




Go Slice 万字拆解:从内存布局到扩容陷阱,带你重新了解 Slice
slice 的灵魂拷问
在讲解slice 之前,请先看以下问题,你可以带着问题去看slice,这样有助于加深对slice的印象,有的问题在本文讲解中会举例,单我希望大家能够动手敲一下。
问题一:请问调用前和调用后打印的内容分别是什么?
func Test_Question1(t *testing.T) {
s := make([]int, 3, 5)
s[0] = 1
s[1] = 2
s[2] = 3
t.Logf("调用前: %v", s)
modifySlice(s)
t.Logf("调用后: %v", s)
}
func modifySlice(s []int) {
s = append(s, 3, 4, 5)
}
问题二: 请问append后 该切片的len 和cap 分别是多少?打印元素是 [10]吗?
func Test_Question2(t *testing.T) {
s := make([]int, 10)
s = append(s, 10)
t.Logf("s: %v, len: %d, cap: %d", s, len(s), cap(s))
}
问题三: 和问题二一样
func Test_Question3(t *testing.T) {
s := make([]int, 0, 10)
s = append(s, 10)
t.Logf("s: %v, len: %d, cap: %d", s, len(s), cap(s))
}
问题四: 截取后的切片 len 和cap 分别是多少?
func Test_Question4(t *testing.T) {
s := make([]int, 10, 12)
s1 := s[8:]
t.Logf("s1: %v, len: %d, cap: %d", s1, len(s1), cap(s1))
}
问题五:s 和 s1 的切片内容是什么?
func Test_Question5(t *testing.T) {
s := []int{1, 2, 3, 4, 5}
s1 := s[1:3]
s1[0] = 99
t.Logf("修改后 s: %v, s1: %v", s, s1)
}
问题六:s 和 s1 的切片内容是什么?
func Test_Question6(t *testing.T) {
s := []int{1, 2, 3, 4, 5}
s1 := s[1:3]
s1 = append(s1, 99)
t.Logf("append后 s: %v, s1: %v", s, s1)
}
问题七:dst 复制了多少个元素?复制后的切片内容是什么?
func Test_Question7(t *testing.T) {
src := []int{1, 2, 3}
dst := make([]int, 2)
n := copy(dst, src)
t.Logf("dst: %v, 复制了 %d 个元素", dst, n)
}
问题八:通过for 循环赋值后,切片的内容是什么?
func Test_Question8(t *testing.T) {
s := []int{1, 2, 3}
for _, v := range s {
v = v * 10
}
t.Logf("修改后: %v , s)
}
问题九:请问下面count 等于几?
func Test_Question9(t *testing.T) {
s := []int{1, 2, 3}
count := 0
for _, v := range s {
count++
s = append(s, v)
}
t.Logf("最终 s: %v, 循环次数: %d", s, count)
}
问题十: s1 和 s2 的len 和cap 分别是多少?
func Test_Question14_ThreeIndexSlice(t *testing.T) {
s := []int{1, 2, 3, 4, 5, 6}
s1 := s[1:3] // 二参数
s2 := s[1:3:4] // 三参数
t.Logf("s1 (二参数): len=%d, cap=%d", len(s1), cap(s1))
t.Logf("s2 (三参数): len=%d, cap=%d", len(s2), cap(s2))
}
问题十一: 请问slice 修改前后修改后 打印的内容分别是什么?
func Test_Question11(t *testing.T) {
slice := []int{1, 2, 3}
fmt.Println("Before:", slice)
modifySlice1(slice)
fmt.Println("After:", slice)
}
func modifySlice1(s []int) {
s = append(s, 4)
s[0] = 100
fmt.Println("temp:", s)
}
问题十二: 同问题十一
func Test_Question12(t *testing.T) {
slice := make([]int, 3, 4)
slice[0] = 1
slice[1] = 2
slice[2] = 3
fmt.Println("Before:", slice)
modifySlice1(slice)
fmt.Println("After:", slice)
}
func modifySlice1(s []int) {
s = append(s, 4)
s[0] = 100
fmt.Println("temp:", s)
}
slice 的错误用法,严重可能会导致内存泄露!
