







Hierarchical Attention Networks for Document Classification
一、模型
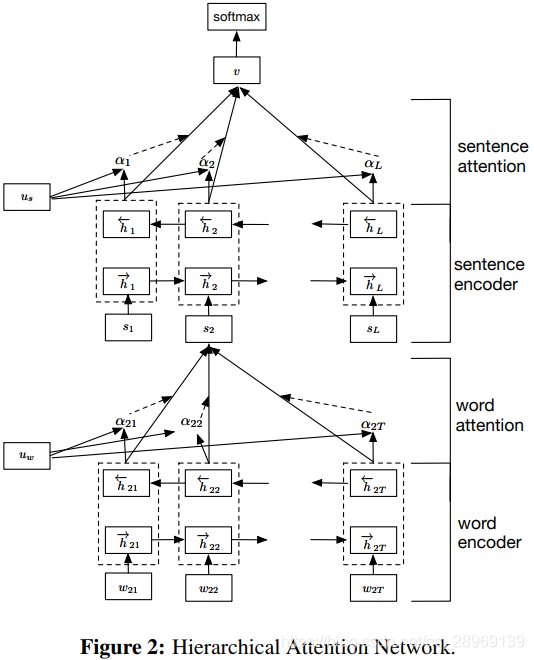
二、代码
import torch.nn.functional as F
from torch import nn
class SelfAttention(nn.Module):
def __init__(self, input_size, hidden_size):
super(SelfAttention, self).__init__()
self.W = nn.Linear(input_size, hidden_size, True)
self.u = nn.Linear(hidden_size, 1)
def forward(self, x):
u = torch.tanh(self.W(x))
a = F.softmax(self.u(u), dim=1)
x = a.mul(x).sum(1)
return x
class HAN(nn.Module):
def __init__(self):
super(HAN1, self).__init__()
num_embeddings = 5844 + 1
num_classes = 10
num_sentences = 30
num_words = 60
embedding_dim = 200 #  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1711
1711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









