






未整理文档
分布式事务的三种解决方案
阿里分布式解决方案:seata
mysql在执行时都是如何选择索引的
查询成本:
这里所说的成本是指:IO成本和CPU成本
- IO成本是指,MySQL读取数据的时候会将数据从磁盘读取到内存中,读取数据的单位是数据页,每一页为16KB,所以读取数据页的成本常熟记做1(1页的成本为1)
- CPU成本是指,查询数据是否满足查询条件或排序条件的CPU的执行成本。默认情况下,检测记录成本常数记录为0.2(这里是指检测每一行数据的成本)。
在MySQL5.6及之后的版本中,我们可以通过optimizer_trace功能来查看优化器生成执行计划的整个过程。通过这个功能,我们可以了解MySQL每个计划的成本,然后来进一步对查询进行优化。optimizer_trace功能,默认是关闭的。可通过如下代码打开后,再执行具体的SQL,然后通过information_schema.OPTIMIZER_TRACE 表查看执行计划,最后记得手动再关闭optimizer_trace功能
MySQL锁系列之锁的种类和概念
在mysql当中,关于innodb的锁类型总共可以分为四种,包含了行锁和表锁,分别是:
- 基本锁:共享锁和排它锁
- 意向锁:意向共享锁和意向排它锁
- 行锁:record Locks、gap locks、next-key locks、insert intention locks
- 自增锁
间隙锁是Innodb在可重复读提交下为了解决幻读问题时引入的锁机制,幻读的问题存在是因为新增或者更新操作,这时如果进行范围查询的时候(加锁查询),会出现不一致的问题,这时使用不同的行锁已经没有办法满足要求,需要对一定范围内的数据进行加锁,间隙锁就是解决这类问题的。
b+Tree 特点
从reentrantlock看AQS(美团团队)
ReentrantLock源码解析
读写锁
mysql常用的函数表达式
ThreadPoolExecutor:队列
拒绝策略
深入浅出AQS之共享锁模式
java
1、 java基础
一、ThreadPoolExecutor的重要参数
corePoolSize:核心线程数
核心线程会一直存活,即使没有任务需要执行
当线程数小于核心线程数时,即使有线程空闲,线程池也会优先创建新线程处理
设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭
queueCapacity:任务队列容量(阻塞队列)
当核心线程数达到最大时,新任务会放在队列中排队等待执行
maxPoolSize:最大线程数
当线程数>=corePoolSize,且任务队列已满时。线程池会创建新线程来处理任务
当线程数=maxPoolSize,且任务队列已满时,线程池会拒绝处理任务而抛出异常
keepAliveTime:线程空闲时间
当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize
如果allowCoreThreadTimeout=true,则会直到线程数量=0
allowCoreThreadTimeout:允许核心线程超时
rejectedExecutionHandler:任务拒绝处理器
两种情况会拒绝处理任务:
当线程数已经达到maxPoolSize,切队列已满,会拒绝新任务
当线程池被调用shutdown()后,会等待线程池里的任务执行完毕,再shutdown。如果在调用shutdown()和线程池真正shutdown之间提交任务,会拒绝新任务
线程池会调用rejectedExecutionHandler来处理这个任务。如果没有设置默认是 AbortPolicy,会抛出异常
ThreadPoolExecutor类有几个内部实现类来处理这类情况:
AbortPolicy 丢弃任务,抛运行时异常
CallerRunsPolicy 执行任务
DiscardPolicy 忽视,什么都不会发生
DiscardOldestPolicy 从队列中踢出最先进入队列(最后一个执行)的任务
实现RejectedExecutionHandler接口,可自定义处理器
二、ThreadPoolExecutor执行顺序
线程池按以下行为执行任务
(1)当线程数小于核心线程数时,创建线程。
(2)当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
(3)当线程数大于等于核心线程数,且任务队列已满
1)若线程数小于最大线程数,创建线程
2)若线程数等于最大线程数,抛出异常,拒绝任务
三、如何设置参数
默认值
corePoolSize=1
queueCapacity=Integer.MAX_VALUE
maxPoolSize=Integer.MAX_VALUE
keepAliveTime=60s
allowCoreThreadTimeout=false
rejectedExecutionHandler=AbortPolicy()
如何来设置
需要根据几个值来决定
tasks :每秒的任务数,假设为500~1000
taskcost:每个任务花费时间,假设为0.1s
responsetime:系统允许容忍的最大响应时间,假设为1s
做几个计算
corePoolSize = 每秒需要多少个线程处理?
threadcount = tasks/(1/taskcost) =tasks*taskcout = (500~1000)*0.1 = 50~100 个线程。corePoolSize设置应该大于50
根据8020原则,如果80%的每秒任务数小于800,那么corePoolSize设置为80即可
queueCapacity = (coreSizePool/taskcost)responsetime
计算可得 queueCapacity = 80/0.11 = 80。意思是队列里的线程可以等待1s,超过了的需要新开线程来执行
切记不能设置为Integer.MAX_VALUE,这样队列会很大,线程数只会保持在corePoolSize大小,当任务陡增时,不能新开线程来执行,响应时间会随之陡增。
maxPoolSize = (max(tasks)- queueCapacity)/(1/taskcost)
计算可得 maxPoolSize = (1000-80)/10 = 92
(最大任务数-队列容量)/每个线程每秒处理能力 = 最大线程数
rejectedExecutionHandler:根据具体情况来决定,任务不重要可丢弃,任务重要则要利用一些缓冲机制来处理
keepAliveTime和allowCoreThreadTimeout采用默认通常能满足
以上都是理想值,实际情况下要根据机器性能来决定。如果在未达到最大线程数的情况机器cpu load已经满了,则需要通过升级硬件和优化代码,降低taskcost来处理。
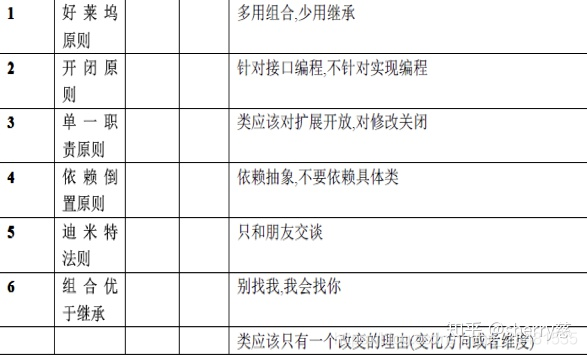
2、面向对象的设计原则
1,开闭原则
对扩展开放------- 模块的行为可以被扩展从而满足新的需求。
对修改关闭-------不允许修改模块的源代码(或者尽量使修改最小化)
开闭原则是说我们应该努力设计不需要修改的模块。在实际应用将变化的代码和不需要变化的代码进行隔离,将变化的代码抽象成稳定接口,针对接口进行编程。在扩展系统的行为时,我们只需要添加新的代码,而不需要修改已有的代码。一般可以通过添加新的子类和重写父类的方法来实现。
开闭原则是面向对象设计的核心,满足该原则可以达到最大限度的复用性和可维护性。
2,单一原则
单一原则表明,如果你有多个原因去改变一个类,那么应该把这些引起变化的原因分离开,把这个类分成多个类,每个类只负责处理一种改变。当你做出某种改变时,只需要修改负责处理该改变的类。当我们去改变一个具有多个职责的类时可能会影响该类的其他功能
单一职责原则代表了设计应用程序时一种很好的识别类的方式,并且它提醒你思考一个类的所有演化方式。只有对应用程序的工作方式有了很好的理解,才能很好的分离职责。
3,接口隔离原则
接口隔离原则表明客户端不应该被强迫实现一些他们不会使用的接口,应该把肥胖接口中的方法分组,然后用多个接口代替它,每个接口服务于一个子模块。
如果已经设计成了胖接口,可以使用适配器模式隔离它。像其他设计原则一样,接口隔离原则需要额外的时间和努力,并且会增加代码的复杂性,但是可以产生更灵活的设计。如果我们过度的使用它将会产生大量的包含单一方法的接口,所以需要根据经验并且识别出那些将来需要扩展的代码来使用它。
4,里氏替换原则
里氏替换原则是对开闭原则的扩展,它表明我们在创建基类的新的子类时,不应该改变基类的行为。
当我们设计程序模块时,我们会创建一些类层次结构,然后我们通过扩展一些类来创建它们的子类。我们必须确保子类只是扩展而没有替换父类的功能,否则当我们在已有程序模块中使用它们时将会产生不可预料的结果。里氏代换原则表明当一个程序模块使用基类时,基类的引用可以被子类替换而不影响模块的功能。
5,依赖倒转原则
上层模块不应该依赖于底层模块,它们都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
应用该原则意味着上层类不直接使用底层类,他们使用接口作为抽象层。这种情况下上层类中创建底层类的对象的代码不能直接使用new 操作符。可以使用一些创建型设计模式,例如工厂方法,抽象工厂和原型模式。模版设计模式是应用依赖倒转原则的一个例子。当然,使用该模式需要额外的努力和更复杂的代码,不过可以带来更灵活的设计。不应该随意使用该原则,如果我们有一个类的功能很有可能在将来不会改变,那么我们就不需要使用该原则。
6,迪米特法则
迪米特法则(Law of Demeter)又叫最少知识原(Least Knowledge Principle LKP),就是说一个对象应当对其他对象有尽可能少的了解。
迪米特法则的目的在于降低类之间的耦合。由于每个类尽量减少对其他类的依赖,因此,很容易使得系统的功能模块相互独立,相互之间不存在依赖关系。
应用迪米特法则有可能造成的一个后果就是,系统中存在的大量的中介类,这些类之所以存在完全是为了传递类之间的相互调用关系—这在一定程度上增加系统的复杂度。
设计模式中的门面模式(Facade)和中介模式(Mediator)都是迪米特法则的应用的例子。
狭义的迪米特法则的缺点:
在系统里面造出大量的小方法,这些方法仅仅是传递间接的调用,与系统的商业逻辑无关。遵循类之间的迪米特法则会使一个系统的局部设计简化,因为每一个局部都不会和远距离的对象有之间的关联。但是,这也会造成系统的不同模块之间的通信效率降低,也会使系统的不同模块之间不容易协调。
广义的迪米特法则在类的设计上的体现:
优先考虑将一个类设置成不变类。尽量降低一个类的访问权限。尽量降低成员的访问权限。
7,组合/聚合复用原则
聚合表示整体与部分的关系,表示“含有”,整体由部分组合而成,部分可以脱离整体作为一个独立的个体存在。组合则是一种更强的聚合,部分组成整体,而且不可分割,部分不能脱离整体而单独存在。在合成关系中,部分和整体的生命周期一样,组合的新的对象完全支配其组成部分,包括他们的创建和销毁。
组合/聚合和继承是实现复用的两个基本途径。合成复用原则是指尽量使用组合/聚合,而不是使用继承。只有当以下的条件全部被满足时,才应当使用继承关系:
子类是超类的一个特殊种类,而不是超类的一个角色,也就是区分“Has-A”和“Is-A”.只有“Is-A”关系才符合继承关系,“Has-A”关系应当使用聚合来描述。永远不会出现需要将子类换成另外一个类的子类的情况。如果不能肯定将来是否会变成另外一个子类的话,就不要使用继承。子类具有扩展超类的责任,而不是具有置换掉或注销掉超类的责任。如果一个子类需要大量的置换掉超类的行为,那么这个类就不应该是这个超类的子类。
以上就是面向对象的7大设计原则,你可以用下面这张连线图来检测自己的掌握情况
1. Integer 缓存数据的范围?
| 包装类型 | 基本数据类型 | 缓存范围 |
|---|---|---|
| Boolean | boolean | true,false |
| Byte | byte | -128~127 |
| Short | short | -128~127 |
| Chatactor | char | 0~127 |
| Integer | int | -128~127 |
| Long | long | -128~127 |
| Float | float | 无 |
| Double | double | 无 |
JVM会自动维护八种基本类型的常量池,int常量池中初始化-128~127的范围,所以当为Integer i=127时,在自动装箱过程中是取自常量池中的数值,而当Integer i=128时,128不在常量池范围内,所以在自动装箱过程中需new 128,所以地址不一样。
原来Integer把-128到127(可调)的整数都提前实例化了。 这就解释了那道面试题的答案,原来你不管创建多少个这个范围内的Integer用ValueOf出来的都是同一个对象。
但是为什么JDK要这么多此一举呢? 我们仔细想想, 淘宝的商品大多数都是100以内的价格, 一天后台服务器会new多少个这个的Integer, 用了IntegerCache,就减少了new的时间也就提升了效率。同时JDK还提供cache中high值得可配置,这无疑提高了灵活性,方便对JVM进行优化。
修改缓存范围:
所以我们可以通过设置java 的时候的参数来配置运行时的参数:
java -D java.lang.Integer.IntegerCache.high=1000 TestAutoBoxCache
java -XX:AutoBoxCacheMax=1000 TestAutoBoxCache
2. 自己定义一个对象是否可以作为hashmap的key
答:重写equals方法和hashcode
hashmap 的 equals 中比较了reference 和 它们的hashcode的值。
需要重写hashCode()和equals()方法才可以实现自定义键在HashMap中的查找。
3. final关键字
在使用匿名内部类的时候可能会经常用到final关键字;
final类不能被继承,没有子类,final类中的方法默认是final的。
final方法不能被子类的方法覆盖,但可以被继承。
使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升。在最近的Java版本中,不需要使用final方法进行这些优化了
final成员变量表示常量,只能被赋值一次,赋值后值不再改变。
final不能用于修饰构造方法。
3、悲观锁和乐观锁
悲观锁(Pessimistic Lock):
每次获取数据的时候,都会担心数据被修改,所以每次获取数据的时候都会进行加锁,确保在自己使用的过程中数据不会被别人修改,使用完成后进行数据解锁。由于数据进行加锁,期间对该数据进行读写的其他线程都会进行等待。
乐观锁(Optimistic Lock):
每次获取数据的时候,都不会担心数据被修改,所以每次获取数据的时候都不会进行加锁,但是在更新数据的时候需要判断该数据是否被别人修改过。如果数据被其他线程修改,则不进行数据更新,如果数据没有被其他线程修改,则进行数据更新。由于数据没有进行加锁,期间该数据可以被其他线程进行读写操作。
适用场景:
悲观锁:比较适合写入操作比较频繁的场景,如果出现大量的读取操作,每次读取的时候都会进行加锁,这样会增加大量的锁的开销,降低了系统的吞吐量。
乐观锁:比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可能性就会增大,为了保证数据的一致性,应用层需要不断的重新获取数据,这样会增加大量的查询操作,降低了系统的吞吐量。
4、 linkedlist和arraylist有什么区别
1、ArrayList和LinkedList可想从名字分析,它们一个是Array(动态数组)的数据结构,一个是Link(链表)的数据结构,此外,它们两个都是对List接口的实现。前者是数组队列,相当于动态数组;后者为双向链表结构,也可当作堆栈、队列、双端队列
2、当随机访问List时(get和set操作),ArrayList比LinkedList的效率更高,因为LinkedList是线性的数据存储方式,所以需要移动指针从前往后依次查找。
3、当对数据进行增加和删除的操作时(add和remove操作),LinkedList比ArrayList的效率更高,因为ArrayList是数组,所以在其中进行增删操作时,会对操作点之后所有数据的下标索引造成影响,需要进行数据的移动。
4、从利用效率来看,ArrayList自由性较低,因为它需要手动的设置固定大小的容量,但是它的使用比较方便,只需要创建,然后添加数据,通过调用下标进行使用;而LinkedList自由性较高,能够动态的随数据量的变化而变化,但是它不便于使用。
5、ArrayList主要控件开销在于需要在lList列表预留一定空间;而LinkList主要控件开销在于需要存储结点信息以及结点指针信息。
8. cas是什么,怎么实现的,会有什么问题。
CAS的语义是“我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉V的值实际为多少”,CAS是项 乐观锁 技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
对于并发控制而言,锁是一种悲观策略,会阻塞线程执行。而无锁是一种乐观策略,它会假设对资源的访问时没有冲突的,既然没有冲突就不需要等待,线程不需要阻塞。
那多个线程共同访问临界区的资源怎么办呢,无锁的策略采用一种比较交换技术CAS(compare and swap)来鉴别线程冲突,一旦检测到冲突,就充实当前操作直到没有冲突为止。
乐观锁的核心算法是CAS(Compareand Swap,比较并交换),它涉及到三个操作数:内存值、预期值、新值,当且仅当预期值和内存值相等时才将内存值修改为新值。这样处理的逻辑是,首先检查某块内存的值是否跟之前我读取时的一样,如不一样则表示期间此内存值已经被别的线程更改过,舍弃本次操作,否则说明期间没有其他线程对此内存值操作,可以把新值设置给此块内存现在已经了解乐观锁及CAS相关机制,乐观锁避免了悲观锁独占对象的现象,同时也提高了并发性能,但它也有缺点:
乐观锁只能保证一个共享变量的原子操作。如上例子,自旋过程中只能保证value变量的原子性,这时如果多一个或几个变量,乐观锁将变得力不从心,但互斥锁能轻易解决,不管对象数量多少及对象颗粒度大小。
长时间自旋可能导致开销大。假如CAS长时间不成功而一直自旋,会给CPU带来很大的开销。
ABA问题。CAS的核心思想是通过比对内存值与预期值是否一样而判断内存值是否被改过,但这个判断逻辑不严谨,假如内存值原来是A,后来被一条线程改为B,最后又被改成了A,则CAS认为此内存值并没有发生改变,但实际上是有被其他线程改过的,这种情况对依赖过程值的情景的运算结果影响很大。解决的思路是引入版本号,每次变量更新都把版本号加一。
10. String,StringBuffer,StringBuilder的区别,为什么String是不可变的,StringBuffer和StringBuilder哪个是线程安全的,他们分别适用于什么场景。
url
String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,这样不仅效率低下,而且大量浪费有限的内存空间,所以经常改变内容的字符串最好不要用 String 。
5、类加载机制
*JVM的类加载机制主要有如下3种。
- 全盘负责:所谓全盘负责,就是当一个类加载器负责加载某个Class时,该Class所依赖和引用其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。
- 双亲委派:所谓的双亲委派,则是先让父类加载器试图加载该Class,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类。通俗的讲,就是某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父加载器,依次递归,如果父加载器可以完成类加载任务,就成功返回;只有父加载器无法完成此加载任务时,才自己去加载。
- 缓存机制。缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区中搜寻该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓冲区中。这就是为什么修改了Class后,必须重新启动JVM,程序所做的修改才会生效的原因。
1. java类加载过程是怎么样的
- 加载
这个阶段主要完成三件事情:
1)通过一个类的全限定类名来获取描述此类的二进制字节流。
2)将这个字节流代表的静态存储结构转化为方法区运行时的数据结构。
3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
类加载完成后,虚拟机外部的二进制字节流就按照虚拟机所需的格式存储在方法区中,然后再内存中实例化一个java.lang.Class对象(对于HotSpot虚拟机而言,class对象不存在于Java堆,而在方法区中创建),这个对象将作为外部程序访问方法区中这些类型数据的外部接口。 - 验证
这一阶段的目的主要是确保class文件的字节流中所包含的信息符合虚拟机规范的要求,并且不会危害虚拟机,确保虚拟机自身安全。
主要进行四部分的验证:
1)文件格式的验证,class文件是否符合虚拟机class文件格式规范,比如是否以0xCAFEBABE开头、主次版本号是否和当前虚拟机匹配,等等。
2)元数据验证,主要对字节码描述的信息进行语义分析,确保语言描述符合java语言规范,如是否继承了被final修饰的类等等。
3)字节码验证,主要是通过数据流和控制流分析,确保程序语义是合法的、符合逻辑的,这一个阶段也是最复杂的验证阶段。
4)符号引用验证,对类自身以外的信息(常量池中的各种符号引用)进行匹配性校验,通常校验的内容有:
4.1符号引用中通过字符串描述的全限定类名能否找到对应的类。
4.2在指定类中是否存在符合方法的字段描述符以及简单名称描述的方法和字段。
4.3符号引用中类、字段、方法的访问性是否可被当前类访问。 - 准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些变量所需要的内存,都将在方法区中进行分配。这里有概念容易混淆:第一这时候进行内存分配仅包括类变量(被static修饰的)不包括实例变量,实例变量将随着对象实例化时一起在Java堆中分配内存。第二这里所说的初始值,通常情况下是数据类型的0值或者null值。 - 解析
解析阶段主要是完成符号引用替换为直接引用,部分初始化也可以在这个阶段完成,比如类或者接口中被final修饰的类成员变量的初始化阶段就是在这个阶段完成的。这么说可能会引起误解,类成员变量的初始化本来就是在这个阶段完成的,比如public static Integer A=10,那么在解析阶段,A的初始化值为NULL,至于A=10的初始化动作,一般是在初始化阶段完成的。而如果是public static final Integer A=10,那么这时A的初始化A=10是在解析阶段就直接完成了的。 - 初始化
初始化阶段主要是给类的成员变量进行初始化值,在这个阶段,虚拟机会自动创建一个方法,我们称之为类构造器,这个方法的要执行的内容主要包括两部分,类成员变量的初始化和静态代码块。它们的执行顺序按照在类中的定义的顺序。其中,静态代码块中可以对其前面定义的类成员变量赋值和访问,但不可以对其后定义的类成员变量访问,但可以赋值。
触发类初始化动作的方式:
1)new 对象实例或者显式的调用类的静态方法或访问或设置类的静态成员变量。
2)通过java.lang.reflect中的方法对类进行反射调用。
3)当初始化一个类的时候,如果发现其父类尚未被初始化,则先初始化其父类。
4)当虚拟机启动时,用户需要指定一个要执行主类(main方法所在的类),虚拟机会先初始化这个主类。
5)在使用jdk1.7的动态语言支持时,被解析成的方法句柄未被初始化,则要先初始化。
15. volite关键字
16. 为什么使用线程池?线程池的实现?四种线程池?重要参数及原理?
