







摘要
本文提出了一种多流深度神经网络(MDNN)方法,用于RGB-D第一人称动作识别。该方法通过三个深度卷积神经网络分别提取RGB帧、光流和深度帧的特征,并利用Cauchy估计器和正交性约束来最大化模态间的相关性并保留各模态的独特性。为进一步提升性能,MDNN结合手部线索(MDNN + Hand),通过全卷积网络分割手部区域并融合手部信息。实验在THU-READ、WCVS和GUN-71数据集上进行,结果表明MDNN和MDNN + Hand在动作识别任务中均优于现有方法,验证了多模态融合和手部线索的有效性。
Abstract
This paper proposes a Multi-stream Deep Neural Network (MDNN) method for RGB-D first-person action recognition. The approach uses three deep convolutional neural networks to extract features from RGB frames, optical flow, and depth frames separately. It then employs a Cauchy estimator and orthogonality constraints to maximize cross-modal correlations while preserving the unique characteristics of each modality.To further improve performance, the MDNN + Hand variant integrates hand cues by segmenting hand regions with a fully convolutional network and fusing hand-specific information. Experiments on the THU-READ, WCVS, and GUN-71 datasets show that both MDNN and MDNN + Hand outperform existing methods in action recognition, proving the effectiveness of multi-modal fusion and hand cues.
用于RGB-D自我中心动作识别的多流深度神经网络
Title: Multi-Stream Deep Neural Networks for RGB-D Egocentric Action Recognition
Author: Yansong Tang; Zian Wang; Jiwen Lu; Jianjiang Feng; Jie Zhou
Source: IEEE Transactions on Circuits and Systems for Video Technology ( Volume: 29, Issue: 10, October 2019)
Link: https://ieeexplore.ieee.org/abstract/document/8489917
研究背景
随着可穿戴设备(如GoPro、Google Glass等)的普及,第一人称视角(Egocentric)视频的数量近年来急剧增加。与传统的由静态摄像机被动记录的人类动作视频不同,第一人称视频是由穿戴者在行动时主动生成的,能够提供穿戴者视觉注意力的近距离视角。这种视频在医疗保健、生活记录、虚拟现实和远程康复等领域具有重要的应用价值。然而,第一人称视频的分析面临着许多挑战,例如背景杂乱、摄像机运动剧烈等。此外,RGB视频虽然包含了空间外观和时间信息,但缺乏三维结构信息,且对光照变化敏感。深度(Depth)视频则能够弥补这些不足,提供场景的三维结构信息。因此,结合RGB和深度信息的RGB-D视频在动作识别任务中具有巨大的潜力。

尽管RGB-D动作识别在文献中已被广泛研究,但在第一人称视角下的研究却相对较少。这主要是由于以下几个原因:首先,如何联合利用不同模态并挖掘它们的互补信息是一个难题;其次,第一人称场景中的固有挑战(如背景杂乱和摄像机的大幅度运动)增加了问题的复杂性;最后,公开可用的RGB-D第一人称动作识别数据集稀缺。本文旨在解决这些问题,提出了一种多流深度神经网络(Multi-Stream Deep Neural Networks, MDNN)方法,用于RGB-D第一人称动作识别。
方法论
