



 本文深入探讨程序员的修炼之路,涵盖了Tomcat启动流程、Netty、Spring框架的设计模式,如责任链模式,以及JVM的运行数据区、垃圾回收和类加载过程。此外,文章还讨论了数据结构、算法、Go、Python和Java等语言,以及Zookeeper、ES集群、RabbitMQ和Kafka等组件。在存储方面,涉及了Redis、MongoDB和MySQL的事务隔离级别、索引等。最后,文章介绍了Spring全家桶、Docker和Kubernetes等DevOps相关技术。
本文深入探讨程序员的修炼之路,涵盖了Tomcat启动流程、Netty、Spring框架的设计模式,如责任链模式,以及JVM的运行数据区、垃圾回收和类加载过程。此外,文章还讨论了数据结构、算法、Go、Python和Java等语言,以及Zookeeper、ES集群、RabbitMQ和Kafka等组件。在存储方面,涉及了Redis、MongoDB和MySQL的事务隔离级别、索引等。最后,文章介绍了Spring全家桶、Docker和Kubernetes等DevOps相关技术。
每天120分钟
源码篇
tomcat
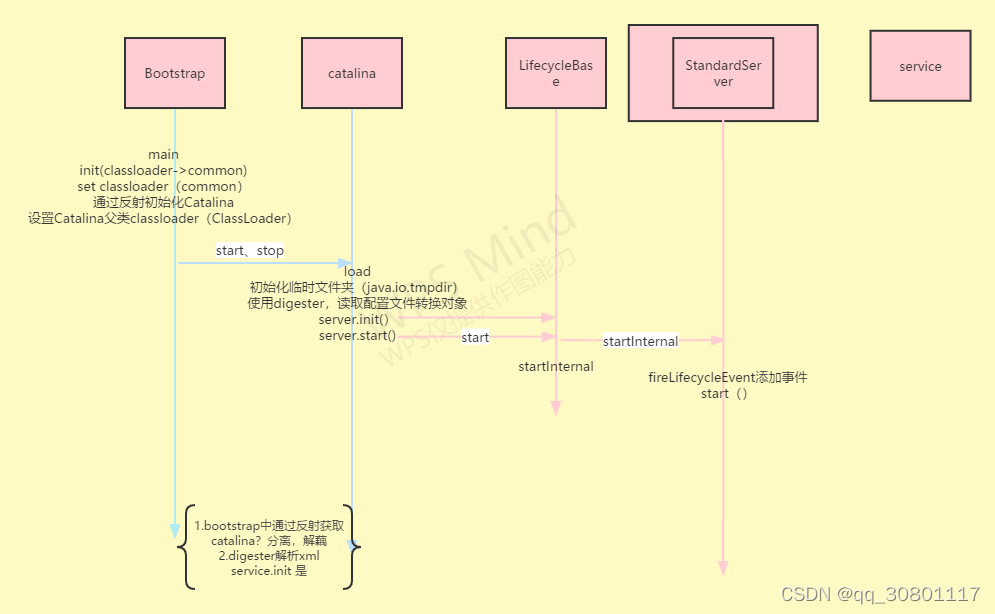
tomcat启动流程
netty
spring
spring容器启动流程
AbstractApplicationContext.refresh() 主要流程集中在refresh方法中,涵盖了spring容器的启动的大部分工作
1. 为刷新准备;修改状态,加载配置数据,验证配置数据, 加载ApplicationListeners和ApplicationEvents 事件
// Prepare this context for refreshing.
prepareRefresh();
1. 1 刷新方法
protected void prepareRefresh() {
// Switch to active. 1.1.1修改状态
this.startupDate = System.currentTimeMillis();
this.closed.set(false);
this.active.set(true);
// Initialize any placeholder property sources in the context environment. 1.1.2 加载配置数据
initPropertySources();
// Validate that all properties marked as required are resolvable: 1.1.3 验证配置数据
// see ConfigurablePropertyResolver#setRequiredProperties
getEnvironment().validateRequiredProperties();
// Store pre-refresh ApplicationListeners... 1.1.4 加载刷新前 ApplicationListeners 监听器
if (this.earlyApplicationListeners == null) {
this.earlyApplicationListeners = new LinkedHashSet<>(this.applicationListeners);
