






 本文探讨了解决算法题目的多种方法,包括分治法、减治法、动态规划、贪心算法等,以最大子序和问题为例,详细解析了各种算法的实现与效率分析。
本文探讨了解决算法题目的多种方法,包括分治法、减治法、动态规划、贪心算法等,以最大子序和问题为例,详细解析了各种算法的实现与效率分析。
本篇文章将通过最大自序和这个题目来学习解决算法题目的几种方法–分治法、减治法、动态规划、贪心算法等。
题目:最大子序和
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4]
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
进阶:
如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的分治法求解。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/maximum-subarray
- 常规思路:暴力破解
看到一道算法题最容易想到的就是暴力破解,通过遍历每一种情况来找到最大子序和。但要记住这种方式的时间复杂度可能很大,往往不满足题目要求的执行用时。本题目使用两个指针,第一个指针选定一个位置,第二个指针从第一个指针的位置开始,逐渐后移,两个指针之间便是一个子序列,通过两个指针的移动,可以遍历每一种子序列。
class Solution {
public:
int maxSubArray(vector<int>& nums) {
vector<int>::iterator it;
vector<int>::iterator it2;
int mmax = INT_MIN;
int temp = 0;
for(it = nums.begin();it != nums.end();it++,temp = 0){
for(it2 = it;it2!=nums.end();it2++){
temp += *it2;
mmax = max(temp,mmax);
}
}
return mmax;
}
};
时间复杂度分析:算法的基本语句是temp += *it2; 在问题规模为n的情况下,基本语句要执行 ((1+n)n)/2 次,所以时间复杂度为 O(n2)。
空间复杂度分析:程序运行所需的全部额外空间(注意:空间复杂度不考虑输入)只有temp临时变量,所以空间复杂度为O(1)。
LeetCode给出的执行结果如下图,果然时间耗费的比较多。

- 递归-减治法
因为暴力破解的方法时间复杂度较大,所以最好找到更加优化的算法,分治法和减治法是能想到的递归算法。一般的问题,会先想分治法,将数组一分为二,将左右子数组分别递归地求解。但是这种一分为二的方法,显然忽略了跨越两个子数组边界的情况,需要进行处理,所以先放在一边,想想能不能通过减治法来解决问题。
减治法的思维,是将问题划分为两个子问题,其一是平凡的(容易求解的,或者说能在o(1)时间范围内解决的问题),另一个是规模缩减的,平凡的子问题是易解的,规模缩减的问题通过递归的方式进一步解决。如下图所示:
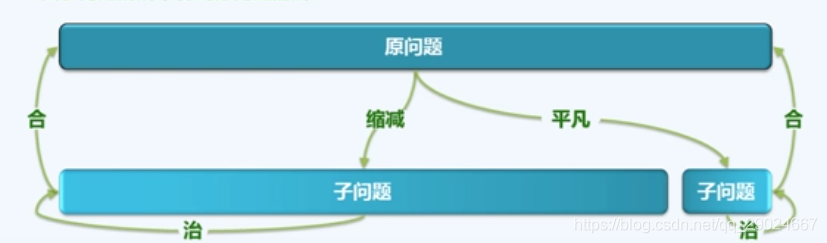
思考本题,对于n个元素的序列,我们可以先解决n-1序列的最大自序和,然后再加上最后一个元素来合并获得原问题的解。如图所示,计算出前8个序列的最大子序和,然后再加入最后一个元素,考虑整体的最大自序和。

那么,如何在已知前边序列的最大自序和max1基础上,获得加入最后一个元素后序列的最大自序和max2呢?
考虑到max1可能的情况如图中红色所示,红色部分无法与最后一个元素4进行合并,所以除了知道左边序列的max1以外,还需要知道左边序列的向右最大贡献值,也就是包含最右边数字-5的最大自序和,然后再加上新成员4,如果大于max1,则它更大的子序和,如果不小于max1,那么就没他什么事情了。
所以,再进行每一次计算时,都需要计算两个东西,一个是该序列的当前最大自序和,一个是计算该子串的向右最大贡献。通过递归的方式,我们逐步将问题简化,最终遇到递归基(最小规模的问题),也就是最左边的一个元素时,直接让当前最大自序和还有很多向右最大贡献为该值即可。
class Solution {
public:
int maxSubArray(vector<int>& nums) {
vector<int>::iterator start = nums.begin();
vector<int>::iterator end = nums.end();
int maxH = 0;
return getSubMax(nums, start, end, &maxH);
}
//返回值是当前子序列最大值,maxH是最大向右贡献值
int getSubMax(vector<int>& nums, vector<int>::iterator start, vector<int>::iterator end, int* maxH) {
int mmax = 0; // 最大序列值
if (end - start == 1) {
if(*start > 0){
*maxH = *start;
}
else{
*maxH = 0;
}
return *start;
}
else{
mmax = getSubMax(nums, start, end - 1, maxH);
*maxH = *maxH + *(end-1);
if(*maxH > mmax){
mmax = *maxH;
}
if(*maxH < 0){
*maxH = 0;
}
return mmax;
}
}
};
时间复杂度分析:显然递归的次数就是问题的规模n,所以基本语句执行n次,时间算法复杂度为O(n)。
空间复杂度分析:函数递归调用随着问题规模的增大需要额外的栈空间来存储,执行一个问题,需要进行n次递归,所以空间复杂度为O(n)。
LeetCode给出的执行结果如下图,时间比较短,但是耗费的空间比较多。