本文提出了一种多流深度神经网络(MDNN)方法,旨在充分利用RGB-D视频中的空间外观、时间信息和几何结构。具体来说,MDNN通过三个深度卷积神经网络分别学习RGB帧、光流和深度帧的特征。为了在统一的深度架构中保留每个模态的独特性并探索它们的共享信息,MDNN采用了Cauchy估计器来最大化共享组件之间的相关性,并通过正交性约束来确保每个模态的独特性。

上图所示为每个流中提取特征的可视化,一共分为四组,红框中从上往下分别是RGB流、光流流和深度流的图像,对应的右边绿框为卷积神经网络逐步提取的特征。
MDNN的流程主要包括三个步骤:特征提取、多视图学习和分类。在特征提取阶段,MDNN将RGB视频分解为空间和时间组件(即RGB图像和光流),并从深度视频中提取深度帧。然后,使用三个深度卷积神经网络分别学习这些模态的特征。在多视图学习阶段,MDNN通过Cauchy估计器最大化不同模态之间的相关性,并通过正交性约束保留每个模态的独特性。最后,通过加权融合策略将不同模态的特征结合起来,输入到分类层中进行动作类别的预测。
为了进一步提高识别性能,本文还扩展了MDNN,将其与第一人称视频中的手部线索相结合。具体来说,MDNN + Hand方法通过一个全卷积网络(FCN)模型分割RGB帧中的手部区域,并利用分割结果去除背景中的杂乱信息。然后,将处理后的RGB帧输入到另一个卷积神经网络中,计算每个像素的二分类softmax损失。最后,通过加权融合策 略将MDNN和手部模块的分类得分结合起来,得到最终的动作类别预测。
网络结构
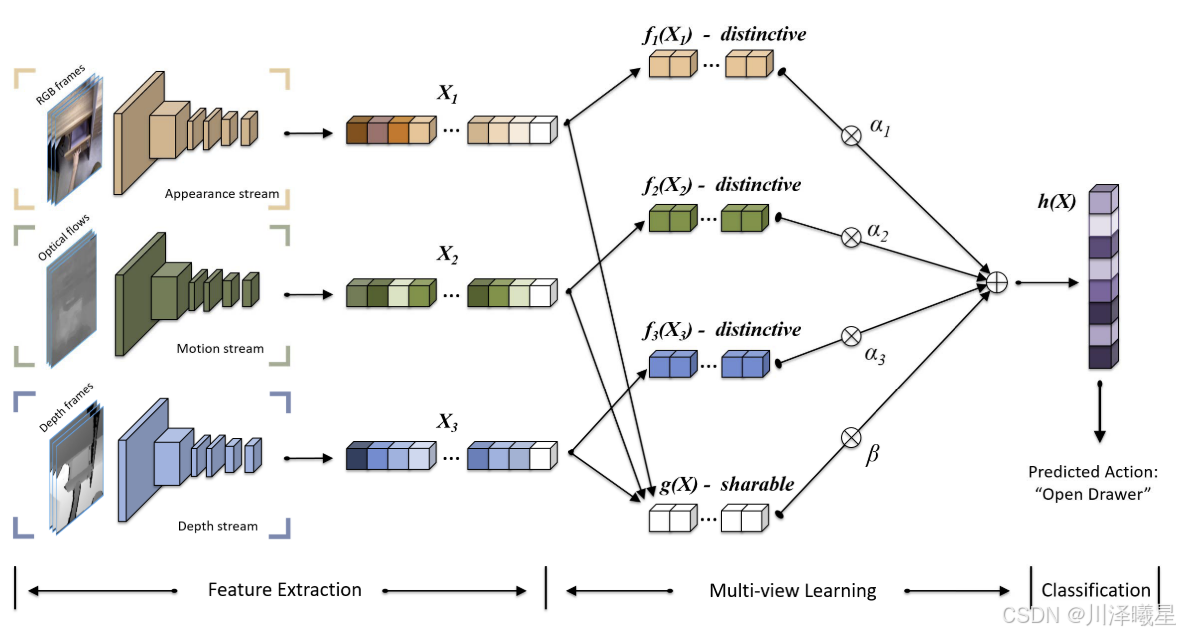
正如上图所示,MDNN的输入包括从RGB-D第一人称视频中提取的RGB帧、光流和深度帧。在特征提取阶段,我们使用三个深度神经网络分别学习空间外观、时间信息和几何属性,并提取每个模态的特征
(
X
1
)
(X_1)
(X1)、
(
X
2
(X_2
(X2) 和
(
X
3
(X_3
(X3)。在多视图学习过程中,我们仔细将学习到的特征分解为四个部分:
(
f
1
(
X
1
)
)
(f_1(X_1))
(f1(X1))、
(
f
2
(
X
2
)
)
(f_2(X_2))
(f2(X2))、
(
f
3
(
X
3
)
)
(f_3(X_3))
(f3(X3)) 和
(
g
(
X
)
)
(g(X))
(g(X)),其中
(
f
1
(
X
1
)
)
(f_1(X_1))
(f1(X1))、
(
f
2
(
X
2
)
)
(f_2(X_2))
(f2(X2)) 和
(
f
3
(
X
3
)
)
(f_3(X_3))
(f3(X3))保留了每个模态的独有特征,而
(
g
(
X
)
)
(g(X))
(g(X)) 包含了它们的共享信息。我们通过分配不同的权重
(
a
1
,
a
2
,
a
3
,
β
)
({a_1, a_2, a_3, \beta })
(a1,a2,a3,β)将这四个部分结合起来。得到融合特征
(
h
(
X
)
)
(h(X))
(h(X)) 后,我们将其传递到最终的分类层,以预测动作标签。
特征提取
特征提取是MDNN方法的第一步,旨在从RGB-D视频中提取出能够有效表示动作的空间外观、时间信息和几何结构的特征。与传统的基于手工特征的方法不同,MDNN直接使用深度卷积神经网络(CNN)从原始数据中学习特征。具体来说,MDNN通过三个独立的流(stream)分别处理RGB帧、光流和深度帧,每个流对应一个深度卷积神经网络。
网络结构:每个流的网络结构基于VGG-16模型,但在最后一层(即分类层)之前移除了softmax层,保留了全连接层(fc7层)的输出作为特征。
特征维度:每个流的特征 X 1 X_1 X1、 X 2 X_2 X2 和 X 3 X_3 X3 的维度均为512维。
时间一致性:为了确保时间一致性,MDNN对每个视频的所有帧提取特征,并在分类阶段对所有帧的特征进行平均,以得到最终的动作类别预测。
import torch
import torch.nn as nn
import torchvision.models as models
# 定义特征提取网络(基于VGG-16)
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
# 加载预训练的VGG-16模型
vgg16 = models.vgg16(pretrained=True)
# 移除最后的分类层(fc8和softmax)
self.features = nn.Sequential(*list(vgg16.children())[:-1]