}
else {
// Reset local application listeners to pre-refresh state.
this.applicationListeners.clear();
this.applicationListeners.addAll(this.earlyApplicationListeners);
}
// Allow for the collection of early ApplicationEvents, 1.1.5 加载发布事件,收集事件
// to be published once the multicaster is available...
this.earlyApplicationEvents = new LinkedHashSet<>();
}
1. 2 刷新方法
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
设计模式
责任链模式
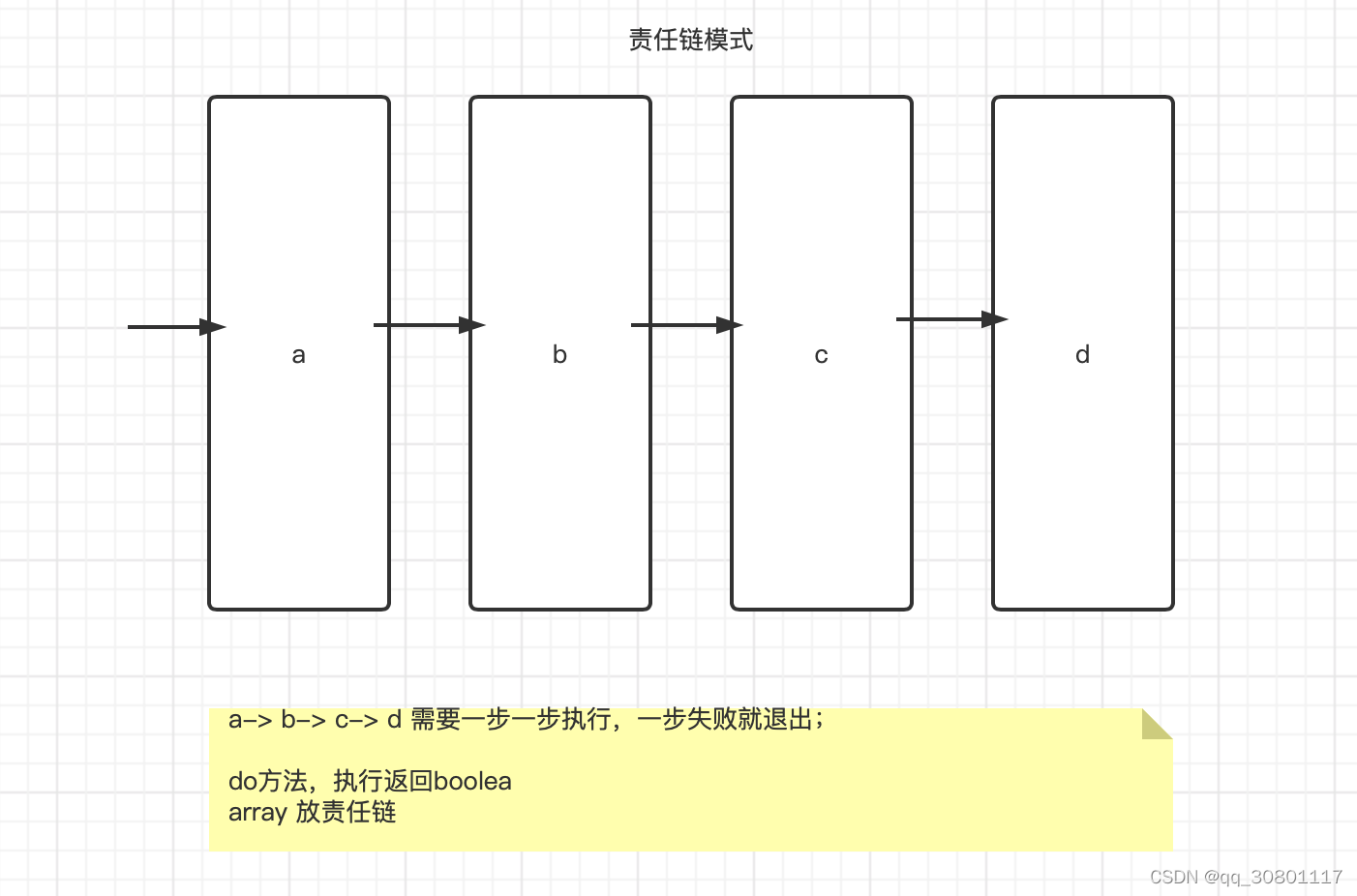
List<Filter> array = new ArrayList();
public viod add(Filter filter){
array.add(filter);
}
public boolean doFilter(){
for(Filter f : array)
if(!f.do())
return false;
return true
}
jvm
jvm 运行数据区

- 栈
- 在程序运行时,每个线程独有的,代码编辑之后,内存大小确定。包含虚拟机栈,和native栈;虚拟机栈包含操作栈、局部变量表、其他的栈信息;
1.1 操作栈是指程序执行时,入栈和出栈的过程;
1.2 局部变量表,在程序执行时,放一些临时值; - 在运行时,如果栈的深度太深,可能会出现stackOver…,,当栈数据量太大会出现outOfMe…;
- 通过设置-Xss 设置栈的最大内存;
- 在程序运行时,每个线程独有的,代码编辑之后,内存大小确定。包含虚拟机栈,和native栈;虚拟机栈包含操作栈、局部变量表、其他的栈信息;
- . 堆
- 线程共享的,包含java Head 和方法区
1.1. java head 存放一些对象信息,采用分代机制对对象管理,gc 会对这个区域进行回收;
1.2. 方法区存放对象信息,包含常量池,常量池会存放一些常量和字面量;也可以配资后方法区的内存大小-XXper…g设置最大的内存,如果不设置,默认为-Xmx的值; - 使用-Xms和-Xmx 设置堆内存的大小
- 线程共享的,包含java Head 和方法区
- . 计数器(pc计数器)
- 在当前线程运行时,计数器记录当前代码执行的行;
类加载过程

- 加载 使用类加载去加载二进制文件,把class加载到方法区
- 连接 分为验证、准备、解析
– 验证 二进制文件是否合法
– 准备 赋值为系统默认值
–解析 把常量引用修改为常量 - 使用
- gc
类加载器

- 双亲委派,自下而上,和自上而下,把需要的类加载一次,下次不用重新加载;要想打破双亲委派,重写classLoad方法。
- 安全。从Luacher中看到源码。
Java 堆模型

