




分类器代码:
# 用于分类的输入向量是inX 其实就是一个点,输入的训练样本集为dataSet,标签向量为labels,K表示选择最近邻居的数目
# 分类器
def classify0(inX,dataSet,labels,k):
# 距离计算
dataSetSize=dataSet.shape[0] # 计算行数 shape返回是一个元组(行数,列数)
# dataSetSize,dataSetNumber = dataSet.shape # shape返回是一个元组(行数,列数)
# tile(a,reps) a是待输入数组,reps是a重复的次数(c,b) c是行上重复,b是列上重复
# eg:a=[1,2,3] b=tile(a,(2,1)) 结果:[[1 2 3][1 2 3]]
# x2-x1 y2-y1
diffMat=tile(inX,(dataSetSize,1))-dataSet
# x结果平方,y结果平方
sqDiffMat=diffMat**2
# x**2+y**2 axis=1行上求和 axis=0列上求和
sqDistances=sqDiffMat.sum(axis=1)
# 开根号
distances=sqDistances**0.5
# 排序 argsort() 排序返回数组值从小到大的索引值
sortedDistIndicies=distances.argsort()
# 统计各个类别的个数
classCount={}
# 选择距离最小的K个点
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]]
# dict.get(key, default=None)
# key -- 字典中要查找的键。default -- 如果指定键的值不存在时,返回该默认值值
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
# 排序 sort() 应用在list sorted() 应用在所有可迭代的对象进行排序操作 reverse=True 反向排序 key=lambda x
# operator.itemgetter[1] operator模块提供的itemgetter函数用于获取对象的哪些维的数据==list.index(1)
# 跟据下标为1的部分排序 即('B',2)中的2部分
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
创建DataSet
def createDateSet():
# 转换为矩阵
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels
调用:
group,labels=createDateSet()
sortedClassCount=classify0([0,0],group,labels,3)
print(sortedClassCount)
加载文本中的数据:
# 把文档中的数据入到array中
def file2matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
# 得到文本行数
numberOfLines=len(arrayOLines)
# 生成 array 相同大小的
returnMat=zeros((numberOfLines,3))
classLabelVector=[]
index=0
for line in arrayOLines:
line=line.strip()
listFromLine=line.split('\t')
returnMat[index,:]=listFromLine[0:3]
# 把分类的结果放到list中
classLabelVector.append(int(listFromLine[-1]))
index+=1
return returnMat,classLabelVector
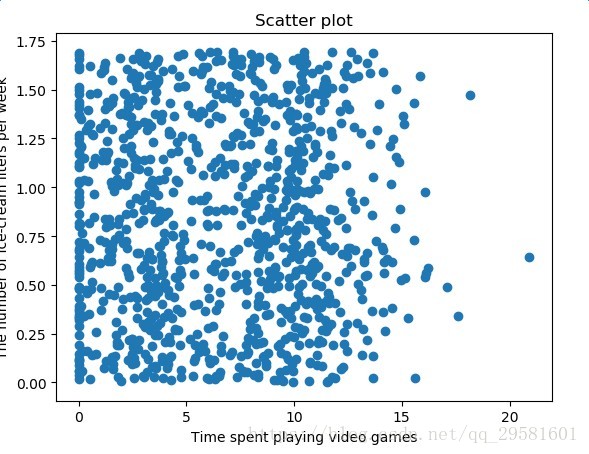
调用并显示矩阵第二列,第三列数据:
dataingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
fig=plt.figure()
# 添加子轴、图。subplot(m, n, p)或者subplot(mnp)此函数最常用:subplot是将多个图画到一个平面上的工具。其中,m表示是图排成m行,
# n表示图排成n列,也就是整个figure中有n个图是排成一行的,一共m行,
# 如果第一个数字是2就是表示2行图。p是指你现在要把曲线画到figure中哪个图上,最后一个如果是1表示是从左到右第一个位置。
ax=fig.add_subplot(111)
# 设置标题
ax.set_title('Scatter plot')
# 设置x轴标签
ax.set_xlabel("Time spent playing video games")