# 保留fc7层作为特征输出
self.fc7 = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096), # VGG-16的fc6层
nn.ReLU(inplace=True),
nn.Linear(4096, 4096), # VGG-16的fc7层
nn.ReLU(inplace=True),
nn.Linear(4096, 512) # 输出512维特征
)
def forward(self, x):
x = self.features(x) # 提取卷积特征
x = x.view(x.size(0), -1) # 展平特征
x = self.fc7(x) # 通过fc7层
return x
# 定义多流特征提取器
class MultiStreamFeatureExtractor(nn.Module):
def __init__(self):
super(MultiStreamFeatureExtractor, self).__init__()
# 三个独立的特征提取网络
self.appearance_stream = FeatureExtractor() # RGB流
self.motion_stream = FeatureExtractor() # 光流流
self.depth_stream = FeatureExtractor() # 深度流
def forward(self, rgb_frames, optical_flow_frames, depth_frames):
# 提取RGB特征
appearance_features = self.appearance_stream(rgb_frames)
# 提取光流特征
motion_features = self.motion_stream(optical_flow_frames)
# 提取深度特征
depth_features = self.depth_stream(depth_frames)
return appearance_features, motion_features, depth_features
# 数据预处理
def preprocess_data(video_frames):
# 对RGB帧、光流帧和深度帧进行预处理
# 这里假设输入已经是归一化后的张量
rgb_frames = video_frames['rgb'] # 形状: (batch_size, 3, H, W)
optical_flow_frames = video_frames['optical_flow'] # 形状: (batch_size, 2, H, W)
depth_frames = video_frames['depth'] # 形状: (batch_size, 1, H, W)
return rgb_frames, optical_flow_frames, depth_frames
# 主函数
if __name__ == "__main__":
video_frames = {
'rgb': torch.randn(16, 3, 224, 224), # 16个RGB帧,3通道,224x224分辨率
'optical_flow': torch.randn(16, 2, 224, 224), # 16个光流帧,2通道
'depth': torch.randn(16, 1, 224, 224) # 16个深度帧,1通道
}
# 数据预处理
rgb_frames, optical_flow_frames, depth_frames = preprocess_data(video_frames)
# 初始化多流特征提取器
feature_extractor = MultiStreamFeatureExtractor()
# 提取特征
appearance_features, motion_features, depth_features = feature_extractor(
rgb_frames, optical_flow_frames, depth_frames
)
# 输出特征形状
print("Appearance Features Shape:", appearance_features.shape) # (16, 512)
print("Motion Features Shape:", motion_features.shape) # (16, 512)
print("Depth Features Shape:", depth_features.shape) # (16, 512)