减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下(每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机)。
17. 线程池有几种?怎么定时完成一项任务?
- newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
- newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
url
url
-
sleep和wait方法的区别
url
线程池参数及拒绝策略
- corePoolSize:线程池中的核心线程数。默认情况下核心线程一直存活在线程池中,如果将 ThreadPoolExecutor 的 allowCoreThreadTimeOut 属性设为 true,如果线程池一直闲置并超过了 keepAliveTime 所指定的时间,核心线程就会被终止。
系统资源状况主要考虑系统CPU个数以及JVM堆内存的大小。通常,线程池的大小不是硬编码在代码中,而是可配置的(如通过配置文件配置)或者动态计算出来的。动态计算出来的线程池通常是基于CPU个数计算的。在java中我们可以调用java.lang.Runtime类的avaliableProcessors方法获取JVM宿主机CPU个数。下面为了讨论方便,我们用N(cpu)表示CPU个数。
任务的特性主要考虑任务是CPU密集型、I/O密集型,还是混合型。对于CPU密集型任务,相应的线程池的大小可考虑设置为N(cpu)+1。这里,之所以线程池的大小比CPU的个数还多1个,是因为考虑到即便是CPU密集型的任务其执行线程也可能在某一时刻由于某种原因,如缺页中断而出现等待。此时,一个额外的线程可以继续使用CPU时间片。对于I/O密集型任务,相应的线程池大小可以考虑设置的相对大一点。这是因为I/O密集型任务执行过程中等待I/O的时间相对于其使用CPU的时间长,而处于I/O等待状态的线程并不会消耗CPU资源,因此相应的线程池的大小调成大于N(cpu)的
CPU密集型:CPU核数+1
IO密集型:
《Java并发编程实战》 线程数=CPU核心数*(1+IO耗时/CPU耗时)
《Java虚拟机并发编程》 线程数=CPU核心数/(1-阻塞系数)
阻塞系数=阻塞时间/(阻塞时间+计算时间) - maximumPoolSize:最大线程数,当线程不够时能够创建的最大线程数。
最大线程数=(最大任务数-队列容量)/每个线程每秒处理能力 - keepAliveTime:线程池的闲置超时时间,默认情况下对非核心线程生效,如果闲置时间超过这个时间,非核心线程就会被回收。如果 ThreadPoolExecutor 的 allowCoreThreadTimeOut 设为 true 的时候,核心线程如果超过闲置时长也会被回收。
- unit:配合 keepAliveTime 使用,用来标识 keepAliveTime 的时间单位。TimeUnit 枚举类提供了很多单位,如:纳秒、微秒、毫秒、秒、分、时、天。
- workQueue:线程池中的任务队列,使用 execute() 或 submit() 方法提交的任务都会存储在此队列中。
- threadFactory:为线程池提供创建新线程的线程工厂。
- rejectedExecutionHandler:线程池任务队列超过最大值之后的拒绝策略,RejectedExecutionHandler 是一个接口,里面只有一个 rejectedExecution 方法,可在此方法内添加任务超出最大值的事件处理。ThreadPoolExecutor 也提供了 4 种默认的拒绝策略:
- new ThreadPoolExecutor.DiscardPolicy():丢弃掉该任务,不进行处理
- new ThreadPoolExecutor.DiscardOldestPolicy():丢弃队列里最近的一个任务,并执行当前任务
- new ThreadPoolExecutor.AbortPolicy():直接抛出 RejectedExecutionException 异常
- new ThreadPoolExecutor.CallerRunsPolicy():既不抛弃任务也不抛出异常,直接使用主线程来执行此任务
workQueue任务队列:用于保存等待执行的任务的阻塞队列。可以选择以下几个阻塞队列。
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
- LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
- PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
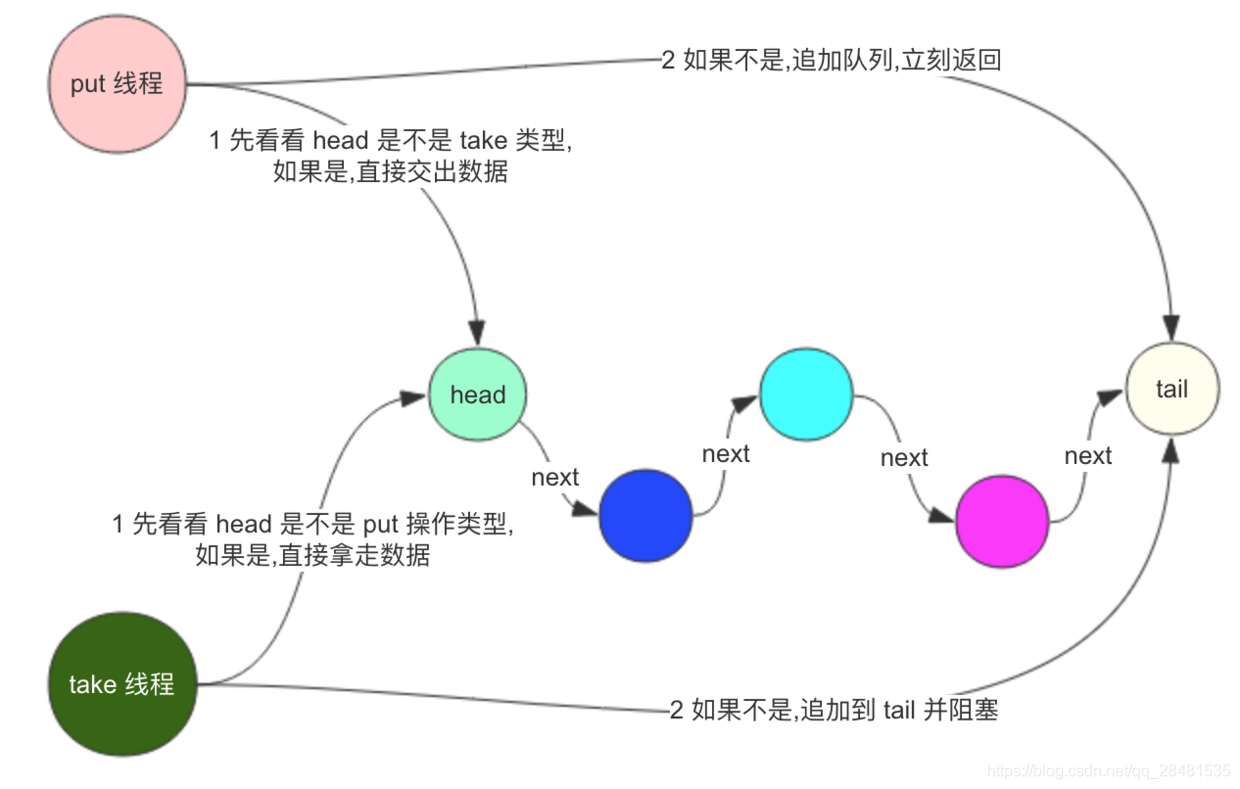
- LinkedTransferQueue:找到 head 节点,如果 head 节点是匹配的操作,就直接赋值,如果不是,添加到队列中。
注意:队列中永远只有一种类型的操作,要么是 put 类型, 要么是 take 类型.
停止线程池的几种方式
-
shutdown()
- 将线程池状态置为SHUTDOWN,并不会立即停止:
- 停止接收外部submit的任务
- 内部正在跑的任务和队列里等待的任务,会执行完
- 等到第二步完成后,才真正停止
-
shutdownNow()
- 将线程池状态置为STOP。企图立即停止,事实上不一定:
- 跟shutdown()一样,先停止接收外部提交的任务
- 忽略队列里等待的任务
- 尝试将正在跑的任务interrupt中断
- 返回未执行的任务列表
-
awaitTermination(long timeOut, TimeUnit unit)
- 当前线程阻塞,直到
- 等所有已提交的任务(包括正在跑的和队列中等待的)执行完或者等超时时间到
- 或者线程被中断,抛出InterruptedException
shutdown()和shutdownNow()的区别
从字面意思就能理解,shutdownNow()能立即停止线程池,正在跑的和正在等待的任务都停下了。这样做立即生效,但是风险也比较大;
shutdown()只是关闭了提交通道,用submit()是无效的;而内部该怎么跑还是怎么跑,跑完再停。
sychronized锁升级
url
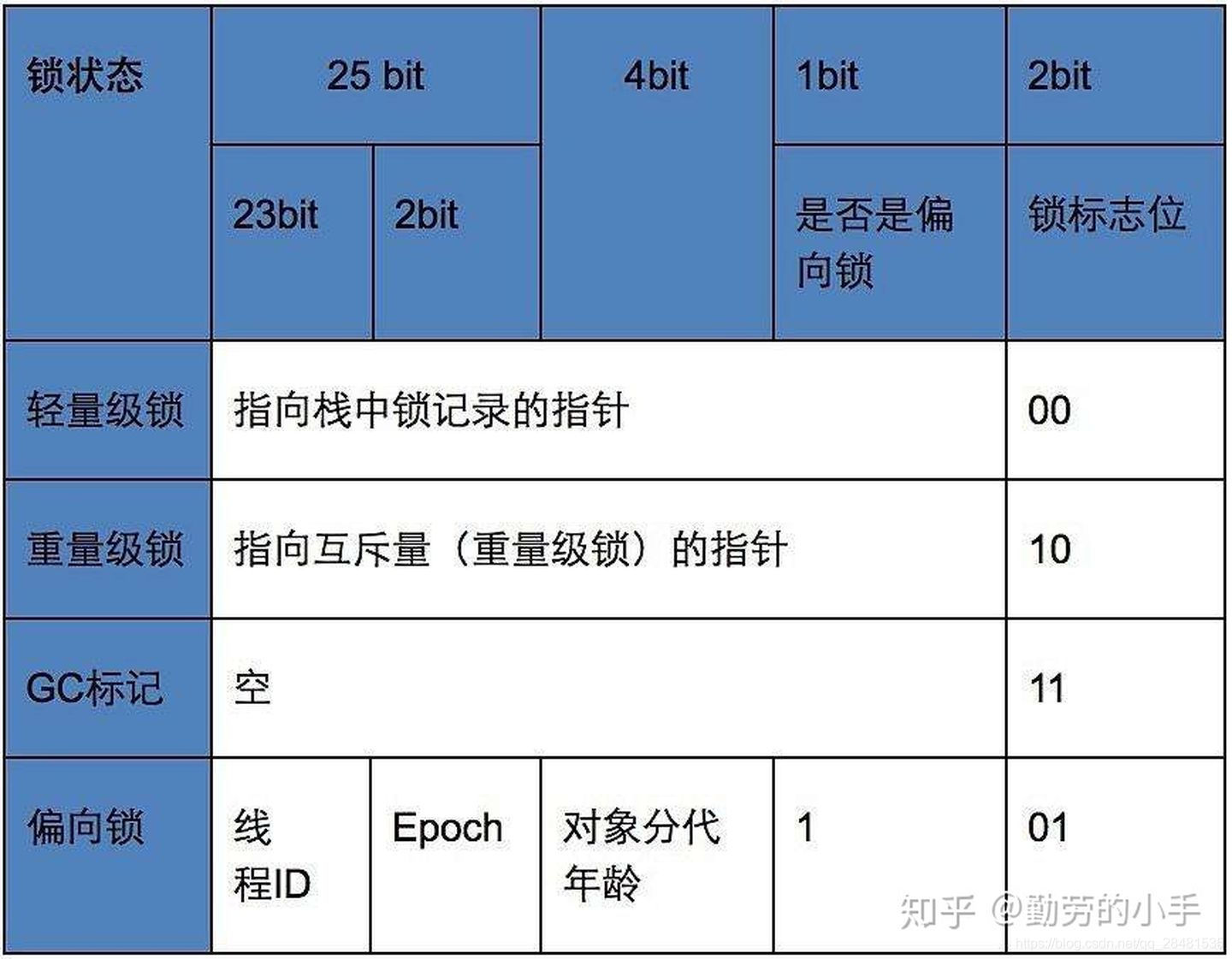
锁一共有四种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态随着竞争情况逐渐升级。为了提高获得锁和释放锁的效率,锁可以升级但不能降级,意味着偏向锁升级为轻量级锁后不能降级为偏向锁。
1.偏向锁
当一个线程访问同步块并获取锁时,会在对象头和栈帧的锁记录里存储偏向的线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需测试Mark Word里线程ID是否为当前线程。如果测试成功,表示线程已经获得了锁。如果测试失败,则需要判断偏向锁的标识。如果标识被设置为0(表示当前是无锁状态),则使用CAS竞争锁;如果标识设置成1(表示当前是偏向锁状态),则尝试使用CAS将对象头的偏向锁指向当前线程,触发偏向锁的撤销。偏向锁只有在竞争出现才会释放锁。当其他线程尝试竞争偏向锁时,程序到达全局安全点后(没有正在执行的代码),它会查看Java对象头中记录的线程是否存活,如果没有存活,那么锁对象被重置为无锁状态,其它线程可以竞争将其设置为偏向锁;如果存活,那么立刻查找该线程的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停当前线程,撤销偏向锁,升级为轻量级锁,如果线程1不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程。
2.轻量级锁
线程在执行同步块之前,JVM会先在当前线程的栈帧中创建用于存储锁记录的空间,并将对象头的MarkWord复制到锁记录中,即Displaced Mark Word。然后线程会尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁。如果失败,表示其他线程在竞争锁,当前线程使用自旋来获取锁。当自旋次数达到一定次数时,锁就会升级为重量级锁。
轻量级锁解锁时,会使用CAS操作将Displaced Mark Word替换回到对象头,如果成功,表示没有竞争发生。如果失败,表示当前锁存在竞争,锁已经被升级为重量级锁,则会释放锁并唤醒等待的线程。
Synchronyzed 重量级锁monitor 的实现
我们可以通过javac -p xxx.class来查看带有synchronyzed 关键字类的代码编译成的指令
我们发现编译成指令后每个synchronized修饰的代码块前后都会有加上一个monitorenter 和monitorexit指令, 这其实就对应了我们上面那种加锁逻辑图里的lock 和unlock操作,monitorexit 指令又两次是因为在出现异常的时候我们也需要解锁操作。
我们知道只有锁达到一定竞争情况才会使用重量级锁,而synchronized重量级锁的实现原理就是基于Monitor,monitor封装了一套多线程访问共享变量机制以达到互斥和同步的机,下面我们简单的了解下Monitor实现的流程。
这里我们把sychronized修饰的代码块当做一个临界区,当线程进入临界区内时首先要获得对应的锁,这里我们简把monitorEnter指令理解为获取锁的过程,获取锁成功则可以进入临界区,获取锁 失败时,会把当前线程放到一个等待队列里面去,线程置为wait状态;当前面的线进入临界区执行完之后,再释放锁,我们可以把monitorExit 指令理解为释放锁的过程,锁释放后再从等待队列里面唤醒线程,进行下一轮的锁竞争。
AQS
1. 概述
谈到并发,不得不谈ReentrantLock;而谈到ReentrantLock,不得不谈AbstractQueuedSynchronized(AQS)!
类如其名,抽象的队列式的同步器,AQS定义了一套多线程访问共享资源的同步器框架,许多同步类实现都依赖于它,如常用的ReentrantLock/Semaphore/CountDownLatch…。
以下是本文的目录大纲:
1.1. 概述
2.1. 框架
3.1. 源码详解
4.1. 简单应用
2. 框架
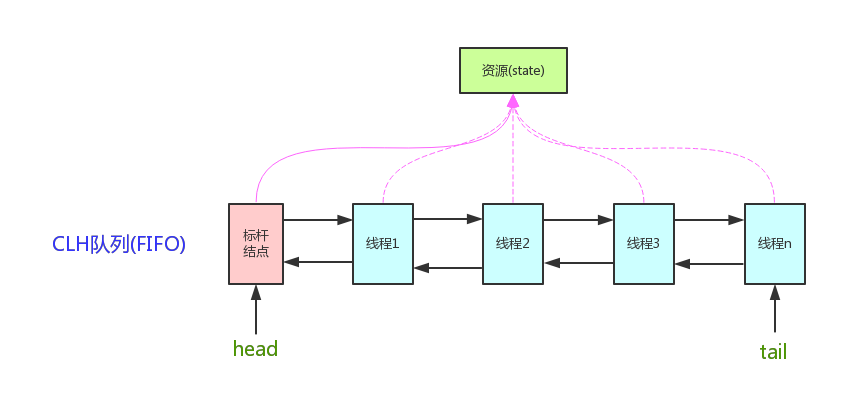
它维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)。这里volatile是核心关键词,具体volatile的语义,在此不述。state的访问方式有三种:
- getState()
- setState()
- compareAndSetState()
AQS定义两种资源共享方式:Exclusive(独占,只有一个线程能执行,如ReentrantLock)和Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源state的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。自定义同步器实现时主要实现以下几种方法: - isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
- tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
- tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
- tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
- tryReleaseShared(int):共享方式。尝试释放资源,成功则返回true,失败则返回false。
以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。
3. 源码详解
本节开始讲解AQS的源码实现。依照acquire-release、acquireShared-releaseShared的次序来。
3.1. acquire(int)
此方法是独占模式下线程获取共享资源的顶层入口。如果获取到资源,线程直接返回,否则进入等待队列,直到获取到资源为止,且整个过程忽略中断的影响。这也正是lock()的语义,当然不仅仅只限于lock()。获取到资源后,线程就可以去执行其临界区代码了。下面是acquire()的源码:
1 public final void acquire(int arg) {
2 if (!tryAcquire(arg) &&
3 acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
4 selfInterrupt();
5 }
函数流程如下:
1. tryAcquire()尝试直接去获取资源,如果成功则直接返回;
2. addWaiter()将该线程加入等待队列的尾部,并标记为独占模式;
3. acquireQueued()使线程在等待队列中获取资源,一直获取到资源后才返回。如果在整个等待过程中被中断过,则返回true,否则返回false。
4. 如果线程在等待过程中被中断过,它是不响应的。只是获取资源后才再进行自我中断selfInterrupt(),将中断补上。
这时单凭这4个抽象的函数来看流程还有点朦胧,不要紧,看完接下来的分析后,你就会明白了。就像《大话西游》里唐僧说的:等你明白了舍生取义的道理,你自然会回来和我唱这首歌的。
3.1.1. tryAcquire(int)
此方法尝试去获取独占资源。如果获取成功,则直接返回true,否则直接返回false。这也正是tryLock()的语义,还是那句话,当然不仅仅只限于tryLock()。如下是tryAcquire()的源码:
1 protected boolean tryAcquire(int arg) {
2 throw new UnsupportedOperationException();
3 }
什么?直接throw异常?说好的功能呢?好吧,还记得概述里讲的AQS只是一个框架,具体资源的获取/释放方式交由自定义同步器去实现吗?就是这里了!!!AQS这里只定义了一个接口,具体资源的获取交由自定义同步器去实现了(通过state的get/set/CAS)!!!至于能不能重入,能不能加塞,那就看具体的自定义同步器怎么去设计了!!!当然,自定义同步器在进行资源访问时要考虑线程安全的影响。
这里之所以没有定义成abstract,是因为独占模式下只用实现tryAcquire-tryRelease,而共享模式下只用实现tryAcquireShared-tryReleaseShared。如果都定义成abstract,那么每个模式也要去实现另一模式下的接口。说到底,Doug Lea还是站在咱们开发者的角度,尽量减少不必要的工作量。
3.1.2 addWaiter(Node)
此方法用于将当前线程加入到等待队列的队尾,并返回当前线程所在的结点。还是上源码吧:
1 private Node addWaiter(Node mode) {
2 //以给定模式构造结点。mode有两种:EXCLUSIVE(独占)和SHARED(共享)
3 Node node = new Node(Thread.currentThread(), mode);
4
5 //尝试快速方式直接放到队尾。
6 Node pred = tail;
7 if (pred != null) {
8 node.prev = pred;
9 if (compareAndSetTail(pred, node)) {
10 pred.next = node;
11 return node;
12 }
13 }
14
15 //上一步失败则通过enq入队。
16 enq(node);
17 return node;
18 }
不用再说了,直接看注释吧。
3.1.2.1 enq(Node)
此方法用于将node加入队尾。源码如下:
1 private Node enq(final Node node) {
2 //CAS"自旋",直到成功加入队尾
3 for (;;) {
4 Node t = tail;
5 if (t == null) { // 队列为空,创建一个空的标志结点作为head结点,并将tail也指向它。
6 if (compareAndSetHead(new Node()))
7 tail = head;
8 } else {//正常流程,放入队尾
9 node.prev = t;
10 if (compareAndSetTail(t, node)) {
11 t.next = node;
12 return t;
13 }
14 }
15 }
16 }
如果你看过AtomicInteger.getAndIncrement()函数源码,那么相信你一眼便看出这段代码的精华。CAS自旋volatile变量,是一种很经典的用法。还不太了解的,自己去百度一下吧。
3.1.3 acquireQueued(Node, int)
OK,通过tryAcquire()和addWaiter(),该线程获取资源失败,已经被放入等待队列尾部了。聪明的你立刻应该能想到该线程下一部该干什么了吧:进入等待状态休息,直到其他线程彻底释放资源后唤醒自己,自己再拿到资源,然后就可以去干自己想干的事了。没错,就是这样!是不是跟医院排队拿号有点相似。acquireQueued()就是干这件事:在等待队列中排队拿号(中间没其它事干可以休息),直到拿到号后再返回。这个函数非常关键,还是上源码吧:
1 final boolean acquireQueued(final Node node, int arg) {
2 boolean failed = true;//标记是否成功拿到资源
3 try {
4 boolean interrupted = false;//标记等待过程中是否被中断过
5
6 //又是一个“自旋”!