错误用法一: append后底层数组地址改变,导致引用失效
func Test_DangerousUsage1(t *testing.T) {
original := make([]int, 3, 3)
original[0], original[1], original[2] = 1, 2, 3
// 获取原始底层数组的地址
originalPtr := &original[0]
t.Logf("原始数组地址: %p", originalPtr)
// 创建一个指向原数组某个元素的指针(模拟外部引用)
elementPtr := &original[1]
t.Logf("元素指针指向的值: %d, 地址: %p", *elementPtr, elementPtr)
// append 操作导致扩容,底层数组地址改变
newSlice := append(original, 4)
newPtr := &newSlice[0]
t.Logf("扩容后数组地址: %p", newPtr)
// 修改新切片的值
newSlice[1] = 999
t.Logf("修改新切片后,elementPtr 指向的值: %d (没有改变!)", *elementPtr)
t.Logf("新切片中的值: %d", newSlice[1])
}
错误用法二: 大切片的小子切片阻止gc回收,导致内存泄露
func Test_DangerousUsage2_SmallSliceBlocksLargeArrayGC(t *testing.T) {
// 模拟一个大数据处理场景
createLargeSliceAndReturnSmallPart := func() []byte {
// 创建一个很大的切片(模拟读取大文件或网络数据)
largeData := make([]byte, 1024*1024) // 1MB 数据
// 填充一些数据
for i := 0; i < len(largeData); i++ {
largeData[i] = byte(i % 256)
}
t.Logf("创建了 %d 字节的大数组", len(largeData))
// 错误做法:只返回前10个字节的子切片
// 这会导致整个 1MB 的数组无法被GC回收!
return largeData[:10]
}
// 正确做法的函数
createLargeSliceAndCopySmallPart := func() []byte {
largeData := make([]byte, 1024*1024)
for i := 0; i < len(largeData); i++ {
largeData[i] = byte(i % 256)
}
// 正确做法:复制需要的部分到新切片
result := make([]byte, 10)
copy(result, largeData[:10])
return result
}
// 错误用法
smallSlice1 := createLargeSliceAndReturnSmallPart()
t.Logf("错误方式 - 小切片长度: %d, 容量: %d", len(smallSlice1), cap(smallSlice1))
t.Logf("错误方式 - 小切片容量 = 大数组大小: %d", cap(smallSlice1))
// 正确用法
smallSlice2 := createLargeSliceAndCopySmallPart()
t.Logf("正确方式 - 小切片长度: %d, 容量: %d", len(smallSlice2), cap(smallSlice2))
}
错误用法三:并发环境下对切片的不安全操作
func Test_DangerousUsage3_ConcurrentSliceAccess(t *testing.T) {
sliceUnsafe := make([]int, 0, 10000)
wg := &sync.WaitGroup{}
wg.Add(2)
go func() {
defer wg.Done()
// 模拟一个协程添加5000个元素
for i := 0; i < 5000; i++ {
sliceUnsafe = append(sliceUnsafe, i)
}
}()
go func() {
defer wg.Done()
// 模拟另一个协程添加5000个元素
for i := 5000; i < 10000; i++ {
sliceUnsafe = append(sliceUnsafe, i)
}
}()
wg.Wait()
// 由于数据竞争,len(sliceUnsafe) 的结果是不确定的,可能小于10000
t.Logf("无锁并发append后,最终长度: %d (期望 10000,实际结果不确定)", len(sliceUnsafe))
t.Log("\n--- 正确示例: 使用 sync.Mutex 保护 ---")
sliceSafe := make([]int, 0, 1000)
mu := &sync.Mutex{}
wg.Add(2) // 重置 WaitGroup
go func() {
defer wg.Done()
for i := 0; i < 5000; i++ {
mu.Lock()
sliceSafe = append(sliceSafe, i)
mu.Unlock()
}
}()
go func() {
defer wg.Done()
for i := 5000; i < 10000; i++ {
mu.Lock()
sliceSafe = append(sliceSafe, i)
mu.Unlock()
}
}()
wg.Wait()
t.Logf("加锁并发append后,最终长度: %d (期望 10000)", len(sliceSafe))
}
第一章:Slice 它到底是什么?
