






 文章介绍了数据库查询中的连接过程,包括驱动表和被驱动表的概念,内连接和外连接的区别,以及连接条件的重要性。内连接只包含匹配的记录,而外连接保留所有驱动表的记录,即使在被驱动表中没有匹配。此外,文章还探讨了循环嵌套连接的基本思想以及基于块的循环嵌套连接,这是一种优化策略,减少从磁盘加载数据的次数。
文章介绍了数据库查询中的连接过程,包括驱动表和被驱动表的概念,内连接和外连接的区别,以及连接条件的重要性。内连接只包含匹配的记录,而外连接保留所有驱动表的记录,即使在被驱动表中没有匹配。此外,文章还探讨了循环嵌套连接的基本思想以及基于块的循环嵌套连接,这是一种优化策略,减少从磁盘加载数据的次数。
连接过程简介
- 确定第一个需要查询的表,称之为驱动表,在驱动表中将记录查询出来之后得到多个记录结果
- 通过驱动表中查询到的结果,挨个到被驱动表中查询
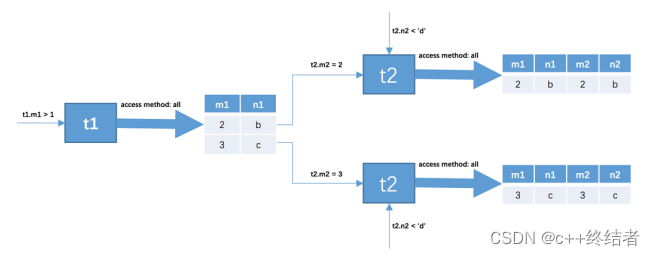
也就是说,驱动表只需要访问一次,而被驱动表则需要被访问多次
内连接和外连接
内连接
本质:在被驱动表中找不到的驱动表记录不再需要加入到结果中
外连接
本质:在被驱动表中找不到的驱动表记录仍然需要加入到结果中
连接条件
对于上文的外连接,在WHERE ON语句上的才会有特赦行为的存在 ON也被称为连接条件
连接语法
- 左外连接
SELECT * FROM t1 LEFT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];
#ON 子句是必须存在的
- 右外连接
同左外连接,不再解释 - 内连接
SELECT * FROM t1 [INNER | CROSS] JOIN t2 [ON 连接条件] [WHERE 普通过滤条件];
由于内连接中Where和ON子句是等价的,所以内连接不要求强制写明ON子句
连接的原理
循环嵌套连接
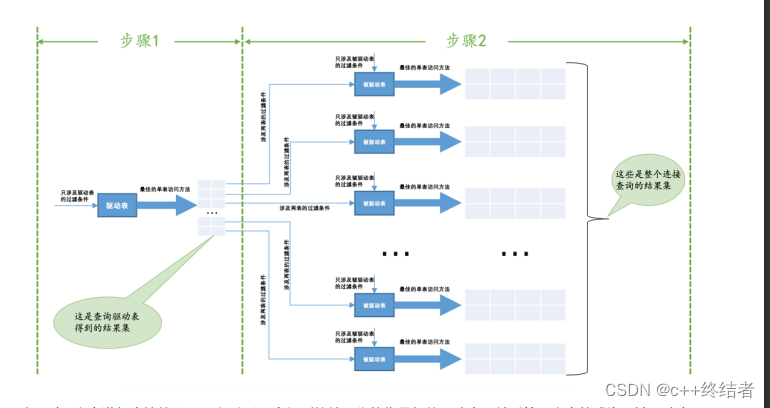
循环嵌套连接用伪代码表示类似这样
for each row in t1 { #此处表示遍历满足对t1单表查询结果集中的每一条记录
for each row in t2 { #此处表示对于某条t1表的记录来说,遍历满足对t2单表查询结果集中的
每一条记录
for each row in t3 { #此处表示对于某条t1和t2表的记录组合来说,对t3表进行单表查询
if row satisfies join conditions, send to client
}
}
}
基于块的循环嵌套连接
扫描表的过程需要将磁盘上块的记录加载到内存中,再逐一比较,为了减少连接过程中从磁盘加载到内存的次数,MySQL提出了一个join buffer的概念类似下面这样



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









