







摘要
本周主要复习了之前学过的循环神经网络,加深了对 RNN 基础结构和原理的印象,了解到了这种网络结构适用的任务类型以及优缺点,并且对 RNN 进行了相应的代码实践。
Abstract
This week, I mainly reviewed the recurrent neural networks (RNNs) that I had learned before, deepening my understanding of their basic structure and principles. I also gained insight into the types of tasks suitable for this network architecture, as well as its advantages and disadvantages. Additionally, I practiced implementing RNNs through corresponding code exercises.
RNN的代码实践
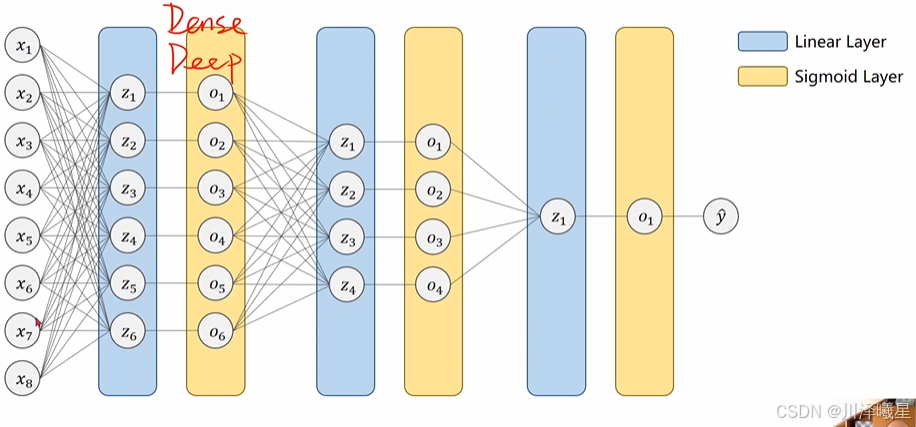
图上的这种网络我们称为全连接的神经网络,或者是 DNN(Dense Neural Network),其中 x i x_i xi 是一个样本的不同输入特征。
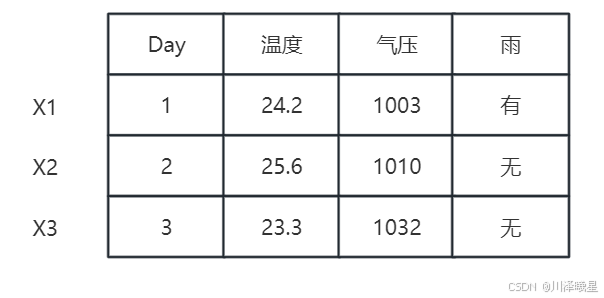
假设我们有如上图的数据,其中 x i x_i xi 表示的是不同的样本(和上文提到的不一样),每个 x i x_i xi 里有三个不同的特征——温度、气压和是否有雨。如果我们要判断第四天是否下雨,我们可以把前三天的数据同时输入神经网络,再由神经网络进行输出。
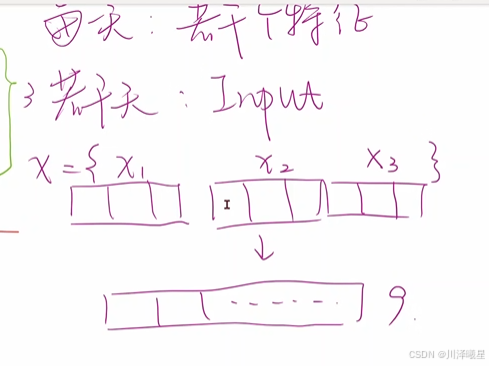