- 递归-分治法
使用减治法成功解决问题后,回头再考虑一下分治法,因为一般的问题还是用分治法比较现实,分治法是将问题划分为若干个规模相当的子问题,并递归地求解每一个子问题,如下图所示:
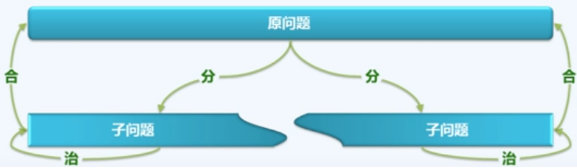
将序列一分为二后,除了左序列和右序列的解以外,怎样解决跨左右序列的子序列和,是最难的问题,如图所示,序列1和序列2可以通过递归的方式求解,那么如果最终的最大自序是包含mid以及左右元素的序列怎么办呢?最简单直接的办法,就是暴力解决所有包含mid以及左右子序列的情况。
根据不同的数组下标处理方式,mid可能被包含在左序列中也可以被包含在右序列中,我的代码是将mid包含在右序列中,那么就只需要考虑包含mid以及左序列的某些元素的序列和即可。

下面的代码,getSubMax函数通过递归的方式获得一个序列的最大自序和,该函数首先将序列一分为二,并分别计算这两个序列的最大自序和,然后通过getMidMax函数获得包含mid元素的最大序列和,最后在这三个结果中取最大即可。
class Solution {
public:
int maxSubArray(vector<int>& nums) {
vector<int>::iterator start = nums.begin();
vector<int>::iterator end = nums.end();
return getSubMax(nums, start, end);
}
int getSubMax(vector<int>& nums, vector<int>::iterator start, vector<int>::iterator end) {
if (end - start == 1) {
return *start;
}
int maxLeft = 0;
int maxRight = 0;
int maxMid = 0;
vector<int>::iterator mid = start + (end - start) / 2;
maxLeft = getSubMax(nums, start, mid);
maxRight = getSubMax(nums, mid, end);
maxMid = getMidMax(nums, start, end, mid);
return max(max(maxLeft, maxRight), maxMid);
}
int getMidMax(vector<int>& nums, vector<int>::iterator start, vector<int>::iterator end, vector<int>::iterator mid) {
int temp = 0;
int maxLeft = INT_MIN;
int maxRight = INT_MIN;
for (vector<int>::iterator left = mid - 1; left >= start;left--) {
temp += *left;
if (temp > maxLeft) {
maxLeft = temp;
}
if (left == nums.begin()) {
break;
}
}
temp = 0;
for (vector<int>::iterator right = mid; right != end; right++) {
temp += *right;
if (temp > maxRight) {
maxRight = temp;
}
}
return maxRight + maxLeft;
}
};
时间复杂度:在递归的函数中,调用的getMidMax函数仍然有循环,所以这个函数中的两个for循环中的代码为基本语句,但是这里for循环内的语句执行次数还要取决于输入子序列的长度,所以不能直接计算。可以由递归分层考虑,在第一层,序列长度为n,有一个递归函数实例在运行,每个getMidMax函数中基本语句执行n次,总共执行n次,在第二层,序列长度为n/2,有2个递归函数实例在运行,每个实例中基本语句执行n/2次,总共执行n次……后面的每一层都执行n次。而一个规模为n的序列不断2分,直到序列长度为1,总共有log2n层,由此可见基本语句执行的次数为nlog2n次,所以时间复杂度为O(nlogn)。
空间复杂度:本算法中没有用到与问题规模n有关的数组,所以所有的开销都是函数栈造成的。递归算法的空间复杂度=递归深度N×每次递归所要的辅助空间,而递归深度也就是上面说的层数,也就是log2n层,所以空间复杂度为O(logn)。
LeetCode给出的执行结果如下图,执行时间非常短,内存消耗中等。