- 创建的对象首先进入eden 区,在创新对象时,当eden 内存不足时,yong gc 触发,之后把存活的对象放到from区,清除垃圾,当下次在触发yong gc 时,把from中的对象放到to中,并把eden的也放到to,清除from内存,下次再to-> from,在移动对象是,对象生命+1,知道达到一定指,对象还存活,把对象移动到老年代中;
- 老年代进行采用fullgc ,内存比较大,耗时比较长,尽量减少fullgc 的频率;老年代内存大小也不能设置太大;
- 如果首次创建的对象比较大,直接分配到老年代。
垃圾回收器

回收算法
- 标记清除
- 标记整理
- 复制算法
算法篇
数据结构
数组
动态数组
有最大长度MaxLength,和最大值MaxValue生成一个随机长度和随机值的数组;
public int[] arr(int maxLength,int maxValue)
{
int [] arr = new int [(int) Math.random()*MaxLength+1];
for(int i=0; i< arr.length ;i++)
{
arr[i] = (int) Math.random()*MaxValue+1;
}
}
链表
链表反转输出
哈希
hashMap 中的范型如果是基本类型和String,是值传递;是非基本类型则是引用传递。
队列
使用队列转栈结构数据
栈
使用栈改成成队列结构
树
二叉树
- 排序方式
前序(先序): 子树按照头左右
中序 :所有子树按照左头右
后序:所有子树按照左右头 - 特点
有以上规则可以推出先序的第一个节点为首节点;中序排出的结果中首几点左边为左子树,首节点右边的为右子树;
算法
冒泡
冒泡算法流程
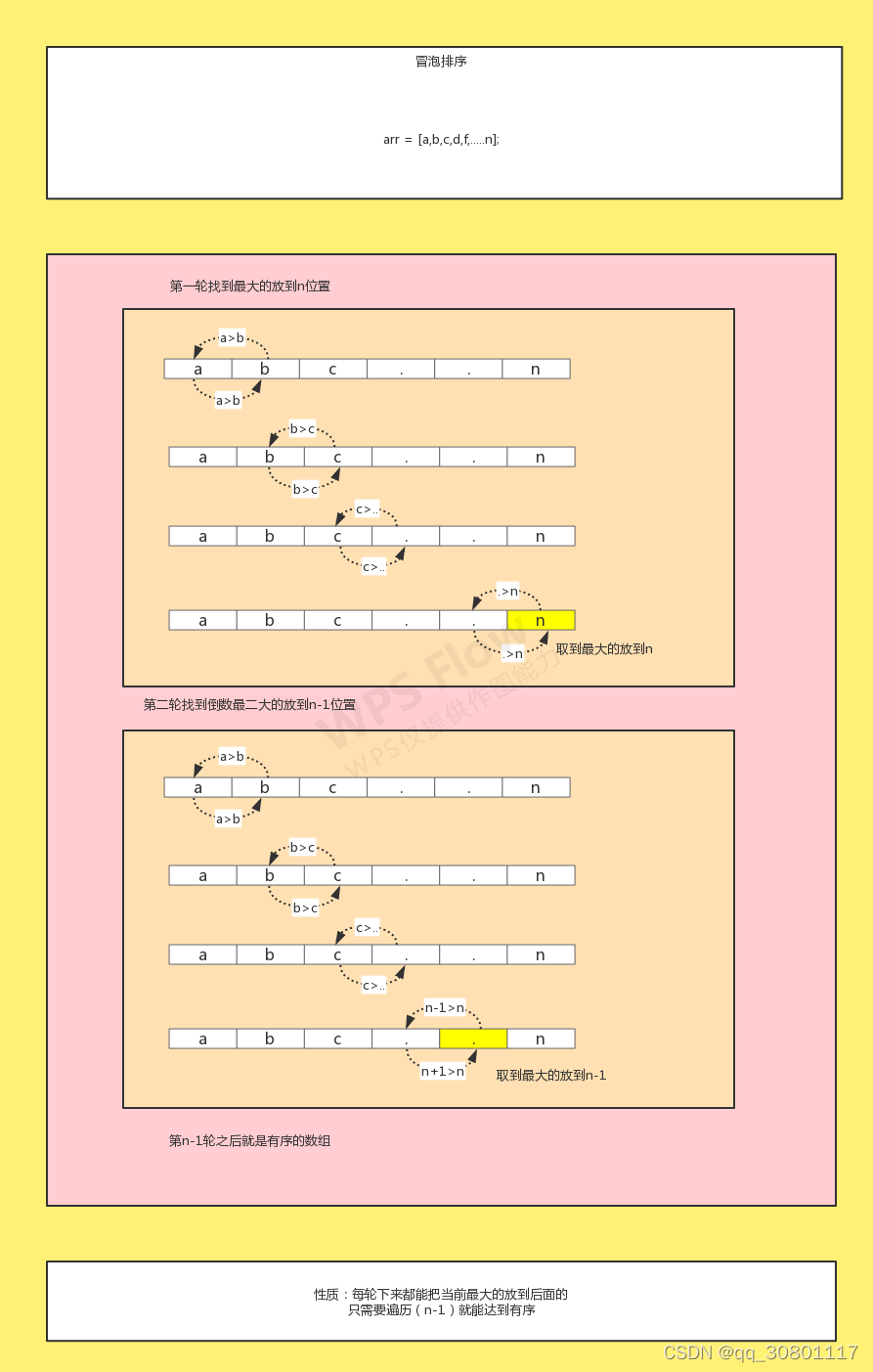
冒泡算法code
// 此代码为伪代码,主要是逻辑
// (n-1)轮就能变成有序
for(int i=0;i<array.lenth-1;i++)
{
// 比较(n-1)就能找到每轮最大的
for(int j=i+1;j<array.lenth-i;j++)
{
if(a[j-1] >a[j]){
// 位置交换
swap(a[i],a[j])
}
}
插入算法
-
插入排序算法流程
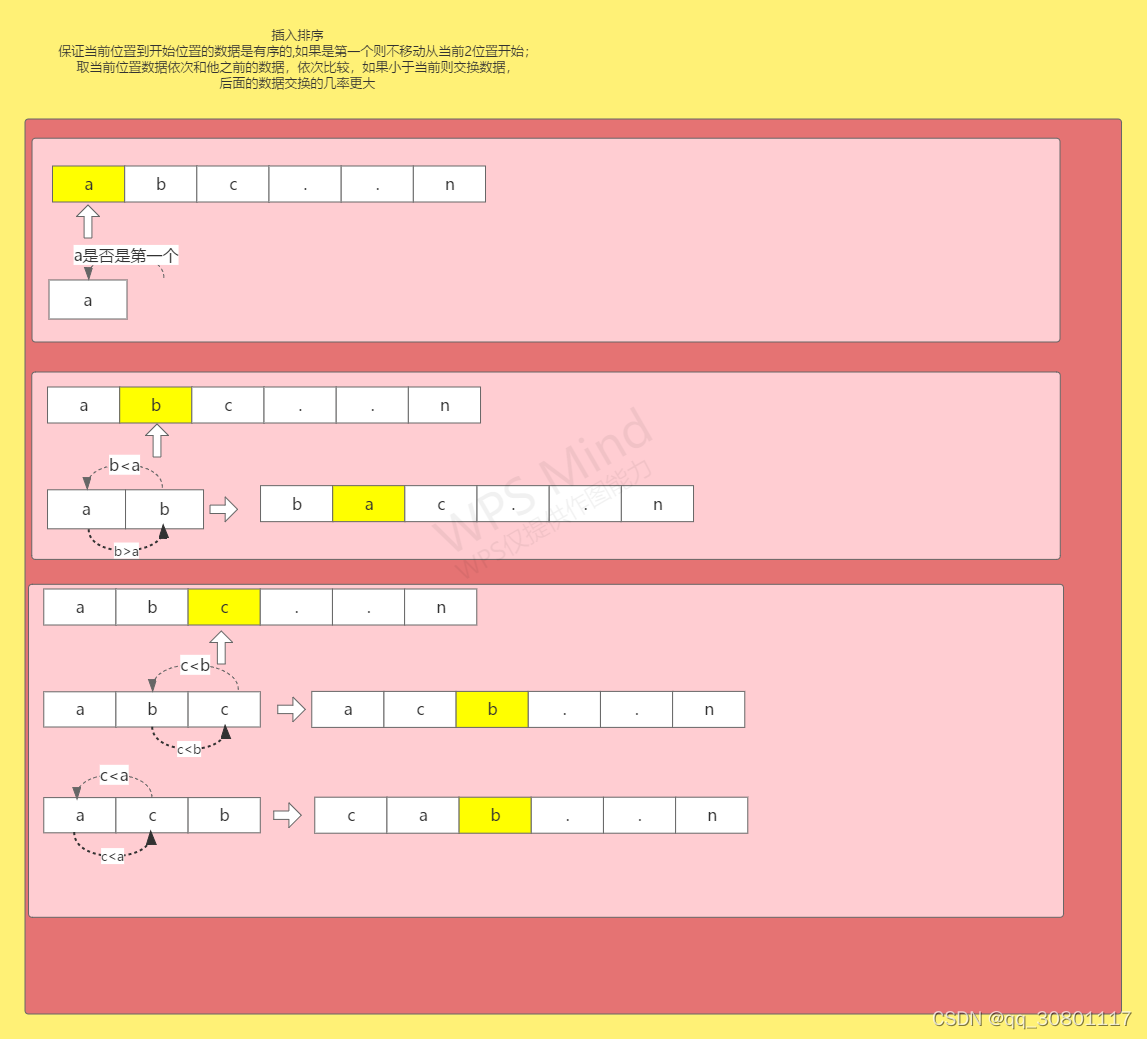
-
插入排序算法code
//从第二数据开始,如果数组只有一个直接返回
if(array.lenth==1){
return ;
}
for(int i=1;i<array.lenth;i++)
{
// 依次比较前面的数据,如果前面的数据大,则进行交换
for(int j = i ; (j > 0 && array[j] < array[j-1]); j--)
{
// 交换位置
swap(array(j),array(j-1));
}
}
归并排序
-
归并排序流程

-
归并排序code
语言篇
go
- 基础语法
1.defer 只执行到该代码出入栈,在方法执行完之后出栈;
defer
python
java
集合框架
io

- bio
- nio
- aio
多线程 高并发
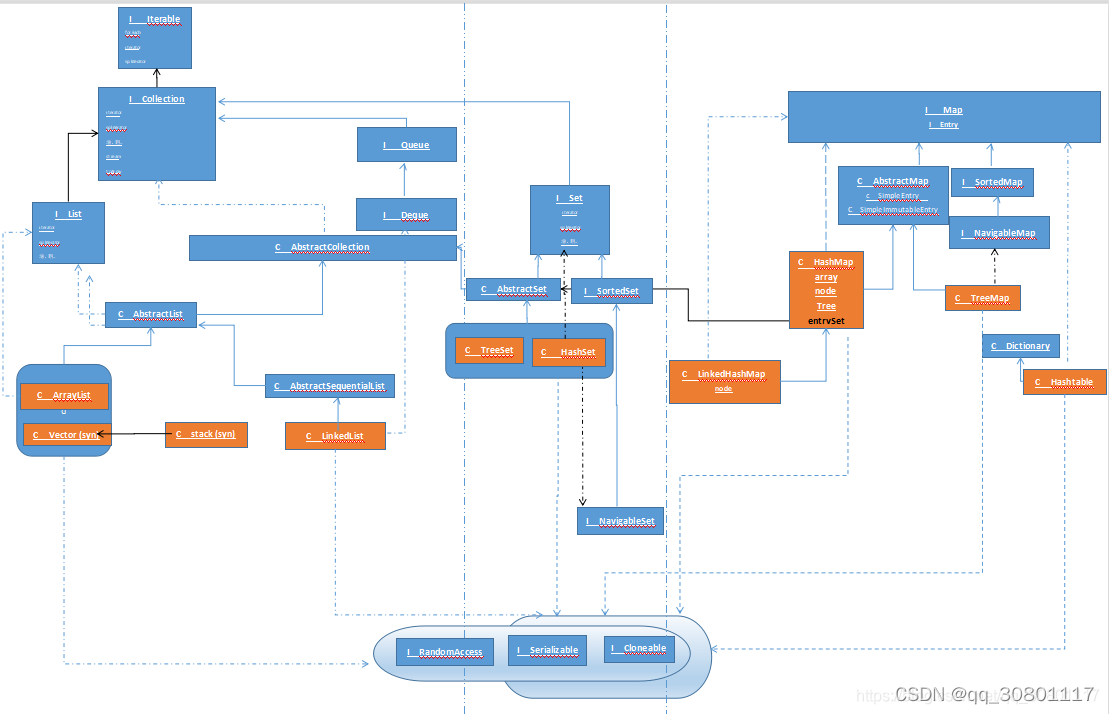
- aqs 属性 (volatile )state ,和头尾 节点队列;
- 公平锁非公平锁 ,公平锁 当前线程队列为空,或者为空队列,cas 修改state 并获取锁
