




 博客围绕字符串最长公共前缀问题展开,介绍了两种解决方法。方法一是切割元素字符串逐个匹配,分析了其时间复杂度;方法二则未详细说明。还给出了网友的五种算法思路及对应时间性能,如纵向扫描、横向扫描等。
博客围绕字符串最长公共前缀问题展开,介绍了两种解决方法。方法一是切割元素字符串逐个匹配,分析了其时间复杂度;方法二则未详细说明。还给出了网友的五种算法思路及对应时间性能,如纵向扫描、横向扫描等。
2019年5月4日
目录
题目:
解决方法一:切割元素的字符串,然后逐个匹配元素
package leetCode;
/**
* Date: 2019/5/4 11 :08
*/
public class LongestCommonPrefix {
public static String longestCommonPrefix(String[] strs) {
String commonPrefix = "";
if (strs.length >= 1){
for (int i=1 ; i <= strs[0].length(); i++){
// 1.prefix字段的末索引
String prefix = strs[0].substring(0, i);
int commonNum = 1;
// 2.逐个元素比较是否以prefix字段开头
for (int j=1; j < strs.length; j++) {
if (strs[j].startsWith(prefix)){
commonNum ++;
}else {
break;
}
}
// 3.所有元素都包括prefix字段则更新commonPrefix,否则退出循环并返回
if (commonNum == strs.length){
commonPrefix = prefix;
}else {
break;
}
}
}
return commonPrefix;
}
public static void main(String[] args){
// String[] vars = {"flower","flow","flight"};
// String[] vars = {"dog","racecar","car"};
// String[] vars = {"mmb1","mmb111","mmb1111"};
String[] vars = {};
String result = longestCommonPrefix(vars);
System.out.println("result="+result);
}
}
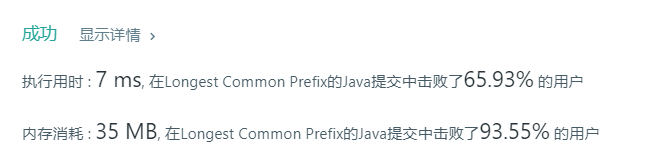
性能结果:
小结:
- 字符串数组初始化使用花括号直接赋值:String[] vars = {"mmb1","mmb111","mmb1111"} ;
- 字符串切割使用substring(beginIndex, int endIndex)函数;
- 数组是一个对象,其元素个数是一个属性:strs.length;字符串的长度属性: length() 函数;
- 时间复杂度:O(m*n),m为公共长度,n为数组元素个数;
看下JDK源码:
public boolean startsWith(String prefix) {
return startsWith(prefix, 0);
} public boolean startsWith(String prefix, int toffset) {
char ta[] = value;
int to = toffset;
char pa[] = prefix.value;
int po = 0;
int pc = prefix.value.length;
// Note: toffset might be near -1>>>1.
if ((toffset < 0) || (toffset > value.length - pc)) {
return false;
}
while (--pc >= 0) {
if (ta[to++] != pa[po++]) {
return false;
}
}
return true;
}源码底层,对prefix建立指正,逐一比较字符串数组与目标元素;
解决方法二:
class Solution {
public String longestCommonPrefix(String[] strs) {
int len=strs.length;
if(len==0) return "";
int i=0;
while(true){
if(isValueEquels(strs,i)){
i++;
}else{
return strs[0].substring(0,i);
}
}
}
private static boolean isValueEquels(String[] strs, int i) {
char c = 0;
for(int j=0;j<strs.length;j++){
String str = strs[j];
if(str.length()<=i) return false;
if(j==0){
c=str.charAt(i);
}else{
if(str.charAt(i)!= c) return false;
}
}
return true;
}
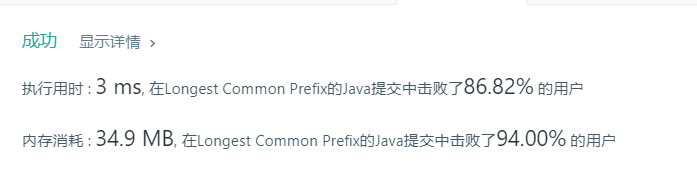
}性能结果:
网友的算法分析:
大概有这五种思路, 一般都会采用第四种, 但是耗时太多
1、所求的最长公共前缀子串一定是每个字符串的前缀子串。
所以随便选择一个字符串作为标准,把它的前缀串,与其他所有字符串进行判断,看是否是它们所有人的前缀子串。这里的时间性能是O(m*n*m)。
2、列出所有的字符串的前缀子串,将它们合并后排序,找出其中个数为n且最长的子串。时间性能为O(n*m+m*n*log(m*n))
3、纵向扫描:从下标0开始,判断每一个字符串的下标0,判断是否全部相同。直到遇到不全部相同的下标。时间性能为O(n*m)。
4、横向扫描:前两个字符串找公共子串,将其结果和第三个字符串找公共子串……直到最后一个串。时间性能为O(n*m)。
5、借助trie字典树。将这些字符串存储到trie树中。那么trie树的第一个分叉口之前的单分支树的就是所求。


















 1636
1636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