好了,经过灵魂拷问之后,正式讲解slice的底层原理。Slice 它本身不存储任何数据,它只是一个“指针”结构体。它告诉我们去哪里(内存地址)、拿多少个(长度)、以及那块内存区域总共有多大(容量)。如下就是slice的结构:
// src/reflect/value.go
type SliceHeader struct {
Data uintptr // 指向底层数组的指针
Len int // 切片的长度
Cap int // 切片的容量
}
一个 slice 在运行时就是一个包含三个字段的结构体:
Data(uintptr): 这是一个指向内存的指针,它指向的是底层数组中,该切片所能访问到的第一个元素。注意,不一定是数组的第 0 个元素!Len(int): 切片的长度。也就是我们通过len()函数获取到的值。它表示这个slice中当前包含了多少个元素。Len不能超过Cap。Cap(int): 切片的容量。也就是我们通过cap()函数获取到的值。它表示从Data指针开始,到底层数组末尾,也就是该切片最多能够存储多少元素,这个字段决定你程序的性能,你知道为什么吗?
让我们用一张图来把这个关系形象化:
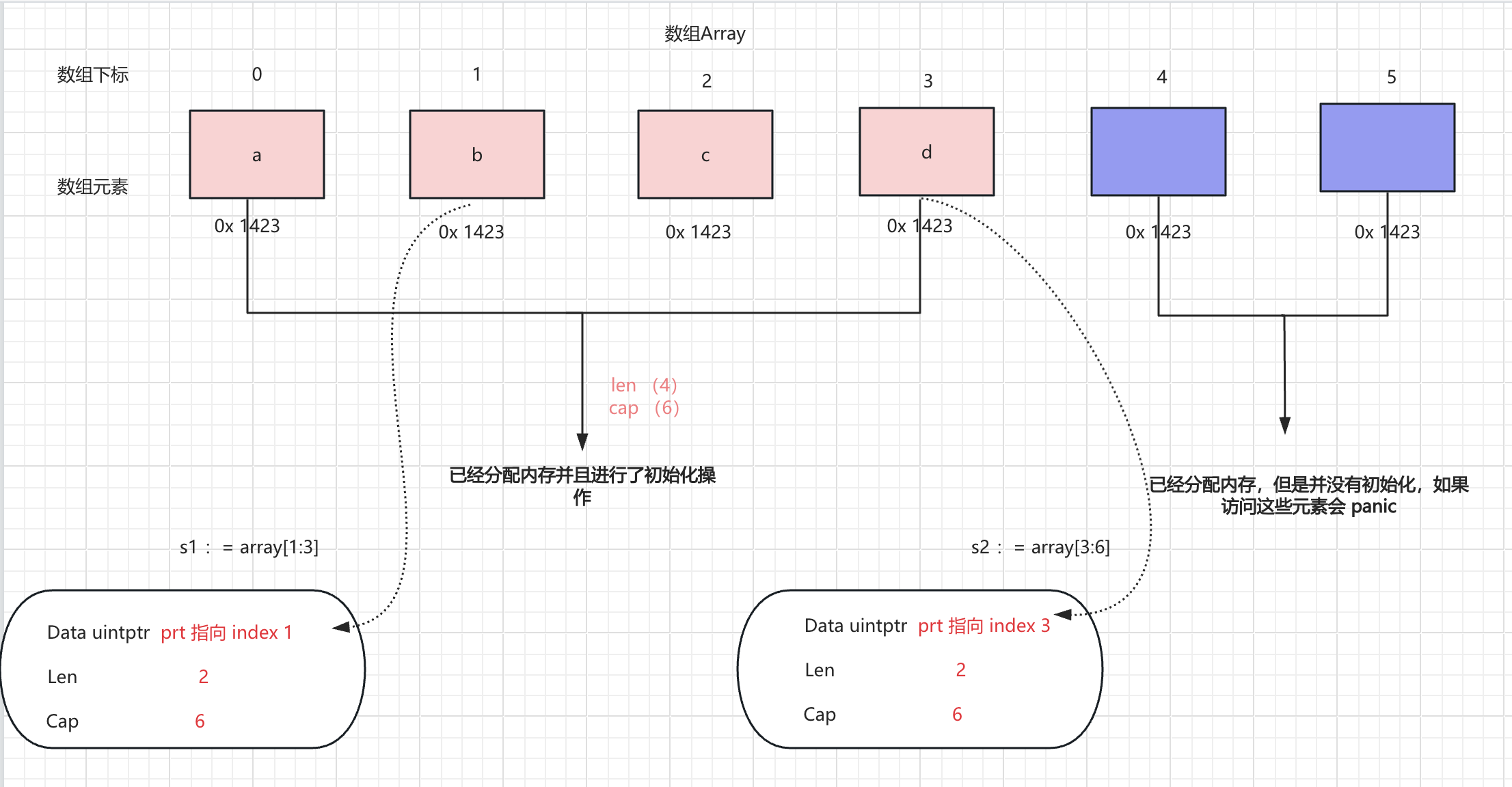
这张图揭示了几个核心要点:
- 共享底层数组:
s1和s2是两个完全不同的slice变量,但它们可以指向同一个底层数组。 - 修改的联动效应:如果你执行
s1[0] = 'Z',那么你实际上修改的是底层数组索引为 2 的那个元素。此时,如果你打印s2,你会发现它变成了['a', 'b', 'Z', 'd']。即修改底层数组会同步修改所有引用该数组的切片。在问题五中 s 和 s1 就是公用了一个底层数组,导致s1 修改 会影响s的切片内容。 Len和Cap的区别:Len是“你现在能用多少”,Cap是“你最多能用多少,如果事先能预估cap数量,尽量进行预分配,防止因为频繁扩容导致性能下降。这也就是为什么该字段和性能相关。
理解了 SliceHeader,接下来,我们看看他是如何被创建出来的。
第二章:创建 Slice —— make 和字面量
创建 slice 主要有两种方式:通过字面量(literal)和通过 make 函数。它们的底层行为略有不同。
1. 字面量初始化
s := []int{10, 20, 30}
这是我们最常用的方式之一。当我们这么做的时候,Go 编译器会帮我们完成两件事:
- 在内存中创建一个匿名的、大小刚刚好的底层数组,用于存储
{10, 20, 30}。 - 创建一个
SliceHeader,其Data指针指向这个数组的开头,Len和Cap都设置为 3。
这种方式非常直接,Len 和 Cap 总是相等的。
2. make 函数
make 函数为我们提供了更精细的控制。它接受两个或三个参数:类型、长度,以及可选的容量。对应的是问题二和问题三,看完这章节,这两个问题就迎刃而解。下面是两中make 使用用例:
// 方式一:只指定长度
s1 := make([]int, 5) // len=5, cap=5
s1 = append(s1,4)
// 方式二:同时指定长度和容量
s2 := make([]int, 0, 10) // len=5, cap=10