如果我们设计的是一个全连接神经网络,要把前三天的样本输入神经网络,就要把前三天的数据展平成一个向量,也就是要传入一个 1x9 的行向量。这种方法对于一个稠密的全连接网络来说计算量是非常大的,即使在以共享权重闻名的 CNN 中,其计算量的大头也在最后的全连接层。如果考虑前30天的数据且每个样本的特征值足够多,这种方法的效率就不是很高了。
所以我们需要一个擅长处理序列输入的神经网络—— RNN(循环神经网络)。
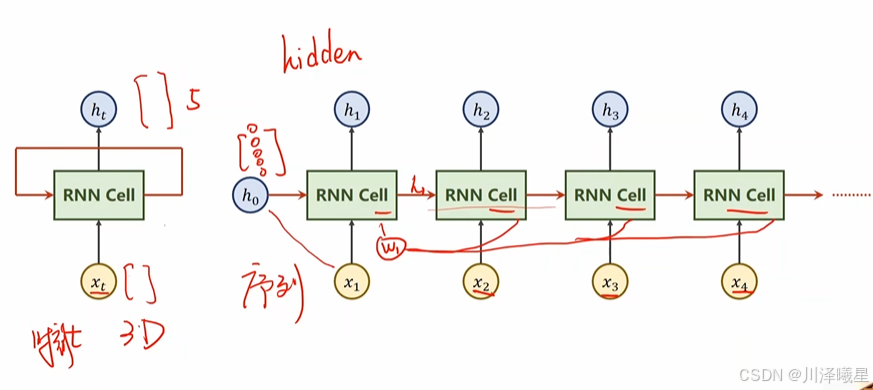
循环神经网络的结构大致像上图的左半部分,其中 RNN Cell 说白了就是一个线性层,实现的是输入和输出张量的维度变换。把左图展开成右图,可以看到其中的循环就是值得把上一个变换后的张量重新输入到 RNN Cell 里再进行相应的变换。 RNN Cell 中的权重也是共享的,这也是 RNN 比 DNN 减少大量计算的关键。
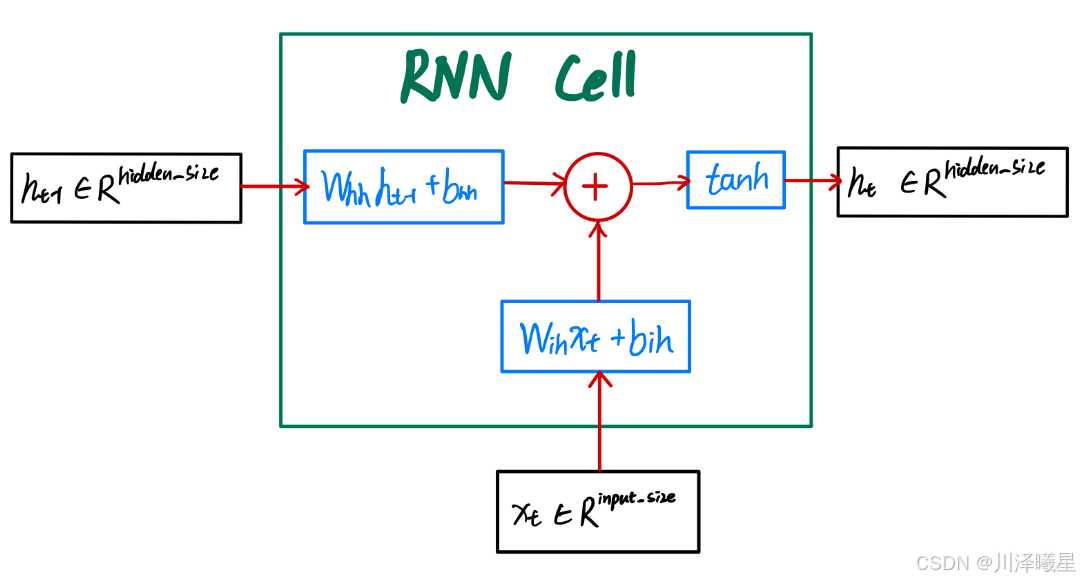
RNN 的具体运算过程如上所示,其中蓝框中的两个线性运算都是将两个向量转换为 hidden_size 大小的向量,然后再进行信息融合,最后激活再输出到下一个循环。
具体的维度如下所示:

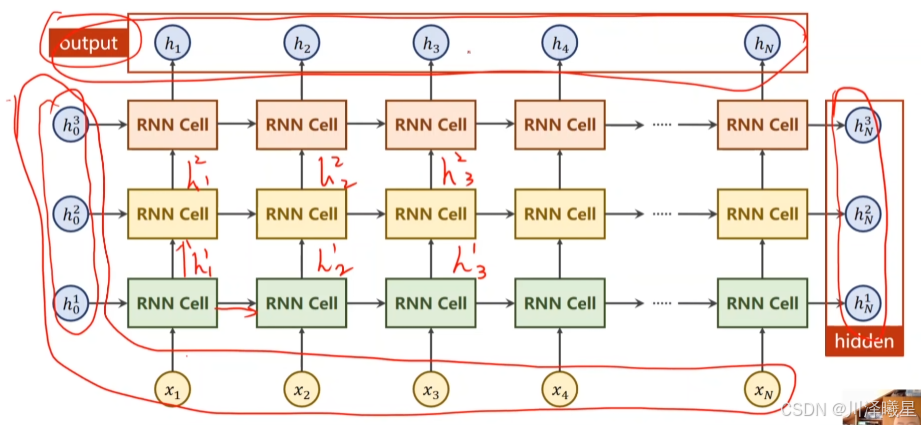
其中隐层的维度之所以多了个 numLayers 是由于 RNN 可以经过多层 RNN Cell ,因此张量再需要多个维度来表示。
我们可以用一个简单的例子来体验一下维度的变化:
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1 # RNN层数
# Construction of RNN
rnn = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
# Wrapping the sequence into:(seqLen,batchSize,InputSize)
inputs = torch.randn(seq_len, batch_size, input_size) # (3,1,4)