7 for (;;) {
8 final Node p = node.predecessor();//拿到前驱
9 //如果前驱是head,即该结点已成老二,那么便有资格去尝试获取资源(可能是老大释放完资源唤醒自己的,当然也可能被interrupt了)。
10 if (p == head && tryAcquire(arg)) {
11 setHead(node);//拿到资源后,将head指向该结点。所以head所指的标杆结点,就是当前获取到资源的那个结点或null。
12 p.next = null; // setHead中node.prev已置为null,此处再将head.next置为null,就是为了方便GC回收以前的head结点。也就意味着之前拿完资源的结点出队了!
13 failed = false;
14 return interrupted;//返回等待过程中是否被中断过
15 }
16
17 //如果自己可以休息了,就进入waiting状态,直到被unpark()
18 if (shouldParkAfterFailedAcquire(p, node) &&
19 parkAndCheckInterrupt())
20 interrupted = true;//如果等待过程中被中断过,哪怕只有那么一次,就将interrupted标记为true
21 }
22 } finally {
23 if (failed)
24 cancelAcquire(node);
25 }
26 }
到这里了,我们先不急着总结acquireQueued()的函数流程,先看看shouldParkAfterFailedAcquire()和parkAndCheckInterrupt()具体干些什么。
3.1.3.1 shouldParkAfterFailedAcquire(Node, Node)
此方法主要用于检查状态,看看自己是否真的可以去休息了(进入waiting状态,如果线程状态转换不熟,可以参考本人上一篇写的Thread详解),万一队列前边的线程都放弃了只是瞎站着,那也说不定,对吧!
1 private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
2 int ws = pred.waitStatus;//拿到前驱的状态
3 if (ws == Node.SIGNAL)
4 //如果已经告诉前驱拿完号后通知自己一下,那就可以安心休息了
5 return true;
6 if (ws > 0) {
7 /*
8 * 如果前驱放弃了,那就一直往前找,直到找到最近一个正常等待的状态,并排在它的后边。
9 * 注意:那些放弃的结点,由于被自己“加塞”到它们前边,它们相当于形成一个无引用链,稍后就会被保安大叔赶走了(GC回收)!
10 */
11 do {
12 node.prev = pred = pred.prev;
13 } while (pred.waitStatus > 0);
14 pred.next = node;
15 } else {
16 //如果前驱正常,那就把前驱的状态设置成SIGNAL,告诉它拿完号后通知自己一下。有可能失败,人家说不定刚刚释放完呢!
17 compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
18 }
19 return false;
20 }
整个流程中,如果前驱结点的状态不是SIGNAL,那么自己就不能安心去休息,需要去找个安心的休息点,同时可以再尝试下看有没有机会轮到自己拿号。
3.1.3.2 parkAndCheckInterrupt()
如果线程找好安全休息点后,那就可以安心去休息了。此方法就是让线程去休息,真正进入等待状态。
1 private final boolean parkAndCheckInterrupt() {
2 LockSupport.park(this);//调用park()使线程进入waiting状态
3 return Thread.interrupted();//如果被唤醒,查看自己是不是被中断的。
4 }
park()会让当前线程进入waiting状态。在此状态下,有两种途径可以唤醒该线程:1)被unpark();2)被interrupt()。(再说一句,如果线程状态转换不熟,可以参考本人写的Thread详解)。需要注意的是,Thread.interrupted()会清除当前线程的中断标记位。
3.1.3.3 小结
OK,看了shouldParkAfterFailedAcquire()和parkAndCheckInterrupt(),现在让我们再回到acquireQueued(),总结下该函数的具体流程:
- 结点进入队尾后,检查状态,找到安全休息点;
- 调用park()进入waiting状态,等待unpark()或interrupt()唤醒自己;
- 被唤醒后,看自己是不是有资格能拿到号。如果拿到,head指向当前结点,并返回从入队到拿到号的整个过程中是否被中断过;如果没拿到,继续流程1。
3.1.4 小结
OKOK,acquireQueued()分析完之后,我们接下来再回到acquire()!再贴上它的源码吧:
1 public final void acquire(int arg) {
2 if (!tryAcquire(arg) &&
3 acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
4 selfInterrupt();
5 }
再来总结下它的流程吧:
- 调用自定义同步器的tryAcquire()尝试直接去获取资源,如果成功则直接返回;
- 没成功,则addWaiter()将该线程加入等待队列的尾部,并标记为独占模式;
- acquireQueued()使线程在等待队列中休息,有机会时(轮到自己,会被unpark())会去尝试获取资源。获取到资源后才返回。如果在整个等待过程中被中断过,则返回true,否则返回false。
- 如果线程在等待过程中被中断过,它是不响应的。只是获取资源后才再进行自我中断selfInterrupt(),将中断补上。
由于此函数是重中之重,我再用流程图总结一下:
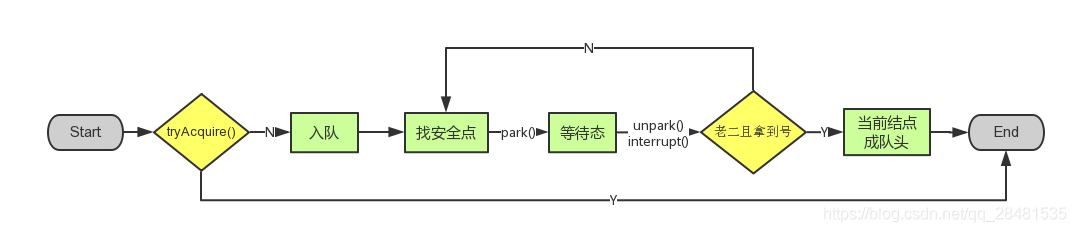
至此,acquire()的流程终于算是告一段落了。这也就是ReentrantLock.lock()的流程,不信你去看其lock()源码吧,整个函数就是一条acquire(1)!!!
3.2 release(int)
上一小节已经把acquire()说完了,这一小节就来讲讲它的反操作release()吧。此方法是独占模式下线程释放共享资源的顶层入口。它会释放指定量的资源,如果彻底释放了(即state=0),它会唤醒等待队列里的其他线程来获取资源。这也正是unlock()的语义,当然不仅仅只限于unlock()。下面是release()的源码:
1 public final boolean release(int arg) {
2 if (tryRelease(arg)) {
3 Node h = head;//找到头结点
4 if (h != null && h.waitStatus != 0)
5 unparkSuccessor(h);//唤醒等待队列里的下一个线程
6 return true;
7 }
8 return false;
9 }
逻辑并不复杂。它调用tryRelease()来释放资源。有一点需要注意的是,它是根据tryRelease()的返回值来判断该线程是否已经完成释放掉资源了!所以自定义同步器在设计tryRelease()的时候要明确这一点!!
3.2.1 tryRelease(int)
此方法尝试去释放指定量的资源。下面是tryRelease()的源码:
1 protected boolean tryRelease(int arg) {
2 throw new UnsupportedOperationException();
3 }
跟tryAcquire()一样,这个方法是需要独占模式的自定义同步器去实现的。正常来说,tryRelease()都会成功的,因为这是独占模式,该线程来释放资源,那么它肯定已经拿到独占资源了,直接减掉相应量的资源即可(state-=arg),也不需要考虑线程安全的问题。但要注意它的返回值,上面已经提到了,release()是根据tryRelease()的返回值来判断该线程是否已经完成释放掉资源了!所以自义定同步器在实现时,如果已经彻底释放资源(state=0),要返回true,否则返回false。
3.2.2 unparkSuccessor(Node)
此方法用于唤醒等待队列中下一个线程。下面是源码:
1 private void unparkSuccessor(Node node) {
2 //这里,node一般为当前线程所在的结点。
3 int ws = node.waitStatus;
4 if (ws < 0)//置零当前线程所在的结点状态,允许失败。
5 compareAndSetWaitStatus(node, ws, 0);
6
7 Node s = node.next;//找到下一个需要唤醒的结点s
8 if (s == null || s.waitStatus > 0) {//如果为空或已取消
9 s = null;
10 for (Node t = tail; t != null && t != node; t = t.prev)
11 if (t.waitStatus <= 0)//从这里可以看出,<=0的结点,都是还有效的结点。
12 s = t;
13 }
14 if (s != null)
15 LockSupport.unpark(s.thread);//唤醒16 }
这个函数并不复杂。一句话概括:用unpark()唤醒等待队列中最前边的那个未放弃线程,这里我们也用s来表示吧。此时,再和acquireQueued()联系起来,s被唤醒后,进入if (p == head && tryAcquire(arg))的判断(即使p!=head也没关系,它会再进入shouldParkAfterFailedAcquire()寻找一个安全点。这里既然s已经是等待队列中最前边的那个未放弃线程了,那么通过shouldParkAfterFailedAcquire()的调整,s也必然会跑到head的next结点,下一次自旋p==head就成立啦),然后s把自己设置成head标杆结点,表示自己已经获取到资源了,acquire()也返回了!!And then, DO what you WANT!
3.2.3 小结
release()是独占模式下线程释放共享资源的顶层入口。它会释放指定量的资源,如果彻底释放了(即state=0),它会唤醒等待队列里的其他线程来获取资源。
3.3 acquireShared(int)
此方法是共享模式下线程获取共享资源的顶层入口。它会获取指定量的资源,获取成功则直接返回,获取失败则进入等待队列,直到获取到资源为止,整个过程忽略中断。下面是acquireShared()的源码:
1 public final void acquireShared(int arg) {
2 if (tryAcquireShared(arg) < 0)
3 doAcquireShared(arg);
4 }
这里tryAcquireShared()依然需要自定义同步器去实现。但是AQS已经把其返回值的语义定义好了:负值代表获取失败;0代表获取成功,但没有剩余资源;正数表示获取成功,还有剩余资源,其他线程还可以去获取。所以这里acquireShared()的流程就是:
1. tryAcquireShared()尝试获取资源,成功则直接返回;
2. 失败则通过doAcquireShared()进入等待队列,直到获取到资源为止才返回。
3.3.1 doAcquireShared(int)
此方法用于将当前线程加入等待队列尾部休息,直到其他线程释放资源唤醒自己,自己成功拿到相应量的资源后才返回。下面是doAcquireShared()的源码:
1 private void doAcquireShared(int arg) {
2 final Node node = addWaiter(Node.SHARED);//加入队列尾部 3 boolean failed = true;//是否成功标志 4 try {
5 boolean interrupted = false;//等待过程中是否被中断过的标志 6 for (;;) {
7 final Node p = node.predecessor();//前驱 8 if (p == head) {//如果到head的下一个,因为head是拿到资源的线程,此时node被唤醒,很可能是head用完资源来唤醒自己的 9 int r = tryAcquireShared(arg);//尝试获取资源10 if (r >= 0) {//成功11 setHeadAndPropagate(node, r);//将head指向自己,还有剩余资源可以再唤醒之后的线程12 p.next = null; // help GC13 if (interrupted)//如果等待过程中被打断过,此时将中断补上。14 selfInterrupt();
15 failed = false;
16 return;
17 }
18 }
19
20 //判断状态,寻找安全点,进入waiting状态,等着被unpark()或interrupt()21 if (shouldParkAfterFailedAcquire(p, node) &&
22 parkAndCheckInterrupt())
23 interrupted = true;
24 }
25 } finally {
26 if (failed)
27 cancelAcquire(node);
28 }
29 }
有木有觉得跟acquireQueued()很相似?对,其实流程并没有太大区别。只不过这里将补中断的selfInterrupt()放到doAcquireShared()里了,而独占模式是放到acquireQueued()之外,其实都一样,不知道Doug Lea是怎么想的。
跟独占模式比,还有一点需要注意的是,这里只有线程是head.next时(“老二”),才会去尝试获取资源,有剩余的话还会唤醒之后的队友。那么问题就来了,假如老大用完后释放了5个资源,而老二需要6个,老三需要1个,老四需要2个。因为老大先唤醒老二,老二一看资源不够自己用继续park(),也更不会去唤醒老三和老四了。独占模式,同一时刻只有一个线程去执行,这样做未尝不可;但共享模式下,多个线程是可以同时执行的,现在因为老二的资源需求量大,而把后面量小的老三和老四也都卡住了。
3.3.1.1 setHeadAndPropagate(Node, int)
1 private void setHeadAndPropagate(Node node, int propagate) {
2 Node h = head;
3 setHead(node);//head指向自己
4 //如果还有剩余量,继续唤醒下一个邻居线程 5 if (propagate > 0 || h == null || h.waitStatus < 0) {
6 Node s = node.next;
7 if (s == null || s.isShared())
8 doReleaseShared();
9 }
10 }
此方法在setHead()的基础上多了一步,就是自己苏醒的同时,如果条件符合(比如还有剩余资源),还会去唤醒后继结点,毕竟是共享模式!
doReleaseShared()我们留着下一小节的releaseShared()里来讲。
3.3.2 小结
OK,至此,acquireShared()也要告一段落了。让我们再梳理一下它的流程:
1. tryAcquireShared()尝试获取资源,成功则直接返回;
2. 失败则通过doAcquireShared()进入等待队列park(),直到被unpark()/interrupt()并成功获取到资源才返回。整个等待过程也是忽略中断的。
其实跟acquire()的流程大同小异,只不过多了个自己拿到资源后,还会去唤醒后继队友的操作(这才是共享嘛)。
3.4 releaseShared()
上一小节已经把acquireShared()说完了,这一小节就来讲讲它的反操作releaseShared()吧。此方法是共享模式下线程释放共享资源的顶层入口。它会释放指定量的资源,如果彻底释放了(即state=0),它会唤醒等待队列里的其他线程来获取资源。下面是releaseShared()的源码:
1 public final boolean releaseShared(int arg) {
2 if (tryReleaseShared(arg)) {//尝试释放资源3
doReleaseShared();//唤醒后继结点4
return true;
5 }
6 return false;
7 }
此方法的流程也比较简单,一句话:释放掉资源后,唤醒后继。跟独占模式下的release()相似,但有一点稍微需要注意:独占模式下的tryRelease()在完全释放掉资源(state=0)后,才会返回true去唤醒其他线程,这主要是基于可重入的考量;而共享模式下的releaseShared()则没有这种要求,一是共享的实质–多线程可并发执行;二是共享模式基本也不会重入吧(至少我还没见过),所以自定义同步器可以根据需要决定返回值。
3.4.1 doReleaseShared()
此方法主要用于唤醒后继。下面是它的源码:
1 private void doReleaseShared() {
2 for (;;) {
3 Node h = head;
4 if (h != null && h != tail) {
5 int ws = h.waitStatus;
6 if (ws == Node.SIGNAL) {
7 if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
8 continue;
9 unparkSuccessor(h);//唤醒后继10 }
11 else if (ws == 0 &&
12 !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
13 continue;
14 }
15 if (h == head)// head发生变化16 break;
17 }
18 }
3.5 小结
本节我们详解了独占和共享两种模式下获取-释放资源(acquire-release、acquireShared-releaseShared)的源码,相信大家都有一定认识了。值得注意的是,acquire()和acquireSahred()两种方法下,线程在等待队列中都是忽略中断的。AQS也支持响应中断的,acquireInterruptibly()/acquireSharedInterruptibly()即是,这里相应的源码跟acquire()和acquireSahred()差不多,这里就不再详解了。
4. 简单应用
通过前边几个章节的学习,相信大家已经基本理解AQS的原理了。这里再将“框架”一节中的一段话复制过来:
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源state的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。自定义同步器实现时主要实现以下几种方法:
- isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
- tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
- tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
- tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
- tryReleaseShared(int):共享方式。尝试释放资源,成功则返回true,失败则返回false。
OK,下面我们就以AQS源码里的Mutex为例,讲一下AQS的简单应用。
4.1 Mutex(互斥锁)
Mutex是一个不可重入的互斥锁实现。锁资源(AQS里的state)只有两种状态:0表示未锁定,1表示锁定。下边是Mutex的核心源码:
class Mutex implements Lock, java.io.Serializable {
// 自定义同步器
private static class Sync extends AbstractQueuedSynchronizer {
// 判断是否锁定状态
protected boolean isHeldExclusively() {
return getState() == 1;
}
// 尝试获取资源,立即返回。成功则返回true,否则false。
public boolean tryAcquire(int acquires) {
assert acquires == 1; // 这里限定只能为1个量
if (compareAndSetState(0, 1)) {
//state为0才设置为1,不可重入!
setExclusiveOwnerThread(Thread.currentThread());//设置为当前线程独占资源
return true;
}
return false;
}
// 尝试释放资源,立即返回。成功则为true,否则false。
protected boolean tryRelease(int releases) {
assert releases == 1; // 限定为1个量
if (getState() == 0)//既然来释放,那肯定就是已占有状态了。只是为了保险,多层判断!
throw new IllegalMonitorStateException();
setExclusiveOwnerThread(null);
setState(0);//释放资源,放弃占有状态
return true;
}
}
// 真正同步类的实现都依赖继承于AQS的自定义同步器!
private final Sync sync = new Sync();
//lock<-->acquire。两者语义一样:获取资源,即便等待,直到成功才返回。
public void lock() {
sync.acquire(1);
}
//tryLock<-->tryAcquire。两者语义一样:尝试获取资源,要求立即返回。成功则为true,失败则为false。
public boolean tryLock() {
return sync.tryAcquire(1);
}
//unlock<-->release。两者语文一样:释放资源。
public void unlock() {
sync.release(1);
}
//锁是否占有状态
public boolean isLocked() {
return sync.isHeldExclusively();
}
}
同步类在实现时一般都将自定义同步器(sync)定义为内部类,供自己使用;而同步类自己(Mutex)则实现某个接口,对外服务。当然,接口的实现要直接依赖sync,它们在语义上也存在某种对应关系!!而sync只用实现资源state的获取-释放方式tryAcquire-tryRelelase,至于线程的排队、等待、唤醒等,上层的AQS都已经实现好了,我们不用关心。
除了Mutex,ReentrantLock/CountDownLatch/Semphore这些同步类的实现方式都差不多,不同的地方就在获取-释放资源的方式tryAcquire-tryRelelase。掌握了这点,AQS的核心便被攻破了!
