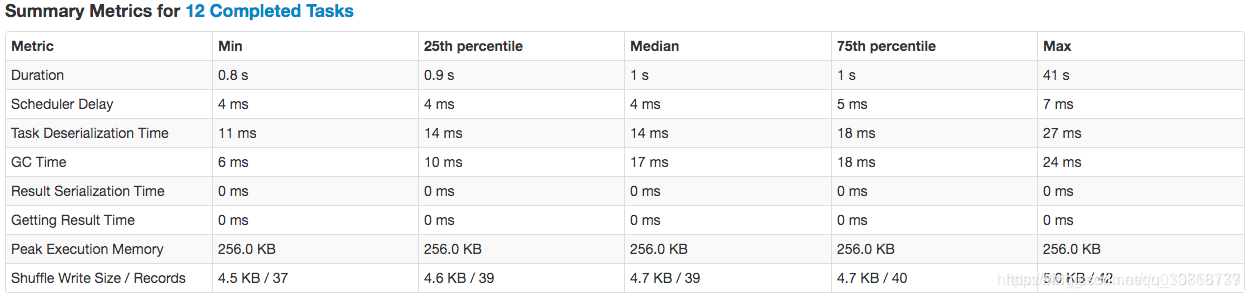
可以看到75%的task在1秒内执行完,但是Max最大的确实41秒,首先猜想的是机器性能差异,但是经过排查集群机器性能并无区别,且每台机器上执行的task比较均衡,基本上排除了单机性能差异问题,且在耗时较长的批次中,可以发现耗时长的task每次回出现在不同的机器上,因此也从侧面排除了机器性能差异问题。
2. 网络因素排查
那么会不会是spark读取kafka网络问题呢
从这张图可以看到,读取kafka全部具有数据本地性PROCESS_LOCAL,且集群内网万兆口互联,网络不应该成为瓶颈。
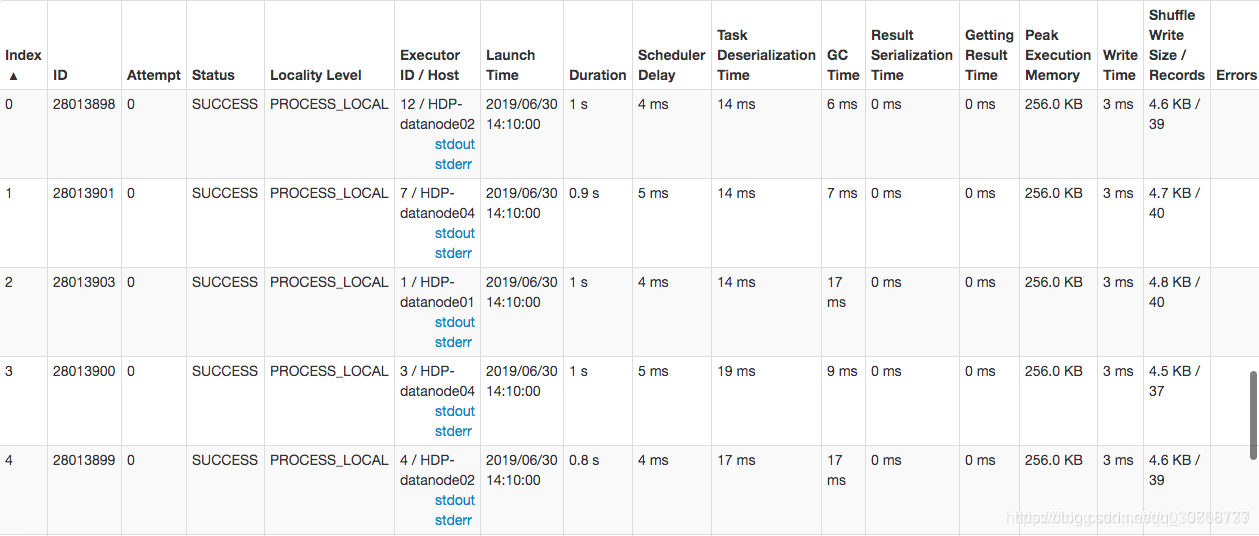
且从这张图中可以排除数据量差异的原因以及GC耗时的原因。
数据倾斜加盐排查
既然数据量差异不是很大,接着对数据特征进行了筛查,通过最终打印多个批次的不同的key的数据量,我们发现并不存在时间长的批次里某些key的数据量突然增大的情况,且最后对数据量的较大的几个key加随机数分散处理,还是未能解决问题,也应证了不是数据倾斜的问题。
单次消费数据量会话超时消费速率排查
接着对kafka消费参数进行调节,主要有以下这么几个
加大session.timeout.ms、减小max.poll.records,延长会话超时时间,减少每次从kafka拉取的数据量,参数经过多次调整,未解决问题。
3. 集群重建问题复现排查
后面题主怀疑过是集群的问题,在今年3月份有了一批压测机器,我们在全新的环境照着之前的模式再搭了一套HDP集群起来,但是发现还是有同样的问题,真是令人沮丧,一度换衣是spark的bug了。
kafka读取超时压缩排查
后面再询问多为大数据圈内好友的经历后,建议修改了一个参数spark.streaming.kafka.consumer.poll.ms,默认512 将这个参数值改为了1000ms,神奇的现象出现了
有两点,第一,耗时长的批次的process time不会“那么长”了,只比正常运行的batch多了3秒,第二,多了3秒的批次日志会报如下异常
20/06/18 16:48:16 WARN TaskSetManager: Lost task 9.1 in stage 103632.0 (TID 621842, 172.16.0.44): java.lang.AssertionError: assertion failed: Failed to get records for spark-executor-user-dinc global-biz-log 3 808993488 after polling for 512
at scala.Predef$.assert(Predef.scala:170)
at org.apache.spark.streaming.kafka010.CachedKafkaConsumer.get(CachedKafkaConsumer.scala:74)
at org.apache.spark.streaming.kafka010.KafkaRDD$KafkaRDDIterator.next(KafkaRDD.scala:227)
at org.apache.spark.streaming.kafka010.KafkaRDD$KafkaRDDIterator.next(KafkaRDD.scala:193)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:409)
at scala.collection.Iterator$$anon$13.hasNext(Iterator.scala:462)
at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:192)
at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:63)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:79)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:47)
at org.apache.spark.scheduler.Task.run(Task.scala:86)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:274)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
很明显,大致意思是5000ms内未从kafka中获取到任何数据信息,接下来会进行重试,原因找到了,之前未获取到消息会一直阻塞到大约延迟40秒拿到消息运行成功,现在是5秒内拿不到消息就重试,不长时间等待。
解决方案
我们可以先修改两个参数临时解决这个问题,第一,减小spark.streaming.kafka.consumer.poll.ms参数到1000ms以内,即1秒超时就重试,第二,将spark.task.maxFailures改为10,默认值是4,加大重试次数,修改完这两个参数后基本上解决了这个问题,多数批次在阻塞重连后都能很快读到消息并运行成功。但这只是临时解决方案,kafka集群不稳定是最根本的原因,最后我们还是建议将kafka集群和计算、存储集群分开部署,减少CPU、IO密集对消息队列带来的不稳定影响。
原文链接:https://blog.youkuaiyun.com/u013716179/article/details/94330478

















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