方式一:有很多新手栽进去,他们想要的结果是 [4] 但是实际切片的内容是[0,0,0,0,0,4],因为指定的长度为5,所以它会预分配5个为0 的元素,使用方式二就能完美解决问题。
make的存在,就是为了处理那些“预知未来”的场景。比如,你知道你马上要往一个slice 里添加大约 1000 个元素,那么预先分配足够的容量 (make([]int, 0, 1000)) 就可以极大地提升性能,避免后续 append` 操作中频繁的内存分配和数据拷贝。
那么,make 在底层又做了什么呢?让我们深入到 runtime 的源码中一探究竟。
当我们调用 make([]T, len, cap) 时,编译器会将其转换为对 runtime.makeslice 函数的调用。其签名如下:
// src/runtime/slice.go
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 1. 计算需要的内存大小
// math.MulUintptr 会检查乘法是否溢出
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// 如果内存请求过大或参数非法,就会 panic
// ... panic a lot ...
mem, overflow = math.MulUintptr(et.size, uintptr(len))
// ... more checks ...
panic(errorString("makeslice: " + itoa(len) + " > " + itoa(cap)))
}
// 2. 调用真正的内存分配函数
return mallocgc(mem, et, true)
}
- 内存计算与检查:它首先会根据
slice的元素类型et(_type是 Go 运行时的内部类型表示)的大小(et.size)和我们指定的容量cap,计算出总共需要分配多少字节的内存。这里用math.MulUintptr是为了防止整数溢出,非常严谨。同时,它会进行一系列的边界检查,比如len不能为负、len不能大于cap、总内存不能超过maxAlloc等。如果检查不通过,程序就会panic。 - 内存分配:核心步骤是调用
mallocgc。这个函数是 Go 内存分配器的核心,它负责从堆(heap)上申请一块连续的内存。mallocgc的名字也暗示了它的职责:malloc(分配)和gc(garbage collection,垃圾回收)。它分配的内存块会被垃圾回收器所管理。 - 返回指针:
makeslice返回一个unsafe.Pointer,这是一个通用的指针类型,它将作为SliceHeader的Data字段。调用make的外层逻辑会用这个指针,以及我们传入的len和cap,组装成一个完整的slice并返回。
第三章:append 的扩容陷阱
Golang 引用传递和值传递
首先,我们先把引用传递和值传递这两个弄清楚,在Golang 语言中所有的函数参数传递都是值传递,不存在真正意义上的引用传递,其实我们在讨论引用传递时,实际上是在讨论传递一个"引用类型"的值来实现类似引用传递的效果!