多视图学习
多视图学习的目标是将来自不同模态的特征( X 1 X_1 X1, X 2 X_2 X2, X 3 X_3 X3)融合为一个统一的特征表示,同时保留每个模态的独有特性并挖掘它们的共享信息。
首先:
- 设 X = { X i } i = 1 K X = \{X_i\}_{i=1}^K X={Xi}i=1K 表示从不同模态提取的特征,其中 K K K 是模态的数量(在本文中 K = 3 K=3 K=3)。
- X i X_i Xi 表示第 i i i 个模态的特征(例如, X 1 X_1 X1 是RGB特征, X 2 X_2 X2 是光流特征, X 3 X_3 X3 是深度特征)。
为了融合不同模态的特征,MDNN将每个模态的特征分解为两部分:
- 共享信息:不同模态之间的共同特征,表示为 g ( X ) g(X) g(X)。
- 独有特性:每个模态独有的特征,表示为 f i ( X i ) f_i(X_i) fi(Xi)。
具体公式如下:
-
共享信息 g ( X ) g(X) g(X) 是所有模态特征的加权平均:
g ( X ) = 1 K ∑ i = 1 K g i ( X i ) , g(X) = \frac{1}{K} \sum_{i=1}^K g_i(X_i), g(X)=K1∑i=1Kgi(Xi),
其中 g i ( X i ) g_i(X_i) gi(Xi) 是第 i i i 个模态的共享组件。 -
g i ( X i ) g_i(X_i) gi(Xi) 通过线性映射和非线性激活函数计算:
g i ( X i ) = σ ( W i g X i + b i g ) , g_i(X_i) = \sigma(W_i^g X_i + b_i^g), gi(Xi)=σ(WigXi+big),
其中:- W i g W_i^g Wig 和 b i g b_i^g big 是共享组件的权重矩阵和偏置项。
- σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是非线性激活函数(本文使用 tanh \tanh tanh 函数)。
-
每个模态的独有特性 f i ( X i ) f_i(X_i) fi(Xi) 通过另一个非线性变换计算:
f i ( X i ) = σ ( W i f X i + b i f ) , f_i(X_i) = \sigma(W_i^f X_i + b_i^f), fi(Xi)=σ(WifXi+bif),
其中:- W i f W_i^f Wif 和 b i f b_i^f bif 是独有特性的权重矩阵和偏置项。
- σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是非线性激活函数(本文使用 tanh \tanh tanh 函数)。
将共享信息和独有特性结合起来,得到融合后的特征
h
(
X
)
h(X)
h(X):
h
(
X
)
=
∑
i
=
1
K
α
i
f
i
(
X
i
)
+
β
g
(
X
)
,
h(X) = \sum_{i=1}^K \alpha_i f_i(X_i) + \beta g(X),
h(X)=∑i=1Kαifi(Xi)+βg(X),
其中:
- α i \alpha_i αi 是第 i i i 个模态独有特性的权重。
- β \beta β 是共享信息的权重。
- 权重满足约束条件:
∑ i = 1 K α i + β = 1 , 0 ≤ α 1 , α 2 , … , α K , β ≤ 1. \sum_{i=1}^K \alpha_i + \beta = 1, \quad 0 \leq \alpha_1, \alpha_2, \ldots, \alpha_K, \beta \leq 1. ∑i=1Kαi+β=1,0≤α1,α2,…,αK,β≤1.
MDNN的目标函数包括三部分:
- 分类损失:用于动作识别的交叉熵损失。
- 共享信息损失:通过Cauchy估计器最大化共享组件之间的相关性。
- 独有特性损失:通过正交性约束保留每个模态的独有特性。
具体公式如下:
分类损失
J
c
l
s
=
−
∑
l
=
1
L
1
(
y
=
l
)
log
(
s
l
)
,
J_{cls} = -\sum_{l=1}^L \mathbb{1}(y = l) \log(s_l),
Jcls=−∑l=1L1(y=l)log(sl),
其中:
- y y y 是预测的类别标签。
- l l l 是真实的类别标签。
- s l s_l sl 是类别 l l l 的softmax输出概率。
共享信息损失
J
s
=
λ
1
∑
1
