









 本文介绍DuLa-Net网络,用于从单RGB全景图估计房间布局。它使用等距全景图和透视天花板图,提出2分支特征融合方法,对多角度复杂布局房间效果好。文中阐述网络结构、布局估计步骤和实验结果,指出其进步与局限,并给出发展建议。
本文介绍DuLa-Net网络,用于从单RGB全景图估计房间布局。它使用等距全景图和透视天花板图,提出2分支特征融合方法,对多角度复杂布局房间效果好。文中阐述网络结构、布局估计步骤和实验结果,指出其进步与局限,并给出发展建议。
DuLa-Net: A Dual-Projection Network for Estimating Room Layouts from a Single RGB Panorama (CVPR 2019)
pdf下载 项目地址
使用等距全景图和透视天花板图,各自一个encode-decoder分支,提出新颖的2分支特征融合方法。对于多角度复杂布局的房间效果较好。
2021 4.1 update
原作者没提供训练代码,借鉴layout训练代码,为dula-net增加了训练代码
fork地址:https://github.com/zhigangjiang/DuLa-Net


主要贡献
- 提出在2个视图上进行2分支端到端学习,最后2分支进行特征融合。
- NN直接输出二维平面图的概率图。后处理比较少。
- 引入Realtor360数据集,包含多角点的复杂房间布局。
相关
这个研究方向分为3个不同点:
- 假设房间布局是曼哈顿世界,即房间的墙都是垂直于全局坐标系。更强的约束是房间时4个墙角的盒子。本论文支持多角点,但还是基于曼哈顿世界假设,即墙角都是直角。
- 输入图片类型,根据Fov的设置,有Fov为360的全景图和正常拍摄的透视图。还有是否带深度信息。