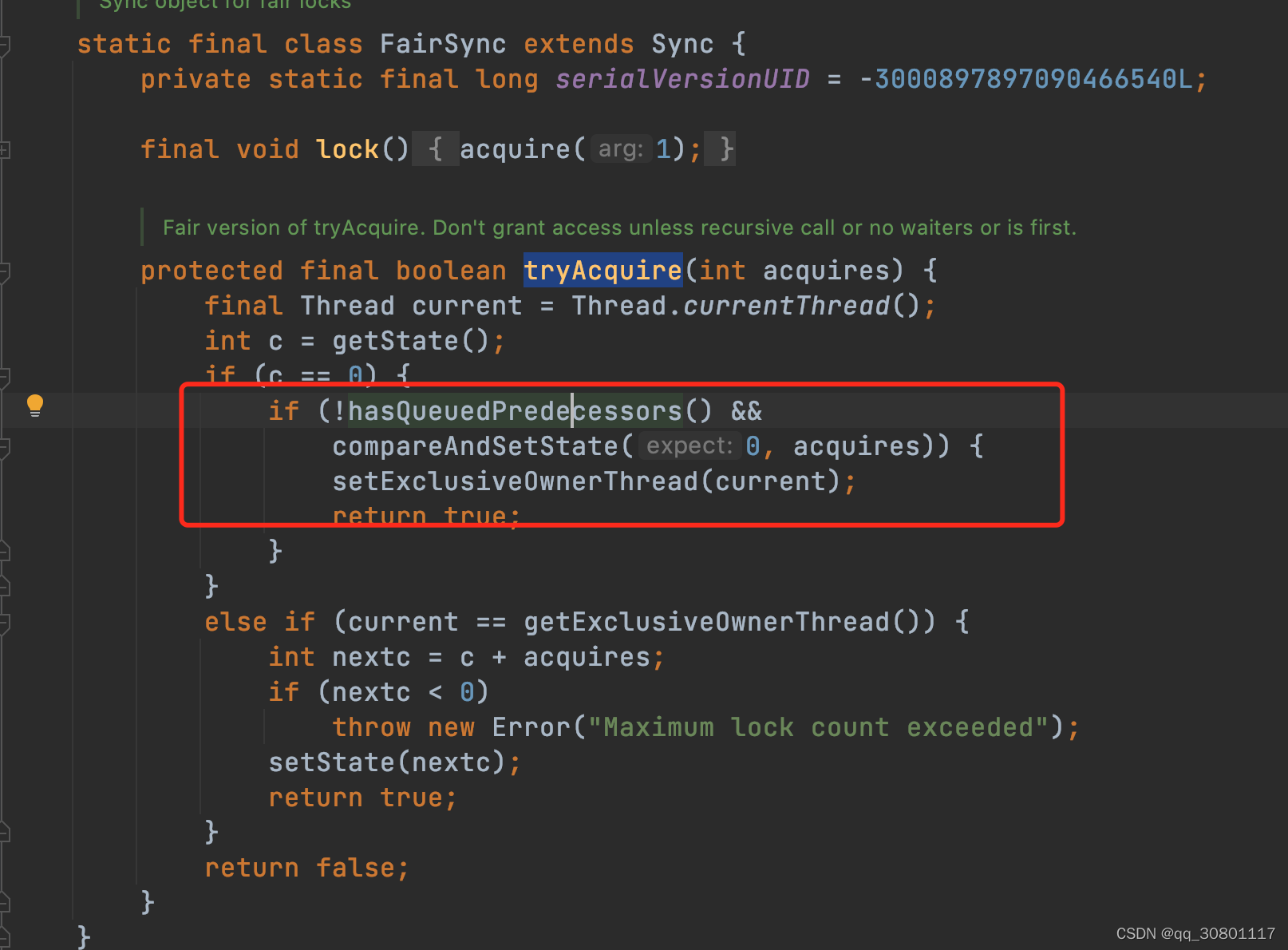
- 非公平锁,cas 修改state 并获取锁。
- Map 结构 扩容 安全性
- 线程池
ExcutorsService.new***ThreadPool(
coreSize,//核心线程数
maxThreadSize,//最大线程数
3,// 多长时间内没有执行的任务,回收线程
timeUnit,// 时间单位
workQueue,// 线程队列
ThreadFactory,// 线程工厂
resure //拒绝策略
)
1.当线程数量没有达到核心线程数,直接执行任务;
2.当线程数量超过核心线程数,把任务放到队列中;
3.当线程数量超过核心线程数,队列没有满,且小于线程最大线程数,启动线程
4.当线程数大于线程最大线程数,且队列已满,直接执行拒绝策略; - 异步阻塞
- join
- futureTask、callable
- 异步非阻塞 通过监听器,事件完成通过call 回调达到异步处理的功能
组件篇
zookeeper
官网地址
https://zookeeper.apache.org/doc/r3.7.0/zookeeperOver.html
分布式服务协调解决方案
-
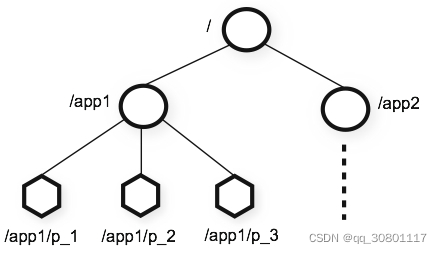
基于内存的,类似目录结构 存储数据;
-
-
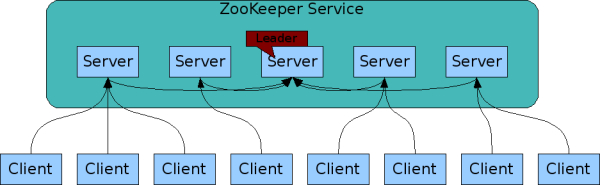
高可用模式 (client >server(fowller)>server(leader)) 服务过半可用
-
-
数据有序(都是通过leader,进行数据读取和同步)
-
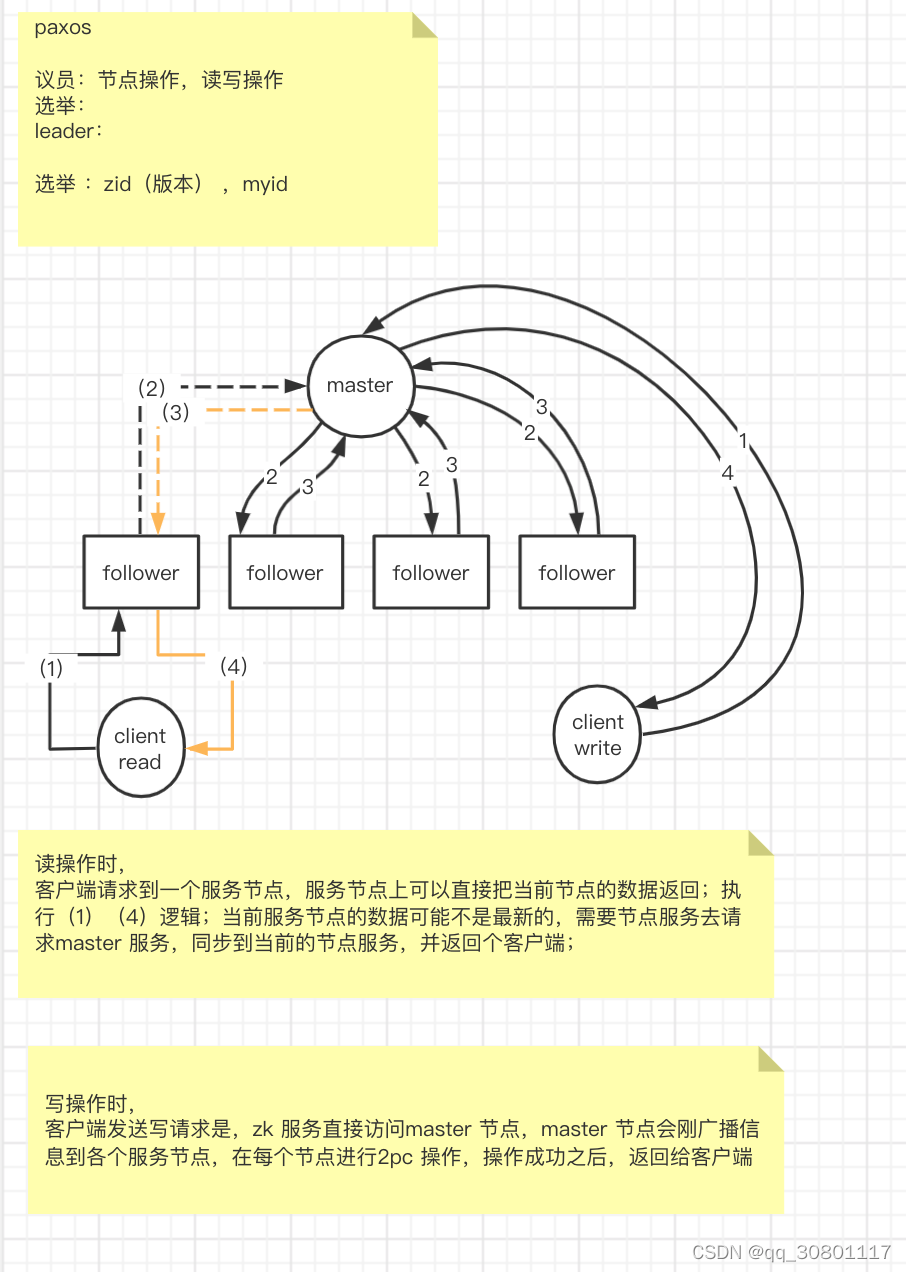
Paxos 算法
ES
倒排索引
倒排结构组成:(图片借鉴)
-
postingList 存入含有字典的id 列表(每一个单词在那个数据中使用)
-
词项索引
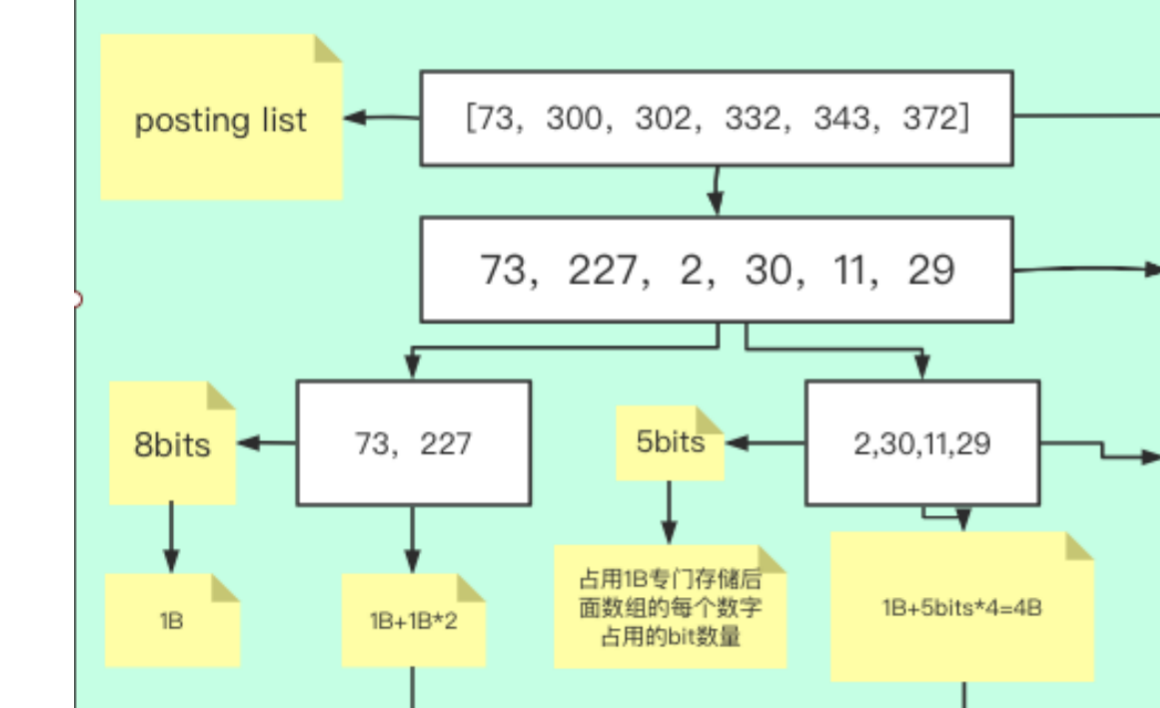
1.2 . postingList 中的压缩算法 for 和rbm
1.2.1 for 适合密集型,差值比较小( 1,2,3,4,)->1,1,1,1
1.2.1.1 会把差值 在进行不同的范围进行分组
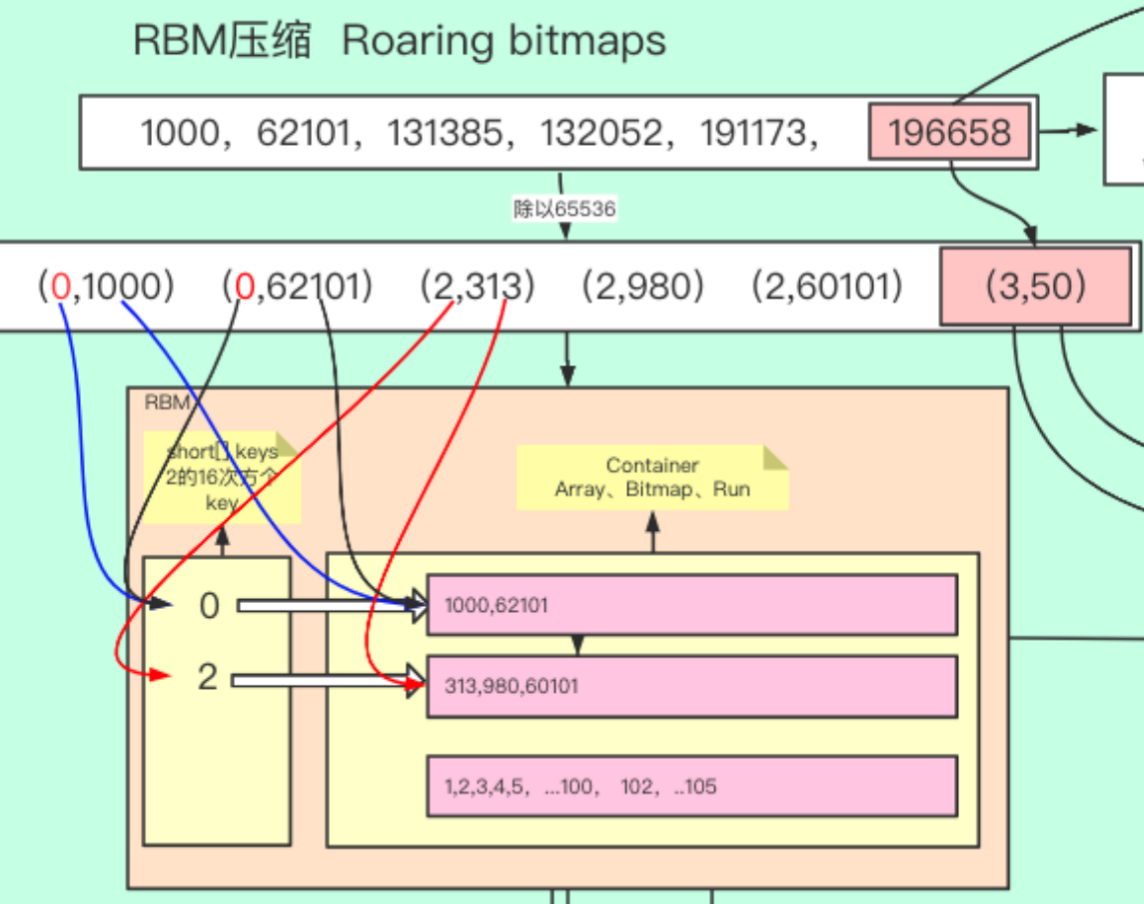
1.2.2 for 适合分霰型数据,会对半取余 2的16 次方
1.2.2.1 取模的正数放在short 数组中,每个数组后面执行一个余数的数组,余数的数组是一个containar;containar有arraycontainar 数组,bitcontainar 位图 2的16 次方个bit 位 ,,Runcontainar 连续数组直接用起始值和结束值表示[1,2,3,4,5]->[1,5];
-
分次器分隔的词项为字典项;(每一个单词)
2.1 前缀树结构 (对于某些前面重复的单词可以服用)
hello Marry
hello Word -
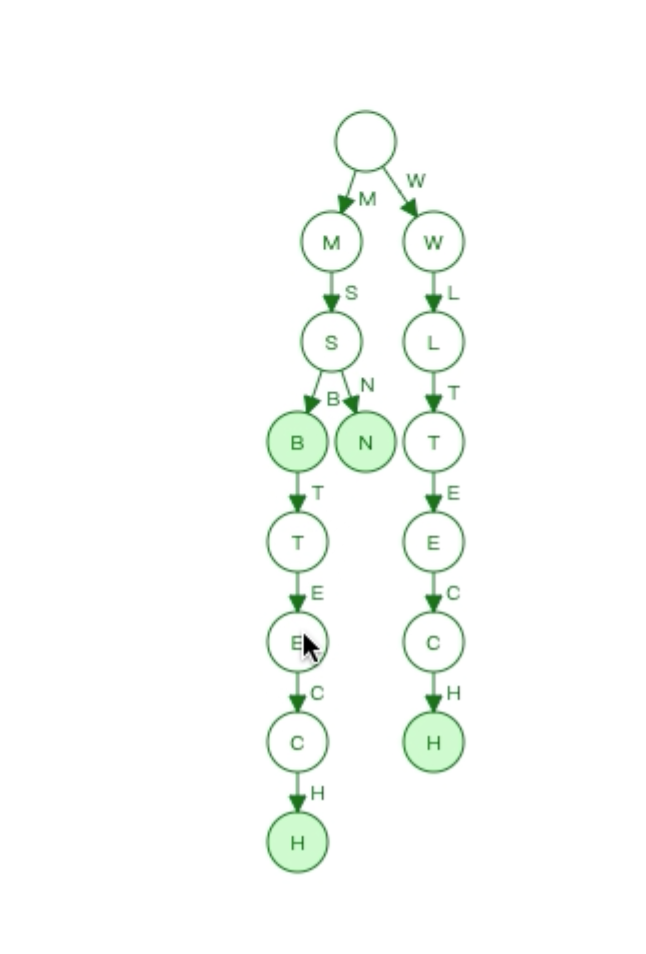
2.2 对于前缀树结构职能服用前面的,后面重复的无法复用 mfa
hello Marry
hello Word
mft
6. 分词字典列表postingList压缩算法,for、 rbm
7.