≤
i
<
j
≤
K
Φ
s
(
g
i
(
X
i
)
,
g
j
(
X
j
)
)
,
J_s = \lambda_1 \sum_{1 \leq i < j \leq K} \Phi_s(g_i(X_i), g_j(X_j)),
Js=λ1∑1≤i<j≤KΦs(gi(Xi),gj(Xj)),
其中:
-
Φ
s
(
g
i
(
X
i
)
,
g
j
(
X
j
)
)
\Phi_s(g_i(X_i), g_j(X_j))
Φs(gi(Xi),gj(Xj)) 是Cauchy估计器,用于衡量共享组件之间的相关性:
Φ s ( g i ( X i ) , g j ( X j ) ) = log ( 1 + ∥ g i ( X i ) − g j ( X j ) ∥ 2 a 2 ) . \Phi_s(g_i(X_i), g_j(X_j)) = \log\left(1 + \frac{\|g_i(X_i) - g_j(X_j)\|^2}{a^2}\right). Φs(gi(Xi),gj(Xj))=log(1+a2∥gi(Xi)−gj(Xj)∥2). - a a a 是Cauchy估计器的超参数(本文设置为1)。
- λ 1 \lambda_1 λ1 是共享信息损失的权重。
独有特性损失
J
d
=
λ
2
[
∑
1
≤
i
<
j
≤
K
Φ
d
(
f
i
(
X
i
)
,
f
j
(
X
j
)
)
+
∑
i
=
1
K
Φ
d
(
f
i
(
X
i
)
,
g
i
(
X
i
)
)
]
,
J_d = \lambda_2 \left[ \sum_{1 \leq i < j \leq K} \Phi_d(f_i(X_i), f_j(X_j)) + \sum_{i=1}^K \Phi_d(f_i(X_i), g_i(X_i)) \right],
Jd=λ2[∑1≤i<j≤KΦd(fi(Xi),fj(Xj))+∑i=1KΦd(fi(Xi),gi(Xi))],
其中:
-
Φ
d
(
f
i
(
X
i
)
,
f
j
(
X
j
)
)
\Phi_d(f_i(X_i), f_j(X_j))
Φd(fi(Xi),fj(Xj)) 是正交性约束,用于确保不同模态的独有特性相互独立:
Φ d ( f i ( X i ) , f j ( X j ) ) = ∥ f i ( X i ) ⊙ f j ( X j ) ∥ 2 . \Phi_d(f_i(X_i), f_j(X_j)) = \|f_i(X_i) \odot f_j(X_j)\|^2. Φd(fi(Xi),fj(Xj))=∥fi(Xi)⊙fj(Xj)∥2. -
Φ
d
(
f
i
(
X
i
)
,
g
i
(
X
i
)
)
\Phi_d(f_i(X_i), g_i(X_i))
Φd(fi(Xi),gi(Xi)) 是正交性约束,用于确保独有特性与共享信息无关:
Φ d ( f i ( X i ) , g i ( X i ) ) = ∥ f i ( X i ) ⊙ g i ( X i ) ∥ 2 . \Phi_d(f_i(X_i), g_i(X_i)) = \|f_i(X_i) \odot g_i(X_i)\|^2. Φd(fi(Xi),gi(Xi))=∥fi(Xi)⊙gi(Xi)∥2. - λ 2 \lambda_2 λ2 是独有特性损失的权重。
因此,总目标函数为:
J
=
J
c
l
s
+
J
s
+
J
d
.
J = J_{cls} + J_s + J_d.
J=Jcls+Js+Jd.$
算法流程如下所示:

代码实现如下所示:
# 定义共享信息和独有特性的计算模块
class SharedAndSpecificFeatures(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(SharedAndSpecificFeatures, self).__init__()
# 共享信息的线性映射
self.shared_fc = nn.Linear(input_dim, hidden_dim)
# 独有特性的线性映射
self.specific_fc = nn.Linear(input_dim, hidden_dim)
def forward(self, x):
# 共享信息
g = torch.tanh(self.shared_fc(x))
# 独有特性
f = torch.tanh(self.specific_fc(x))
return g, f
# 定义多视图学习模块
class MultiViewLearning(nn.Module):