- 值传递核心思想:函数接收的是调用者所提供变量的一个副本(Copy)。在函数内部对这个副本进行任何修改,都不会影响到函数外部的原始变量,例如Go中
所有的基本类型都是值传递。
基本类型实现引用类型的效果: 既然Go 只有值传递,那么怎么才能实现在函数内部修改外部变量呢?答案是:使用指针,指针本身是一个变量,它存储的是另一个变量的内存地址。当我们把指针作为参数传递给函数时,Go 依然是进行值传递,只不过这次复制的是指针的值,也就是那个内存地址。
举例:这好比你把你的家庭住址写在一张纸条上给了我。我拿到的是地址的复印件(纸条),但我可以根据这个地址找到你的家,然后改变你家里的布局。地址本身(纸条上的文字)我没法改,但你家里的东西我能动 - 引用传递:在Golang中 slice, map, channel 这三种类型被称为引用类型,下面我将重点讲解 slice的
"引用传递"
我们来回忆一下问题十二:
func Test_Question12(t *testing.T) {
slice := make([]int, 3, 4)
slice[0] = 1
slice[1] = 2
slice[2] = 3
fmt.Println("Before:", slice) s[1,2,3]
modifySlice1(slice)
fmt.Println("After:", slice) s[100,2,3]
}
func modifySlice1(s []int) {
s = append(s, 4)
s[0] = 100
fmt.Println("temp:", s) s[100,2,3,4]
}
运行结果如下:
=== RUN Test_Question12
Before: [1 2 3]
temp: [100 2 3 4]
After: [100 2 3] 这里并没有append 4 why?
--- PASS: Test_Question12 (0.00s)
在上面的示例中,我们定义了一个 modifySlice 函数,它接收一个切片作为参数。在函数内部,我们追加一个新的元素 4,并将第一个元素修改为 100。
我们打印输出原始切片 slice,可以看到修改已经影响了原始切片的内容,slice 是引用类型,他们公用的同一个数组,函数内部对切片的修改会影响原始切片。但是并没有添加新元素,为什么会出现这种情况呢? 先带你重温一下 SliceHeader 的结构,如下所示:
// src/reflect/value.go
type SliceHeader struct {
Data uintptr // 指向底层数组的指针
Len int // 切片的长度
Cap int // 切片的容量
}
之前我们讲过Golang 中所有的函数参数传递都是值传递,slice 是特殊的"引用传递" ,当我们传递一个 slice 时,实际上是复制了它的 SliceHeader。这个副本 Header 和原始 Header 包含了一个指向同一个底层数组的指针,以及各自独立的长度(Len)和容量(Cap)字段。
然后在modifySlice1 函数中修改了切片的长度(len),因他是值传递,函数内部修改不会影响外部的长度(len),这就是为什么外部的切片没有append 新元素 。
那么我们如果在外部看到append 之后的内容呢? 最好的办法就是将修改之后的切片返回。
弄明白值传递和引用传递之后,下面讲解一下append 的行为的两种情况:
情况一:容量(Capacity)足够
当底层数组的容量减去 slice 的长度后,剩余的空间足够容纳要添加的新元素时,只需要将元素赋值到数组上即可。下面是问题六的解析。
arr := [5]int{1, 2, 3, 4, 5}
s := arr[1:3] // len=2, cap=4. 内容是 [2, 3]
fmt.Printf("Before append: len=%d, cap=%d, data=%v\n", len(s), cap(s), s)
s = append(s, 99) // 添加一个元素
fmt.Printf("After append: len=%d, cap=%d, data=%v\n", len(s), cap(s), s)
fmt.Println("Original array:", arr)
// 输出:
// Before append: len=2, cap=4, data=[2 3]
// After append: len=3, cap=4, data=[2 3 99]
// Original array: [1 2 3 99 5]
在这个例子中:
s := arr[1:3]创建切片,其初始len=2,cap=4,内容是 [2, 3]。它与 arr 共享底层数组。append(s, 99)时,因cap > len,容量充足,不发生扩容,直接在底层数组上操作。- 新元素 99 被放入底层数组 arr 的索引 3 位置,arr 变为 [1, 2, 3, 99, 5]。
append返回一个 len 更新为 3 的新SliceHeader,并重新赋值给 s。最终 s 的内容是 [2, 3, 99]。
这就是最经典的“扩容陷阱”我们只是想给 s 添加一个元素,结果却把 arr 的数据给“污染”了。这是因为 s 和 arr 共享了同一个底层数组,而 s2 在 append 时,它的容量(cap=2)是足够的,所以 Go 选择了原地修改,直接动了底层数组的数据。
陷阱:当多个
slice共享一个底层数组时,任何一个slice的append操作,只要没发生扩容,都有可能修改其他slice能看到的数据
如何规避这个陷阱?
