






一、分组聚合

.
import pandas as ps
import numpy as np
a1 = ps.read_csv("./分组聚合.txt")
# A, B, C, D
# 45,26,57,92
# 215,548,5,78
# 45,51,102,36
# 584,56,98,72
b1 = a1.groupby(by="A") # 以列索引 A 单独分组
print(b1)
for i in b1:
print(i,"\n","*"*50) # 查看分组以后的效果
print(b1.count(),"\n","*"*50) # count() 方法用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置(统计所有数字出现的次数)
b2 = b1["A"].count() # 统计列索引 A 下的所有数字出现的次数
print(b2[45],"\n","*"*50) # 输出行索引 45 这一数字出现的次数


二、数据的索引
1、获取index
import pandas as ps
import numpy as np
a1 = ps.DataFrame(np.arange(8).reshape((2,4)),columns=["A","B","C","D"],index=["a","b"])
print(a1,"\n","#"*50)
# A B C D
# a 0 1 2 3
# b 4 5 6 7
print(a1.index) # 获取a1的行索引

2、指定index
import pandas as ps
import numpy as np
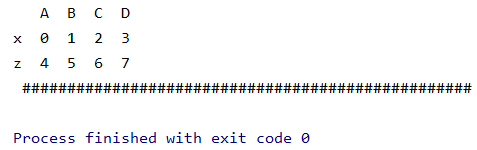
a1 = ps.DataFrame(np.arange(8).reshape((2,4)),columns=["A","B","C","D"],index=["a","b"])
print(a1,"\n","#"*50)
# A B C D
# a 0 1 2 3
# b 4 5 6 7
a1.index = ["x","z"] # 指定a1的行索引
print(a1,"\n","#"*50)
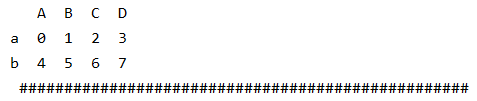

















 1373
1373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









