




 本文介绍了SQL查询中的SORTBY、ORDERBY、DISTRIBUTEBY及CLUSTERBY子句的使用方法及其区别。通过具体示例说明如何利用这些子句对查询结果进行排序、分区和全局排序,帮助读者理解不同场景下选择合适子句的重要性。
本文介绍了SQL查询中的SORTBY、ORDERBY、DISTRIBUTEBY及CLUSTERBY子句的使用方法及其区别。通过具体示例说明如何利用这些子句对查询结果进行排序、分区和全局排序,帮助读者理解不同场景下选择合适子句的重要性。
使用的表格
下面是文中使用到的数据
SalesYear Amount
2017 100
2018 200
2019 300
2020 400
2017 500
2018 600
2019 700
2020 800
1 SORT BY
SORT by子句对每个reducer的数据进行排序。结果,如果我们有N个减速器,则输出中将有N个排序文件。这些文件的数据范围可以重叠。同样,输出数据也不是全局排序的,因为配置单元会根据SORT BY子句中使用的键列对行进行排序,然后再将它们提供给减速器。SORT BY子句的语法如下:
SELECT Col1, Col2,……ColN FROM TableName SORT BY Col1 <ASC | DESC>, Col2 <ASC | DESC>, …. ColN <ASC | DESC>