- 方法上很大程度取决于输入图片的类型,其中单帧的RGB图像是很难处理。有使用几何方法:寻找墙性和墙角,使用语义分割,最后通过优化在众多假设中选择合理。而最近使用基于NN的方法取得很大进步。本论文通过概率图+曲线拟合就能得到结果。
除了LayoutNet之外,大多数方法都依赖于利用现有的技术,在从输入全景图中提取的样本上获取单视角图像。这是LayoutNet具有优越性能的一个主要原因,因为它对全景图进行了整体预测,从而提取了更多的全局信息,使输入的全景图可能包含这些信息。
本文一个核心思想是使用天花板视图具有更少杂音。和全景视图进行联合学习。
网络结构
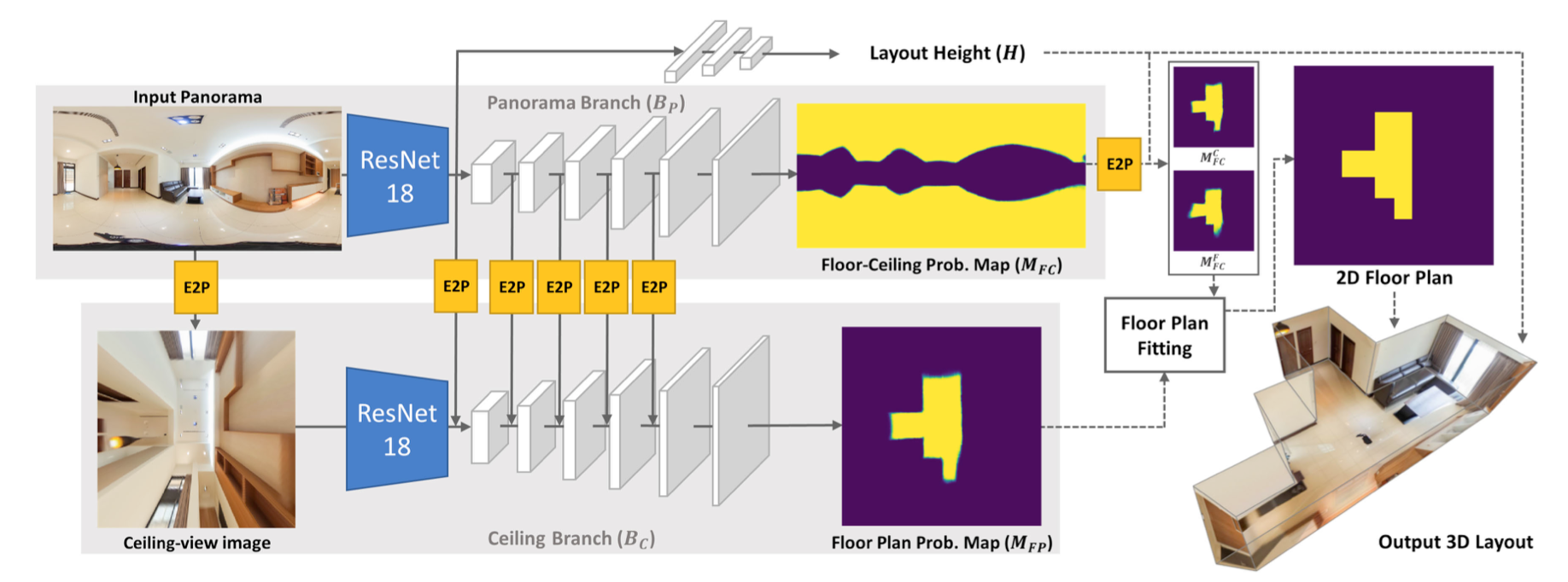
输入图片是等距柱状投影图(Equirectangular projection),预处理使用PanoContext进行垂直矫正。主要思想就是搜索直线,使其对齐全局坐标系。
天花板视图:摄像机看向上方,Fov取160,包含天花板墙线
地板视图:摄像机看向下方,Fov取160,包含地板板墙线
全局视图:摄像机看前看Fov取360,包含天花板墙线和地板墙线
E2P得到的就是天花板视图,2个分支:
- 全景图分支预测floor-ceiling proba- bility map和height
- 天花板视图得到天花板墙线,但是作为floor plan probability map
- 融合:floor-ceiling proba- bility map + floor plan probability map,在2D上曼哈顿假设,3个概率图进行加权平均。最后通过预测的房间高度恢复3D布局。
E2P(类似得到6面图的顶面)
UV坐标表示:
(
p
x
′
,
p
y
′
)
,
−
1
≤
p
x
′
≤
1
,
−
1
≤
p
y
′
≤
1
\left(p_{x}^{\prime}, p_{y}^{\prime}\right),-1 \leq p_{x}^{\prime} \leq 1,-1 \leq p_{y}^{\prime} \leq 1