分片
-
创建一个索引会创建1个以上的主分片,和1个以上的副本分片。
-
分片感知策略 ,当某一个节点宕机,副本分片升级为主分片,在特定时间内,会把宕机的分片分配到新的节点上。
集群
master选举
选举条件
- 候选角色,集群配置文件中新增 node.role=master ,拥有选举权和被选举权
- 投票角色 voting_only = true ,只有选举权
- 选举master脑裂问题,集群中配置minnum.mater = n/2+1
当超过部分的候选节点连接不上master 节点时,就认为master节点宕机;需要选举master节点
选举过程
- 从当前节点获取集群中所有的节点,并找到候选节点。
- 从候选列表中选择一个集群状态版本最大的一个,如果集群状态版本相同,选择候选节点id最小的一个。
选举完成
jms
rabbitmq
- 用途
- 解藕
- 跨系统(go 生产,java 消费)
- 流量削锋(数据量大,新增消费者)
- 消息是怎么放松到队列中的
1.exchang 、queue、生产者、消费者
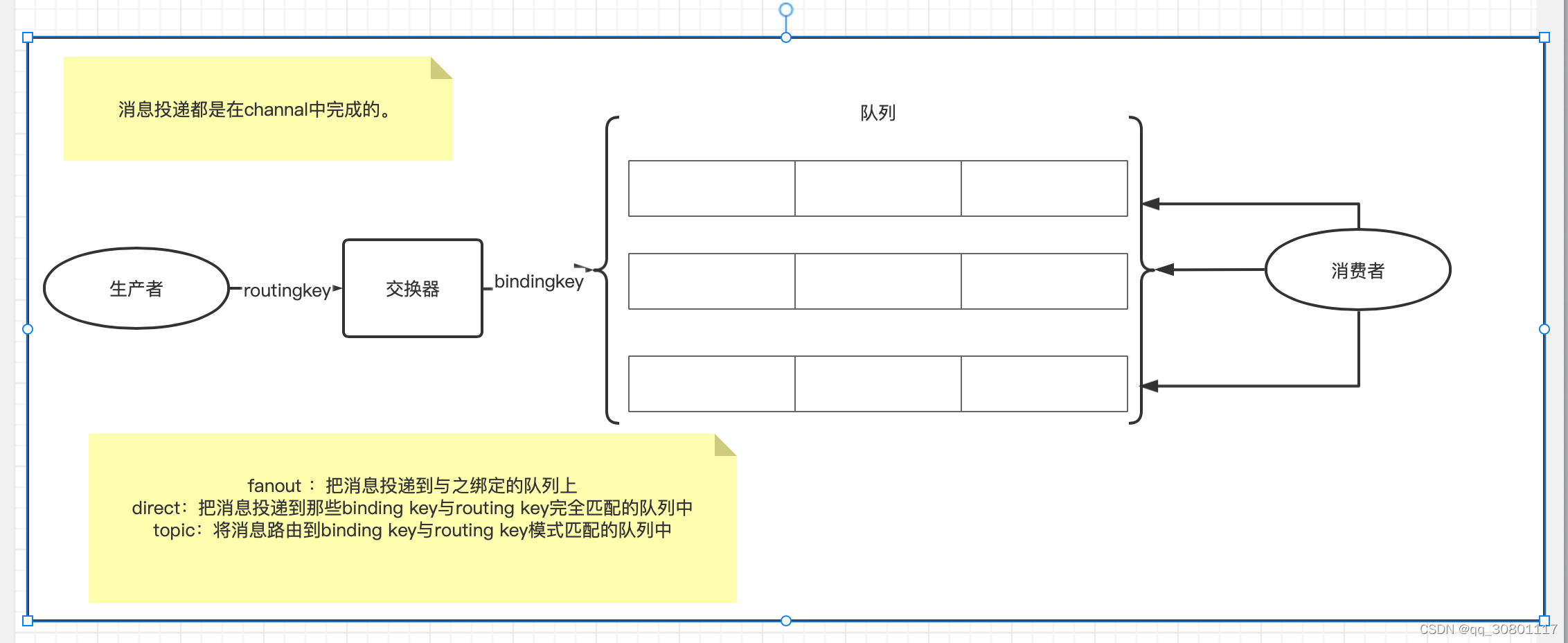
- 防止数据丢失问题
- 生产者
开启消息确认机制 - 消费者
手动ack - 数据持久化
- 集群架构
kafak
flowable
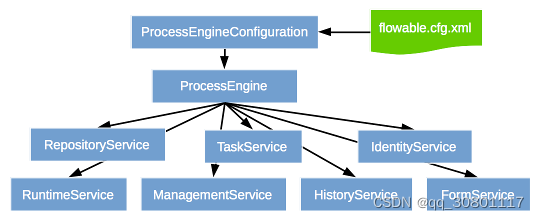
通过配置xml,配置置参数,保存xml模型,生成发布模型,获取到实例id,通过实例id开始任务,在执行任务前,先预判下一个节点,并传入下一节点需要的数据;
- 引擎
- RepositoryService
- TaskServic
- IdentityService
- RuntimeService
- ManagementService
- HistoryService
存储篇
非关系型数据
redis
- 数据类型
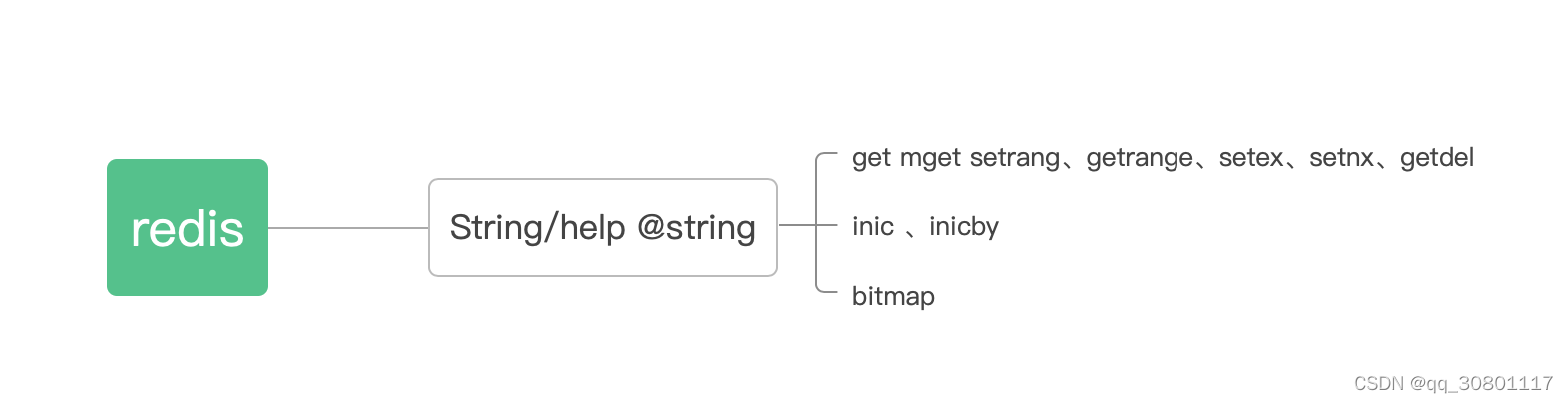
- 分布式锁的实现
- 高可用集群
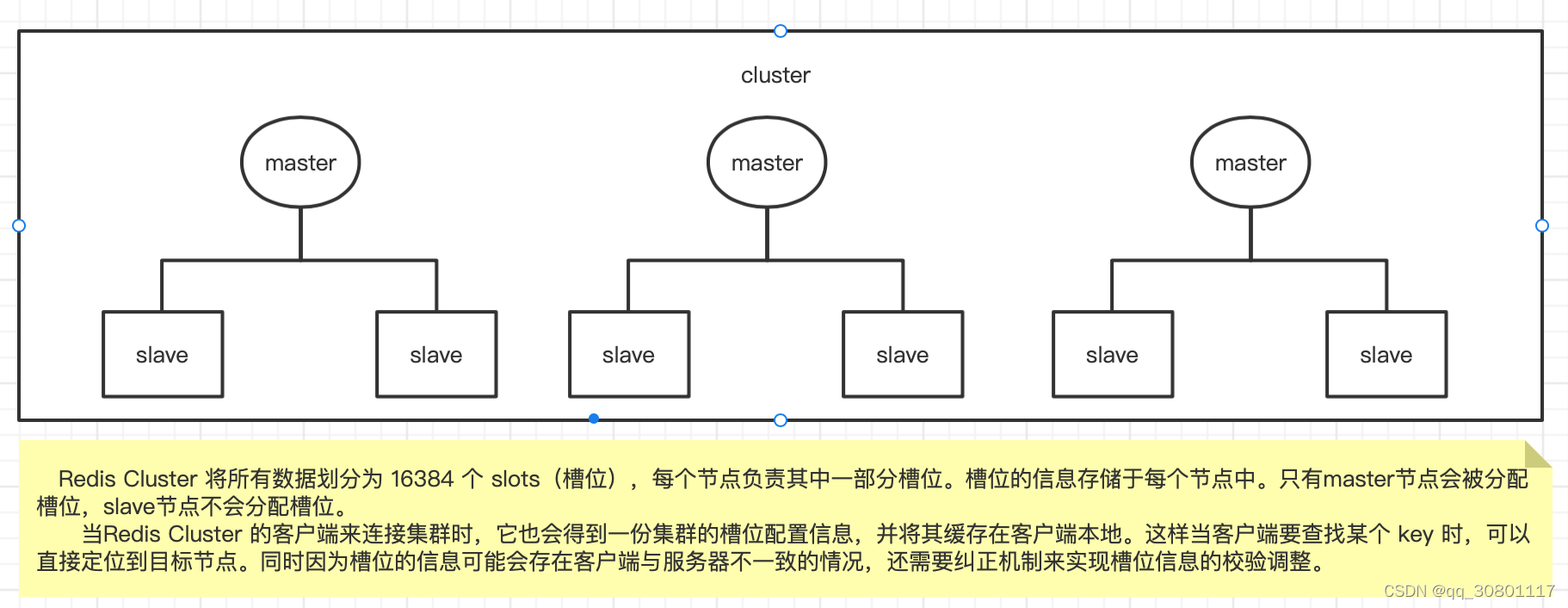
- 代理模式
- 常见问题
- 击穿
- 雪崩
- 数据备份方式
- aof 把写的操作不断追加到日值记录中。特定的时间内进行一次持久化操作。
- rdb 对一次日志进行一次压缩;
