







 本文探讨了深度网络中参数初始化的重要性,通过实验展示了不同激活函数下的网络表现,并提出了xavier初始化方法,以解决梯度消失与爆炸的问题。
本文探讨了深度网络中参数初始化的重要性,通过实验展示了不同激活函数下的网络表现,并提出了xavier初始化方法,以解决梯度消失与爆炸的问题。
这篇论文详细解析了深度网络中参数xavier初始化方法,这里做一下读书笔记,同时记录一下自己的理解。
1 引言
经典前馈神经网络其实很早就有了(Remelhart et al.,1986),近年来对深度监督神经网络的一些成果只不过在初始化和训练方法跟以前有点区别,可是为什么能够取得这么好的结果?部分原因可能是使用非监督训练方法来初始化网络,使得网络整体处于一个比较好的优化状态。但是更早的一些研究(Bengio et al.,2007)显示,使用greedy layer-wise procedure的方法能够得到更好的结果,这篇论文没有把精力放在深度网络的非监督的预训练方法,而是着眼于多层神经网络究竟哪个环节出了问题(才会导致直接训练效果不佳)
2实验一
作者使用了一个四层的网络,使用sigmoid激活函数,权重层bias初始化为0,weight取下面的均匀分布,n是前一层输入维度
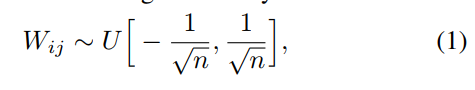
在Shapeset-3*2的数据上训练,训练过程中,使用300副测试图测试,得到各层激活函数值,分别统计出均值和方差,结果得到了下图,图中曲线代表均值,总线条代表方差,可以看到训练一刚开始,最后一层就饱和了(sigmoid范围0-1),训练过了很久,终于走出饱和区了。可是为什么会这样?
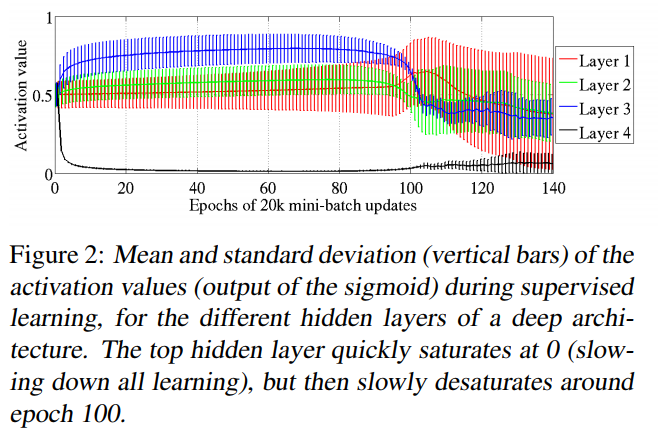
作者提出了解释是这样的,刚开始时,整个网络参数都是随机初始化的,这时低层计算得到的数据对整个分类没带任何分类信息,逻辑层softmax(b+Wh)的学习会更多的去调节b,而把Wh压制到0(毕竟Wh对分类无帮助,属于噪音),继而将h推向0,然而sigmoid输出0,意味着饱和,梯度就传递不过去了,低层的学习过程就被阻碍了。这也是实践中sigmoid慢慢被抛弃的原因了,如果我们将激活函数换成在0附近梯度不为零的Hyperbolic tangent呢?
3实验二
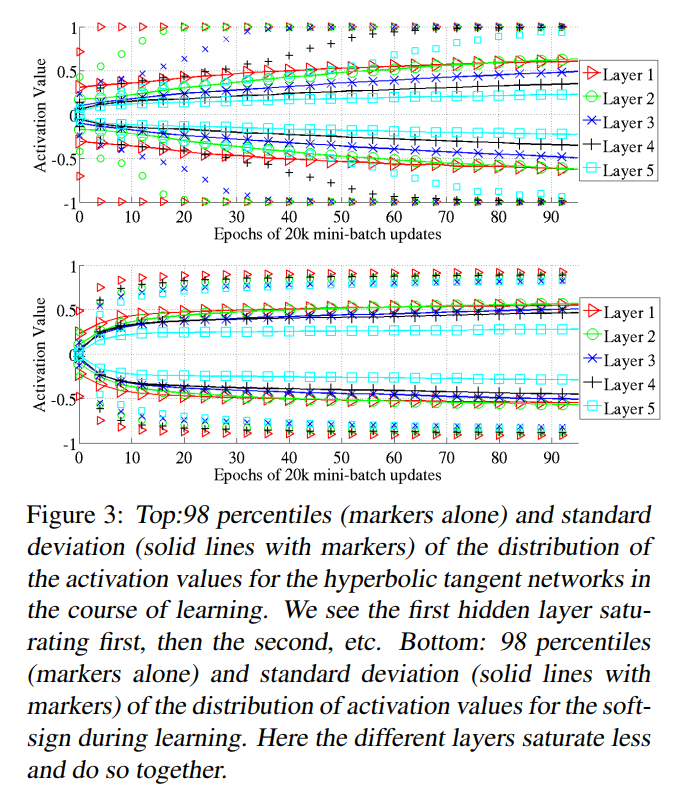
作者将实验一中激活函数换对称的tangent和soft-sign,其他都一样,得到了下图,还是发现从第一层饱和,第二层饱和,最终都饱和了。这个违背了深度学习的两个经验原则,我们既不想网络过饱和也不希望过线性。得到这个结果深层次的原因是什么呢?