# 设置y轴标签
ax.set_ylabel("The number of ice-cream liters per week")
# 输出array的第一列x和第二列y
ax.scatter(dataingDataMat[:,1],dataingDataMat[:,2])
plt.show()
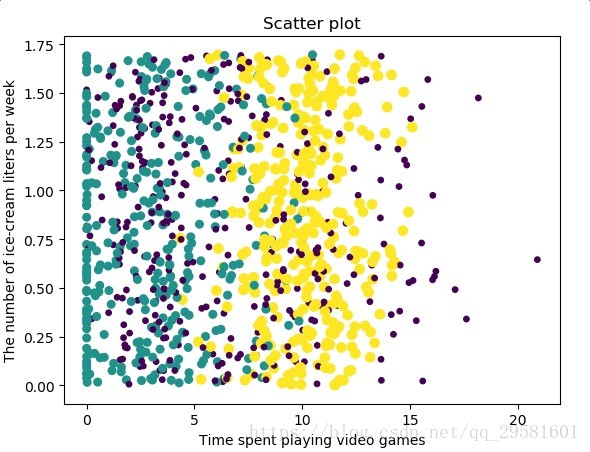
数据分类显示:
ax.scatter(dataingDataMat[:, 1], dataingDataMat[:, 2],15.0*array(datingLabels),15.0*array(datingLabels))
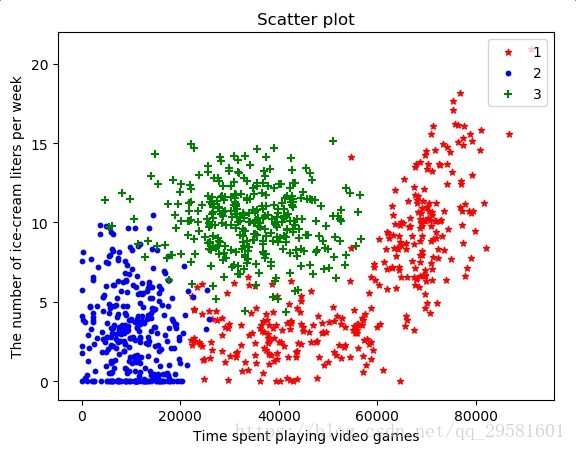
区分数据:
# 在散点图上绘制了色彩不等、尺寸不同的点,数据点所属三个样本分类的区域轮廓 红色的'*'表示类标签1、蓝色的'o'表示表示类标签2、绿色的'+'表示类标签3
datingLabels = array(datingLabels)
idx_1 = where(datingLabels == 1)[0][:]
ax.scatter(dataingDataMat[idx_1,0], dataingDataMat[idx_1,1], c='r', label='1',s=20,marker='*')
idx_2 = where(datingLabels == 2)[0][:]
ax.scatter(dataingDataMat[idx_2,0], dataingDataMat[idx_2,1], c='b', label='2',s=10,marker='o')
idx_3 = where(datingLabels == 3)[0][:]
ax.scatter(dataingDataMat[idx_3,0], dataingDataMat[idx_3,1], c='g', label='3',s=30,marker='+')
# 设置图标
plt.legend(loc='upper right')
plt.show()
矩阵归一化:
# 矩阵归一化数据
def autoNorm_use(dataSet):
# 获取第一列的最小值
minVals = dataSet[:,0].min(0)
# 获取第一列的最大值
maxVals=dataSet[:,0].max(0)
ranges=maxVals-minVals
# 构造一个dataSet 行,列的全0矩阵
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet[:,0] -tile(minVals, (1, m))[0]
# 特征值相除
normDataSet=normDataSet/tile(ranges,(1,m))[0]
return normDataSet ,ranges,minVals
调用:
normMat, range, minVals = autoNorm(dataingDataMat)
得到错误率:
# 针对约会网站分类器的测试代码 即得到错误率
def datingClassTest():
hoRatio=0.10
datingDataMay,datingLabels=file2matrix('datingTestSet2.txt')
# print(datingLabels)
normMat,ranges,minVals=autoNorm(datingDataMay)
m=normMat.shape[0]
# 取出10分之一作为测试数据
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print("the classifier came back with:%d,the real answer is :%d" %(classifierResult,datingLabels[i]))
if (classifierResult != datingLabels[i]):
errorCount+=1.0
print("the total error rate is : %f"%(errorCount/float(numTestVecs)))
调用:
datingClassTest()
预测函数:
def classifyPerson():
resultList=['not at all','in small doses','in large doses']
percentTats=float(input("percentage of time spent playing video games?"))
ffMiles=float(input("frequent flier miles earned per year?"))
iceCream=float(input("liters of ice cream consumed per year?"))