(px′,py′),−1≤px′≤1,−1≤py′≤1
和球面坐标对应关系:
(
p
x
′
,
p
y
′
)
=
(
arctan
2
(
s
x
s
z
)
π
,
arcsin
(
s
y
)
0.5
π
)
\left(p_{x}^{\prime}, p_{y}^{\prime}\right)=\left(\frac{\arctan _{2}\left(\frac{s_{x}}{s_{z}}\right)}{\pi}, \frac{\arcsin \left(s_{y}\right)}{0.5 \pi}\right)
(px′,py′)=⎝⎛πarctan2(szsx),0.5πarcsin(sy)⎠⎞
这是右手坐标系,y轴查下,z+轴对应全景图左边x=-1和右边x=1,z-轴对应全景图中间x=0处
如果要取天花板视图,在y=-1处截取。
网络结构
Encoder
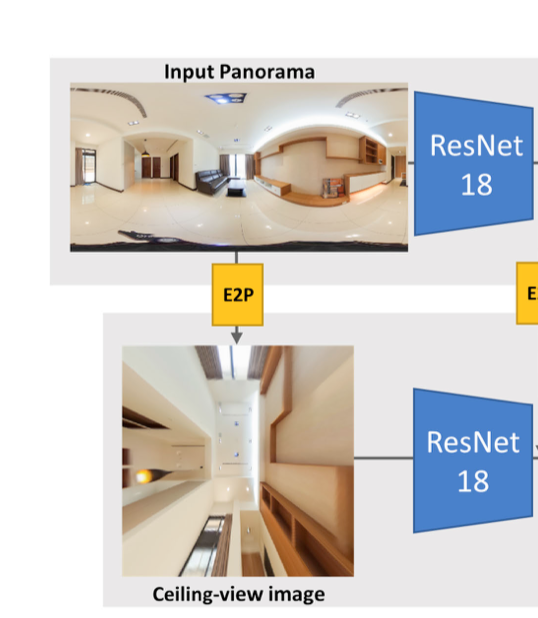
基于ResNet-18的两个分支:
E
B
P
E_{B_{P}}
EBP输入:全景图
512
×
1024
×
3
512 \times 1024 \times 3
512×1024×3, 输出
16
×
32
×
512
16 \times 32 \times 512
16×32×512
E B C E_{B_{C}} EBC输入:天花板透视图(使用E2P,Fov=160) 512 × 512 × 3 512 \times 512 \times 3 512×512×3,输出: 16 × 16 × 512 16 \times 16 \times 512 16×16×512
作者尝试ResNet-50,效果没有改善。
Decoder
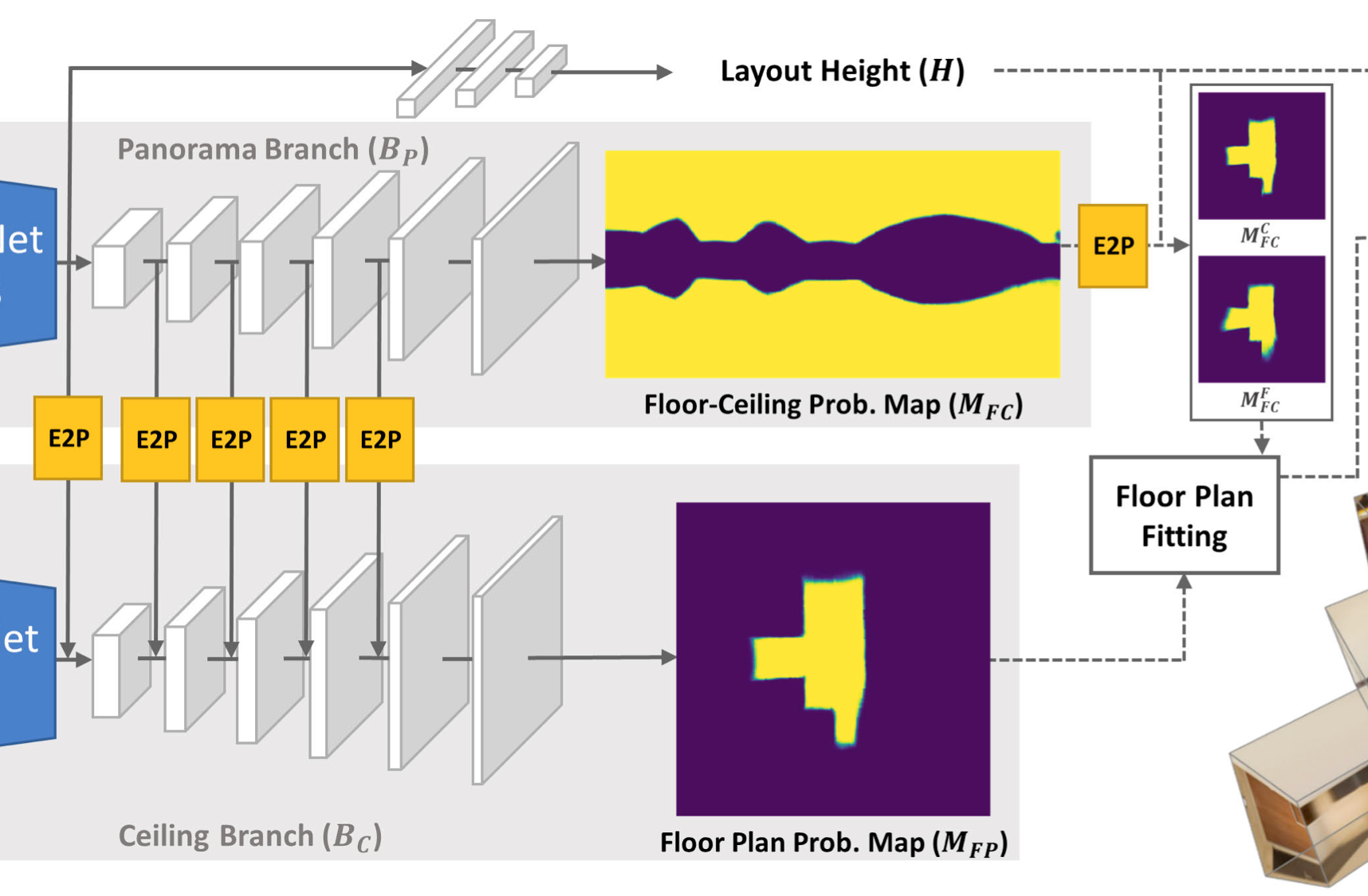