Go 提供了一种被称为 “full slice expression” 的语法糖 s[i:j:k],它可以让我们在切片时,主动限制新 slice 的容量。
s1 := []int{1, 2, 3, 4, 5}
// 第三个参数 k 用来限制新 slice 的 cap
// 新 slice 的 cap = k - i
s2 := s1[1:2:3] // i=1, j=2, k=3
// len = j - i = 2 - 1 = 1
// cap = k - i = 3 - 1 = 2
// data = [2]
s3 := s1[1:2] // 作为对比
// len = 1
// cap = 5 - 1 = 4
// data = [2]
通过 s1[1:2:3],我们创建的 s2 的容量被限制为 2。如果我们再对 s2 进行 append,它就会因为容量不足而触发扩容,从而分配新的底层数组,与 s1 “解耦”。
情况二:容量(Capacity)不足
当 append 发现现有容量不够放下新元素时,它就会自动扩容,这也是 slice 被称为“动态数组”的核心原因。
// src/runtime/slice.go @ Go 1.24
// growslice 的调用约定比较特别,它接收旧指针、新长度、旧容量等分散的参数
// 返回一个组装好的新 slice 结构体
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
// ... 前置安全检查 ...
// 计算新容量的核心逻辑在 nextslicecap 函数中
newcap := nextslicecap(newLen, oldCap)
// ... 针对不同元素大小进行优化的内存计算 ...
// var lenmem, newlenmem, capmem uintptr
// ...
// capmem = roundupsize(capmem, noscan) // 内存规格对齐
// newcap = int(capmem / et.Size_) // 根据对齐结果反算真实容量
// ...
var p unsafe.Pointer
if !et.Pointers() { // 检查类型是否不含指针
p = mallocgc(capmem, nil, false) // 请求未清零的内存
// 将旧数据拷贝后,手动清理新分配内存中未被覆盖的尾部
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else { // 类型包含指针
p = mallocgc(capmem, et, true) // 请求已清零的内存,保证GC安全
// 如果开启了写屏障,执行一次性的批量写屏障操作
if writeBarrier.enabled {
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(oldPtr), lenmem, et)
}
}
// 将旧数组的内容整体搬迁到新数组
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}
}
// nextslicecap 封装了新版本的扩容策略
func nextslicecap(newLen, oldCap int) int {
newcap := oldCap
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen // 如果一次追加太多,直接满足需求
return newcap
}
const threshold = 256 // 新的阈值是 256,而不是 1024
if oldCap < threshold {
newcap = doublecap // 小于阈值,容量翻倍
return newcap
}
// 大于阈值后,采用更平滑的增长策略,接近 1.25x
for {
newcap += (newcap + 3*threshold) >> 2
if uint(newcap) >= uint(newLen) {
break
}
}
// 处理溢出情况
if newcap <= 0 {
return newLen
}
return newcap
}
growslice 的工作流程(Go 1.24 版)可以概括为:
-
确定新容量:
- 这部分逻辑被清晰地封装在新的
nextslicecap函数中。 - 首先,
growslice会检查期望的新长度newLen是否大于当前容量的两倍 (doublecap)。如果是(意味着一次append了大量元素),新容量就直接采用newLen,保证能装下。 - 如果不是,则进入标准的扩容策略:
- 新的阈值是 256。如果旧切片的容量小于 256,新容量会直接翻倍 (
newcap = doublecap)。这保证了小切片能快速成长,避免初期频繁的内存分配。 - 一旦旧切片容量超过或等于 256,增长因子就会变得更平滑。它采用
newcap += (newcap + 3*threshold) >> 2的公式,增长率从~1.44x(在256时) 逐渐收敛到 1.25x。相比旧版固定的 1.25 倍,这个公式在过渡阶段更平滑,也兼顾了效率与内存浪费。