SELECT SalesYear, Amount
FROM tbl_Sales
SORT BY SalesYear;
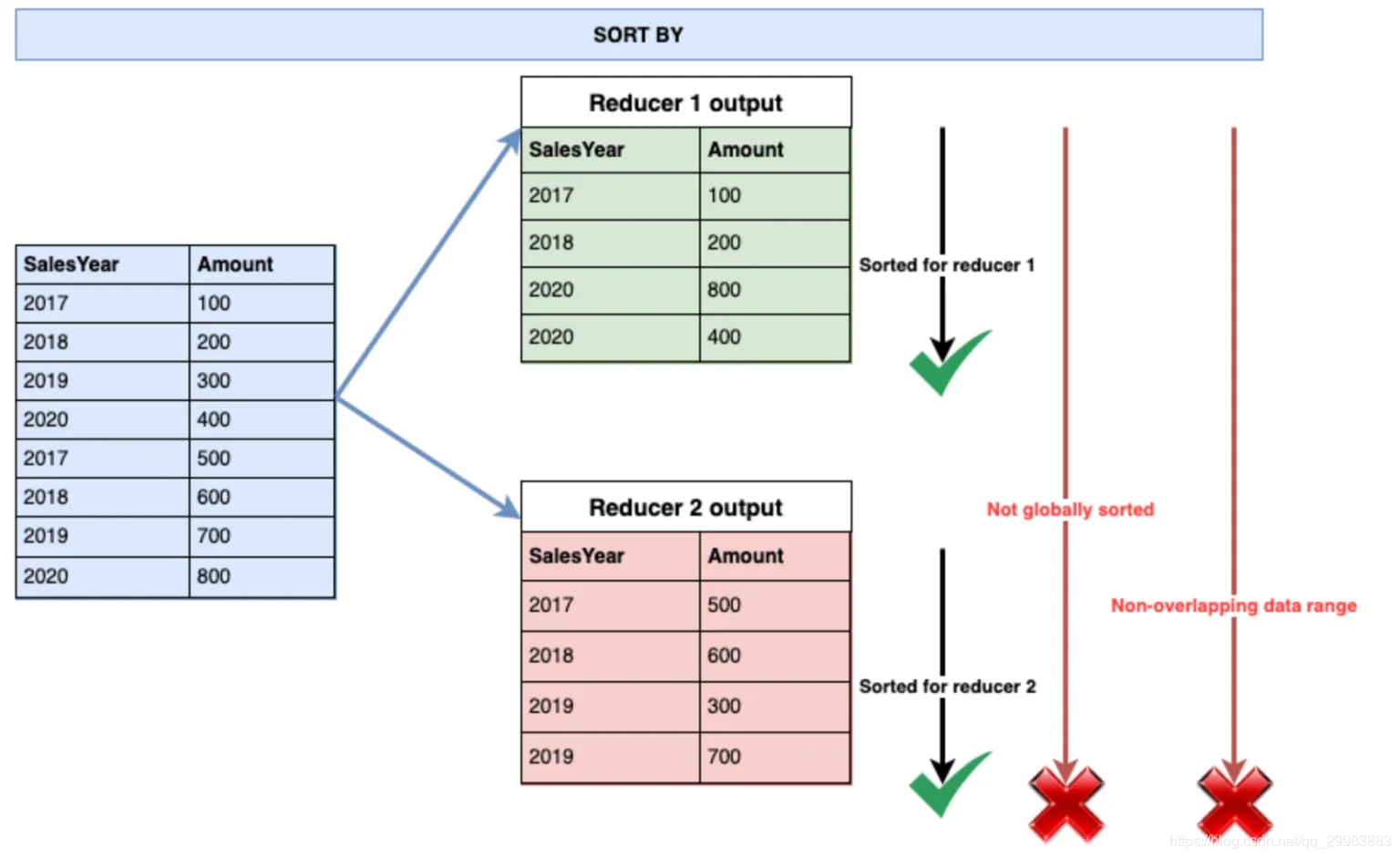
现在,假设我们有两个化简器来执行此查询。因此,在最终输出中,我们将基于每个化简器的SalesYear列值,获得两个本地排序的文件。这意味着文件仅按reducer进行排序,而不是全局。请注意,最终输出数据不是全局排序的,并且可能具有重叠的数据范围。
带有2个reducers的上述查询的输出将如下所示:
2 、ORDER BY
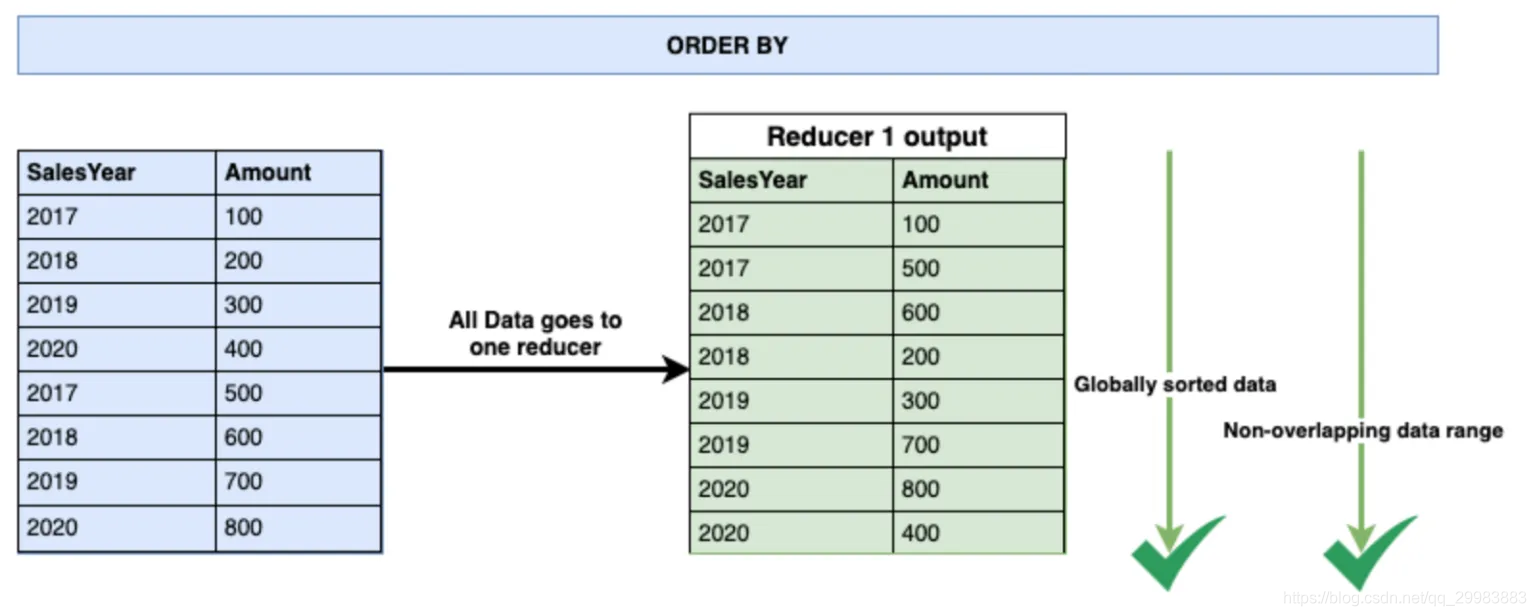
ORDER BY子句对数据进行全局排序。因为它确保了数据的全局排序,所以所有数据仅需要从单个reducer传递。结果,order by子句仅输出一个文件。将所有数据都放在一个reducer上可能会成为性能杀手,尤其是在我们的输出数据集非常大的情况下。因此,我们应该始终避免在配置单元查询中使用ORDER BY子句。但是,如果需要强制对数据进行全局排序,而输出数据集不是那么大,则可以使用此配置单元子句对最终数据集进行全局排序。