ReentrantLock是基于AQS实现的,AQS是一个抽象的队列同步器,自定义同步器只需要实现tryAcquire/tryRelease-
tryAcquireShared/tryReleaseShared即可,线程队列的维护,由AQS实现。
ReentrantLock内部有个抽象类Sync,它有两个实现:FairSync和NoFairSync。分别实现了公平锁和非公平锁。
当调用ReentrantLock的lock方法的时候,它要调用Sync的lock方法。
根据具体创建的是公平锁还是非公平锁进行不同的调用,他们唯一的区别就是:
公平锁:谁先到,谁先执行acquire方法,遵守先来先到,在公平锁的lock方法中也只有acquire一个方法。
非公平锁:同时获取锁,谁能抢到到锁谁就先执行,同时去CAS state的值。没获取到锁的线程在执行acquire方法。
在AQS的acquire方法中,主要就是一个if的&&的判断,首先使用它们自定义实现的tryAcquire方法去获取锁,它们的
tryAcquire方法如果发现state为0 就CAS设置state的值为1,然后将自己设置为该锁的拥有者,同时在改方法中还可以进行可重入的state的叠加。如果获取失败,&&第一个条件成立,执行第二个条件。首先调用addwaiter方法,将线程加入等待队列,这个队列是一个双向的队列。FIFO准则。
在addwaiter方法中,会CAS 把自己设置成队尾。如果设置失败则调用enq进行自旋CAS设置成队尾。设置成功之后返回新建的Node。然后acquiredQueue方法执行,该方法的参数就是返回的Node
在acquiredQueue方法中,有一个中断标记,用于标记该线程是否中断过。然后就是一个自旋的过程,首先获取该节点的前驱,如果前驱是头结点,那么就再次获取锁,如果获取成功将本节点设置成头节点,然后返回中断标记。如果前驱节点不是头节点,就会调用shouldParkAfterFailedAcquire方法,进行安全点的设置。在shouldParkAfterFailedAcquire方法中,首先获取前驱节点的状态值,如果状态值等于signal(-1)就直接返回true,前驱节点状态值为-1 说明它后面有等待锁的线程,当前驱节点释放锁之后需要唤醒后面的节点。
如果前驱节点的状态值大于0,说明节点持有的线程已经被取消,循环剔除前面全部被取消的线程。
如果条件都不满足,就可以把前驱节点的状态值设置成-1了。
找到安全点之后并返回ture之后,就执行parkAndCheckInterrupt进行线程的阻塞。当被唤醒之后,会检查是否被中断过,如果被中断过,该方法就会返回true,之后就会将中断标记设置成true。最后会在acquire的if 中将中断补上。
HashMap
判断数组是否为空,为空进行初始化;
不为空,计算 k 的 hash 值,通过(n - 1) & hash计算应当存放在数组中的下标 index;
查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;
存在数据,说明发生了hash冲突(存在二个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据(onlyIfAbsent为false);
如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;(如果当前节点是树型节点证明当前已经是红黑树了)
如果不是树型节点,创建普通Node加入链表中;判断链表长度是否大于 8并且数组长度大于64, 大于的话链表转换为红黑树;
插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的二倍。
Concurrenthashmap线程安全的
concurrentHashMap是没有做到线程强一致的,只满足了最终一致性
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashMap类似,是一种数组和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁,如下图所示。
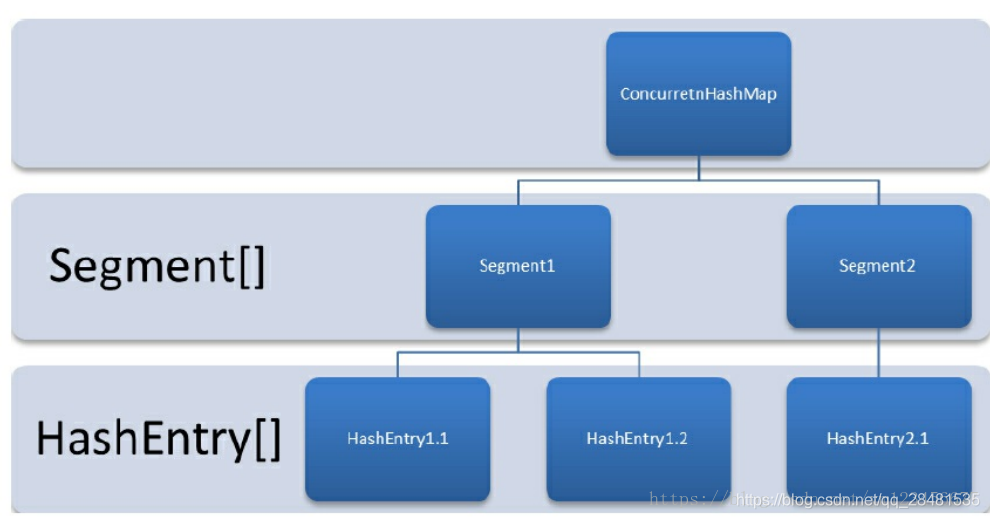
ConcurrentHashMap初始化时,计算出Segment数组的大小ssize和每个Segment中HashEntry数组的大小cap,并初始化Segment数组的第一个元素;其中ssize大小为2的幂次方,默认为16,cap大小也是2的幂次方,最小值为2,最终结果根据根据初始化容量initialCapacity进行计算,其中Segment在实现上继承了ReentrantLock,这样就自带了锁的功能。
当执行put方法插入数据时,根据key的hash值,在Segment数组中找到相应的位置,如果相应位置的Segment还未初始化,则通过CAS进行赋值,接着执行Segment对象的put方法通过加锁机制插入数据。
1、线程A执行tryLock()方法成功获取锁,则把HashEntry对象插入到相应的位置;
2、线程B获取锁失败,则执行scanAndLockForPut()方法,在scanAndLockForPut方法中,会通过重复执行tryLock()方法尝试获取锁,在多处理器环境下,重复次数为64,单处理器重复次数为1,当执行tryLock()方法的次数超过上限时,则执行lock()方法挂起线程B;
3、当线程A执行完插入操作时,会通过unlock()方法释放锁,接着唤醒线程B继续执行;
size实现
因为ConcurrentHashMap是可以并发插入数据的,所以在准确计算元素时存在一定的难度,一般的思路是统计每个Segment对象中的元素个数,然后进行累加,但是这种方式计算出来的结果并不一样的准确的,因为在计算后面几个Segment的元素个数时,已经计算过的Segment同时可能有数据的插入或则删除,在1.7的实现中,采用了如下方式:
先采用不加锁的方式,连续计算元素的个数,最多计算3次:
1、如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;
2、如果前后两次计算结果都不同,则给每个 Segment 进行加锁,再计算一次元素的个数;
1.8实现
ConcurrentHashMap在1.8中的实现,相比于1.7的版本基本上全部都变掉了。首先,取消了Segment分段锁的数据结构,取而代之的是数组+链表(红黑树)的结构。而对于锁的粒度,调整为对每个数组元素加锁(Node)。然后是定位节点的hash算法被简化了,这样带来的弊端是Hash冲突会加剧。因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。这样一来,查询的时间复杂度就会由原先的O(n)变为O(logN)。下面是其基本结构:
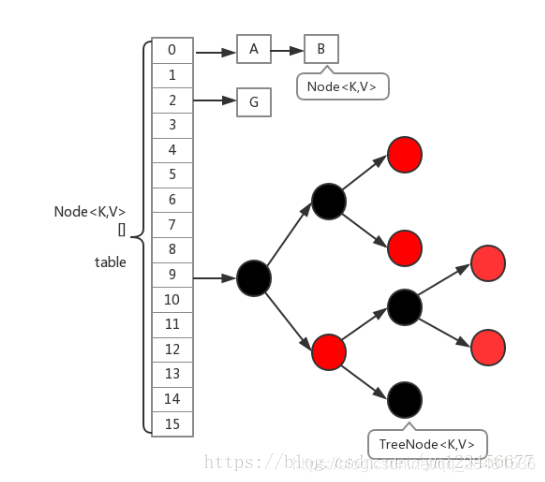
1.8中放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,
只有在执行第一次put方法时才会调用initTable()初始化Node数组,实现如下:
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
put实现
当执行put方法插入数据时,根据key的hash值,在Node数组中找到相应的位置,实现如下:
1、如果相应位置的Node还未初始化,则通过CAS插入相应的数据;
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
2、如果相应位置的Node不为空,且当前该节点不处于移动状态,则对该节点加synchronized锁,如果该节点的hash不小于0,则遍历链表更新节点或插入新节点;
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value, null);
break;
}
}
}
3、如果该节点是TreeBin类型的节点,说明是红黑树结构,则通过putTreeVal方法往红黑树中插入节点;
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
4、如果binCount不为0,说明put操作对数据产生了影响,如果当前链表的个数达到8个,则通过treeifyBin方法转化为红黑树,如果oldVal不为空,说明是一次更新操作,没有对元素个数产生影响,则直接返回旧值;
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
5、如果插入的是一个新节点,则执行addCount()方法尝试更新元素个数baseCount;
size实现
1.8中使用一个volatile类型的变量baseCount记录元素的个数,当插入新数据或则删除数据时,会通过addCount()方法更新baseCount,实现如下:
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
1、初始化时counterCells为空,在并发量很高时,如果存在两个线程同时执行CAS修改baseCount值,则失败的线程会继续执行方法体中的逻辑,使用CounterCell记录元素个数的变化;
2、如果CounterCell数组counterCells为空,调用fullAddCount()方法进行初始化,并插入对应的记录数,通过CAS设置cellsBusy字段,只有设置成功的线程才能初始化CounterCell数组,实现如下:
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try { // Initialize table
if (counterCells == as) {
CounterCell[] rs = new CounterCell[2];
rs[h & 1] = new CounterCell(x);
counterCells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
3、如果通过CAS设置cellsBusy字段失败的话,则继续尝试通过CAS修改baseCount字段,如果修改baseCount字段成功的话,就退出循环,否则继续循环插入CounterCell对象;
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break;
所以在1.8中的size实现比1.7简单多,因为元素个数保存baseCount中,部分元素的变化个数保存在CounterCell数组中,实现如下:
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
通过累加baseCount和CounterCell数组中的数量,即可得到元素的总个数;
spring
https://blog.youkuaiyun.com/zl1zl2zl3/article/details/81865407
spring实现事务的原理
@Transactional的工作机制是基于AOP实现的,而AOP是使用动态代理实现的,动态代理要么是JDK方式、要么是Cglib方式。如果是JDK动态代理的方式,根据上面的分析可以知道,目标类的目标方法是在接口中定义的,也就是必须是public修饰的方法才可以被代理。如果是Cglib方式,代理类是目标类的子类,理论上可以代理public和protected方法,但是Spring在进行事务增强是否能够应用到当前目标类判断的时候,遍历的是目标类的public方法,所以Cglib方式也只对public方法有效。
Spring框架中声明式事务处理是如何实现的?
小小白:Spring容器在初始化每个单例bean的时候,会遍历容器中的所有BeanPostProcessor实现类,并执行其postProcessAfterInitialization方法,在执行AbstractAutoProxyCreator类的postProcessAfterInitialization方法时会遍历容器中所有的切面,查找与当前实例化bean匹配的切面,这里会获取事务属性切面,查找@Transactional注解及其属性值,然后根据得到的切面创建一个代理对象,默认是使用JDK动态代理创建代理,如果目标类是接口,则使用JDK动态代理,否则使用Cglib。在创建代理的过程中会获取当前目标方法对应的拦截器,此时会得到TransactionInterceptor实例,在它的invoke方法中实现事务的开启和回滚,在需要进行事务操作的时候,Spring会在调用目标类的目标方法之前进行开启事务、调用异常回滚事务、调用完成会提交事务。是否需要开启新事务,是根据@Transactional注解上配置的参数值来判断的。如果需要开启新事务,获取Connection连接,然后将连接的自动提交事务改为false,改为手动提交。当对目标类的目标方法进行调用的时候,若发生异常将会进入completeTransactionAfterThrowing方法。
能否通俗的讲述一下它的实现原理?
如果在类A上标注Transactional注解,Spring容器会在启动的时候,为类A创建一个代理类B,类A的所有public方法都会在代理类B中有一个对应的代理方法,调用类A的某个public方法会进入对应的代理方法中进行处理;如果只在类A的b方法(使用public修饰)上标注Transactional注解,Spring容器会在启动的时候,为类A创建一个代理类B,但只会为类A的b方法创建一个代理方法,调用类A的b方法会进入对应的代理方法中进行处理,调用类A的其它public方法,则还是进入类A的方法中处理。在进入代理类的某个方法之前,会先执行TransactionInterceptor类中的invoke方法,完成整个事务处理的逻辑,如是否开启新事务、在目标方法执行期间监测是否需要回滚事务、目标方法执行完成后提交事务等。
Spring框架对事务回滚的实现,是不是对所有类型的异常都会进行事务回滚操作?
Spring并不会对所有类型异常都进行事务回滚操作,默认是只对Unchecked Exception(Error和RuntimeException)进行事务回滚操作。
有没有遇到过Transactional注解的不合理用法?
当下对数据库连接的使用基本上都用连接池技术,每个应用会根据环境和自身需求设置一些合适的连接池配置,如果每个连接都一直被长时间占用,会导致数据库连接数不够用、系统各项压力指标不断攀升、系统缓慢等问题,所以说连接池中的每一个连接都是很昂贵的。那么问题就来了,只要需要事务就需要占用一个数据库连接,如果在需要开启事务的方法里进行一些IO操作、网络通讯等需要长时间处理的操作,这个数据库连接就一直被占用着,直到方法执行结束后自动提交事务或执行过程中发生异常回滚事务,这个数据库连接才会被释放掉。这个过程中还有一个很可怕的问题,如果在需要开启事务的方法里进行了网络通讯操作,而这个操作没有设置网络超时时间,那这个数据库连接就会被一直占用着。上述问题,在流量很大的情况下简直就是灾难,会直接导致应用系统挂掉。
正确的使用Transactional注解需要做到如下四点:
1、不要在类上标注Transactional注解,要在需要的方法上标注。即使类的每个方法都需要事务也不要在类上标注,因为有可能你或别人新添加的方法根本不需要事务;
2、标注了Transactional注解的方法体中不要涉及耗时很久的操作,如IO操作、网络通信等;
3、根据业务需要设置合适的事务参数,如是否需要新事务、超时时间等;
4、控制事务影响的范围,代码中减少事务影响的代码。
@Transactional注解中常用参数说明
| 参数名称 | 功能描述 |
|---|---|
| readOnly | 该属性用于设置当前事务是否为只读事务,设置为true表示只读,false则表示可读写,默认值为false。例如:@Transactional(readOnly=true) |
| rollbackFor | 该属性用于设置需要进行回滚的异常类数组,当方法中抛出指定异常数组中的异常时,则进行事务回滚。例如:指定单一异常类:@Transactional(rollbackFor=RuntimeException.class)指定多个异常类:@Transactional(rollbackFor={RuntimeException.class, Exception.class}) |
| rollbackForClassName | 该属性用于设置需要进行回滚的异常类名称数组,当方法中抛出指定异常名称数组中的异常时,则进行事务回滚。例如:指定单一异常类名称:@Transactional(rollbackForClassName=“RuntimeException”)指定多个异常类名称:@Transactional(rollbackForClassName={“RuntimeException”,“Exception”}) |
| noRollbackFor | 该属性用于设置不需要进行回滚的异常类数组,当方法中抛出指定异常数组中的异常时,不进行事务回滚。例如:指定单一异常类:@Transactional(noRollbackFor=RuntimeException.class)指定多个异常类:@Transactional(noRollbackFor={RuntimeException.class,Exception.class}) |
| noRollbackForClassName | 该属性用于设置不需要进行回滚的异常类名称数组,当方法中抛出指定异常名称数组中的异常时,不进行事务回滚。例如:指定单一异常类名称:@Transactional(noRollbackForClassName=“RuntimeException”)指定多个异常类名称:@Transactional(noRollbackForClassName={“RuntimeException”,“Exception”}) |
| propagation | 该属性用于设置事务的传播行为,具体取值可参考表6-7。例如:@Transactional(propagation=Propagation.NOT_SUPPORTED,readOnly=true) |
| isolation | 该属性用于设置底层数据库的事务隔离级别,事务隔离级别用于处理多事务并发的情况,通常使用数据库的默认隔离级别即可,基本不需要进行设置 |
| timeout | 该属性用于设置事务的超时秒数,默认值为-1表示永不超时 |
spring bean的生命周期及三级缓存

spring三级缓存解决循环依赖

三级缓存
1、singletonFactories : 单例对象工厂的cache
2、earlySingletonObjects :提前暴光的单例对象的Cache 。【用于检测循环引用,与singletonFactories互斥】
3、singletonObjects:单例对象的cache
这样做有什么好处呢?让我们来分析一下“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。
spring是如何实现事务的
链接
Spring AOP默认使用JDK动态代理, 但是前提为目标类必须实现接口, 使用反射, 如果没有实现接口, 则会使用CGLib代理, 前提为目标类不能被final修饰, 也可以强制使用CGLib代理
事务传播机制
1、PROPAGATION_REQUIRED 如果存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。
2、PROPAGATION_SUPPORTS 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行。但是 对于事务同步的事务管理器,PROPAGATION_SUPPORTS与不使用事务有少许不同。
3、PROPAGATION_MANDATORY 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
4、PROPAGATION_REQUIRES_NEW 总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
5、PROPAGATION_NOT_SUPPORTED 总是非事务地执行,并挂起任何存在的事务。
6、PROPAGATION_NEVER 总是非事务地执行,如果存在一个活动事务,则抛出异常
7、PROPAGATION_NESTED如果一个活动的事务存在,则运行在一个嵌套的事务中. 如果没有活动事务, 则按TransactionDefinition.PROPAGATION_REQUIRED 属性执行
1.Spring的Bean是单例的吗?
Spring下默认的bean均为singleton,可以通过singleton=“true|false” 或者 scope=“?”来指定
Spring涉及到的设计模式:
2 在装配Bean前怎么对Bean进行配置?
在XML中进行显示配置;在Java中进行显示配置;隐式的bean发现机制和自动
url
3 说一下spring容器的启动过程?
4 事务注解失效的情况
数据库引擎是否支持事务(Mysql 的 MyIsam引擎不支持事务);
注解所在的类是否被加载为 Bean(是否被spring 管理);
注解所在的方法是否为 public 修饰的;
是否存在自身调用的问题;
所用数据源是否加载了事务管理器;
@Transactional的扩展配置propagation是否正确。
url
Mysql
Apache ShardingSphere
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,仍在不断增加中。
ShardingSphere 已于2020年4月16日成为 Apache 软件基金会的顶级项目。
当前读(锁定读)加锁情况.
| 读提交 | 可重复读 | |
|---|---|---|
| 主键索引 | 锁定主键索引 | 锁定主键索引 |
| 唯一索引 | 锁定唯一索引的值和主键索引的值 | 锁定唯一索引的值和主键索引的值 |
| 普通索引 | 锁定普通索引的值和主键索引的值 | 锁定普通索引的值和主键索引的值,普通索引增加间隙锁 |
| 无索引 | 锁定所有的主键索引,在服务器层对不符合条件的记录解锁 | 锁定所有的主键索引和主键索引的间隙 |
唯一索引和普通索引的区别
- 查询
- 更新
第一种情况,要更新的记录所在的数据页在内存中,这种情况下普通索引和唯一索引对更新语句性能的差别,只是一个判断,只会耗费微笑的CPU时间。
对于唯一索引,找到3和5之间的位置,判断到没有冲突,插入这个值,语句执行结束;
对于普通索引,找到3和5之间的位置,插入这个值,语句执行结束。
第二中情况,要更新的记录所在的数据页不在内存中。
对于唯一索引,需要将数据页读入内存中,判断有没有冲突,插入这个值,语句执行结束;
对于普通索引来说,则是将更新记录在change buffer,语句执行就结束了;
将数据从磁盘读入内存,涉及随机IO的访问,是数据库里面成本最高的操作之一。change buffer因为减少了随机磁盘访问,所以对更新性能的提升是很明显的。
主键
链接
uuid的缺点
与自增相比,最大的缺陷就是随机io。这一点又要谈到我们的innodb了,因为这个默认引擎,表中数据是按照主键顺序存放的。也就是说,如果发生了随机io,那么就会频繁地移动磁盘块。当数据量大的时候,写的短板将非常明显。当然,这个缺点可以通过nosql那些产品解决。
读取出来的数据也是没有规律的,通常需要order by,其实也很消耗数据库资源
看起来比较丑
雪花算法简单描述:
- 最高位是符号位,始终为0,不可用。
- 41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
- 10位的机器标识,10位的长度最多支持部署1024个节点。
- 12位的计数序列号,序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号。
MVCC(可重复读)
简单理解一下可重复读
可重复读是指:一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。
我们可以简单理解为:在可重复读隔离级别下,事务在启动的时候就”拍了个快照“。注意,这个快照是基于整个库的。
这时,你可能就会想,如果一个库有 100G,那么我启动一个事务,MySQL就要拷贝 100G 的数据出来,这个过程得多慢啊。可是,我平时的事务执行起来很快啊。
实际上,我们并不需要拷贝出这 100G 的数据。我们来看下”快照“是怎么实现的。
拍个快照
InnoDB 里面每个事务都有一个唯一的事务 ID,叫作 transaction id。它在事务开始的时候向 InnoDB 的事务系统申请的,是按申请顺序严格递增的。
每条记录在更新的时候都会同时记录一条 undo log,这条 log 就会记录上当前事务的 transaction id,记为 row trx_id。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。
如下图所示,一行记录被多个事务更新之后,最新值为 k=22。假设事务A在 trx_id=15 这个事务提交后启动,事务A 要读取该行时,就通过 undo log,计算出该事务启动瞬间该行的值为 k=10。
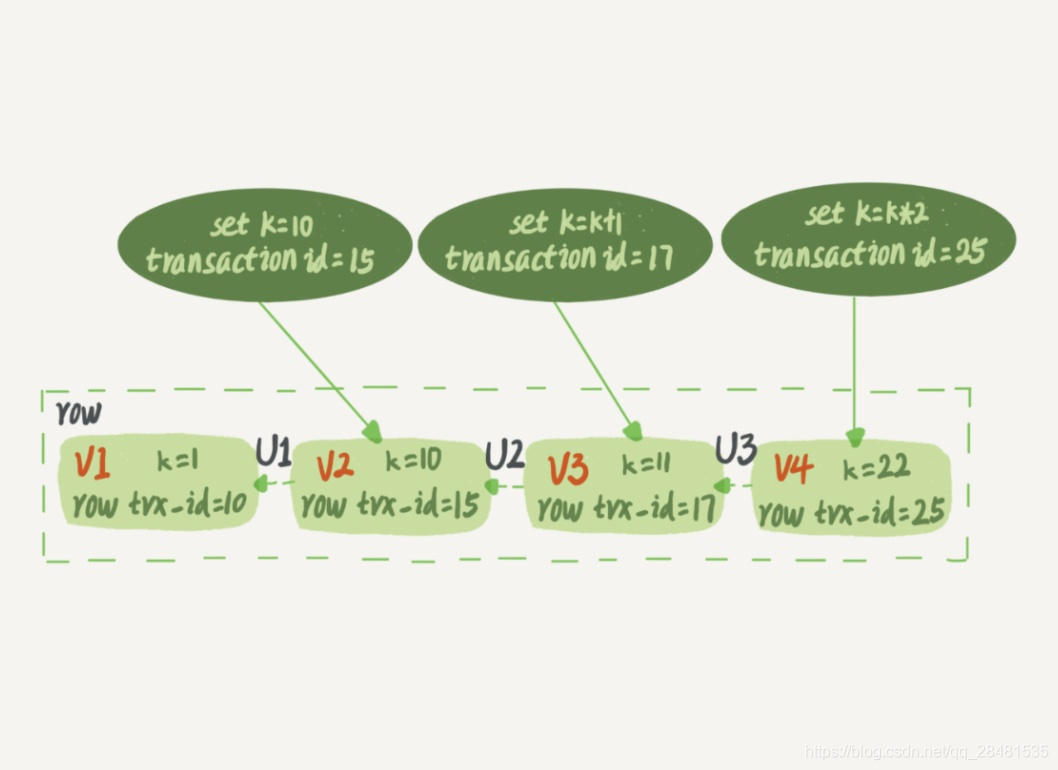
在可重复读隔离级别下,一个事务在启动时,InnoDB 会为事务构造一个数组,用来保存这个事务启动瞬间,当前正在”活跃“的所有事务ID。”活跃“指的是,启动了但还没提交。
数组里面事务 ID 为最小值记为低水位,当前系统里面已经创建过的事务 ID 的最大值加 1 记为高水位。
这个视图数组和高水位,就组成了当前事务的一致性视图(read-view)。
这个视图数组把所有的 row trx_id 分成了几种不同的情况。
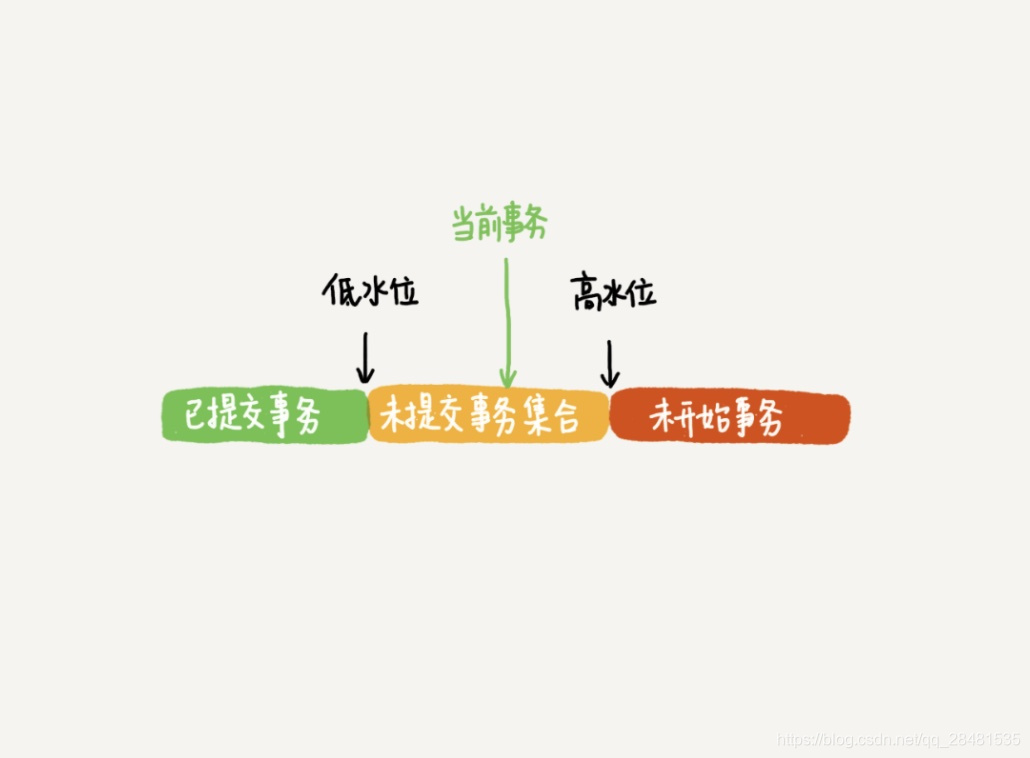
- 如果 trx_id 小于低水位,表示这个版本在事务启动前已经提交,可见;
- 如果 trx_id 大于高水为,表示这个版本在事务启动后生成,不可见;
- 如果 trx_id 大于低水位,小于高水位,分为两种情况:
- 若 trx_id 在数组中,表示这个版本在事务启动时还未提交,不可见;
- 若 trx_id 不在数组中,表示这个版本在事务启动时已经提交,可见。
InnoDB 就是利用 undo log 和 trx_id 的配合,实现了事务启动瞬间”秒级创建快照“的能力。
1.数据库MyIsam和Innodb的区别?