Mongodb
- 文档类型
关系型数据库
mysql
事务隔离级别
- uncommit_read
- commit_read review在每次查询就是一个新的read view
- repable_read 不可重复读,read view在第一次查询是就创建,以后查询不在重新创建
- serlized_read
日志
- binlog 追加sql日志,在主从配置时,把master上的binglog发送到节点上,并记录自己的中继日志中。在开启sql线程执行中继日志。
- redolog 两阶段提交保证数据完整性。
- undolog mvcc 版本控制中使用
索引
1.结构
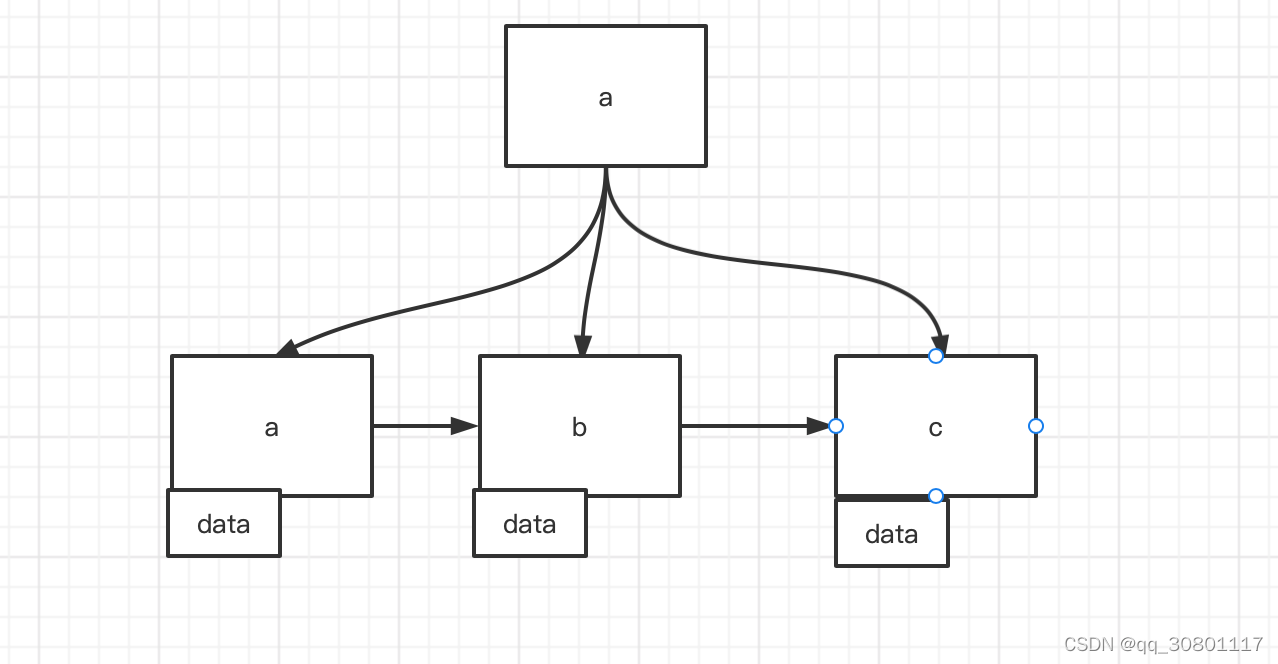
- 最左匹配原则
- 索引长度
- explan 执行计划
- 不能破环索引
- 减少回表操作
锁
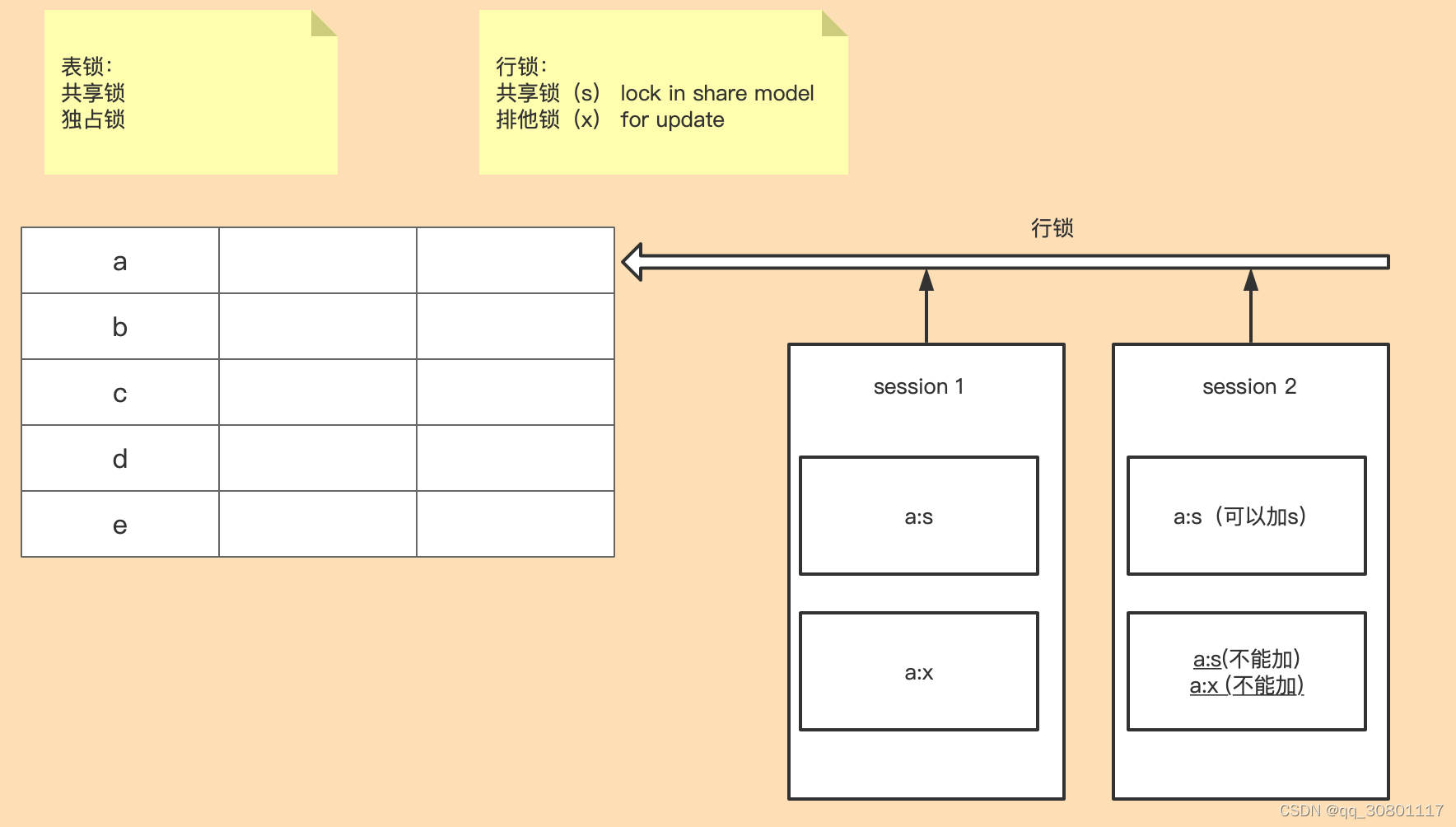
1) 查看当前活跃的连接
SHOW PROCESSLIST
2) 查看锁表信息
SHOW OPEN TABLES where in_use>0
3) 查看当前事务
SELECT * from information_schema.INNODB_TRX;
4)查看当前锁定的事务
SELECT * from information_schema.INNODB_LOCKS;
5)查看当前等锁的事物
SELECT * from information_schema.INNODB_LOCK_WAITS
分片
pation by hash ,list 对上数据进行分片
集群
- 数据库在操作复杂的业务逻辑是,锁操作导致效率不高,采用读写分离模式
- master 日志是追加的; 从节点会有一个线程间隔一段时间想master节点询问,binlog日志是否改变了,如果发生改变了,就请求日志文件到自己的中继日志中。并开启一个sql线程,执行sql;保证数据一直
- 在sql 服务上配置权限和主节点。
框架
Spring
-
Ioc
把管理bean的工作交给容器,有容器来替代之前的人工工作;一种思想,并不是一种技术。
BeanFactory 、ApplacationContext -
DI
依赖注入,把对象中依赖的其他对象,通过set 、注解方式注入到当前对象中。