def __init__(self, input_dim, hidden_dim, num_modalities):
super(MultiViewLearning, self).__init__()
self.num_modalities = num_modalities
# 每个模态的共享信息和独有特性计算模块
self.modality_modules = nn.ModuleList([
SharedAndSpecificFeatures(input_dim, hidden_dim) for _ in range(num_modalities)
])
# 共享信息的权重
self.beta = nn.Parameter(torch.tensor(0.5))
# 独有特性的权重
self.alphas = nn.Parameter(torch.ones(num_modalities) / num_modalities)
def forward(self, modality_features):
# modality_features: 列表,包含每个模态的特征 [X1, X2, X3]
shared_features = []
specific_features = []
for i in range(self.num_modalities):
g_i, f_i = self.modality_modules[i](modality_features[i])
shared_features.append(g_i)
specific_features.append(f_i)
# 计算共享信息 g(X)
g_X = torch.mean(torch.stack(shared_features), dim=0)
# 计算融合特征 h(X)
h_X = torch.zeros_like(g_X)
for i in range(self.num_modalities):
h_X += self.alphas[i] * specific_features[i]
h_X += self.beta * g_X
return h_X, shared_features, specific_features
# 定义目标函数
def compute_loss(h_X, shared_features, specific_features, labels, lambda1, lambda2):
# 分类损失 (假设有一个分类器)
classifier = nn.Linear(h_X.size(1), num_classes) # num_classes 是类别数
logits = classifier(h_X)
cls_loss = F.cross_entropy(logits, labels)
# 共享信息损失 (Cauchy估计器)
shared_loss = 0
num_pairs = 0
for i in range(len(shared_features)):
for j in range(i + 1, len(shared_features)):
diff = shared_features[i] - shared_features[j]
shared_loss += torch.log(1 + torch.norm(diff, p=2) ** 2)
num_pairs += 1
shared_loss = (lambda1 / num_pairs) * shared_loss
# 独有特性损失 (正交性约束)
specific_loss = 0
for i in range(len(specific_features)):
for j in range(i + 1, len(specific_features)):
# 独有特性之间的正交性
specific_loss += torch.norm(specific_features[i] * specific_features[j], p=2) ** 2
# 独有特性与共享信息的正交性
specific_loss += torch.norm(specific_features[i] * shared_features[i], p=2) ** 2
specific_loss = lambda2 * specific_loss
# 总目标函数
total_loss = cls_loss + shared_loss + specific_loss
return total_loss
# 主函数
if __name__ == "__main__":
input_dim = 512 # 输入特征维度