(1)事务处理: MyISAM是非事务安全型的,而InnoDB是事务安全型的(支持事务处理等高级处理);
(2)锁机制不同: MyISAM是表级锁,而InnoDB是行级锁;
(3)select ,update ,insert ,delete 操作:MyISAM:如果执行大量的SELECT,MyISAM是更好的选择
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用
(4)查询表的行数不同:MyISAM:select count() from table,MyISAM只要简单的读出保存好的行数,注意的是,当count()语句包含where条件时,两种表的操作是一样的
InnoDB :InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行
(5)外键支持:mysiam表不支持外键,而InnoDB支持
2 数据库优化
3. select * from Table where a=? and b=? order by c,d;如何建立索引
建立索引的原则:
- 在经常用作过滤器的字段上建立索引;
- 在SQL语句中经常进行GROUP BY、ORDER BY的字段上建立索引;
- 在不同值较少的字段上不必要建立索引,如性别字段;
- 对于经常存取的列避免建立索引;
- 用于联接的列(主健/外健)上建立索引;
- 在经常存取的多个列上建立复合索引,但要注意复合索引的建立顺序要按照使用的频度来确定;
- 缺省情况下建立的是非簇集索引,但在以下情况下最好考虑簇集索引,如:含有有限数目(不是很少)唯一的列;进行大范围的查询;充分的利用索引可以减少表扫描I/0的次数,有效的避免对整表的搜索。当然合理的索引要建立在对各种查询的分析和预测中,也取决于DBA的所设计的数据库结构。百万级别或以上的数据如何删除
sql优化
1.如果声明了主键(primary key),则这个列会被做为聚集索引
2.如果没有声明主键,则会用一个唯一且不为空的索引列做为主键,成为此表的聚集索引
3.上面二个条件都不满足,InnoDB会自己产生一个虚拟的聚集索引。
索引失效:
1、like 以%开头,索引无效;当like前缀没有%,后缀有%时,索引有效。
2、or语句前后没有同时使用索引。当or左右查询字段只有一个是索引,该索引失效,只有当or左右查询字段均为索引时,才会生效
3、组合索引,不是使用第一列索引,索引失效。
4、数据类型出现隐式转化。如varchar不加单引号的话可能会自动转换为int型,使索引无效,产生全表扫描。
5、在索引列上使用 IS NULL 或 IS NOT NULL操作。索引是不索引空值的,所以这样的操作不能使用索引,可以用其他的办法处理,例如:数字类型,判断大于0,字符串类型设置一个默认值,判断是否等于默认值即可。
6、在索引字段上使用not,<>,!=。不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描。 优化方法: key<>0 改为 key>0 or key<0。
7、对索引字段进行计算操作、字段上使用函数。(索引为 emp(ename,empno,sal))
8、当全表扫描速度比索引速度快时,mysql会使用全表扫描,此时索引失效。
4.分库分表
5 mybaits二级缓存
1、 mybatis的一级缓存是指SqlSession,一级缓存的作用域是一个sqlSession,mybatis默认开启一级缓存-----在同一个sqlSession中,执行相同的查询sql,第一次回去查询数据库,并写到缓存汇总;第二次直接从缓存中取,当执行sql时两次查询中间发生了增删改操作,则sqlsession的缓存清空
但是不同的SqlSession对象,因为不同的SqlSession都是相互隔离的,所以相同的Mapper、参数和方法,他还是会再次发送到SQL到数据库去执行,返回结果。
2、二级缓存–是指mapper映射文件,二级缓存的作用域是同一个namespace下的mapper映射文件内容,多个sqlsession共享,mybatis需要手动设置启动二级缓存
在同一个namespace下的mapper文件中,执行相同的查询SQL,第一次会去查询数据库,并写到缓存中;第二次直接从缓存中取。当执行SQL时两次查询中间发生了增删改操作,则二级缓存清空。
二级缓存是mapper级别的。Mybatis默认是没有开启二级缓存。
(1)第一次调用mapper下的SQL去查询用户信息。查询到的信息会存到该mapper对应的二级缓存区域内。
(2)第二次调用相同namespace下的mapper映射文件中相同的SQL去查询用户信息。会去对应的二级缓存内取结果。
(3)如果调用相同namespace下的mapper映射文件中的增删改SQL,并执行了commit操作。此时会清空该namespace下的二级缓存。
开启二级缓存
MyBatis 包含一个强在的、可配置、可定制的缓存机制。MyBatis 3 的缓存实现有了许多改进,既强劲也更容易配置。
默认的情况,缓存是没有开启,除了会话缓存以外,它可以提高性能,且能解决全局依赖。开启二级缓 存,你只需要在 SQL 映射文件中加入简单的一行:
这句简单的语句的作用如下:
� 所有在映射文件里的 select 语句都将被缓存。
� 所有在映射文件里 insert,update 和 delete 语句会清空缓存。
� 缓存使用“最近很少使用”算法来回收
� 缓存不会被设定的时间所清空。
� 每个缓存可以存储 1024 个列表或对象的引用(不管查询出来的结果是什么)。
� 缓存将作为“读/写”缓存,意味着获取的对象不是共享的且对调用者是安全的。不会有其它的调用者或线程潜在修改。
8 处理死锁的方式
1.预防死锁:通过设置一些限制条件,去破坏产生死锁的必要条件
2.避免死锁:在资源分配过程中,使用某种方法避免系统进入不安全的状态,从而避免发生死锁
3.检测死锁:允许死锁的发生,但是通过系统的检测之后,采取一些措施,将死锁清除掉
4.解除死锁:该方法与检测死锁配合使用
防死锁的办法就是破坏死锁的四个必要条件,只要破坏了条件,死锁自然就不会产生了,简单的描述一下破坏四个
条件的思想
(1)破坏请求和保持条件
1)所有进程在开始运行之前,必须一次性获得所有资源,如果无法获得完全,释放已经获得的资源,等待;
2)所有进程在开始运行之前,只获得初始运行所需要的资源,然后在运行过程中不断请求新的资源,同时释放自己
已经用完的资源。
相比第一种而言,第二种方式要更加节省资源,不会浪费(因为第一种可能出现一种资源只在进程结束用那么一小
下,但却从头到尾都被占用,使用效率极低),而且,减少了进程饥饿的情况。
(2)破坏不可抢占条件
说起来简单,只要当一个进程申请一个资源,然而却申请不到的时候,必须释放已经申请到的所有资源。但是做
起来很复杂,需要付出很大的代价,加入该进程已经持有了类似打印机(或者其他的有必要连续工作的)这样的设
备,申请其他资源的时候失败了,必须释放打印机资源,但是人家用打印机已经用过一段时间了,此时释放打印机资
源很可能造成之后再次是用打印机时两次运行的信息不连续(得不到正确的结果)。
(3)破坏循环等待条件
设立一个规则,让进程获取资源的时候按照一定的顺序依次申请,不能违背这个顺序的规则。必须按照顺序申请
和释放,想要申请后面的资源必须先把该资源之前的资源全部申请,想要申请前面的资源必须先把该资源之后的资源
(前提是已获得)全部释放。
(4)破坏互斥条件:
没法破坏,是资源本身的性质所引起的。
B+Tree
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
从上一节中的B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
B+Tree相对于B-Tree有几点不同:
非叶子节点只存储键值信息。
所有叶子节点之间都有一个链指针。
数据记录都存放在叶子节点中。
将上一节中的B-Tree优化,由于B+Tree的非叶子节点只存储键值信息,假设每个磁盘块能存储4个键值及指针信息,则变成B+Tree后其结构如下图所示:
通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
可能上面例子中只有22条数据记录,看不出B+Tree的优点,下面做一个推算:
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗3)。也就是说一个深度为3的B+Tree索引可以维护103 * 10^3 * 10^3 = 10亿 条记录。
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在24层。mysql的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要13次磁盘I/O操作。
数据库中的B+Tree索引可以分为聚集索引(clustered index)和辅助索引(secondary index)。上面的B+Tree示例图在数据库中的实现即为聚集索引,聚集索引的B+Tree中的叶子节点存放的是整张表的行记录数据。辅助索引与聚集索引的区别在于辅助索引的叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键,即主键。当通过辅助索引来查询数据时,InnoDB存储引擎会遍历辅助索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据。
JVM
JVM五大区
JVM五大区
JVM 由类加载器子系统、运行时数据区、执行引擎以及本地方法接口组成。
- 程序计数器是当前线程所执行的行号指示器。通过改变计数器的值来确定下一条指令,比如循环,分支,跳转,异常处理,线程恢复等都依赖计数器来完成。
- 虚拟机栈也就是我们所说的栈内存,是java方法执行的内存模型。每个方法在执行的时候都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、和方法返回地址等信息。
- 本地方法栈和虚拟机栈类似,只不过本地方法栈为虚拟机使用本地方法(native)服务
- java堆是所有线程共享的一块内存,在虚拟机启动是创建,几乎所有的对象实例都在这里创建,因此该区域经常发生垃圾回收。从内存回收的角度看,由于现在收集器基本都是采用分代收集算法,所以java堆中还可以细分为:新生代和老年代;新生代又分为Eden空间、From Survivor空间、To Survivor空间三部分。
- 方法区用于存放已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
如何分辨一个对象是否为垃圾(垃圾回收)是否可手动回收,不可以手动回收这个方法又有什么作用
如何分辨一个对象是否为垃圾(垃圾回收)是否可手动回收,不可以手动回收这个方法又有什么作用
JVM 参数详解
1. Xms、xmx相同值的好处
面对上面的问题,为了避免在生产环境由于heap内存扩大或缩小导致应用停顿,降低延迟,同时避免每次垃圾回收完成后JVM重新分配内存。所以,-Xmx和-Xms一般都是设置相等的。
2. 触发 full gc:
- System.gc()方法的调用
此方法的调用是建议JVM进行Full GC,虽然只是建议而非一定,但很多情况下它会触发 Full GC,从而增加Full GC的频率,也即增加了间歇性停顿的次数。强烈影响系建议能不使用此方法就别使用,让虚拟机自己去管理它的内存,可通过通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。
2. 老年代空间不足
老年代空间只有在新生代对象转入及创建大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误:
java.lang.OutOfMemoryError: Java heap space
为避免以上两种状况引起的Full GC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
3. 永生区空间不足
JVM规范中运行时数据区域中的方法区,在HotSpot虚拟机中又被习惯称为永生代或者永生区,Permanet Generation中存放的为一些class的信息、常量、静态变量等数据,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下也会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息:
java.lang.OutOfMemoryError: PermGen space
为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。
4. CMS GC时出现promotion failed和concurrent mode failure
对于采用CMS进行老年代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发Full GC。
具体原因和解决方案可以查看使用CMS垃圾收集器产生的问题和解决方案
5. HandlePromotionFailure
在发生Minor GC之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果这个条件成立,那么Minor GC可以确保是安全的。如果不成立,则虚拟机会查看HandlePromotionFailure设置值是否允许担保失败。如果允许,那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次Minor GC,尽管这次Minor GC是有风险的;如果小于,或者HandlePromotionFailure设置不允许冒险,那这时也要改为进行一次Full GC。
统计得到的Minor GC晋升到老年代的平均大小大于老年代的剩余空间,这是一个较为复杂的触发情况,例如程序第一次触发Minor GC后,有6MB的对象晋升到老年代,那么当下一次Minor GC发生时,首先检查老年代的剩余空间是否大于6MB,如果小于6MB,则执行Full GC。
当新生代采用PS GC时,方式稍有不同,PS GC是在Minor GC后也会检查,例如上面的例子中第一次Minor GC后,PS GC会检查此时旧生代的剩余空间是否大于6MB,如小于,则触发对旧生代的回收。
除了以上4种状况外,对于使用RMI来进行RPC或管理的Sun JDK应用而言,默认情况下会一小时执行一次Full GC。可通过在启动时通过 java -Dsun.rmi.dgc.client.gcInterval=3600000来设置Full GC执行的间隔时间或通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。
6. 堆中分配很大的对象
所谓大对象,是指需要大量连续内存空间的java对象,例如很长的数组,此种对象会直接进入老年代,而老年代虽然有很大的剩余空间,但是无法找到足够大的连续空间来分配给当前对象,此种情况就会触发JVM进行Full GC。
为了解决这个问题,CMS垃圾收集器提供了一个可配置的参数,即-XX:+UseCMSCompactAtFullCollection开关参数,用于在“享受”完Full GC服务之后额外免费赠送一个碎片整理的过程,内存整理的过程无法并发的,空间碎片问题没有了,但提顿时间不得不变长了,JVM设计者们还提供了另外一个参数 -XX:CMSFullGCsBeforeCompaction,这个参数用于设置在执行多少次不压缩的Full GC后,跟着来一次带压缩的
3. 讲一下oom以及遇到这种情况怎么处理的,是否使用过日志分析工具
- 什么是OOM?
OOM,全称“Out Of Memory”,翻译成中文就是“内存用完了”,来源于java.lang.OutOfMemoryError,当JVM因为没有足够的内存来为对象分配空间并且垃圾回收器也已经没有空间可回收时,就会抛出这个error - 为什么会OOM?
- 分配的少了:比如虚拟机本身可使用的内存(一般通过启动时的VM参数指定)太少。
- 应用用的太多,并且用完没释放,浪费了。此时就会造成内存泄露或者内存溢出。
内存泄露:申请使用完的内存没有释放,导致虚拟机不能再次使用该内存,此时这段内存就泄露了,因为申请者不用了,而又不能被虚拟机分配给别人用。
内存溢出:申请的内存超出了JVM能提供的内存大小,此时称之为溢出。
在Java语言中,由于存在了垃圾自动回收机制,所以,我们一般不用去主动释放不用的对象所占的内存,也就是理论上来说,是不会存在“内存泄露”的。但是,如果编码不当,比如,将某个对象的引用放到了全局的Map中,虽然方法结束了,但是由于垃圾回收器会根据对象的引用情况来回收内存,导致该对象不能被及时的回收。如果该种情况出现次数多了,就会导致内存溢出,比如系统中经常使用的缓存机制。Java中的内存泄露,不同于C++中的忘了delete,往往是逻辑上的原因泄露。
- OOM的类型
按照JVM规范,除了程序计数器不会抛出OOM外,其他各个内存区域都可能会抛出OOM。
最常见的OOM情况有以下三种:
java.lang.OutOfMemoryError: Java heap space ------>java堆内存溢出,此种情况最常见,一般由于内存泄露或者堆的大小设置不当引起。对于内存泄露,需要通过内存监控软件查找程序中的泄露代码,而堆大小可以通过虚拟机参数-Xms,-Xmx等修改。
java.lang.OutOfMemoryError: PermGen space ------>java永久代溢出,即方法区溢出了,一般出现于大量Class或者jsp页面,或者采用cglib等反射机制的情况,因为上述情况会产生大量的Class信息存储于方法区。此种情况可以通过更改方法区的大小来解决,使用类似-XX:PermSize=64m -XX:MaxPermSize=256m的形式修改。另外,过多的常量尤其是字符串也会导致方法区溢出。
java.lang.StackOverflowError ------> 不会抛OOM error,但也是比较常见的Java内存溢出。JAVA虚拟机栈溢出,一般是由于程序中存在死循环或者深度递归调用造成的,栈大小设置太小也会出现此种溢出。可以通过虚拟机参数-Xss来设置栈的大小。 - 如何解决oom:
- 使用缓存技术,比如LruCache、DiskLruCache、对象重复并且频繁调用可以考虑对象池
推荐大神博客:Android高效加载大图、多图解决方案,有效避免程序OOM
Android照片墙应用实现,再多的图片也不怕崩溃 - 对于引用生命周期不一样的对象,可以用软引用或弱引用SoftReferner WeakReference
- 对于资源对象 使用finally 强制关闭
- 内存压力过大就要统一的管理内存
- 对于java中不再使用的资源需要尽快的释放,即设置成null,不要老是指望垃圾回收器为你工作。如果不设置成null,那么资源回收会受到一定的影响。
- 尽量少用static方法和static成员。因为static的方法或成员被外部使用的话,而外部的牵引对象没有对其进行释放的话那么整个static的类都不会被释放,也就造成内存泄漏。
- 对于不再使用的bitmap应该手动调用recycle方法,并且设置成null。图片还要尽量使用软引用方式,这样可以加快垃圾回收。
- 使用缓存技术,比如LruCache、DiskLruCache、对象重复并且频繁调用可以考虑对象池
- 对象优先在Eden分配,且新生代对象晋升到老年代有多种情况,
现在做一个总结:- Eden区满时,进行Minor GC,当Eden和一个Survivor区中依然存活的对象无法放入到Survivor中,则通过分配担保机制提前转移到老年代中。
- 若对象体积太大, 新生代无法容纳这个对象,-XX:PretenureSizeThreshold即对象的大小大于此值, 就会绕过新生代, 直接在老年代分配, 此参数只对Serial及ParNew两款收集器有效。
- 长期存活的对象将进入老年代。
虚拟机对每个对象定义了一个对象年龄(Age)计数器。当年龄增加到一定的临界值时,就会晋升到老年代中,该临界值由参数:-XX:MaxTenuringThreshold来设置。
如果对象在Eden出生并在第一次发生MinorGC时仍然存活,并且能够被Survivor中所容纳的话,则该对象会被移动到Survivor中,并且设Age=1;以后每经历一次Minor GC,该对象还存活的话Age=Age+1。 - 动态对象年龄判定。
虚拟机并不总是要求对象的年龄必须达到MaxTenuringThreshold才能晋升到老年代,如果在Survivor区中相同年龄(设年龄为age)的对象的所有大小之和超过Survivor空间的一半,年龄大于或等于该年龄(age)的对象就可以直接进入老年代,无需等到MaxTenuringThreshold中要求的年龄。
4. 垃圾回收器
- CMS以获取最短回收停顿时间为目标的收集器,这是因为CMS收集器工作时,GC工作线程与用户线程可以并发执行,以此来达到降低收集停顿时间的目的。
- 基于并发“标记清理”实现过程:
1)初始标记:独占CPU,仅标记GCroots能直接关联的对象(Stop-the-world)
2)并发标记:可以和用户线程并行执行,标记所有可达对象
3)重新标记:独占CPU(STW),对并发标记阶段用户线程运行产生的垃圾对象进行标记修正(Stop-the-world)
4)并发清理:可以和用户线程并行执行,清理垃圾 - 优点:
并发,低停顿 - 缺点:
- 对CPU非常敏感:在并发阶段虽然不会导致用户线程停顿,但是会因为占用了一部分线程使应用程序变慢
- 无法处理浮动垃圾:在最后一步并发清理过程中,用户线程执行也会产生垃圾,但是这部分垃圾是在标记之后,所以只有等到下一次gc的时候清理掉,这部分垃圾叫浮动垃圾
- CMS使用“标记-清理”法会产生大量的空间碎片,当碎片过多,将会给大对象空间的分配带来很大的麻烦,往往会出现老年代还有很大的空间但无法找到足够大的连续空间来分配当前对象,不得不提前触发一次FullGC,为了解决这个问题CMS提供了一个开关参数,用于在CMS顶不住,要进行FullGC时开启内存碎片的合并整理过程,但是内存整理的过程是无法并发的,空间碎片没有了但是停顿时间变长了
- CMS 出现FullGC的原因:
- 年轻带晋升到老年带没有足够的连续空间,很有可能是内存碎片导致的
- 在并发过程中JVM觉得在并发过程结束之前堆就会满,需要提前触发FullGC
- 基于并发“标记清理”实现过程:
- 垃圾回收器介绍:
G1:是一款面向服务端应用的垃圾收集器
特点:- 并行于并发:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
- 分代收集:分代概念在G1中依然得以保留。虽然G1可以不需要其它收集器配合就能独立管理整个GC堆,但它能够采用不同的方式去处理新创建的对象和已经存活了一段时间、熬过多次GC的旧对象以获取更好的收集效果。也就是说G1可以自己管理新生代和老年代了。
- 空间整合:由于G1使用了独立区域(Region)概念,G1从整体来看是基于“标记-整理”算法实现收集,从局部(两个Region)上来看是基于“复制”算法实现的,但无论如何,这两种算法都意味着G1运作期间不会产生内存空间碎片。
- 可预测的停顿:这是G1相对于CMS的另一大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用这明确指定一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒。
- 与其它收集器相比,G1变化较大的是它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留了新生代和来年代的概念,但新生代和老年代不再是物理隔离的了它们都是一部分Region(不需要连续)的集合。同时,为了避免全堆扫描,G1使用了Remembered Set来管理相关的对象引用信息。当进行内存回收时,在GC根节点的枚举范围中加入Remembered Set即可保证不对全堆扫描也不会有遗漏了。
- 如果不计算维护Remembered Set的操作,G1收集器的运作大致可划分为以下几个步骤:
- 初始标记(Initial Making)
- 并发标记(Concurrent Marking)
- 最终标记(Final Marking)
- 筛选回收(Live Data Counting and Evacuation)
- 看上去跟CMS收集器的运作过程有几分相似,不过确实也这样。初始阶段仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAMS(Next Top Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可以用的Region中创建新对象,这个阶段需要停顿线程,但耗时很短。并发标记阶段是从GC Roots开始对堆中对象进行可达性分析,找出存活对象,这一阶段耗时较长但能与用户线程并发运行。而最终标记阶段需要吧Remembered Set Logs的数据合并到Remembered Set中,这阶段需要停顿线程,但可并行执行。最后筛选回收阶段首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划,这一过程同样是需要停顿线程的,但Sun公司透露这个阶段其实也可以做到并发,但考虑到停顿线程将大幅度提高收集效率,所以选择停顿。下图为G1收集器运行示意图:
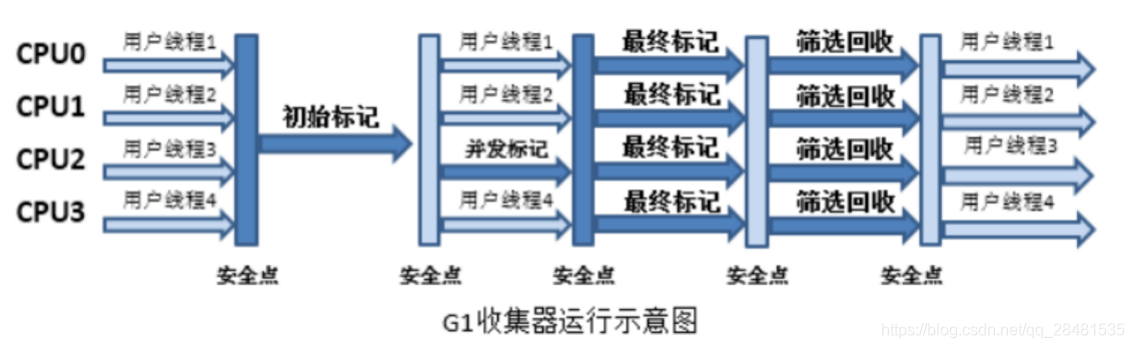
-
G1 GC和CMS GC相比的优缺点?
