






 本文概述了R-CNN家族,包括R-CNN、FastR-CNN、FasterR-CNN和MaskR-CNN,介绍了它们在目标检测中的关键组件如锚框、RoI池化和RoIalign,以及SSD和YOLO等单发多框检测方法。重点强调了这些技术如何通过改进特征提取和区域选择提高精度。
本文概述了R-CNN家族,包括R-CNN、FastR-CNN、FasterR-CNN和MaskR-CNN,介绍了它们在目标检测中的关键组件如锚框、RoI池化和RoIalign,以及SSD和YOLO等单发多框检测方法。重点强调了这些技术如何通过改进特征提取和区域选择提高精度。
R-CNN 区域卷积神经网络
最早也是最有名的一类居于锚框和CNN的目标检测算法
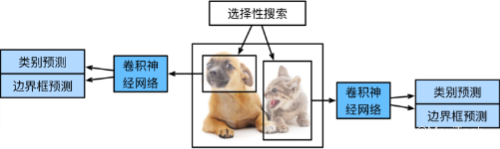
使用启发式搜索算法来选择锚框
使用预训练模型来对每个锚框抽取特征(如VGG)
训练SVM进行分类
训练一个线性回归模型预测边缘框偏移
Fast R-CNN
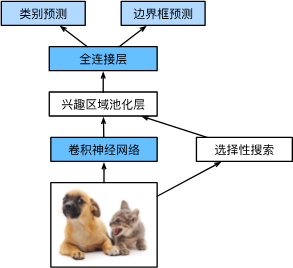
使用CNN对图片抽取特征
使用RoI池化层对每个锚框生成固定长度特征
先抽取特征(RoI Pooling),再从原图上锚框,映射到CNN的输出:(channel, num, mn)
对比于R-CNN的优点就是:只需要使用CNN抽取一次特征然后再选中锚框即可,而R-CNN则需要对于每个锚框都进行一次CNN抽取特征
兴趣区域(RoI)池化层
对于给定的锚框,均匀分割成
n
m
nm
nm块,输出每个块的最大值
不管锚框多大,总是输出
n
m
nm
nm个值
Faster R-CNN
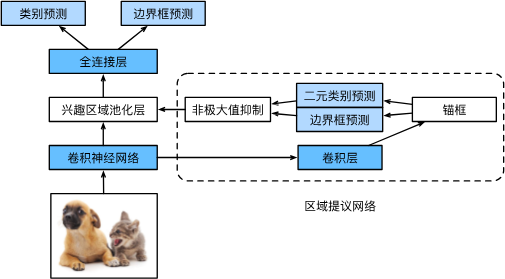
与上面相比,是使用一个神经网络代替选择性搜索的过程(区域提议网络),我认为这个网络的作用就是一个练出来一个比较好的锚框给后面的大网络用(Two Stage)
Mask R-CNN
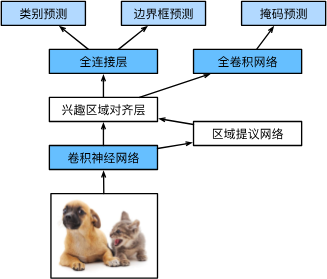
RoI align和RoI Pooling的区别在于,RoI Pooling在切像素的时候有Rounding,而RoI align可以精准切开(用加权)
Faster R-CNN和Mask R-CNN是在最求高精度场景下的常用算法
SSD 单发多框检测
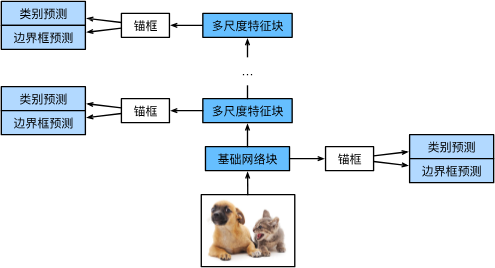
通过但神经网络来检测的模型
生成锚框:对每个像素生成多个以之为中心的锚框(
n
+
m
−
1
n+m-1
n+m−1个)
使用多个分辨率进行检测
YOLO
将图片均匀分成SxS个锚框,每个锚框预测B个边缘框(不会重叠浪费计算量)

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