SELECT Col1, Col2,……ColN FROM TableName ORDER BY Col1 <ASC | DESC>, Col2 <ASC | DESC>, …. ColN <ASC | DESC>
SELECT SalesYear, Amount
FROM tbl_Sales
SORT BY SalesYear;
3、DISTRIBUTE BY
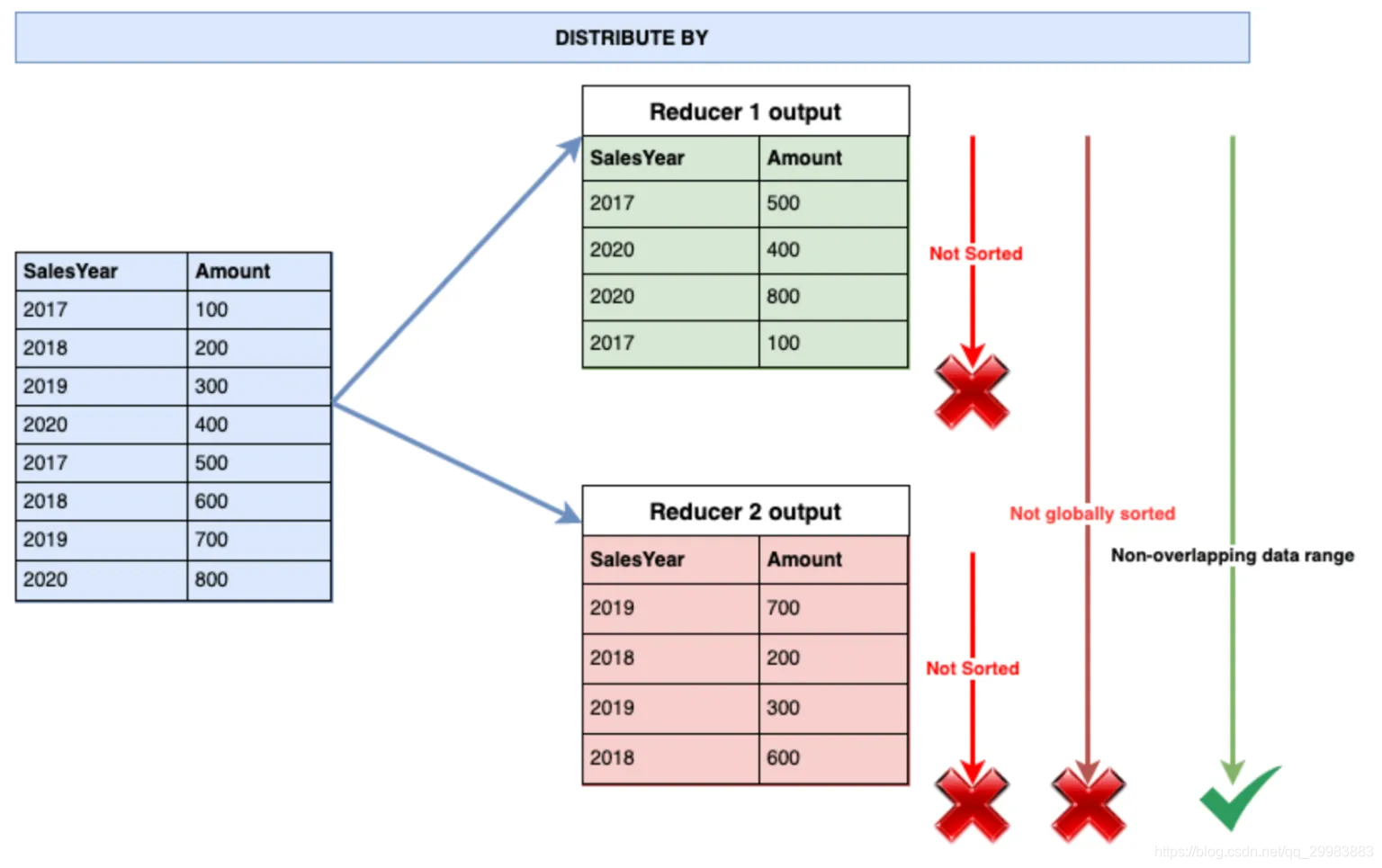
DISTRIBUTE BY子句用于在缩减器之间分配输入行。它确保相同键列的所有行都将到达相同的reducer。因此,如果需要对某个键列上的数据进行分区,则可以在配置单元查询中使用DISTRIBUTE BY子句。但是,DISTRIBUTE BY子句不会在reducer级别或global上对数据进行排序。同样,相同的键值可能不会在输出数据集中彼此相邻放置。
结果,DISTRIBUTE BY子句可以输出N个未排序的文件,其中N是查询处理中使用的化简器数量。但是,输出文件不包含重叠的数据范围。
配置单元中DISTRIBUTE BY子句的语法如下:
SELECT Col1, Col2,……ColN FROM TableName DISTRIBUTE BY Col1, Col2, ….. ColN
SELECT SalesYear, Amount
FROM tbl_Sales