G1 GC 这是一种兼顾吞吐量和停顿时间的 GC 实现,是 Oracle JDK 9 以后的默认 GC 选
项。G1 可以直观的设定停顿时间的目标,相比于 CMS GC,G1 未必能做到 CMS 在最好情况下的延时停顿,但是最差情况要好很多。 -
G1 GC 仍然存在着年代的概念,但是其内存结构并不是简单的条带式划分,而是类似棋盘的一个个 region。Region 之间是复制算法,但整体上实际可看作是标记 - 整理(Mark-Compact)算法,可以有效地避免内存碎片,尤其是当 Java 堆非常大的时候,G1 的优势更加明显。
-
Parrallel GC,(jdk8默认GC)在早期 JDK 8 等版本中,它是 server 模式 JVM 的默认 GC 选择,也被称作是吞吐量优先的 GC。
-
它的算法和 Serial GC(最早的GC,单线程) 比较相似(从年代的角度,通常将其老年代实现单独称作 Serial Old,它采用了标记 - 整理(Mark,Compact)算法,区别于新生代的复制算法),尽管实现要复杂的多,其特点是新生代和老年代 GC 都是并行进行的,在常见的服务器环境中更加高效。
-
垃圾收集器:
- Serial收集器
最基本、发展历史最久的收集器,这个收集器是一个采用复制算法的单线程的收集器,单线程一方面意味着它只会使用一个CPU或一条线程去完成垃圾收集工作,另一方面也意味着它进行垃圾收集时必须暂停其他线程的所有工作,直到它收集结束为止。后者意味着,在用户不可见的情况下要把用户正常工作的线程全部停掉,这对很多应用是难以接受的。不过实际上到目前为止,Serial收集器依然是虚拟机运行在Client模式下的默认新生代收集器,因为它简单而高效。用户桌面应用场景中,分配给虚拟机管理的内存一般来说不会很大,收集几十兆甚至一两百兆的新生代停顿时间在几十毫秒最多一百毫秒,只要不是频繁发生,这点停顿是完全可以接受的。 - ParNew收集器
ParNew收集器其实就是Serial收集器的多线程版本,除了使用多条线程进行垃圾收集外,其余行为和Serial收集器完全一样,包括使用的也是复制算法。ParNew收集器除了多线程以外和Serial收集器并没有太多创新的地方,但是它却是Server模式下的虚拟机首选的新生代收集器,其中有一个很重要的和性能无关的原因是,除了Serial收集器外,目前只有它能与CMS收集器配合工作(看图)。CMS收集器是一款几乎可以认为有划时代意义的垃圾收集器,因为它第一次实现了让垃圾收集线程与用户线程基本上同时工作。ParNew收集器在单CPU的环境中绝对不会有比Serial收集器更好的效果,甚至由于线程交互的开销,该收集器在两个CPU的环境中都不能百分之百保证可以超越Serial收集器。当然,随着可用CPU数量的增加,它对于GC时系统资源的有效利用还是很有好处的。它默认开启的收集线程数与CPU数量相同,在CPU数量非常多的情况下,可以使用-XX:ParallelGCThreads参数来限制垃圾收集的线程数。 - Parallel收集器
Parallel收集器也是一个新生代收集器,也是用复制算法的收集器,也是并行的多线程收集器,但是它的特点是它的关注点和其他收集器不同。介绍这个收集器主要还是介绍吞吐量的概念。CMS等收集器的关注点是尽可能缩短垃圾收集时用户线程的停顿时间,而Parallel收集器的目标则是打到一个可控制的吞吐量。所谓吞吐量s的意思就是CPU用于运行用户代码时间与CPU总消耗时间的比值,即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间),虚拟机总运行100分钟,垃圾收集1分钟,那吞吐量就是99%。另外,Parallel收集器是虚拟机运行在Server模式下的默认垃圾收集器。
停顿时间短适合需要与用户交互的程序,良好的响应速度能提升用户体验;高吞吐量则可以高效率利用CPU时间,尽快完成运算任务,主要适合在后台运算而不需要太多交互的任务。
虚拟机提供了-XX:MaxGCPauseMillis和-XX:GCTimeRatio两个参数来精确控制最大垃圾收集停顿时间和吞吐量大小。不过不要以为前者越小越好,GC停顿时间的缩短是以牺牲吞吐量和新生代空间换取的。由于与吞吐量关系密切,Parallel收集器也被称为“吞吐量优先收集器”。Parallel收集器有一个-XX:+UseAdaptiveSizePolicy参数,这是一个开关参数,这个参数打开之后,就不需要手动指定新生代大小、Eden区和Survivor参数等细节参数了,虚拟机会根据当亲系统的运行情况手机性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量。如果对于垃圾收集器运作原理不太了解,以至于在优化比较困难的时候,使用Parallel收集器配合自适应调节策略,把内存管理的调优任务交给虚拟机去完成将是一个不错的选择。 - Serial Old收集器
Serial收集器的老年代版本,同样是一个单线程收集器,使用“标记-整理算法”,这个收集器的主要意义也是在于给Client模式下的虚拟机使用。 - Parallel Old收集器
Parallel收集器的老年代版本,使用多线程和“标记-整理”算法。这个收集器在JDK 1.6之后的出现,“吞吐量优先收集器”终于有了比较名副其实的应用组合,在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel收集器+Parallel Old收集器的组合。
- Serial收集器
-
年轻代设为 8:1:1 的原理是啥?
因为年轻代中的对象基本都是朝生夕死的(80%以上) -
如何分辨一个对象是否为垃圾(垃圾回收)是否可手动回收,不可以手动回收这个方法又有什么作用
- 目前主流的编程语言(java,C#等)的主流实现中,都是称通过可达性分析(Reachability Analysis)来判定对象是否存活的。这个算法的基本思路就是通过一系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连(用图论的话来说,就是从GC Roots到这个对象不可达)时,则证明此对象是不可用的。
- 在Java语言中,可作为GC Roots的对象包括下面几种:
虚拟机栈(栈帧中的本地变量表)中引用的对象。 方法区中类静态属性引用的对象。 方法区中常量引用的对象。
本地方法栈中JNI(即一般说的Native方法)引用的对象。
5. 被标记的垃圾一定会回收吗?
* 即使在可达性分析算法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑”阶段,要真正宣告一个对象死亡,至少要经历两次标记过程:如果对象在进行可达性分析后发现没有与GC Roots相连接的引用链,那它将会被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行finalize()方法。当对象没有覆盖finalize()方法,或者finalize()方法已经被虚拟机调用过,虚拟机将这两种情况都视为“没有必要执行”。(即意味着直接回收)
* 如果这个对象被判定为有必要执行finalize()方法,那么这个对象将会放置在一个叫做F-Queue的队列之中,并在稍后由一个由虚拟机自动建立的、低优先级的Finalizer线程去执行它。这里所谓的“执行”是指虚拟机会触发这个方法,但并不承诺会等待它运行结束,这样做的原因是,如果一个对象在finalize()方法中执行缓慢,或者发生了死循环(更极端的情况),将很可能会导致F-Queue队列中其他对象永久处于等待,甚至导致整个内存回收系统崩溃。
* finalize()方法是对象逃脱死亡命运的最后一次机会,稍后GC将对F-Queue中的对象进行第二次小规模的标记,如果对象要在finalize()中成功拯救自己——只要重新与引用链上的任何一个对象建立关联即可,譬如把自己(this关键字)赋值给某个类变量或者对象的成员变量,那在第二次标记时它将被移除出“即将回收”的集合;如果对象这时候还没有逃脱,那基本上它就真的被回收了。
6. JVM还有哪些方式可以实现内存屏障
* 内存屏障,又称内存栅栏,是一组处理器指令,用于实现对内存操作的顺序限制。
* LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
* StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
* LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
* StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。 在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
7. 什么时候发生full Gc情况
- System.gc()方法的调用
此方法的调用是建议JVM进行Full GC,虽然只是建议而非一定,但很多情况下它会触发 Full GC,从而增加Full GC的频率,也即增加了间歇性停顿的次数。强烈影响系建议能不使用此方法就别使用,让虚拟机自己去管理它的内存,可通过通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。 - 老年代空间不足
老年代空间只有在新生代对象转入及创建大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误:
java.lang.OutOfMemoryError: Java heap space
为避免以上两种状况引起的Full GC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。 - 永生区空间不足
JVM规范中运行时数据区域中的方法区,在HotSpot虚拟机中又被习惯称为永生代或者永生区,Permanet Generation中存放的为一些class的信息、常量、静态变量等数据,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下也会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息:
java.lang.OutOfMemoryError: PermGen space
为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。 - CMS GC时出现promotion failed和concurrent mode failure
对于采用CMS进行老年代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发Full GC。 - HandlePromotionFailure
在发生Minor GC之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果这个条件成立,那么Minor GC可以确保是安全的。如果不成立,则虚拟机会查看HandlePromotionFailure设置值是否允许担保失败。如果允许,那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次Minor GC,尽管这次Minor GC是有风险的;如果小于,或者HandlePromotionFailure设置不允许冒险,那这时也要改为进行一次Full GC。 - 堆中分配很大的对象
所谓大对象,是指需要大量连续内存空间的java对象,例如很长的数组,此种对象会直接进入老年代,而老年代虽然有很大的剩余空间,但是无法找到足够大的连续空间来分配给当前对象,此种情况就会触发JVM进行Full GC。
为了解决这个问题,CMS垃圾收集器提供了一个可配置的参数,即-XX:+UseCMSCompactAtFullCollection开关参数,用于在“享受”完Full GC服务之后额外免费赠送一个碎片整理的过程,内存整理的过程无法并发的,空间碎片问题没有了,但提顿时间不得不变长了,JVM设计者们还提供了另外一个参数 -XX:CMSFullGCsBeforeCompaction,这个参数用于设置在执行多少次不压缩的Full GC后,跟着来一次带压缩的
Netty
Java NIO 简介
JAVA NIO有两种解释:一种叫非阻塞IO(Non-blocking I/O),另一种也叫新的IO(New I/O),其实是同一个概念。它是一种同步非阻塞的I/O模型,也是I/O多路复用的基础,已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O处理问题的有效方式。
NIO是一种基于通道和缓冲区的I/O方式,它可以使用Native函数库直接分配堆外内存(区别于JVM的运行时数据区),然后通过一个存储在java堆里面的DirectByteBuffer对象作为这块内存的直接引用进行操作。这样能在一些场景显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
Java NIO组件
NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector(选择器)。传统IO是基于字节流和字符流进行操作(基于流),而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。
Buffer
Buffer(缓冲区)是一个用于存储特定基本类型数据的容器。除了boolean外,其余每种基本类型都有一个对应的buffer类。Buffer类的子类有ByteBuffer, CharBuffer, DoubleBuffer, FloatBuffer, IntBuffer, LongBuffer, ShortBuffer 。
Channel
Channel(通道)表示到实体,如硬件设备、文件、网络套接字或可以执行一个或多个不同 I/O 操作(如读取或写入)的程序组件的开放的连接。Channel接口的常用实现类有FileChannel(对应文件IO)、DatagramChannel(对应UDP)、SocketChannel和ServerSocketChannel(对应TCP的客户端和服务器端)。Channel和IO中的Stream(流)是差不多一个等级的。只不过Stream是单向的,譬如:InputStream, OutputStream.而Channel是双向的,既可以用来进行读操作,又可以用来进行写操作。
Selector
Selector(选择器)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个的线程可以监听多个数据通道。即用选择器,借助单一线程,就可对数量庞大的活动I/O通道实施监控和维护。
注:
写就绪相对有一点特殊,一般来说,你不应该注册写事件。写操作的就绪条件为底层缓冲区有空闲空间,而写缓冲区绝大部分时间都是有空闲空间的,所以当你注册写事件后,写操作一直是就绪的,选择处理线程全占用整个CPU资源。所以,只有当你确实有数据要写时再注册写操作,并在写完以后马上取消注册。
基于阻塞式I/O的多线程模型中,Server为每个Client连接创建一个处理线程,每个处理线程阻塞式等待可能达到的数据,一旦数据到达,则立即处理请求、返回处理结果并再次进入等待状态。由于每个Client连接有一个单独的处理线程为其服务,因此可保证良好的响应时间。但当系统负载增大(并发请求增多)时,Server端需要的线程数会增加,对于操作系统来说,线程之间上下文切换的开销很大,而且每个线程都要占用系统的一些资源(如内存)。因此,使用的线程越少越好。
但是,现代的操作系统和CPU在多任务方面表现的越来越好,所以多线程的开销随着时间的推移,变得越来越小了。实际上,如果一个CPU有多个内核,不使用多任务可能是在浪费CPU能力。
传统的IO处理方式,一个线程处理一个网络连接
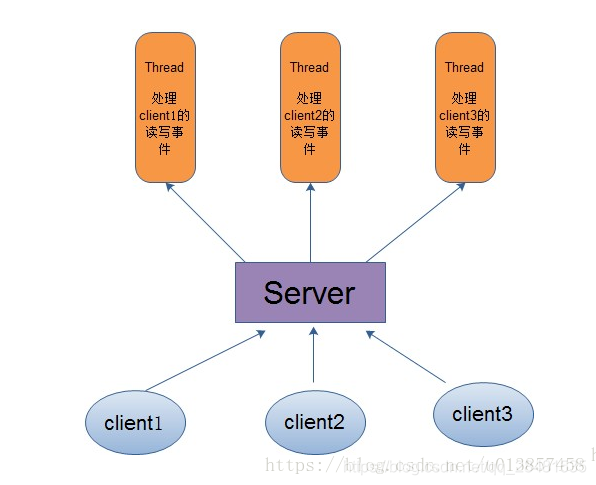
NIO处理方式,一个线程可以管理过个网络连接
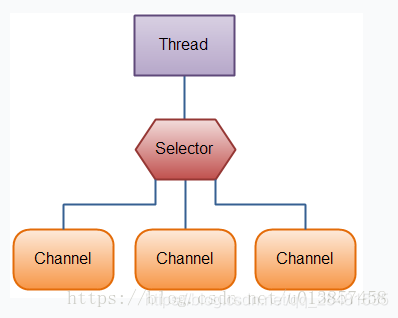
NIO服务器端如何实现非阻塞?
服务器上所有Channel需要向Selector注册,而Selector则负责监视这些Socket的IO状态(观察者),当其中任意一个或者多个Channel具有可用的IO操作时,该Selector的select()方法将会返回大于0的整数,该整数值就表示该Selector上有多少个Channel具有可用的IO操作,并提供了selectedKeys()方法来返回这些Channel对应的SelectionKey集合(一个SelectionKey对应一个就绪的通道)。正是通过Selector,使得服务器端只需要不断地调用Selector实例的select()方法即可知道当前所有Channel是否有需要处理的IO操作。注:java NIO就是多路复用IO,jdk7之后底层是epoll模型。
1.Netty 是什么?
Netty是 一个异步事件驱动的网络应用程序框架,用于快速开发可维护的高性能协议服务器和客户端。Netty是基于nio的,它封装了jdk的nio,让我们使用起来更加方法灵活。
2.Netty 的特点是什么?
高并发:Netty 是一款基于 NIO(Nonblocking IO,非阻塞IO)开发的网络通信框架,对比于 BIO(Blocking I/O,阻塞IO),他的并发性能得到了很大提高。
传输快:Netty 的传输依赖于零拷贝特性,尽量减少不必要的内存拷贝,实现了更高效率的传输。
封装好:Netty 封装了 NIO 操作的很多细节,提供了易于使用调用接口。
3.Netty 的优势有哪些?
使用简单:封装了 NIO 的很多细节,使用更简单。
功能强大:预置了多种编解码功能,支持多种主流协议。
定制能力强:可以通过 ChannelHandler 对通信框架进行灵活地扩展。
性能高:通过与其他业界主流的 NIO 框架对比,Netty 的综合性能最优。
稳定:Netty 修复了已经发现的所有 NIO 的 bug,让开发人员可以专注于业务本身。
社区活跃:Netty 是活跃的开源项目,版本迭代周期短,bug 修复速度快。
4.Netty 的应用场景有哪些?
典型的应用有:阿里分布式服务框架 Dubbo,默认使用 Netty 作为基础通信组件,还有 RocketMQ 也是使用 Netty 作为通讯的基础。
5.Netty 高性能表现在哪些方面?
IO 线程模型:同步非阻塞,用最少的资源做更多的事。
内存零拷贝:尽量减少不必要的内存拷贝,实现了更高效率的传输。
内存池设计:申请的内存可以重用,主要指直接内存。内部实现是用一颗二叉查找树管理内存分配情况。
串形化处理读写:避免使用锁带来的性能开销。
高性能序列化协议:支持 protobuf 等高性能序列化协议。
6.BIO、NIO和AIO的区别?