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
# 归一化处理数据
normMat,ranges,minVals=autoNorm(datingDataMat)
inArr=array([ffMiles,percentTats,iceCream])
# 调用分类器分类
classifierResult=classify0((inArr-minVals)/ranges,normMat,datingLabels,3)
print("You will probably like this person:",resultList[classifierResult -1])
结果:
percentage of time spent playing video games?10
frequent flier miles earned per year?10000
liters of ice cream consumed per year?0.5
You will probably like this person: in small doses
整体代码:
from numpy import *
import operator
# import matplotlib
import matplotlib.pyplot as plt
def createDateSet():
# 转换为矩阵
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels=['A','A','B','B']
return group,labels
# 用于分类的输入向量是inX 其实就是一个点,输入的训练样本集为dataSet,标签向量为labels,K表示选择最近邻居的数目
# 分类器
def classify0(inX,dataSet,labels,k):
# 距离计算
dataSetSize=dataSet.shape[0] # 计算行数 shape返回是一个元组(行数,列数)
# dataSetSize,dataSetNumber = dataSet.shape # shape返回是一个元组(行数,列数)
# tile(a,reps) a是待输入数组,reps是a重复的次数(c,b) c是行上重复,b是列上重复
# eg:a=[1,2,3] b=tile(a,(2,1)) 结果:[[1 2 3][1 2 3]]
# x2-x1 y2-y1
diffMat=tile(inX,(dataSetSize,1))-dataSet
# x结果平方,y结果平方
sqDiffMat=diffMat**2
# x**2+y**2 axis=1行上求和 axis=0列上求和
sqDistances=sqDiffMat.sum(axis=1)
# 开根号
distances=sqDistances**0.5
# 排序 argsort() 排序返回数组值从小到大的索引值
sortedDistIndicies=distances.argsort()
# 统计各个类别的个数
classCount={}
# 选择距离最小的K个点
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]]
# dict.get(key, default=None)
# key -- 字典中要查找的键。default -- 如果指定键的值不存在时,返回该默认值值
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
# 排序 sort() 应用在list sorted() 应用在所有可迭代的对象进行排序操作 reverse=True 反向排序 key=lambda x
# operator.itemgetter[1] operator模块提供的itemgetter函数用于获取对象的哪些维的数据==list.index(1)
# 跟据下标为1的部分排序 即('B',2)中的2部分
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
# 把文档中的数据入到array中
def file2matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
# 得到文本行数
numberOfLines=len(arrayOLines)
# 生成 array 相同大小的
returnMat=zeros((numberOfLines,3))
classLabelVector=[]
index=0
for line in arrayOLines:
line=line.strip()
listFromLine=line.split('\t')
returnMat[index,:]=listFromLine[0:3]
# 把分类的结果放到list中
classLabelVector.append(int(listFromLine[-1]))
index+=1
return returnMat,classLabelVector
def autoNorm(dataSet):
# 获取第三列的最小值
# minVals = dataSet[:, 2].min(0)
# 获取每一列的最大,最小值
minVals = dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
# 构造一个dataSet 行,列的全0矩阵
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet -tile(minVals,(m,1))
# 特征值相除
normDataSet=normDataSet/tile(ranges,(m,1))
return normDataSet ,ranges,minVals
# 矩阵归一化数据
def autoNorm_use(dataSet):
# 获取第一列的最小值
minVals = dataSet[:,0].min(0)
# 获取第一列的最大值
maxVals=dataSet[:,0].max(0)
ranges=maxVals-minVals
# 构造一个dataSet 行,列的全0矩阵
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet[:,0] -tile(minVals, (1, m))[0]
# 特征值相除
normDataSet=normDataSet/tile(ranges,(1,m))[0]
return normDataSet ,ranges,minVals
# 针对约会网站分类器的测试代码 即得到错误率
def datingClassTest():
hoRatio=0.10
datingDataMay,datingLabels=file2matrix('datingTestSet2.txt')
# print(datingLabels)
normMat,ranges,minVals=autoNorm(datingDataMay)
m=normMat.shape[0]
# 取出10分之一作为测试数据
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print("the classifier came back with:%d,the real answer is :%d" %(classifierResult,datingLabels[i]))
if (classifierResult != datingLabels[i]):
errorCount+=1.0
print("the total error rate is : %f"%(errorCount/float(numTestVecs)))
# 约会网站预测函数
def classifyPerson():
resultList=['not at all','in small doses','in large doses']
percentTats=float(input("percentage of time spent playing video games?"))