如上两种算法都是效率比较高的递归算法,但是,比起迭代法,递归的方法便于想到便于理解,但是效率往往不够高。造成效率不高的主要原因,是迭代法可能存在大量的递归实例。
用本题来举个栗子:在考虑分治法时,因为一开始想在二分法中跨中心点mid的序列怎么算,所以考虑了如下图所示的划分子问题方法,以1-(n-1)为序列1,以2-n为序列2,并递归地解决问题。
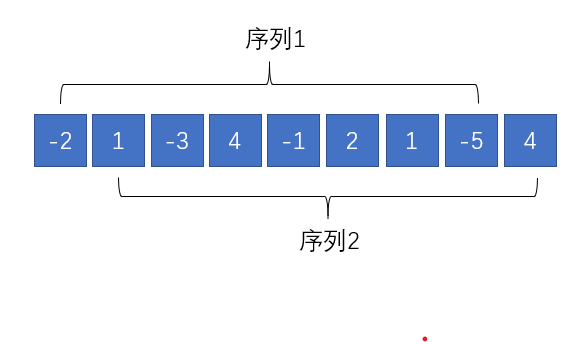
但是这种方法在运行时会超时,这是为什么?思考过后,我发现,在序列1和序列2递归地分析子序列时,会有大量重复的递归的实例在运行,例如4,-1, 2这个子串,在序列1和序列2中都需要计算一遍,并且在序列1和序列2后续的子序列中还可能计算很多遍,这就是递归法中常见的重复递归实例,这会大量增加运算的次数。
针对这种问题,有两种有效的解决方案。
第一种是利用额外空间,记忆重复的计算过程,例如4,-1,2这个子串,在第一次计算时,就将结果记录在一个表中,其他递归示例再计算这个子序列时,就不需要再计算,直接查表即可。
第二种是转换为迭代的方法,从下往上,减少重复计算。
- 迭代-贪心算法
递归的方法是从上往下的方法,往往便于思考,但是效率不高。
迭代的方法是从下往上的方法,思考需要技巧,但是效率高。如果已经完成了递归的方法,可以通过逆向思维思考对应的迭代法。
贪心算法是指在对问题求解时,总是做出在当前看来是最好的选择,根据局部最优解迭代出全局最优解。贪心算法不总是能解决问题,因为很多问题的全局最优解并不能通过局部最优解来得到,能否得到,关键在于贪心算法中选择的贪心策略,这个策略必须满足无后效性:某个状态以前的过程不会影响到这个状态之后的状态,只与当前状态有关,就好比马尔科夫链一样。
回忆减治法,从n长度的序列,逐步递归地求解n-1,n-2…的子序列。其实,逆向思考这个过程,就是贪心算法的迭代过程。贪心算法从最左边第一个元素开始,记录当前的最大子序和以及向右最大贡献,之后加入新的元素,如果新的元素和向右最大贡献加起来大于当前子序和,则替换当前最大子序和,这样不断迭代,遍历整个序列也就得到了序列的最大子序和。
可以想到,这种贪心策略之前的过程完全可以由当前最大自序和还有向右最大贡献这两个值代替,后面的状态可以由这两个值来唯一确定,所以是成功的贪心策略。
之所以这种贪心策略可以成功,一大原因是本题目要求子序列必须是连续的,如果可以任意选择位置构成子序列,那么显然不能通过这种方式来解决。
class Solution {
public:
int maxSubArray(vector<int>& nums) {
vector<int>::iterator it2 = nums.end();
int sum = 0;
int mmax = INT_MIN;
for(vector<int>::iterator it1 = nums.begin();it1 != nums.end(); it1++){
sum += *it1;
mmax = max(sum,mmax);
if(sum < 0){
sum = 0;
}
}
return mmax;
}
};
时间复杂度分析:显然,只需要一个for循环,基本语句执行了n次,这个算法的时间复杂度为O(n)。
空间复杂度分析:额外空间只用到了sum和mmax这两个变量,所以是O(1)。比较减治法的空间复杂度O(n),贪心算法不需要特意保存之前的状态,而减治法需要在函数栈中保存状态,所以贪心算法的空间复杂度更小。
LeetCode给出的执行结果如下图,执行时间非常短,内存消耗也不大。

- 迭代-动态规划
如果没有合适的贪心策略,那么问题就不能用贪心算法来解决,但是仍然可以用动态规划的方法来解决。比起贪心算法,动态规划适用范围更广,因为它可以记住上一状态之前的信息,不必像贪心算法一样无后效性。
但类似的是,动态规划仍然是分解子问题,并不断合并子问题的迭代过程,适合用动态规划的一个关键点在于:大问题分解成的若干个小问题之间还有相会重叠的更小的子问题,也就是之前提到的那种超时分治法的逆向过程,只不过这一次,我们不会再重复计算这些小问题,而是动态地记载这些重复的过程。
首先,temp变量用于记录当前的子序列和,随着指针向右移动,不断加和新的元素,一旦出现的下一个元素大于当前子序和并且当前子序和已经小于0,那么还不如不用之前的子序列,重新从零开始,计算从这个元素开始的新的序列和。
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int m = INT_MIN;
vector<int>::iterator it;
vector<int>::iterator it2;
//temp记载当前的子序列和,m记载最最大自序和
int temp = m;
for(it = nums.begin(); it != nums.end();it++){
if(*it > temp && temp < 0){
temp = *it;
m = max(temp,m);
}
else{
temp += *it;
m = max(temp,m);
}
}
return m;
}
};
时间复杂度:同贪心算法,时间复杂度为O(n)。
空间复杂度:因为只有temp一个变量,所以空间复杂度为O(1)。
LeetCode给出的执行结果如下图,执行时间非常短,内存消耗也不大。

最后感谢松鼠鱼等人在LeetCode上提供的解题思路!https://leetcode-cn.com/problems/maximum-subarray/solution/zui-da-zi-xu-he-de-si-kao-guo-cheng-bao-li-fa-jian/

















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