- 使用spring注解修饰类,都是被spring容器管理,在使用时注入就就能直接使用。
- Aop
- 一种编程思想;不修改代码的前提,对功能进行增强。
切面 : 定义了连接点、增强方法,连接点。
连接点:放在增强的位置;
切点:一组连接点
增强:需要增加的功能,通过before ,after ,exception ,arround
织入:通过切面实现方法增强的整个过程
在运行时动态植入增强方法;
https://editor.youkuaiyun.com/md/?articleId=122171191
- CGLIB是一个强大的高性能的代码生成包。它广泛的被许多AOP的框架使用,例如Spring AOP为他们提供方法的interception(拦截)。CGLIB包的底层是通过使用一个小而快的字节码处理框架ASM,来转换字节码并生成新的类。除了CGLIB包,脚本语言例如Groovy和BeanShell,也是使用ASM来生成java的字节码。当然不鼓励直接使用ASM,因为它要求你必须对JVM内部结构包括class文件的格式和指令集都很熟悉。
- jdk 其实在使用动态代理的时候最最核心的就是Proxy.newProxyInstance(loader, interfaces, h);
- 循环注入问题
- 用到的设计模式
- spring 中bean的生命周期
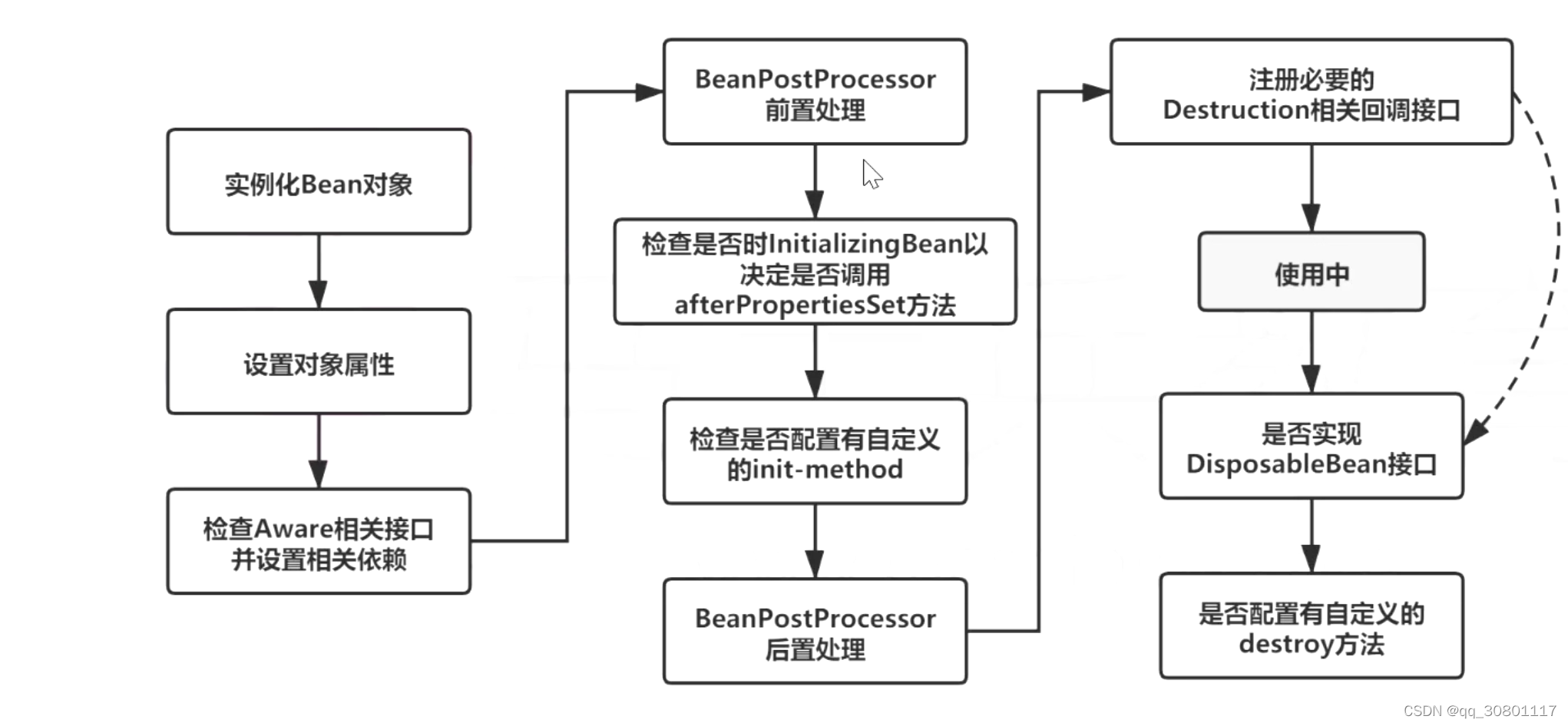
- 初始化bean(使用反射)
- 设置bean属性(循环依赖的问题)
- 调用aware方法设置beanName等属性
- 调用postProcessor前置方法
- 调用init 初始方法
- 调用postProcessor后置方法,(方法增强aop)
- 通过getBean获取对象
- 对象销毁
- 调用自定义的销毁方法
- spring 事务
TransactionDefinitioin: 事务传播机制,事务隔离级别,超时;只读
TransactionManage:获取事务,事务提交;事务回滚;
在spring 中事务采用aop变成思想实现的,使用transtactionInterceper 中的invoke中。
-
- 解析事务信息,是否需要开启事务
-
- 当需要开启事务,关闭自动提交,开启事务
-
- 执行业务逻辑
-
- 如果有异常走异常逻辑关闭事务
-
- 没有异常,执行结束,获取当前连接信息关闭事务