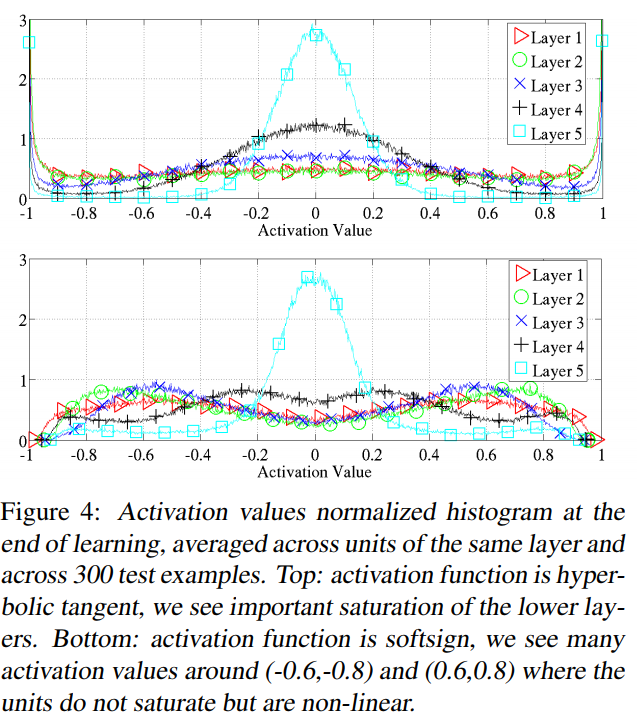
同时也分析了训练结束在300副测试图上各层激活值的分布直方图
4理论分析
这里写下理解,假如我们输入x,方差var(x),那么经过深度网路后输出的z方差是多少呢?已经假定各变量均值为0,激活函数因此都处于线性区,ni'为各层的维度,可以看到如果var[wi']都小于1,那么最后的输出将越来越小,这样不利于数值稳定和梯度计算;
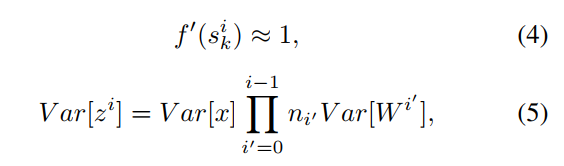
后向传播呢?其中d为网络深度,可以看到,梯度的方差后向传播后是n×Var(W)相乘的形式,乘数正比网络深度d,如果网络很深,传到第一层的梯度方差就很小了,这就是梯度消失了,如果var(W)大于1,那么传到第一层的梯度方差就很大了,这就是梯度爆炸,那么怎么正确的选择var(W)呢?
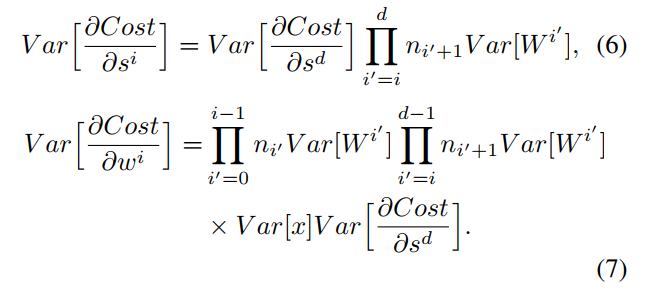
只要我们使得,既我们数据方差前向传递和梯度方差后向传递保持不变,那不是完美?
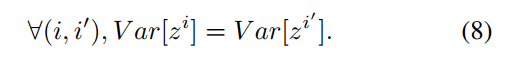
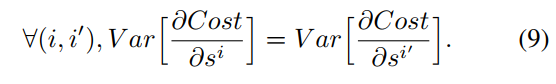
等价于:
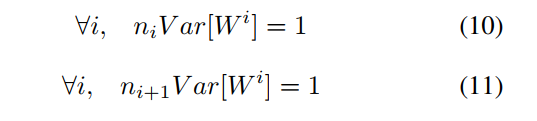
取均值:
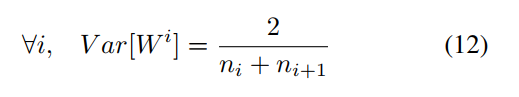
到此结束,引出了目前最常用的xavier初始化方法,现在明白了,哈哈
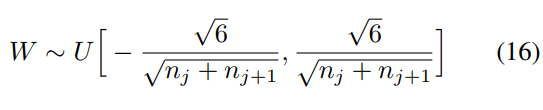
那么问题回来了,之前我们使用的均匀分布初始化方法有影响呢,均匀分布有下面公式,这会导致梯度方差后向传递慢慢变小。
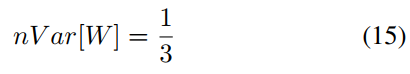

















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