# Initializing the hidden to zero
hidden = torch.zeros(num_layers, batch_size, hidden_size) # (1,1,2)
output, hidden = rnn(inputs, hidden) # RNN内部包含了循环,故这里只需把整个序列输入即可
print('Output size:', output.shape) # (seq_len, batch_size, hidden_size)
print('Output:', output)
print('Hidden size:', hidden.shape) # (num_layers, batch_size, hidden_size)
print('Hidden:', hidden)
运行结果如下:

batch_first
在PyTorch中,RNN模型的输入通常是(seq_len, batch_size, input_size)这样的形式,即时间步序列排列在第一维,批量数据排列在第二维。但是,在某些情况下,我们可能更倾向于使用(batch_size, seq_len, input_size)的输入形式。为了满足这种需要,PyTorch提供了batch_first参数。
当batch_first=True时,输入和输出的形状就变成了(batch_size, seq_len, input_size),这样就更符合一般的数据格式。在构造RNN模型时,只需将batch_first参数设置为True即可。
下面利用 RNN 构建一个简单的案例:
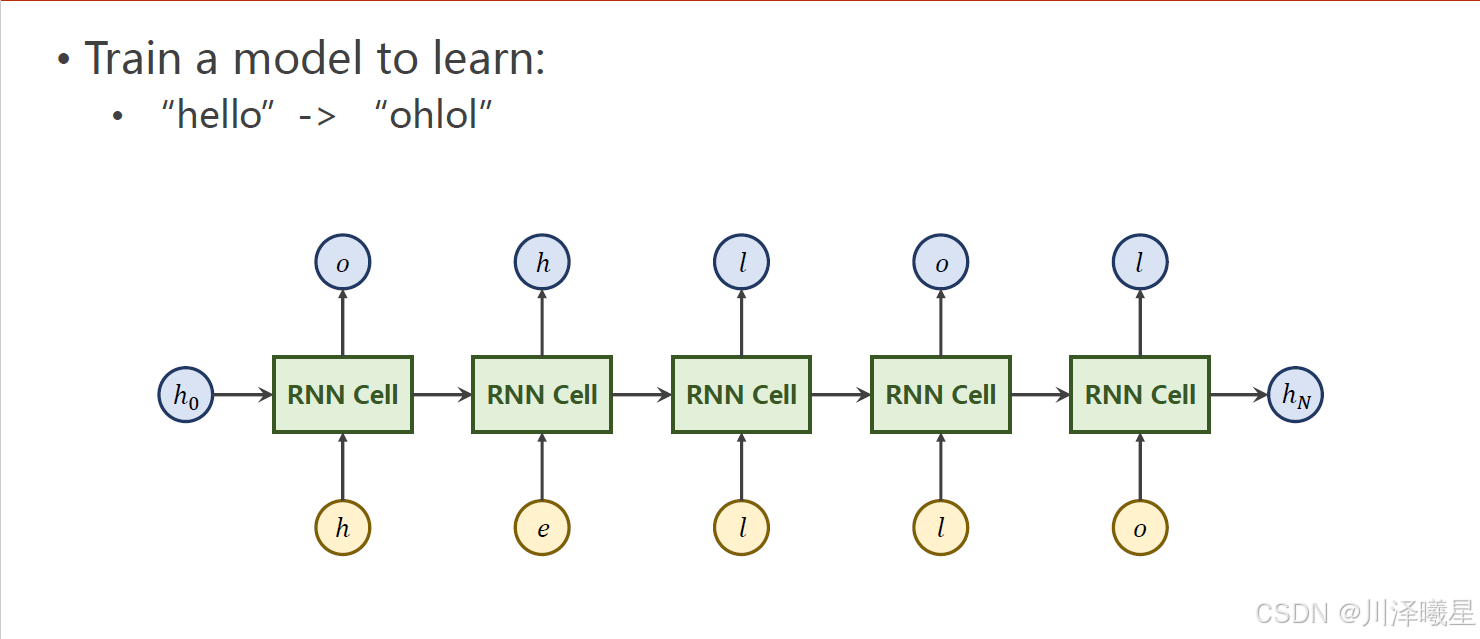
例如把输入序列 hello 转换为输出序列 ohlol。

首先将输入数据按字典转换为索引再转换为独热向量。
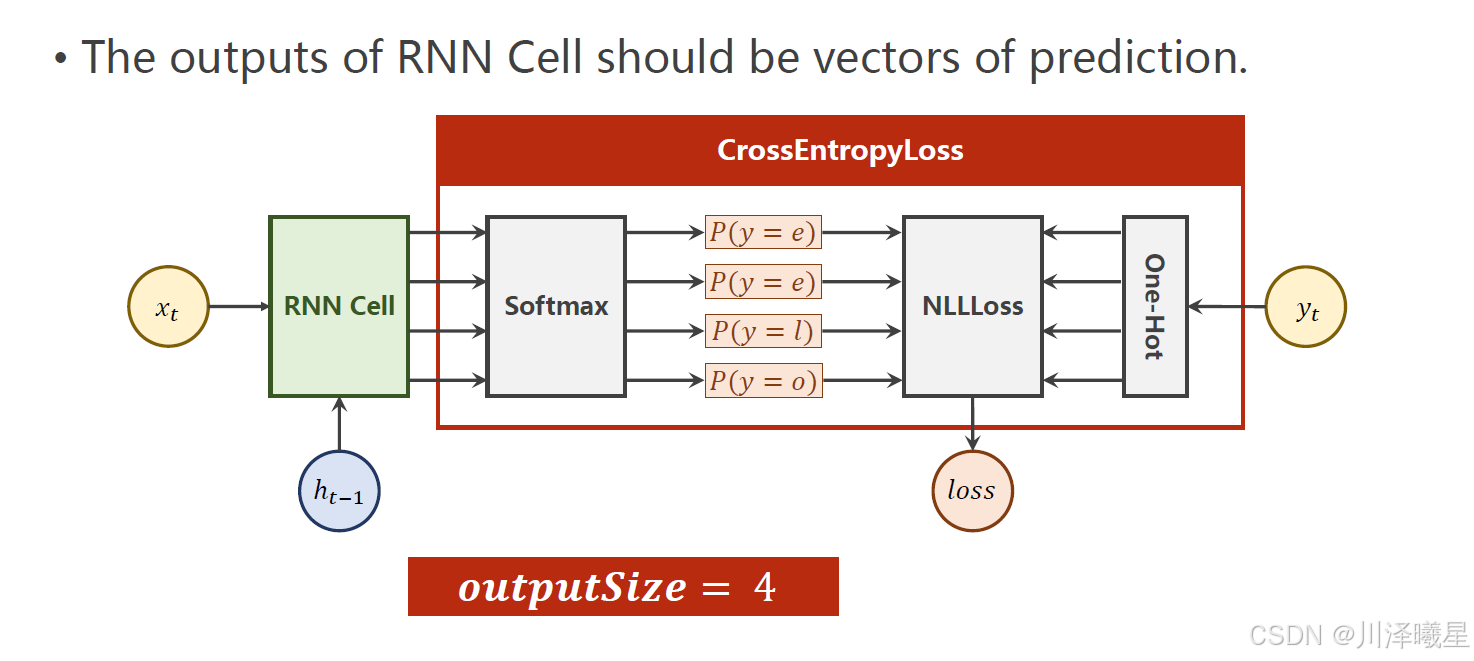
最后的输出实际上是实现一个分类任务。
RNNCell
代码如下:
import torch
# 1、确定参数
input_size = 4
hidden_size = 4
batch_size = 1
# 2、准备数据
index2char = ['e', 'h', 'l', 'o'] #字典
x_data = [1, 0, 2, 2, 3] #用字典中的索引(数字)表示来表示hello
y_data = [3, 1, 2, 3, 2] #标签:ohlol
one_hot_lookup = [[1, 0, 0, 0], # 用来将x_data转换为one-hot向量的参照表
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data] #将x_data转换为one-hot向量
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size) #(𝒔𝒆𝒒𝑳𝒆𝒏,𝒃𝒂𝒕𝒄𝒉𝑺𝒊𝒛𝒆,𝒊𝒏𝒑𝒖𝒕𝑺𝒊𝒛𝒆)
labels = torch.LongTensor(y_data).view(-1, 1) # (seqLen*batchSize,𝟏).计算交叉熵损失时标签不需要我们进行one-hot编码,其内部会自动进行处理
# 3、构建模型
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size)
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden)
return hidden
def init_hidden(self): #初始化隐藏层,需要batch_size
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
# 4、损失和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