hidden_dim = 512 # 隐藏层维度
num_modalities = 3 # 模态数量
num_classes = 40 # 类别数
lambda1 = 1.0 # 共享信息损失的权重
lambda2 = 1.0 # 独有特性损失的权重
# 初始化多视图学习模块
multi_view_learner = MultiViewLearning(input_dim, hidden_dim, num_modalities)
# 输入特征为 [X1, X2, X3]
X1 = torch.randn(16, input_dim) # RGB特征
X2 = torch.randn(16, input_dim) # 光流特征
X3 = torch.randn(16, input_dim) # 深度特征
modality_features = [X1, X2, X3]
# 前向传播
h_X, shared_features, specific_features = multi_view_learner(modality_features)
# 标签
labels = torch.randint(0, num_classes, (16,))
# 计算损失
loss = compute_loss(h_X, shared_features, specific_features, labels, lambda1, lambda2)
print("Total Loss:", loss.item())
手部模块
作者进一步扩展了MDNN方法,通过引入手部线索(hand cues)来增强第一人称动作识别的性能。手部线索在第一人称视频中非常重要,因为人类在行动时通常会关注自己的手部动作,手部的位置和姿态往往与动作类别密切相关。
MDNN + Hand 方法的核心思想是通过引入手部线索来增强动作识别的准确性。具体来说,MDNN + Hand 在MDNN的基础上增加了一个手部模块(hand module),用于提取手部区域的特征,并将其与MDNN的多模态特征融合。
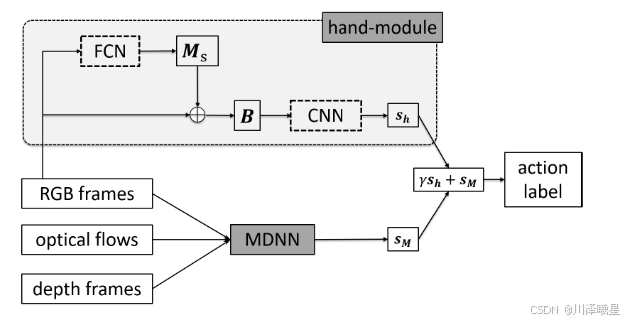
手部模块的主要任务是从RGB帧中分割出手部区域,并提取手部特征。
-
手部分割:使用全卷积网络(Fully Convolutional Network, FCN)对RGB帧进行手部分割,生成手部掩码(hand mask)。FCN的输出是一个二值图像,其中手部区域为1,背景区域为0。由于第一人称视频中通常最多出现两只手,因此只保留掩码中最大的两个连通区域。
-
背景去除:使用手部掩码去除RGB帧中的背景区域,得到只包含手部区域的图像,这样可以减少背景噪声对动作识别的干扰。
-
手部特征提取:将去除背景后的手部图像输入到一个卷积神经网络(CNN)中,提取手部特征。该CNN的结构与MDNN中的外观流(appearance stream)类似,但专门用于提取手部特征。
手部模块的损失函数
-
手部分割损失:使用逐像素的二分类交叉熵损失(per-pixel binary cross-entropy loss)来训练FCN模型。损失函数计算手部掩码的预测结果与真实标签之间的差异。
-
手部特征分类损失:使用交叉熵损失(cross-entropy loss)来训练手部特征提取的CNN模型。损失函数计算手部特征的分类结果与动作标签之间的差异。
手部模块的输出是一个手部特征向量,表示手部区域的外观信息。为了将手部特征与MDNN的多模态特征融合,MDNN + Hand 将手部特征与MDNN的融合特征 h ( X ) h(X) h(X) 进行拼接(concatenation),得到增强后的特征表示。增强后的特征表示可以捕捉到手部区域与多模态特征之间的关联。接下来将增强后的特征输入到一个全连接层和softmax函数中,进行动作类别的预测。为了平衡手部特征和多模态特征的重要性,MDNN + Hand 使用加权融合策略:
s = γ s h + s M s = \gamma s_h + s_M s=γsh+sM
其中:
- s h s_h sh 是手部特征的分类得分。
- s M s_M sM 是 MDNN 的融合特征的分类得分。
- γ \gamma γ 是一个平衡超参数,用于调整手部特征的重要性。
实验结果
本文在三个RGB-D第一人称动作数据集上进行了实验,包括THU-READ、Wearable Computer Vision Systems(WCVS)和Grasp Understanding(GUN-71)数据集。实验结果表明,本文提出的MDNN和MDNN + Hand方法在动作识别任务中均取得了优异的性能。