- 新的阈值是 256。如果旧切片的容量小于 256,新容量会直接翻倍 (
- 这部分逻辑被清晰地封装在新的
-
内存计算与规整:
- Go 会根据元素类型的大小(
et.Size_)进行针对性优化,对大小为1、指针大小、2的幂等情况使用位移代替乘法来计算所需内存,效率更高。 - 计算出的理论内存大小会通过
roundupsize函数进行向上规整。这意味着你实际得到的容量可能会比策略计算的略大一些,这样做是为了减少内存碎片,提高分配效率。
- Go 会根据元素类型的大小(
-
分配新数组并拷贝数据:
- 调用
mallocgc分配一块全新的、更大的内存空间。 - 区分处理指针类型:
- 如果元素不含指针,
mallocgc会申请一块未清零的内存(性能优化),并在数据拷贝后,手动使用memclrNoHeapPointers清理新空间中未被使用的“尾巴”。 - 如果元素包含指针,必须申请已清零的内存来保证GC安全。并且,在拷贝数据前,会调用
bulkBarrierPreWriteSrcOnly执行一次批量写屏障。这比旧版本逐个元素进行typedmemmove的方式要高效得多。
- 如果元素不含指针,
- 最后,统一使用高度优化的
memmove函数,将旧底层数组中的数据原封不动地一次性拷贝到新的底层数组中。
- 调用
-
返回新
slice:growslice会用指向新数组的指针p、调用者传入的新长度newLen和计算出的新容量newcap,组装成一个新的slice结构体并返回。
现在,append 必须使用 s = append(s, ...) 接收返回值的原因也水落石出了。因为当发生扩容时,append 返回的是一个全新的 slice 值——它的 array 指针指向了一块全新的内存,它的 cap 也变了(甚至 len 也变了)。如果你不接收这个返回值,旧的slice 变量仍然指向那块已经被“遗弃”的数组,对新添加的元素一无所知。
第四章:万恶之源?切片导致的内存泄漏
让我们来看一个非常典型的测试用例,它模拟了这种内存泄漏的场景。
场景复现 错误用法二:大切片的小“后代”阻止GC回收
func Test_DangerousUsage2_SmallSliceBlocksLargeArrayGC(t *testing.T) {
// 模拟一个大数据处理场景的“错误”函数
createLargeSliceAndReturnSmallPart := func() []byte {
// 创建一个很大的切片(模拟一次性读取大文件或网络响应)
largeData := make([]byte, 1024*1024) // 1MB 数据
// 可以在此填充一些数据...
// for i := 0; i < len(largeData); i++ {
// largeData[i] = byte(i % 256)
// }
t.Logf("在函数内部,创建了 %d 字节的大数组", len(largeData))
// 错误做法:直接返回前10个字节的子切片
// 这将导致整个 1MB 的底层数组无法被GC回收!
return largeData[:10]
}
// “正确做法”的函数
createLargeSliceAndCopySmallPart := func() []byte {
largeData := make([]byte, 1024*1024) // 同样创建 1MB 数据
// 正确做法:将需要的部分,复制到一个全新的、大小合适的切片中
result := make([]byte, 10)
copy(result, largeData[:10])
// 函数返回后,largeData 将可以被安全回收
return result
}
// --- 测试开始 ---
// 调用错误用法的函数
smallSlice1 := createLargeSliceAndReturnSmallPart()
t.Logf("错误方式 -> 小切片 长度: %d, 容量: %d", len(smallSlice1), cap(smallSlice1))
t.Logf("错误方式 -> 它的容量,就是最初那个大数组的大小: %d", cap(smallSlice1))
// 调用正确用法的函数
smallSlice2 := createLargeSliceAndCopySmallPart()
t.Logf("正确方式 -> 小切片 长度: %d, 容量: %d", len(smallSlice2), cap(smallSlice2))
}
在上面的测试代码中,createLargeSliceAndReturnSmallPart函数模拟了一个常见操作:加载一个大数据块(这里是 1MB 的 largeData),然后我们只需要前10个字节。
我们想要的是,当这个函数执行完毕后,largeData 这个 1MB 内存就应该被回收了,我们只需要保留那 10 个字节的数据。
但现实是残酷的。
只要函数返回的 smallSlice1 还在被使用(哪怕它只是一个局部变量,或者被一个长时间存活的 goroutine 引用),那个 1MB 的 largeData 底层数组就 永远不会被垃圾回收器(GC)释放。
为什么会这样?