由6个卷积层,前5个是 3 × 3 resize convolutions,最后一个是 3 × 3 regular convolution。为了推理高度,在 B P B_P BP的中间特征出添加3个全连接层。 E B P E_{B_{P}} EBP的输出是 16 × 32 × 512 16 \times 32 \times 512 16×32×512,应用verage pooling得到512维输入全连接。为了增加robust,全连接后2层使用了dropout。最后输出的就是 M F C M_{F C} MFC,floor-ceiling proba- bility map。 B C B_C BC输出 M F P M_{F P} MFP,floor plan probability map 。
需要注意的是 B P B_P BP也输出了height,通过 M F C M_{F C} MFC可以估算平均高度。
Feature fusion
使用特征融合可以提升准确度,作者认为对于
B
C
B_C
BC分支,再靠近边缘的地方扭曲会非常严重,影响精度。特征融合时在
B
P
B_P
BP和
B
C
B_C
BC的前5个卷积层:
f
B
C
∗
=
f
B
C
+
α
β
i
×
f
B
P
,
i
∈
{
0
,
1
,
2
,
3
,
4
}
f_{B_{C}}^{*}=f_{B_{C}}+\frac{\alpha}{\beta^{i}} \times f_{B_{P}}, i \in\{0,1,2,3,4\}
fBC∗=fBC+βiα×fBP,i∈{0,1,2,3,4}
其中,
f
B
C
f_{B_{C}}
fBC是
B
P
B_P
BP特征做了E2P后输出。
α
\alpha
α 和
β
\beta
β是衰减系数。
Loss function