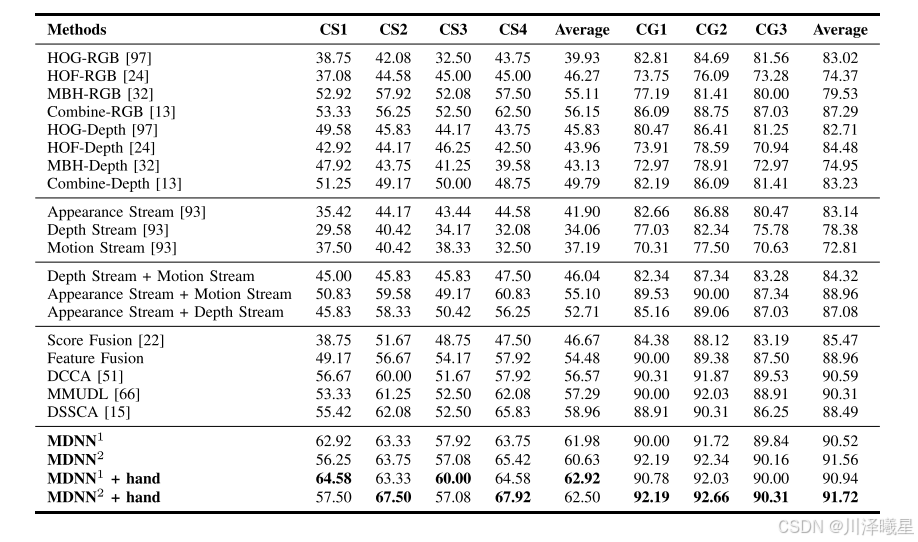
在THU-READ数据集上,MDNN和MDNN + Hand方法的识别准确率分别达到了61.98%和62.92%,显著优于现有的基于手工特征和深度学习的方法。特别是在交叉组(Cross-Group, CG)和交叉对象(Cross-Subject, CS)设置下,MDNN + Hand方法的表现尤为突出,证明了手部线索在动作识别中的重要性。
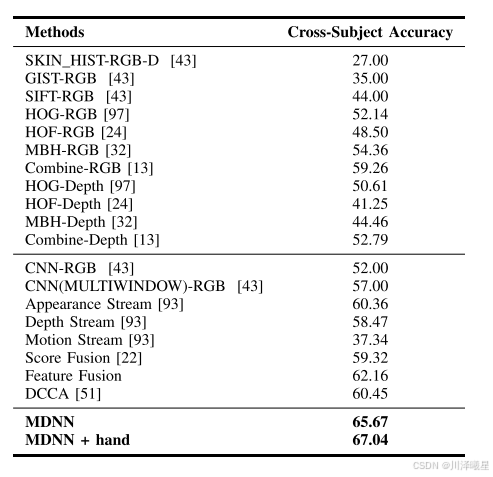
在WCVS数据集上,MDNN和MDNN + Hand方法的识别准确率分别为65.67%和67.04%,同样优于现有的方法。特别是在交叉对象设置下,MDNN + Hand方法的性能提升更为明显,进一步验证了手部线索的有效性。
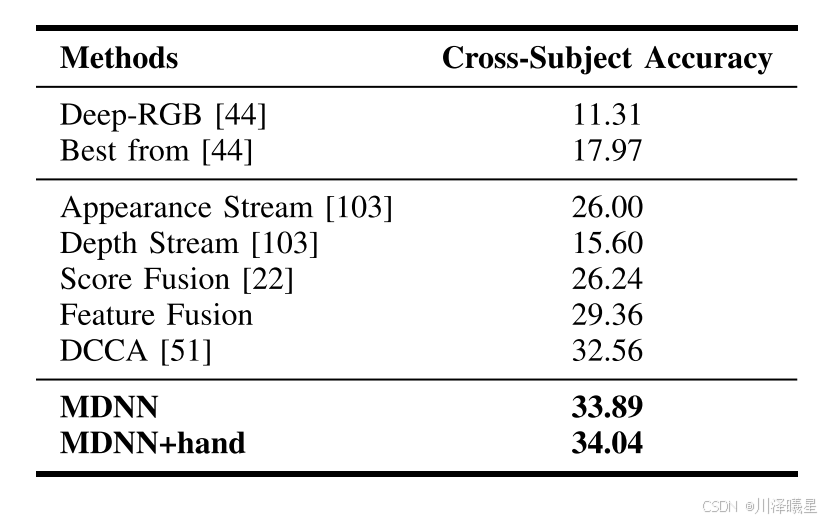
在GUN-71数据集上,MDNN和MDNN + Hand方法的识别准确率分别为33.89%和34.04%,显著优于现有的方法。尽管GUN-71是一个基于图像的数据集,缺乏时间信息,但MDNN方法仍然能够通过融合RGB和深度信息来提高识别性能。
创新性
本文的主要创新点可以总结为以下几个方面:
-
多流深度神经网络(MDNN):本文提出了一种新的多流深度神经网络方法,用于RGB-D第一人称动作识别。MDNN通过三个深度卷积神经网络分别学习RGB帧、光流和深度帧的特征,并通过Cauchy估计器和正交性约束来最大化不同模态之间的相关性并保留每个模态的独特性。这种方法能够更好地挖掘RGB-D视频中的互补信息,从而提高动作识别的准确性。
-
新的RGB-D第一人称动作数据集(THU-READ):本文收集了一个新的RGB-D第一人称动作数据集,称为THU-READ。该数据集包含340K视频帧和200M像素的手部标注,是目前最大的RGB-D第一人称动作数据集。THU-READ的发布为第一人称动作识别研究提供了重要的数据支持。
-
手部线索的引入:本文扩展了MDNN,将其与第一人称视频中的手部线索相结合,进一步提高了动作识别的准确性。手部线索在第一人称动作识别中具有重要作用,因为人类在行动时通常会关注自己的手部动作。通过引入手部线索,MDNN + Hand方法能够更好地捕捉动作的细节信息,从而提高识别性能。
-
Cauchy估计器的应用:本文采用Cauchy估计器来最大化不同模态之间的相关性。与传统的L1和L2距离相比,Cauchy估计器对异常值更加鲁棒,能够更好地处理第一人称视频中的光照变化和摄像机运动带来的噪声。
局限性
尽管本文提出的方法在RGB-D第一人称动作识别任务中取得了显著的成果,但仍存在一些局限性:
-
数据集规模:尽管THU-READ是目前最大的RGB-D第一人称动作数据集,但其规模仍然相对较小。未来可以进一步扩展数据集的规模,增加更多的参与者和更具挑战性的动作类别,以验证方法的泛化能力。
-
手部分割的准确性:MDNN + Hand方法的性能提升依赖于手部分割的准确性。然而,当前的手部分割方法在某些情况下仍然存在失败的情况,影响了动作识别的准确性。未来可以尝试使用更先进的分割方法(如Mask R-CNN)来提高手部分割的质量。
-
模态权重的自适应调整:本文通过实验确定了不同模态的权重分配策略,但这种策略可能不适用于所有数据集和任务。未来可以探索自适应的权重调整方法,根据不同的任务和数据自动调整每个模态的重要性。
-
计算复杂度:MDNN方法涉及多个深度卷积神经网络的训练和特征融合,计算复杂度较高。未来可以尝试优化网络结构,减少计算开销,提高方法的实时性。
总结
本文提出了一种多流深度神经网络(MDNN)方法,用于RGB-D第一人称动作识别。通过结合RGB、光流和深度信息,MDNN能够充分利用不同模态的互补特性,从而提高动作识别的准确性。此外,本文还扩展了MDNN,将其与手部线索相结合,进一步提升了识别性能。实验结果表明,MDNN和MDNN + Hand方法在THU-READ、WCVS和GUN-71数据集上均取得了优异的性能,显著优于现有的方法。不过尽管本文的方法在RGB-D第一人称动作识别任务中取得了显著的成果,但仍存在一些局限性,如数据集规模较小、手部分割的准确性不足等。未来的研究可以进一步扩展数据集的规模,探索更先进的分割方法,并尝试自适应的权重调整策略,以提高方法的泛化能力和实时性。

















 6297
6297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