ffMiles=float(input("frequent flier miles earned per year?"))
iceCream=float(input("liters of ice cream consumed per year?"))
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
# 归一化处理数据
normMat,ranges,minVals=autoNorm(datingDataMat)
inArr=array([ffMiles,percentTats,iceCream])
# 调用分类器分类
classifierResult=classify0((inArr-minVals)/ranges,normMat,datingLabels,3)
print("You will probably like this person:",resultList[classifierResult -1])
if __name__=="__main__":
group,labels=createDateSet()
sortedClassCount=classify0([0,0],group,labels,3)
# print(sortedClassCount)
dataingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
# fig=plt.figure()
# # 添加子轴、图。subplot(m, n, p)或者subplot(mnp)此函数最常用:subplot是将多个图画到一个平面上的工具。其中,m表示是图排成m行,
# # n表示图排成n列,也就是整个figure中有n个图是排成一行的,一共m行,
# # 如果第一个数字是2就是表示2行图。p是指你现在要把曲线画到figure中哪个图上,最后一个如果是1表示是从左到右第一个位置。
# ax=fig.add_subplot(111)
# # 设置标题
# ax.set_title('Scatter plot')
# # 设置x轴标签
# ax.set_xlabel("Time spent playing video games")
# # 设置y轴标签
# ax.set_ylabel("The number of ice-cream liters per week")
# # 输出array的第一列x和第二列y
# # ax.scatter(dataingDataMat[:,1],dataingDataMat[:,2])
# # 分类显示
# # scatter(x,y,s=1,c="g",marker="s",linewidths=0)
# # s:散列点的大小,c:散列点的颜色,marker:形状,linewidths:边框宽度
# # ax.scatter(dataingDataMat[:, 1], dataingDataMat[:, 2],15.0*array(datingLabels),15.0*array(datingLabels))
# # map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回
# # 以第二列和第三列为x,y轴画出散列点,给予不同的颜色和大小
# # 在散点图上绘制了色彩不等、尺寸不同的点,数据点所属三个样本分类的区域轮廓 红色的'*'表示类标签1、蓝色的'o'表示表示类标签2、绿色的'+'表示类标签3
# datingLabels = array(datingLabels)
# idx_1 = where(datingLabels == 1)[0][:]
# ax.scatter(dataingDataMat[idx_1,0], dataingDataMat[idx_1,1], c='r', label='1',s=20,marker='*')
# idx_2 = where(datingLabels == 2)[0][:]
# ax.scatter(dataingDataMat[idx_2,0], dataingDataMat[idx_2,1], c='b', label='2',s=10,marker='o')
# idx_3 = where(datingLabels == 3)[0][:]
# ax.scatter(dataingDataMat[idx_3,0], dataingDataMat[idx_3,1], c='g', label='3',s=30,marker='+')
# # 设置图标
# plt.legend(loc='upper right')
# plt.show()
# print(dataingDataMat)
# normMat, range, minVals = autoNorm(dataingDataMat)
# print(normMat)
# normMat,range,minVals=autoNorm_use(dataingDataMat)
# print(normMat)
datingClassTest()
classifyPerson()

















 2290
2290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