答案就在我们第一章学习的 slice 结构体里。执行 return largeData[:10] 这个切片表达式时,Go 并没有创建新的数据,它只是创建了一个新的 slice 头:
smallSlice1 的 slice 结构体
+-------------------------------------------------+
| array: (指针,指向 largeData 底层数组的起始地址) |
| len: 10 |
| cap: 1024 * 1024 | // 容量是整个底层数组的大小!
+-------------------------------------------------+
Go 的 GC 在进行垃圾回收时,会检查当前所有存活的变量。它会发现 smallSlice1 还没有生命终结,然后顺着 smallSlice1.array 指针,找到了那个 1MB 的底层数组。由于这个数组的地址被一个存活的切片引用着,GC 自然就不会进行回收
于是,你那区区 10 字节的切片,就像一根细细的、看不见的绳子,牢牢地拴住了 1MB 的内存,导致了事实上的内存泄漏。在处理GB级别大文件的场景中,这种问题的影响会被急剧放大。
如何解开这根“绳子”?
测试用例中的 createLargeSliceAndCopySmallPart 函数已经给出了标准答案:复制。
// 正确做法:将需要的部分,复制到一个全新的、大小合适的切片中
result := make([]byte, 10)
copy(result, largeData[:10])
return result
这种做法的核心思想是:
- 使用
make([]byte, 10)创建一个全新的、容量和长度都刚好是10的切片result。 - 使用
copy函数,将largeData中需要的前10个字节,拷贝到result的底层数组中。 - 返回
result。
现在,返回的 smallSlice2 的 slice 结构体是这样的:
smallSlice2 的 slice 结构体
+-----------------------------------------------+
| array: (指针,指向一个全新的、10字节大小的数组) |
| len: 10 |
| cap: 10 |
+-----------------------------------------------+
它与原来的 1MB largeData 已经没有任何关系了。当 createLargeSliceAndCopySmallPart 函数返回后,largeData 不再被任何存活的对象引用,GC 就可以回收1MB内存。
Go 1.22 版本之后,标准库新增的 slices.Clone 函数,就是这个“创建并复制”操作的优雅封装,可以让我们更方便地写出安全的代码。
总结
本文深入剖析了 Go 语言核心数据结构 slice 的内部机制。核心要点可以归纳如下:
-
本质是结构体:
slice本身并非动态数组,而是一个名为SliceHeader的结构体,包含三部分:Data:一个指向底层数组的指针。Len:切片中元素的数量,用户可见的长度。Cap:从Data指针开始,到底层数组末尾的总容量。
slice的所有操作都围绕这三个字段展开。
-
传递机制:Go 中所有参数传递均为值传递。当传递
slice时,是完整复制了它的SliceHeader结构体。因为副本内的指针与原slice指向同一个底层数组,所以修改元素会影响彼此,呈现出“引用传递”的效果。但当append导致扩容时,会返回一个全新的SliceHeader,必须通过s = append(s, ...)接收,否则调用方将丢失变更。 -
扩容策略 (以 Go 1.24 为例): 当
cap不足时,append会触发growslice函数进行扩容。其策略为:- 预估容量:首先计算出至少需要的新长度
newLen。 - 超量增长:如果期望的
newLen大于旧容量oldCap的两倍,则新容量newCap直接采用newLen。 - 小切片翻倍:如果
oldCap小于 256,newCap直接翻倍,即2 * oldCap。 - 大切片平滑增长:如果
oldCap大于等于 256,会进入一个循环,每次让容量增加约(旧容量 / 4),即newcap += (newcap + 3*256) >> 2,直至满足newLen的要求。这个增长因子会从约 1.44x 逐渐收敛到 1.25x。
- 预估容量:首先计算出至少需要的新长度
-
常见陷阱与最佳实践:
- 内存泄漏:从一个大的底层数组创建小切片,会导致整个大数组无法被 GC 回收。正确的做法是使用
copy函数,将所需数据拷贝到新的、大小合适的切片中,从而切断与旧数组的关联。 - 并发安全:
slice不是并发安全的。在多个 goroutine 中对同一个slice进行写入或append操作,必须使用sync.Mutex等同步原语进行保护,否则会引发数据竞争。
- 内存泄漏:从一个大的底层数组创建小切片,会导致整个大数组无法被 GC 回收。正确的做法是使用



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