L = E b ( M F C , M F C ∗ ) + E b ( M F P , M F P ∗ ) + γ E L 1 ( H , H ∗ ) L=E_{b}\left(M_{F C}, M_{F C}^{*}\right)+E_{b}\left(M_{F P}, M_{F P}^{*}\right)+\gamma E_{L 1}\left(H, H^{*}\right) L=Eb(MFC,MFC∗)+Eb(MFP,MFP∗)+γEL1(H,H∗)
其中,带星号是真实值。
概率图使用二分类交叉熵损失:
E
b
(
x
,
x
∗
)
=
−
∑
i
x
i
∗
log
(
x
i
)
+
(
1
−
x
i
∗
)
log
(
1
−
x
i
)
E_{b}\left(x, x^{*}\right)=-\sum_{i} x_{i}^{*} \log \left(x_{i}\right)+\left(1-x_{i}^{*}\right) \log \left(1-x_{i}\right)
Eb(x,x∗)=−i∑xi∗log(xi)+(1−xi∗)log(1−xi)
高度使用L1损失:
E
L
1
(
x
,
x
∗
)
=
∑
i
∣
x
i
−
x
i
∗
∣
E_{L 1}\left(x, x^{*}\right)=\sum_{i}\left|x_{i}-x_{i}^{*}\right|
EL1(x,x∗)=i∑∣xi−xi∗∣
布局估计
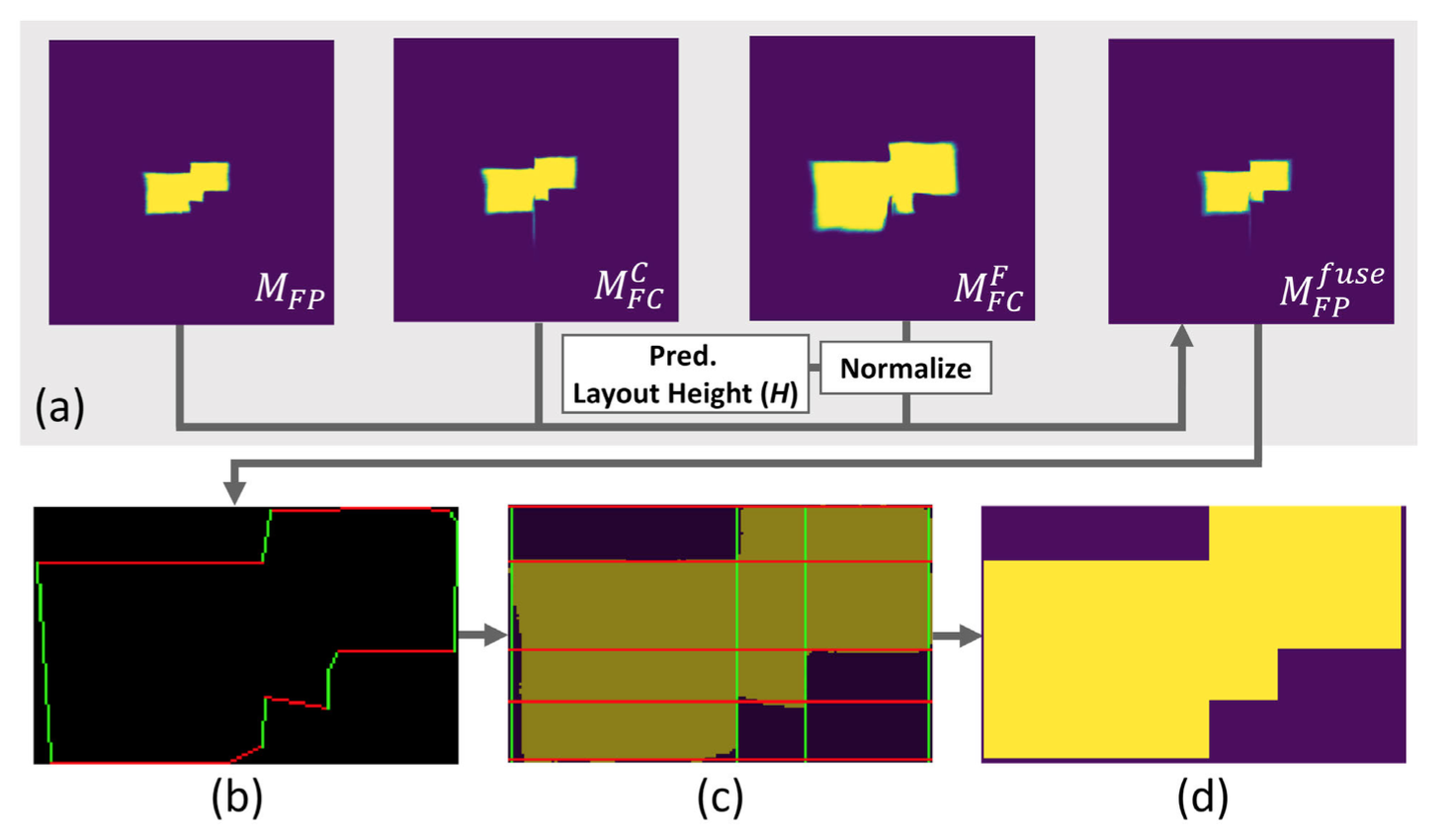
主要分为2步骤
- 使用概率图估计2D曼哈顿平面图
假设相机到地面高度固定为1.6m,那么相机到天花板的距离为 H − 1.6 H-1.6 H−1.6,由此可以得到 M F C F M_{F C}^{F} MFCF和 M F C C M_{F C}^{C} MFCC的比例为: 1.6 / ( H − 1.6 ) 1.6 /(H-1.6) 1.6/(H−1.6)
最终融合3个概率图:
M
F
P
f
u
s
e
=
0.5
∗
M
F
P
+
0.25
∗
M
F
C
C
+
0.25
∗
M
F
C
F
M_{F P}^{f u s e}=0.5 * M_{F P}+0.25 * M_{F C}^{C}+0.25 * M_{F C}^{F}
MFPfuse=0.5∗MFP+0.25∗MFCC+0.25∗MFCF
融合后的概率图进行二值化,阈值取0.5,取最大连通分量。
取连通分量的外轮廓使用 Douglas-Peucker 算法简化轮廓,得到简化边界后的二值图像b。
我们对边缘进行回归分析,并将它们聚成轴对齐的水平和垂直直线。这些直线划分成网格,图像c,单单元格的填充面积>0.5时合并到平面图形状里,图像d。
- 根据布局高度,沿着其法线得到3D布局
对于标注数据,作者专门开发了标注工具,先是使用已有方法故居深度图和线段,个人认为一种主动学习方法。然后利用这些数据初始化一个3D的曼哈顿世界布局。标注工具基于此进行调整。
实验结果

可以看见对于多角点的房间布局也可以进行估计,对于遮挡部分也能进行估计。

LayoutNet,只能预测4个点。
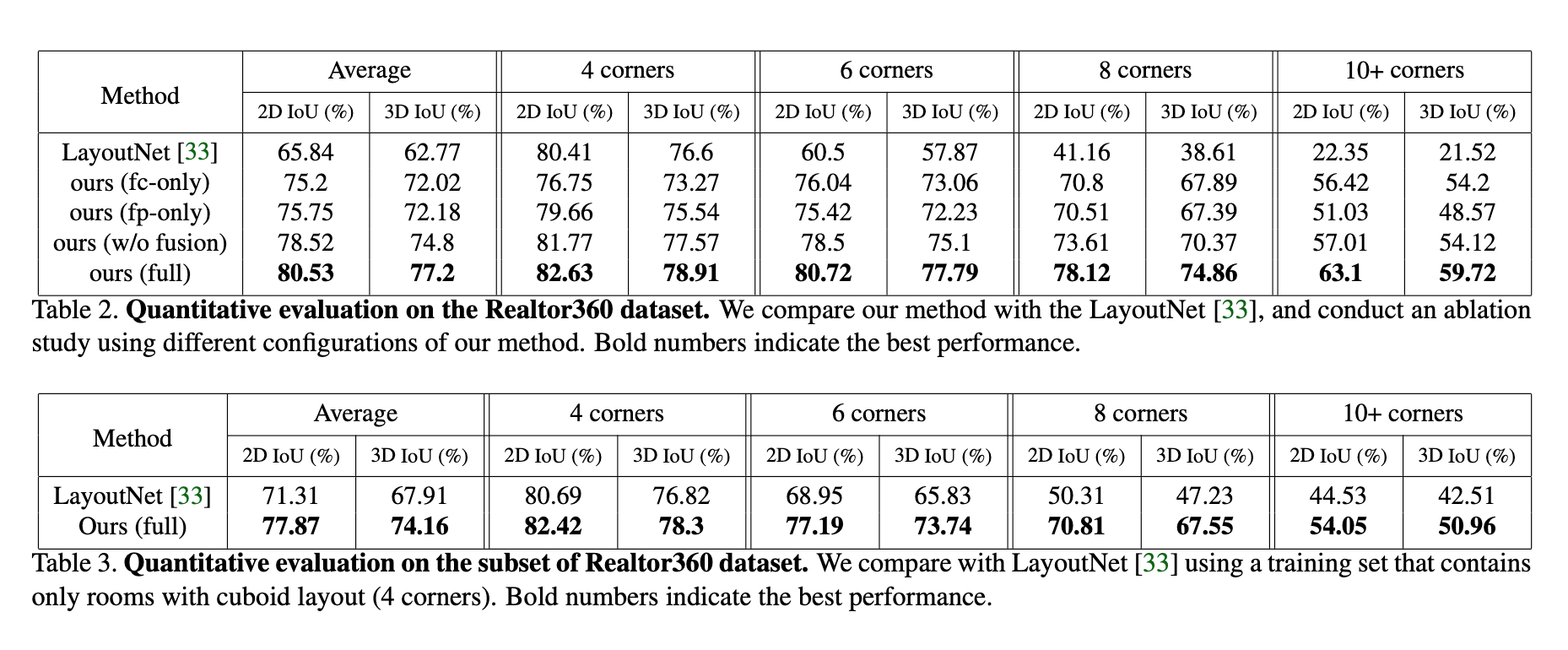
和LayoutNet相比,在多角点情况下提升明显。分支联合学习和特征融合都提升了准确度。
时间上,主要费时在垂直矫正阶段。
总结
本文的方法和以往相比确实进步很大,但是作者也提出限制:
- 会误认镜像和大物体遮挡
- 引入一些假设比如曼哈顿世界
作者提出发展建议:
- 进行语义分割,忽略遮挡物
- 移除曼哈顿世界假设,甚至考虑曲面墙
个人测试结果:
使用作者提供resnet18权重测试:
误差比较大情况:
而HorizonNet会更robust的多


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