DISTRIBUTE BY SalesYear;
4、CLUSTER BY
CLUSTER BY子句是DISTRIBUTE BY和SORT BY子句一起的组合。这意味着CLUSTER BY子句的输出等效于DISTRIBUTE BY + SORT BY子句的输出。CLUSTER BY子句根据键列分配数据,然后通过将相同的键列值彼此相邻来对输出数据进行排序。因此,CLUSTER BY子句的输出在reducer级别排序。结果,我们可以获得N个排序的输出文件,其中N是查询处理中使用的化简器数。此外,CLUSTER by子句可确保我们获取不重叠的数据范围进入最终输出。但是,如果查询仅由一个reducer处理,则输出将等同于ORDER BY子句的输出。
SELECT Col1, Col2,……ColN FROM TableName CLUSTER BY Col1, Col2, ….. ColN
SELECT SalesYear, Amount
FROM tbl_Sales
CLUSTER BY SalesYear;

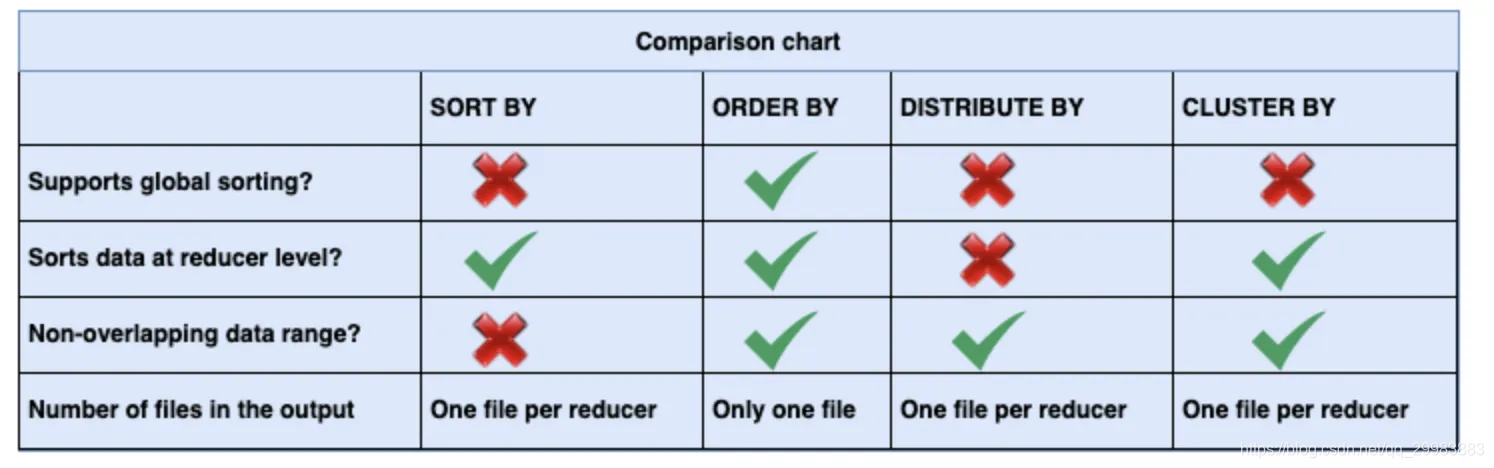
比较

















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