-
声明式事务
-
编程式事务
-
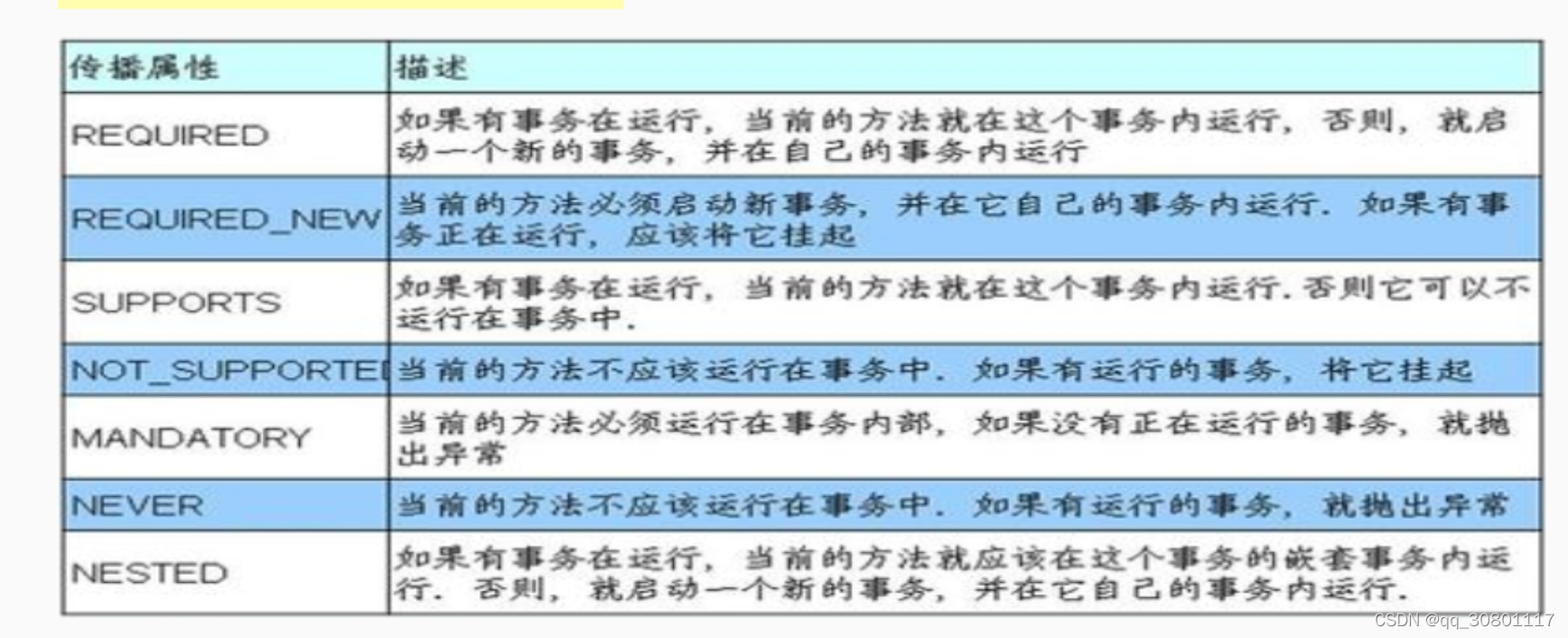
事务传播机制(此处来自连老师辛作品,感谢老师解惑)
springboot
springcloud
eureka
-
向注册中心注册,每30秒完成一次续约;
-
超过90秒续约不成,会从注册列表中移除
-
更新注册信息,并同步注册中心数据到其他claster
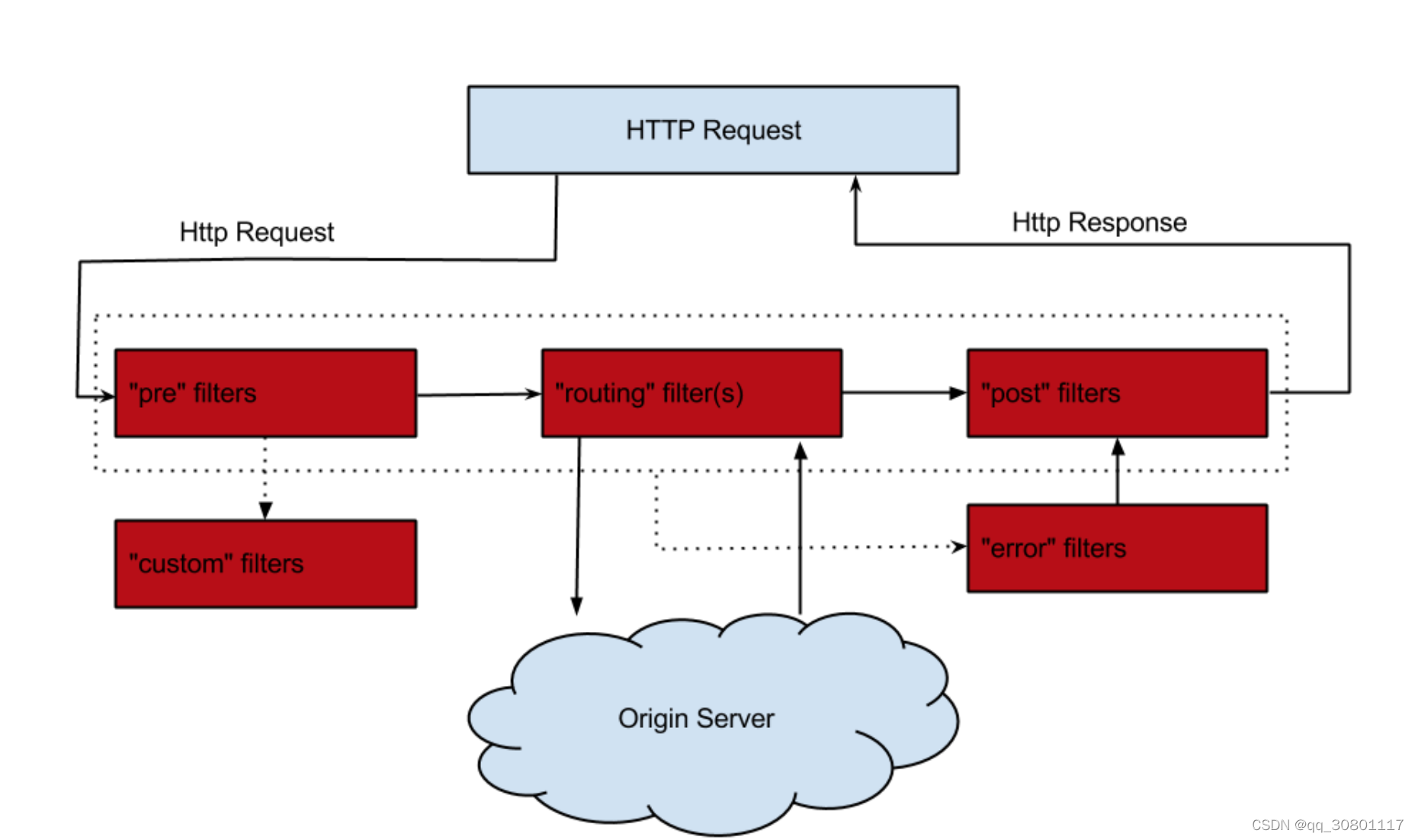
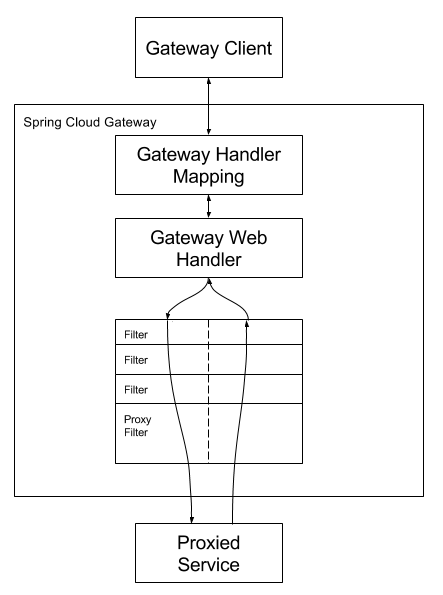
网关
- 鉴权,日志收集、限流、负载、请求转发、保护服务
-
zuul
-
getway
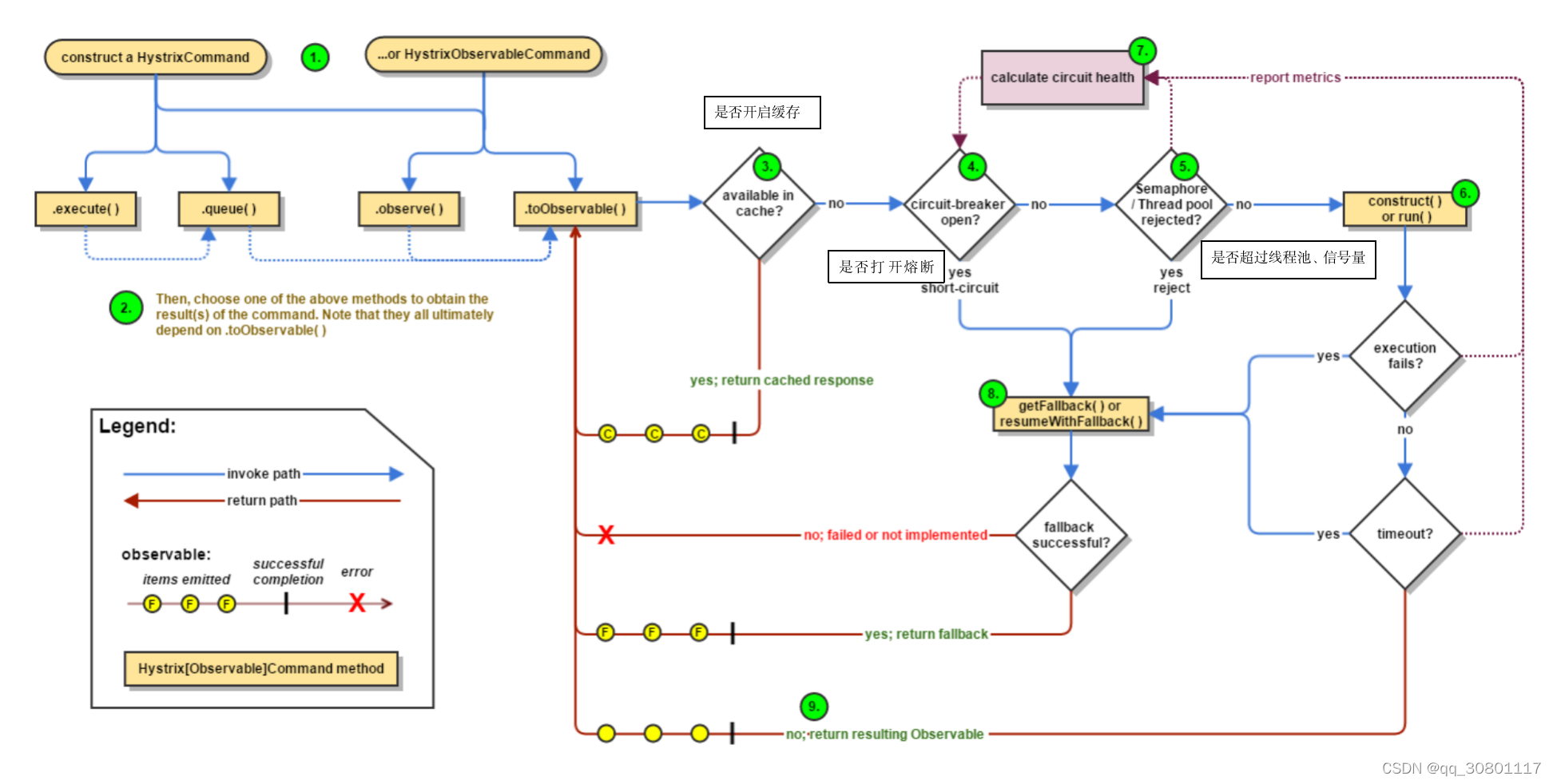
hystrix
feign
Spring Cloud Alibaba
nacos
- nacos
- 服务注册
- 服务发现
- 服务上报
- ap(默认)临时实例, cp模型 持久实例 。不同点,ap 模式下,服务失败则直接移除,如果是cp模式,服务列表不移除
- 服务配置 refreshscope 注解自动刷新配置项;dataId命名规则:服务名-+环境名称.+配置文件后缀。
- 命名空间(配置在bootstra 配置中)、分组(配置在bootstra 配置中)、dataId
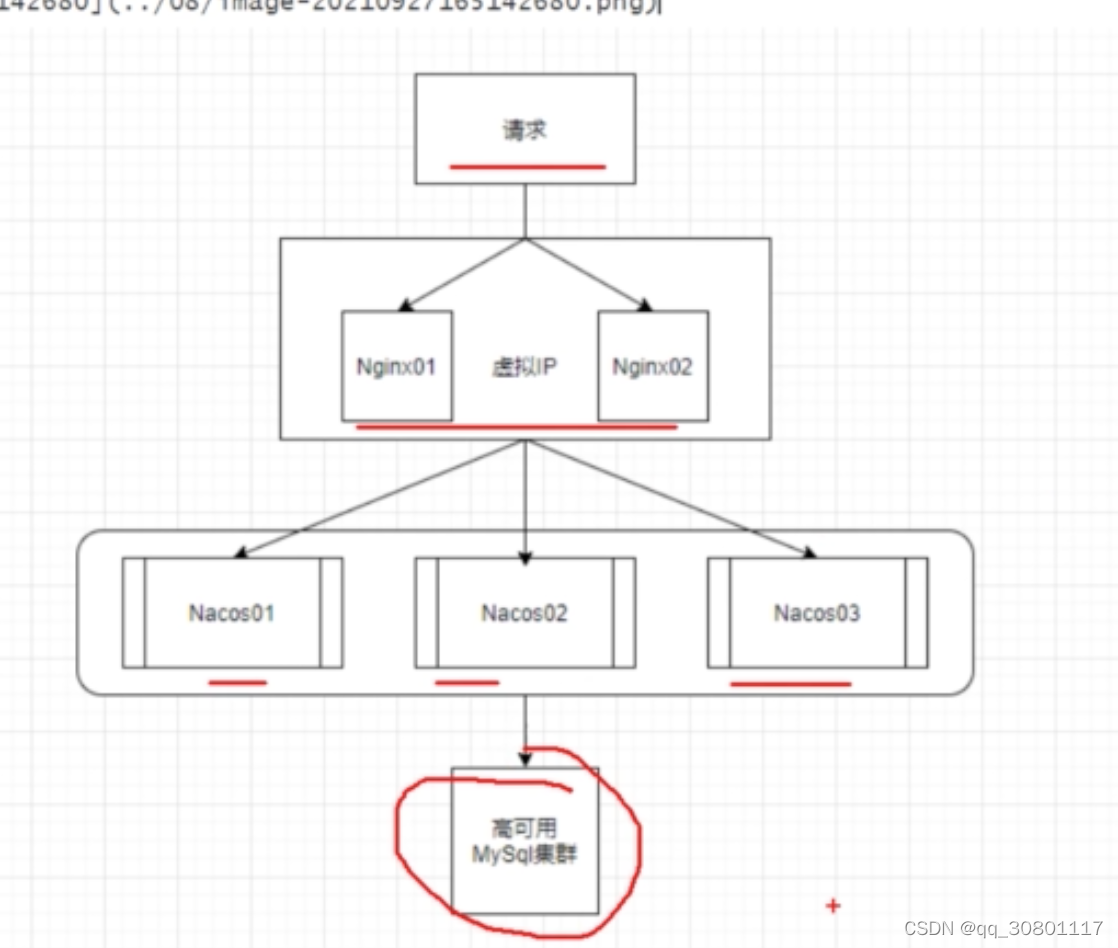
- nacos 集群部署,支持外置数据源目前仅支持mysql
ribbon
RestTemplate.getForObject(url,returnType,params)
- 负载均衡
mybatis
- 一级缓存
- sqlsession 默认开启一级缓存,key-value ,key值是namespce+sqlId…
- 数据被修改之后,就被清除了
- 二级缓存
- 默认关闭,开启全局开关,namescpage 缓存开关,还需要在sql 上加上开启 是key-value, key 为namescpace ,实体必须实例化;
- 三级缓存
- 依赖第三方组建,配置缓存文件

















 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