BIO:一个连接一个线程,客户端有连接请求时服务器端就需要启动一个线程进行处理。线程开销大。
伪异步IO:将请求连接放入线程池,一对多,但线程还是很宝贵的资源。
NIO:一个请求一个线程,但客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
AIO:一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,
BIO是面向流的,NIO是面向缓冲区的;BIO的各种流是阻塞的。而NIO是非阻塞的;BIO的Stream是单向的,而NIO的channel是双向的。
NIO的特点:事件驱动模型、单线程处理多任务、非阻塞I/O,I/O读写不再阻塞,而是返回0、基于block的传输比基于流的传输更高效、更高级的IO函数zero-copy、IO多路复用大大提高了Java网络应用的可伸缩性和实用性。基于Reactor线程模型。
在Reactor模式中,事件分发器等待某个事件或者可应用或个操作的状态发生,事件分发器就把这个事件传给事先注册的事件处理函数或者回调函数,由后者来做实际的读写操作。如在Reactor中实现读:注册读就绪事件和相应的事件处理器、事件分发器等待事件、事件到来,激活分发器,分发器调用事件对应的处理器、事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
7.NIO的组成?
Buffer:与Channel进行交互,数据是从Channel读入缓冲区,从缓冲区写入Channel中的
flip方法 : 反转此缓冲区,将position给limit,然后将position置为0,其实就是切换读写模式
clear方法 :清除此缓冲区,将position置为0,把capacity的值给limit。
rewind方法 : 重绕此缓冲区,将position置为0
DirectByteBuffer可减少一次系统空间到用户空间的拷贝。但Buffer创建和销毁的成本更高,不可控,通常会用内存池来提高性能。直接缓冲区主要分配给那些易受基础系统的本机I/O 操作影响的大型、持久的缓冲区。如果数据量比较小的中小应用情况下,可以考虑使用heapBuffer,由JVM进行管理。
Channel:表示 IO 源与目标打开的连接,是双向的,但不能直接访问数据,只能与Buffer 进行交互。通过源码可知,FileChannel的read方法和write方法都导致数据复制了两次!
Selector可使一个单独的线程管理多个Channel,open方法可创建Selector,register方法向多路复用器器注册通道,可以监听的事件类型:读、写、连接、accept。注册事件后会产生一个SelectionKey:它表示SelectableChannel 和Selector 之间的注册关系,wakeup方法:使尚未返回的第一个选择操作立即返回,唤醒的
原因是:注册了新的channel或者事件;channel关闭,取消注册;优先级更高的事件触发(如定时器事件),希望及时处理。
Selector在Linux的实现类是EPollSelectorImpl,委托给EPollArrayWrapper实现,其中三个native方法是对epoll的封装,而EPollSelectorImpl. implRegister方法,通过调用epoll_ctl向epoll实例中注册事件,还将注册的文件描述符(fd)与SelectionKey的对应关系添加到fdToKey中,这个map维护了文件描述符与SelectionKey的映射。
fdToKey有时会变得非常大,因为注册到Selector上的Channel非常多(百万连接);过期或失效的Channel没有及时关闭。fdToKey总是串行读取的,而读取是在select方法中进行的,该方法是非线程安全的。
Pipe:两个线程之间的单向数据连接,数据会被写到sink通道,从source通道读取
NIO的服务端建立过程:Selector.open():打开一个Selector;ServerSocketChannel.open():创建服务端的Channel;bind():绑定到某个端口上。并配置非阻塞模式;register():注册Channel和关注的事件到Selector上;select()轮询拿到已经就绪的事件
8.Netty的线程模型?
Netty通过Reactor模型基于多路复用器接收并处理用户请求,内部实现了两个线程池,boss线程池和work线程池,其中boss线程池的线程负责处理请求的accept事件,当接收到accept事件的请求时,把对应的socket封装到一个NioSocketChannel中,并交给work线程池,其中work线程池负责请求的read和write事件,由对应的Handler处理。
单线程模型:所有I/O操作都由一个线程完成,即多路复用、事件分发和处理都是在一个Reactor线程上完成的。既要接收客户端的连接请求,向服务端发起连接,又要发送/读取请求或应答/响应消息。一个NIO 线程同时处理成百上千的链路,性能上无法支撑,速度慢,若线程进入死循环,整个程序不可用,对于高负载、大并发的应用场景不合适。
多线程模型:有一个NIO 线程(Acceptor) 只负责监听服务端,接收客户端的TCP 连接请求;NIO 线程池负责网络IO 的操作,即消息的读取、解码、编码和发送;1 个NIO 线程可以同时处理N 条链路,但是1 个链路只对应1 个NIO 线程,这是为了防止发生并发操作问题。但在并发百万客户端连接或需要安全认证时,一个Acceptor 线程可能会存在性能不足问题。
主从多线程模型:Acceptor 线程用于绑定监听端口,接收客户端连接,将SocketChannel 从主线程池的Reactor 线程的多路复用器上移除,重新注册到Sub 线程池的线程上,用于处理I/O 的读写等操作,从而保证mainReactor只负责接入认证、握手等操作;
9.TCP 粘包/拆包的原因及解决方法?
TCP是以流的方式来处理数据,一个完整的包可能会被TCP拆分成多个包进行发送,也可能把小的封装成一个大的数据包发送。
TCP粘包/分包的原因:
应用程序写入的字节大小大于套接字发送缓冲区的大小,会发生拆包现象,而应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包现象;
进行MSS大小的TCP分段,当TCP报文长度-TCP头部长度>MSS的时候将发生拆包
以太网帧的payload(净荷)大于MTU(1500字节)进行ip分片。
解决方法
消息定长:FixedLengthFrameDecoder类
包尾增加特殊字符分割:
行分隔符类:LineBasedFrameDecoder
或自定义分隔符类 :DelimiterBasedFrameDecoder
将消息分为消息头和消息体:LengthFieldBasedFrameDecoder类。分为有头部的拆包与粘包、长度字段在前且有头部的拆包与粘包、多扩展头部的拆包与粘包。
10.什么是 Netty 的零拷贝?
Netty 的零拷贝主要包含三个方面:
Netty 的接收和发送 ByteBuffer 采用 DIRECT BUFFERS,使用堆外直接内存进行 Socket 读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行 Socket 读写,JVM 会将堆内存 Buffer 拷贝一份到直接内存中,然后才写入 Socket 中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
Netty 提供了组合 Buffer 对象,可以聚合多个 ByteBuffer 对象,用户可以像操作一个 Buffer 那样方便的对组合 Buffer 进行操作,避免了传统通过内存拷贝的方式将几个小 Buffer 合并成一个大的 Buffer。
Netty 的文件传输采用了 transferTo 方法,它可以直接将文件缓冲区的数据发送到目标 Channel,避免了传统通过循环 write 方式导致的内存拷贝问题。
11.Netty 中有哪种重要组件?
Channel:Netty 网络操作抽象类,它除了包括基本的 I/O 操作,如 bind、connect、read、write 等。
EventLoop:主要是配合 Channel 处理 I/O 操作,用来处理连接的生命周期中所发生的事情。
ChannelFuture:Netty 框架中所有的 I/O 操作都为异步的,因此我们需要 ChannelFuture 的 addListener()注册一个 ChannelFutureListener 监听事件,当操作执行成功或者失败时,监听就会自动触发返回结果。
ChannelHandler:充当了所有处理入站和出站数据的逻辑容器。ChannelHandler 主要用来处理各种事件,这里的事件很广泛,比如可以是连接、数据接收、异常、数据转换等。
ChannelPipeline:为 ChannelHandler 链提供了容器,当 channel 创建时,就会被自动分配到它专属的 ChannelPipeline,这个关联是永久性的。
12.Netty 发送消息有几种方式?
Netty 有两种发送消息的方式:
直接写入 Channel 中,消息从 ChannelPipeline 当中尾部开始移动;
写入和 ChannelHandler 绑定的 ChannelHandlerContext 中,消息从 ChannelPipeline 中的下一个 ChannelHandler 中移动。
13.默认情况 Netty 起多少线程?何时启动?
Netty 默认是 CPU 处理器数的两倍,bind 完之后启动。
14.了解哪几种序列化协议?
序列化(编码)是将对象序列化为二进制形式(字节数组),主要用于网络传输、数据持久化等;而反序列化(解码)则是将从网络、磁盘等读取的字节数组还原成原始对象,主要用于网络传输对象的解码,以便完成远程调用。
影响序列化性能的关键因素:序列化后的码流大小(网络带宽的占用)、序列化的性能(CPU资源占用);是否支持跨语言(异构系统的对接和开发语言切换)。
Java默认提供的序列化:无法跨语言、序列化后的码流太大、序列化的性能差
XML,优点:人机可读性好,可指定元素或特性的名称。缺点:序列化数据只包含数据本身以及类的结构,不包括类型标识和程序集信息;只能序列化公共属性和字段;不能序列化方法;文件庞大,文件格式复杂,传输占带宽。适用场景:当做配置文件存储数据,实时数据转换。
JSON,是一种轻量级的数据交换格式,优点:兼容性高、数据格式比较简单,易于读写、序列化后数据较小,可扩展性好,兼容性好、与XML相比,其协议比较简单,解析速度比较快。缺点:数据的描述性比XML差、不适合性能要求为ms级别的情况、额外空间开销比较大。适用场景(可替代XML):跨防火墙访问、可调式性要求高、基于Web browser的Ajax请求、传输数据量相对小,实时性要求相对低(例如秒级别)的服务。
Fastjson,采用一种“假定有序快速匹配”的算法。优点:接口简单易用、目前java语言中最快的json库。缺点:过于注重快,而偏离了“标准”及功能性、代码质量不高,文档不全。适用场景:协议交互、Web输出、Android客户端
Thrift,不仅是序列化协议,还是一个RPC框架。优点:序列化后的体积小, 速度快、支持多种语言和丰富的数据类型、对于数据字段的增删具有较强的兼容性、支持二进制压缩编码。缺点:使用者较少、跨防火墙访问时,不安全、不具有可读性,调试代码时相对困难、不能与其他传输层协议共同使用(例如HTTP)、无法支持向持久层直接读写数据,即不适合做数据持久化序列化协议。适用场景:分布式系统的RPC解决方案
Avro,Hadoop的一个子项目,解决了JSON的冗长和没有IDL的问题。优点:支持丰富的数据类型、简单的动态语言结合功能、具有自我描述属性、提高了数据解析速度、快速可压缩的二进制数据形式、可以实现远程过程调用RPC、支持跨编程语言实现。缺点:对于习惯于静态类型语言的用户不直观。适用场景:在Hadoop中做Hive、Pig和MapReduce的持久化数据格式。
Protobuf,将数据结构以.proto文件进行描述,通过代码生成工具可以生成对应数据结构的POJO对象和Protobuf相关的方法和属性。优点:序列化后码流小,性能高、结构化数据存储格式(XML JSON等)、通过标识字段的顺序,可以实现协议的前向兼容、结构化的文档更容易管理和维护。缺点:需要依赖于工具生成代码、支持的语言相对较少,官方只支持Java 、C++ 、python。适用场景:对性能要求高的RPC调用、具有良好的跨防火墙的访问属性、适合应用层对象的持久化
其它
protostuff 基于protobuf协议,但不需要配置proto文件,直接导包即可
Jboss marshaling 可以直接序列化java类, 无须实java.io.Serializable接口
Message pack 一个高效的二进制序列化格式
Hessian 采用二进制协议的轻量级remoting onhttp工具
kryo 基于protobuf协议,只支持java语言,需要注册(Registration),然后序列化(Output),反序列化(Input)
15.如何选择序列化协议?
具体场景
对于公司间的系统调用,如果性能要求在100ms以上的服务,基于XML的SOAP协议是一个值得考虑的方案。
基于Web browser的Ajax,以及Mobile app与服务端之间的通讯,JSON协议是首选。对于性能要求不太高,或者以动态类型语言为主,或者传输数据载荷很小的的运用场景,JSON也是非常不错的选择。
对于调试环境比较恶劣的场景,采用JSON或XML能够极大的提高调试效率,降低系统开发成本。
当对性能和简洁性有极高要求的场景,Protobuf,Thrift,Avro之间具有一定的竞争关系。
对于T级别的数据的持久化应用场景,Protobuf和Avro是首要选择。如果持久化后的数据存储在hadoop子项目里,Avro会是更好的选择。
对于持久层非Hadoop项目,以静态类型语言为主的应用场景,Protobuf会更符合静态类型语言工程师的开发习惯。由于Avro的设计理念偏向于动态类型语言,对于动态语言为主的应用场景,Avro是更好的选择。
如果需要提供一个完整的RPC解决方案,Thrift是一个好的选择。
如果序列化之后需要支持不同的传输层协议,或者需要跨防火墙访问的高性能场景,Protobuf可以优先考虑。
protobuf的数据类型有多种:bool、double、float、int32、int64、string、bytes、enum、message。protobuf的限定符:required: 必须赋值,不能为空、optional:字段可以赋值,也可以不赋值、repeated: 该字段可以重复任意次数(包括0次)、枚举;只能用指定的常量集中的一个值作为其值;
protobuf的基本规则:每个消息中必须至少留有一个required类型的字段、包含0个或多个optional类型的字段;repeated表示的字段可以包含0个或多个数据;[1,15]之内的标识号在编码的时候会占用一个字节(常用),[16,2047]之内的标识号则占用2个字节,标识号一定不能重复、使用消息类型,也可以将消息嵌套任意多层,可用嵌套消息类型来代替组。
protobuf的消息升级原则:不要更改任何已有的字段的数值标识;不能移除已经存在的required字段,optional和repeated类型的字段可以被移除,但要保留标号不能被重用。新添加的字段必须是optional或repeated。因为旧版本程序无法读取或写入新增的required限定符的字段。
编译器为每一个消息类型生成了一个.java文件,以及一个特殊的Builder类(该类是用来创建消息类接口的)。如:UserProto.User.Builder builder = UserProto.User.newBuilder();builder.build();
Netty中的使用:ProtobufVarint32FrameDecoder 是用于处理半包消息的解码类;ProtobufDecoder(UserProto.User.getDefaultInstance())这是创建的UserProto.java文件中的解码类;ProtobufVarint32LengthFieldPrepender 对protobuf协议的消息头上加上一个长度为32的整形字段,用于标志这个消息的长度的类;ProtobufEncoder 是编码类
将StringBuilder转换为ByteBuf类型:copiedBuffer()方法
16.Netty 支持哪些心跳类型设置?
readerIdleTime:为读超时时间(即测试端一定时间内未接受到被测试端消息)。
writerIdleTime:为写超时时间(即测试端一定时间内向被测试端发送消息)。
allIdleTime:所有类型的超时时间。
17.Netty 和 Tomcat 的区别?
作用不同:Tomcat 是 Servlet 容器,可以视为 Web 服务器,而 Netty 是异步事件驱动的网络应用程序框架和工具用于简化网络编程,例如TCP和UDP套接字服务器。
协议不同:Tomcat 是基于 http 协议的 Web 服务器,而 Netty 能通过编程自定义各种协议,因为 Netty 本身自己能编码/解码字节流,所有 Netty 可以实现,HTTP 服务器、FTP 服务器、UDP 服务器、RPC 服务器、WebSocket 服务器、Redis 的 Proxy 服务器、MySQL 的 Proxy 服务器等等。
多路复用IO(IO multiplexing)
IO multiplexing这个词可能有点陌生,但是如果我说select/epoll,大概就都能明白了。有些地方也称这种IO方式为事件驱动IO(event driven IO)。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
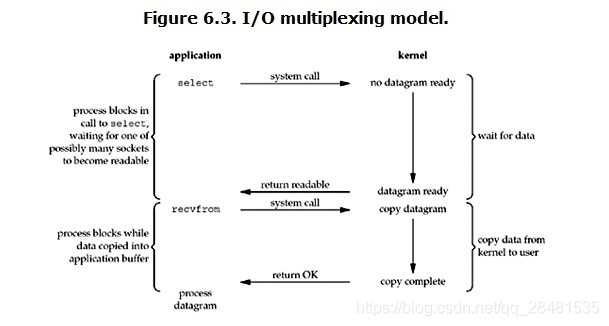
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
强调:
1. 如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
2. 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
结论: select的优势在于可以处理多个连接,不适用于单个连接
select、poll、epoll区别
(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
(3)epoll==>时间复杂度O(1)
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
fd存放文件描述符
RabbitMQ
RabbitMQ保证消息顺序性总结:
核心思路就是根据业务数据关键值划分成多个消息集合,而且每个消息集合中的消息数据都是有序的,每个消息集合有自己独立的一个consumer。多个消息集合的存在保证了消息消费的效率,每个有序的消息集合对应单个的consumer也保证了消息消费时的有序性。
zookeeper
zookeeper一致性协议:
zookeeper实现数据一致性的核心是ZAB协议(Zookeeper原子消息广播协议)。该协议需要做到以下几点:
(1)集群在半数以下节点宕机的情况下,能正常对外提供服务;
(2)客户端的写请求全部转交给leader来处理,leader需确保写变更能实时同步给所有follower及observer;
(3)leader宕机或整个集群重启时,需要确保那些已经在leader服务器上提交的事务最终被所有服务器都提交,确保丢弃那些只在leader服务器上被提出的事务,并保证集群能快速恢复到故障前的状态。
Zab协议有两种模式, 崩溃恢复(选主+数据同步)和消息广播(事务操作)。任何时候都需要保证只有一个主进程负责进行事务操作,而如果主进程崩溃了,就需要迅速选举出一个新的主进程。主进程的选举机制与事务操作机制是紧密相关的。下面详细讲解这三个场景的协议规则,从细节去探索ZAB协议的数据一致性原理。
1、选主:leader选举是zk中最重要的技术之一,也是保证分布式数据一致性的关键所在。当集群中的一台服务器处于如下两种情况之一时,就会进入leader选举阶段——服务器初始化启动、服务器运行期间无法与leader保持连接。
选举阶段,集群间互传的消息称为投票,投票Vote主要包括二个维度的信息:ID、ZXID
ID 被推举的leader的服务器ID,集群中的每个zk节点启动前就要配置好这个全局唯一的ID。
ZXID 被推举的leader的事务ID ,该值是从机器DataTree内存中取的,即事务已经在机器上被commit过了。
节点进入选举阶段后的大体执行逻辑如下:
(1)设置状态为LOOKING,初始化内部投票Vote (id,zxid) 数据至内存,并将其广播到集群其它节点。节点首次投票都是选举自己作为leader,将自身的服务ID、处理的最近一个事务请求的ZXID(ZXID是从内存数据库里取的,即该节点最近一个完成commit的事务id)及当前状态广播出去。然后进入循环等待及处理其它节点的投票信息的流程中。
(2)循环等待流程中,节点每收到一个外部的Vote信息,都需要将其与自己内存Vote数据进行PK,规则为取ZXID大的,若ZXID相等,则取ID大的那个投票。若外部投票胜选,节点需要将该选票覆盖之前的内存Vote数据,并再次广播出去;同时还要统计是否有过半的赞同者与新的内存投票数据一致,无则继续循环等待新的投票,有则需要判断leader是否在赞同者之中,在则退出循环,选举结束,根据选举结果及各自角色切换状态,leader切换成LEADING、follower切换到FOLLOWING、observer切换到OBSERVING状态。
2、选主后的数据同步:选主算法中的zxid是从内存数据库中取的最新事务id,事务操作是分两阶段的(提出阶段和提交阶段),leader生成提议并广播给followers,收到半数以上的ACK后,再广播commit消息,同时将事务操作应用到内存中。follower收到提议后先将事务写到本地事务日志,然后反馈ACK,等接到leader的commit消息时,才会将事务操作应用到内存中。可见,选主只是选出了内存数据是最新的节点,仅仅靠这个是无法保证已经在leader服务器上提交的事务最终被所有服务器都提交。比如leader发起提议P1,并收到半数以上follower关于P1的ACK后,在广播commit消息之前宕机了,选举产生的新leader之前是follower,未收到关于P1的commit消息,内存中是没有P1的数据。而ZAB协议的设计是需要保证选主后,P1是需要应用到集群中的。这块的逻辑是通过选主后的数据同步来弥补。
选主后,节点需要切换状态,leader切换成LEADING状态后的流程如下:
(1)重新加载本地磁盘上的数据快照至内存,并从日志文件中取出快照之后的所有事务操作,逐条应用至内存,并添加到已提交事务缓存commitedProposals。这样能保证日志文件中的事务操作,必定会应用到leader的内存数据库中。
(2)获取learner发送的FOLLOWERINFO/OBSERVERINFO信息,并与自身commitedProposals比对,确定采用哪种同步方式,不同的learner可能采用不同同步方式(DIFF同步、TRUNC+DIFF同步、SNAP同步)。这里是拿learner内存中的zxid与leader内存中的commitedProposals(min、max)比对,如果zxid介于min与max之间,但又不存在于commitedProposals中时,说明该zxid对应的事务需要TRUNC回滚;如果 zxid 介于min与max之间且存在于commitedProposals中,则leader需要将zxid+1~max 间所有事务同步给learner,这些内存缺失数据,很可能是因为leader切换过程中造成commit消息丢失,learner只完成了事务日志写入,未完成提交事务,未应用到内存。
(3)leader主动向所有learner发送同步数据消息,每个learner有自己的发送队列,互不干扰。同步结束时,leader会向learner发送NEWLEADER指令,同时learner会反馈一个ACK。当leader接收到来自learner的ACK消息后,就认为当前learner已经完成了数据同步,同时进入“过半策略”等待阶段。当leader统计到收到了一半已上的ACK时,会向所有已经完成数据同步的learner发送一个UPTODATE指令,用来通知learner集群已经完成了数据同步,可以对外服务了。
细节可参照Leader.lead() 、Follower.followLeader()及LearnerHandler类。
3、事务操作:ZAB协议对于事务操作的处理是一个类似于二阶段提交过程。针对客户端的事务请求,leader服务器会为其生成对应的事务proposal,并将其发送给集群中所有follower机器,然后收集各自的选票,最后进行事务提交。流程如下图。
ZAB协议的二阶段提交过程中,移除了中断逻辑(事务回滚),所有follower服务器要么正常反馈leader提出的事务proposal,要么就抛弃leader服务器。follower收到proposal后的处理很简单,将该proposal写入到事务日志,然后立马反馈ACK给leader,也就是说如果不是网络、内存或磁盘等问题,follower肯定会写入成功,并正常反馈ACK。leader收到过半follower的ACK后,会广播commit消息给所有learner,并将事务应用到内存;learner收到commit消息后会将事务应用到内存。
ZAB协议中多次用到“过半”设计策略 ,该策略是zk在A(可用性)与C(一致性)间做的取舍,也是zk具有高容错特性的本质。相较分布式事务中的2PC(二阶段提交协议)的“全量通过”,ZAB协议可用性更高(牺牲了部分一致性),能在集群半数以下服务宕机时正常对外提供服务。
Redis
redis的三种集群方式
redis有三种集群方式:主从复制,哨兵模式和集群。
1.主从复制
主从复制原理:
从服务器连接主服务器,发送SYNC命令;
主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;(从服务器初始化完成)
主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令(从服务器初始化完成后的操作)
主从复制优缺点:
优点:
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离
为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成
Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。
Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据
缺点:
Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
2.哨兵模式
当主服务器中断服务后,可以将一个从服务器升级为主服务器,以便继续提供服务,但是这个过程需要人工手动来操作。 为此,Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。
哨兵的作用就是监控Redis系统的运行状况。它的功能包括以下两个。
(1)监控主服务器和从服务器是否正常运行。
(2)主服务器出现故障时自动将从服务器转换为主服务器。
哨兵的工作方式:
每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态
当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)
在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
哨兵模式的优缺点
优点:
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
主从可以自动切换,系统更健壮,可用性更高。
缺点:
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
3.Redis-Cluster集群
redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。
Redis-Cluster采用无中心结构,它的特点如下:
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
节点的fail是通过集群中超过半数的节点检测失效时才生效。
客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
工作方式:
在redis的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是cluster,可以理解为是一个集群管理的插件。当我们的存取的key到达的时候,redis会根据crc16的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
为了保证高可用,redis-cluster集群引入了主从模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点A1都宕机了,那么该集群就无法再提供服务了。
RDB 的优势和劣势
①、优势
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
②、劣势
RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
AOF的优点和缺点
4、优点
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。(2)AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
5、缺点
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。
redis数据类型及数据结构
redisObject
Redis的key是顶层模型,它的value是扁平化的。Redis中,所有的value都是一个object,它的结构如下:
typedef struct redisObject {
unsigned [type] 4;
unsigned [encoding] 4;
unsigned [lru] REDIS_LRU_BITS;
int refcount;
void *ptr;
} robj;
简单介绍一下这几个字段:
type:数据类型,就是我们熟悉的string、hash、list等。
encoding:内部编码,其实就是本文要介绍的数据结构。指的是当前这个value底层是用的什么数据结构。因为同一个数据类型底层也有多种数据结构的实现,所以这里需要指定数据结构。
REDIS_LRU_BITS:当前对象可以保留的时长。这个我们在后面讲键的过期策略的时候讲。
refcount:对象引用计数,用于GC。
ptr:指针,指向以encoding的方式实现这个对象的实际地址。
Redis基本类型及其数据结构
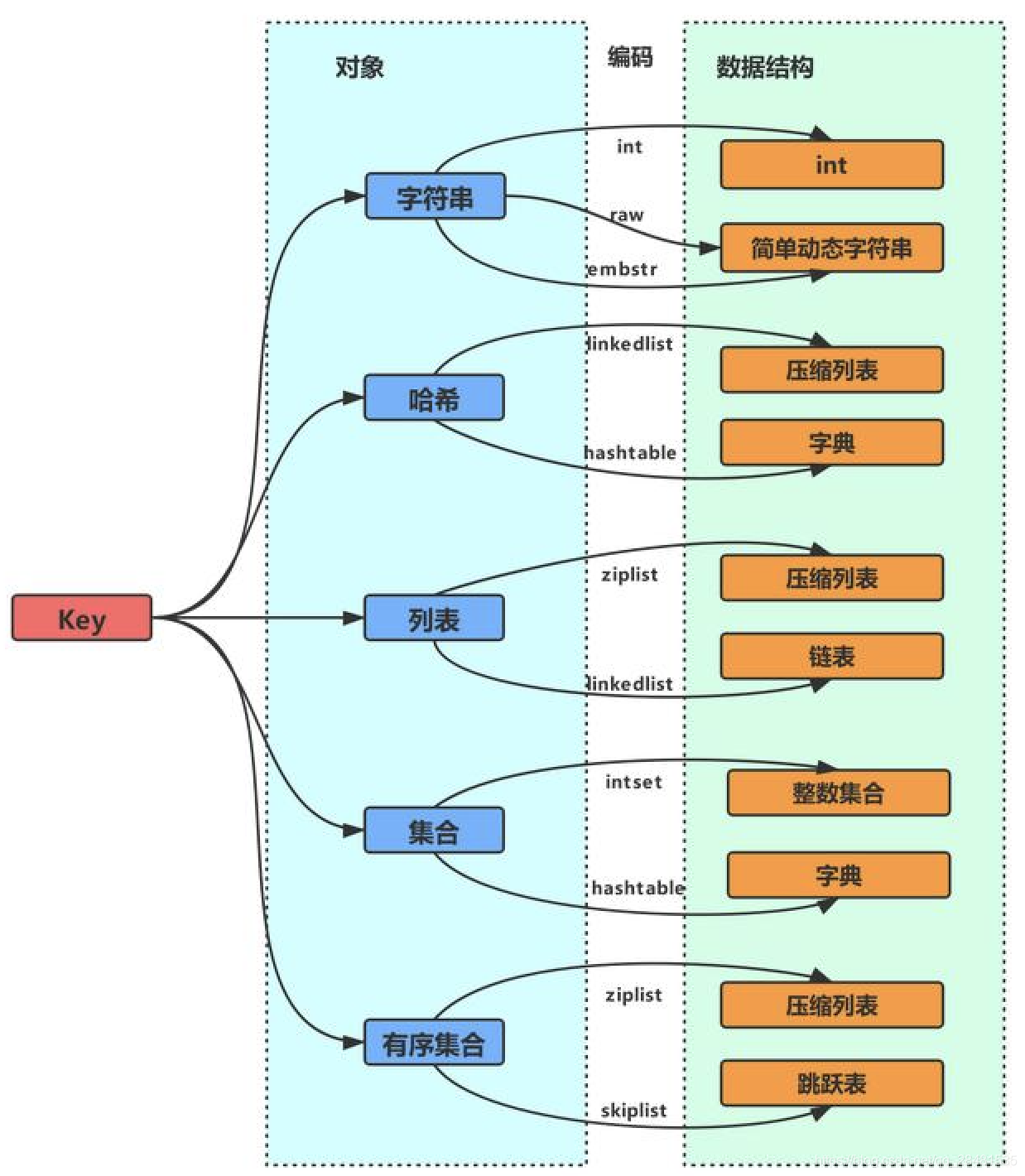
string
在Redis内部,string类型有两种底层储存结构。Redis会根据存储的数据及用户的操作指令自动选择合适的结构:
int:存放整数类型;
SDS:存放浮点、字符串、字节类型;
SDS: 简单动态字符串 simple dynamic string
SDS
SDS的内部数据结构:
typedef struct sdshdr {
// buf中已经占用的字符长度
unsigned int len;
// buf中剩余可用的字符长度
unsigned int free;
// 数据空间
char buf[];
}
可见,其底层是一个char数组。buf最大容量为512M,里面可以放字符串、浮点数和字节。所以你甚至可以放一张序列化后的图片。它为什么没有直接使用数组,而是包装成了这样的数据结构呢?
因为buf会有动态扩容和缩容的需求。如果直接使用数组,那每次对字符串的修改都会导致重新分配内存,效率很低。
buf的扩容过程如下:
如果修改后len长度将小于1M,这时分配给free的大小和len一样,例如修改过后为10字节, 那么给free也是10字节,buf实际长度变成了10 + 10 + 1 = 21byte
如果修改后len长度将大于等于1M,这时分配给free的长度为1M,例如修改过后为30M,那么给free是1M.buf实际长度变成了30M + 1M + 1byte
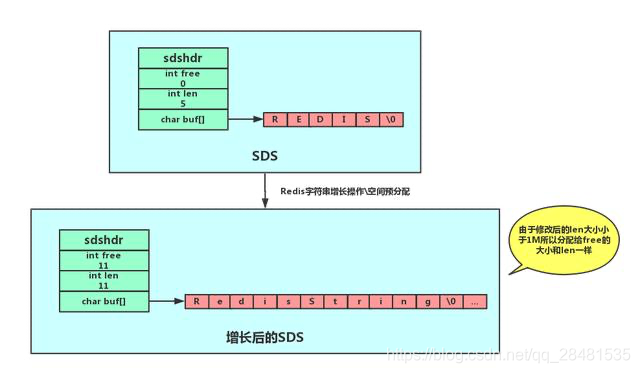
Redis基本类型及其数据结构
惰性空间释放指的是当字符串缩短时,并没有真正的缩容,而是移动free的指针。这样将来字符串长度增加时,就不用重新分配内存了。但这样会造成内存浪费,Redis提供了API来真正释放内存。
list
list底层有两种数据结构:链表linkedlist和压缩列表ziplist。当list元素个数少且元素内容长度不大时,使用ziplist实现,否则使用linkedlist。
链表
Redis使用的链表是双向链表。为了方便操作,使用了一个list结构来持有这个链表。如图所示:

typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void *(*free)(void *ptr);
//节点值对比函数
int (*match)(void *ptr,void *key);
}list;
data存的其实也是一个指针。链表里面的元素是上面介绍的string。因为是双向链表,所以可以很方便地把它当成一个栈或者队列来使用。
压缩列表
与上面的链表相对应,压缩列表有点儿类似数组,通过一片连续的内存空间,来存储数据。不过,它跟数组不同的一点是,它允许存储的数据大小不同。每个节点上增加一个length属性来记录这个节点的长度,这样比较方便地得到下一个节点的位置。
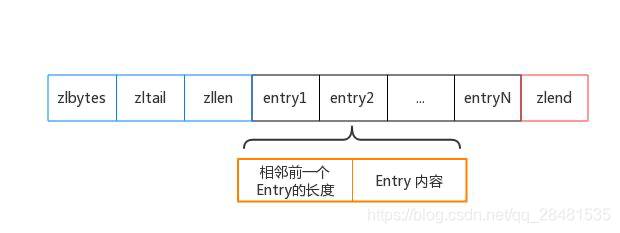
上图的各字段含义为:
zlbytes:列表的总长度
zltail:指向最末元素
zllen:元素的个数
entry:元素的内容,里面记录了前一个Entry的长度,用于方便双向遍历
zlend:恒为0xFF,作为ziplist的定界符
压缩列表不只是list的底层实现,也是hash的底层实现之一。当hash的元素个数少且内容长度不大时,使用压缩列表来实现。
hash
hash底层有两种实现:压缩列表和字典(dict)。压缩列表刚刚上面已经介绍过了,下面主要介绍一下字典的数据结构。
字典
字典其实就类似于Java语言中的Map,Python语言中的dict。与Java中的HashMap类似,Redis底层也是使用的散列表作为字典的实现,解决hash冲突使用的是链表法。Redis同样使用了一个数据结构来持有这个散列表:
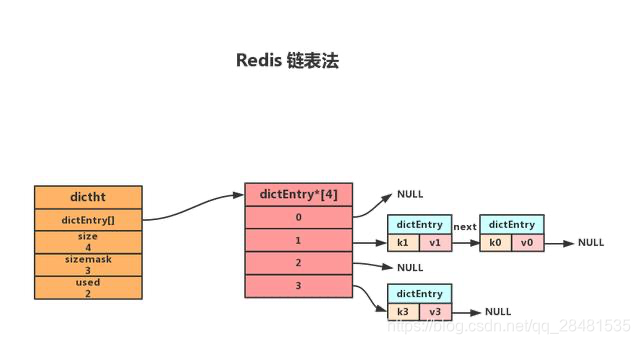
在键增加或减少时,会扩容或缩容,并且进行rehash,根据hash值重新计算索引值。那如果这个字典太大了怎么办呢?
为了解决一次性扩容耗时过多的情况,可以将扩容操作穿插在插入操作的过程中,分批完成。当负载因子触达阈值之后,只申请新空间,但并不将老的数据搬移到新散列表中。当有新数据要插入时,将新数据插入新散列表中,并且从老的散列表中拿出一个数据放入到新散列表。每次插入一个数据到散列表,都重复上面的过程。经过多次插入操作之后,老的散列表中的数据就一点一点全部搬移到新散列表中了。这样没有了集中的一次一次性数据搬移,插入操作就都变得很快了。这个过程也被称为渐进式rehash。
set
set里面没有重复的集合。set的实现比较简单。如果是整数类型,就直接使用整数集合intset。使用二分查找来辅助,速度还是挺快的。不过在插入的时候,由于要移动元素,时间复杂度是O(N)。
如果不是整数类型,就使用上面在hash那一节介绍的字典。key为set的值,value为空。
zset
zset是可排序的set。与hash的实现方式类似,如果元素个数不多且不大,就使用压缩列表ziplist来存储。不过由于zset包含了score的排序信息,所以在ziplist内部,是按照score排序递增来存储的。意味着每次插入数据都要移动之后的数据。
跳表
跳表(skiplist)是另一种实现dict的数据结构。跳表是对链表的一个增强。我们在使用链表的时候,即使元素的有序排列的,但如果要查找一个元素,也需要从头一个个查找下去,时间复杂度是O(N)。而跳表顾名思义,就是跳跃了一些元素,可以抽象多层。
如下图所示,比如我们要查找8,先在最上层L2查找,发现在1和9之间;然后去L1层查找,发现在5和9之间;然后去L0查找,发现在7和9之间,然后找到8。
当元素比较多时,使用跳表可以显著减少查找的次数。
同list类似,Redis内部也不是直接使用的跳表,而是使用了一个自定义的数据结构来持有跳表。下图左边蓝色部分是skiplist,右边是4个zskiplistNode。zskiplistNode内部有很多层L1、L2等,指针指向这一层的下一个结点。BW是回退指针(backward),用于查找的时候回退。然后下面是score和对象本身object。
Redis基本类型及其数据结构
总结
Redis对外暴露的是对象(数据类型),而每个对象都是用一个redisObject持有,通过不同的编码,映射到不同的数据结构。从最开始的那个图可以知道,有时候不同对象可能会底层使用同一种数据结构,比如压缩列表和字典等。
在了解数据结构后,我们就能够更清楚应该选用什么样的对象,出现问题时应该如何优化了。
Redis对于过期键有三种清除策略
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key
- 当前已用内存超过maxmemory限定时,触发主动清理策略
redis数据类型
String、list、hash、set、zset
什么是跳跃表?
它其实是一种随机化的数据结构,一个多层的有序链表,一种基于概率统计的插入算法。
2. redis中的zset为什么不使用红黑树而使用跳跃表
首先,在做范围查询的时候,平衡树的操作要比跳跃表复杂。因为平衡树,在查询到最小值的时候,还需要采用中序遍历去查询最大值。 而skipList只需要在找到最小值后,对第一层的链表(也就是最底层的链表)进行若干次遍历即可。
平衡树的删除和插入,需要对子树进行相应的调整,操作复杂。而skiplist只需要修改相邻的节点即可。
在做查询操作的时候,skiplist和平衡树都是O(logN)的时间复杂度。
从整体上来看,skiplist算法实现的难度要低于平衡树。
HBase
HBase 不同压缩方式介绍
GZ(GZIP)
用于冷数据存储,要求数据访问不频繁,与 Snappy 和 LZO 相比,GZIP 的压缩率更高,但是更消耗 CPU,解压/压缩速度更慢。
Snappy 和 LZO
用于热数据存储,数据访问频繁时使用,占用 CPU 少,解压/压缩速度比 GZ 快,但是压缩率不如 GZ 高。
大部分场景下,开启 Snappy 或者 LZO 压缩会是比较好的选择,其中 Snappy 整体性能优于 LZO,主要表现在解压/压缩速度更快,是使用较多的一种压缩方式。
LZ4
这是一种追求极致解压/压缩速度的压缩方式,HBase 官网上介绍不多。根据 HBase 社区的测试结果来看,在不同业务类型数据下,LZ4 的压缩率与 LZO 相当或者略小于 LZO,但是解压速度却明显高于 LZO,部分场景下可以达到 LZO 的两倍以上。
Hbase列族数量限制思考
每个 RegionServer 包含多个 Region,每个 Region 包含多个Store,每个 Store 包含一个 MemStore 和多个 StoreFile。
在 Hbase 的表中,每个列族对应 Region 中的一个Store,Region的大小达到阈值时会分裂,因此如果表中有多个列族,则可能出现以下现象:
1)一个Region中有多个Store,如果每个CF的数据量分布不均匀时,比如CF1为100万,CF2为1万,则 Region分裂时导致CF2在每个Region中的数据量太少,查询CF2时会横跨多个Region导致效率降低。
2)如果每个CF的数据分布均匀,比如CF1有50万,CF2有50万,CF3有50万,则Region分裂时导致每个CF 在Region的数据量偏少,查询某个CF时会导致横跨多个Region的概率增大。
3)多个CF代表有多个Store,也就是说有多个MemStore,也就导致内存的消耗量增大,使用效率下降。
4)Region 中的 缓存刷新 和 压缩 是基本操作,即一个CF出现缓存刷新或压缩操作,其它CF也会同时做一样的操作,当列族太多时就会导致IO频繁的问题。
Memstore与storefile
一个region由多个store组成,每个store包含一个列族的所有数据。Store包括位于内存的memstore和位于硬盘的storefile
写操作先写入memstore,当memstore中的数据量达到某个阈值,Hregionserver启动flashcache进程写入storefile,每次写入形成单独一个storefile,输出多个storefile后,当storefile数量达到阈值时,将多个合并成一个大的storefile。当storefile大小超过一定阈值后,会把当前的region分割成两个,并由Hmaster分配给相应的region服务器,实现负载均衡。
客户端检索数据时,先在memstore找,找不到再找storefile
HLog(WAL log)
WAL 意为Write ahead log,类似mysql中的binlog,用来做灾难恢复时用,Hlog记录数据的所有变更,一旦数据修改,就可以从log中进行恢复。
每个Region Server 维护一个Hlog,并且每个Region Server 中也仅有一个Hlog。这样不同region(来自不同table)的日志会混在一起,这样做的目的是不断追加单个文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此可以提高对table的写性能。带来的麻烦是,如果一台region server下线,为了恢复其上的region,需要将region server上的log进行拆分,然后分发到其它region server上进行恢复。
Hlog的切分机制
1.当数据写入hlog以后,hbase发生异常,关闭当前的hlog文件
2.当日志的大小达到HDFS数据块的0.95倍的时候,关闭当前日志,生成新的日志
3.每隔一小时生成一个新的日志文件
HBase中高表和宽表的优缺点?
因为HBase是列式存储的nosql,宽表是指很多列较少行,即列多行少的表,一行中的数据量较大,行数少,而高表是指很多行较少列,即行多列少,一行中的数据量较少,行数大。
经过查询,总结出如下结论:
高表优势:
- 查询性能更好------因为查询条件都在row key中,而高表的行数据较少,所以查询缓存BlockCache能缓存更多的行;
- 分片能力更强------同样因为高表中行数据少,宽表中行数据多。HBase按行(row key)来进行分片,所以分片能力更强;
宽表优势: - 元数据开销较小—高表中行多,row key多,可能造成region数量也多,过大的元数据开销,可能引起HBase集群的不稳定;
- 事务(业务)能力更强----宽表事务性更好。HBase对一行的写入(Put)是有事务原子性的,一行的所有列要么全部写入成功,要么全部没有写入。但是多行的更新之间没有事务性保证;
- 数据压缩比更高—故名思议,宽表中行数据远远大于高表,故获得的压缩比更高。
1、 存储
不同的排序、搜索算法在性能上差别可以非常大,从O(n^2)到O(log2N)甚至O(1)。同样不能的存储模型和索引结构对数据库的读写性能影响很大。HBase通过LSM存储模型提高写性能的同时又能保证读性能。
B+树比B树更适合做数据库系统索引。尤其是对于HBase这类常用区间扫描的数据库,因为B+树只需要遍历所有叶子节点即可实现区间扫描,B+树的最大性能问题就是插入,随着越来越多的数据插入,叶子节点会慢慢分裂,逻辑上会存储到磁盘的不痛快,做区间扫描产生大量随机读IO,同时数据写入时维护树的分裂、合并也会产生大量随机写IO。
2、 LSM树
为了解决B+树随机写IO的问题,HBase引入了LSM树(log structured merge-trees),LSM的核心思想是将一颗大树拆分成多棵小树,HBase数据的写入都会先写MemStore,在内存中构建一颗有序的小树,当MemStore达到一定条件时即会刷新输出写入到磁盘,所以写入速度很快。这里的弊端是随着数据量的增大,StoreFile(即小树)会越来越多,导致查询数据时需要扫描所有的文件,显然文件越多,扫描效率越低。
LSM的merge(合并),当MemStore刷新后StoreFile达到配置的数量或者距离上次压缩时间满足配置的间隔时,HBase即会自动触发压缩(MINOR和MAJOR),合并成一棵大树。
LSM的核心思想是通过牺牲一定的读性能来换取写能力的最大化。为了避免读性能下降成为瓶颈,HBase也提供了一些其他策略。例如:布隆过滤器等过滤查询所需要读取的文件数量以提高读性能。
LSM为了提高写性能,数据先写入内存,如果服务器宕机或者断点,就会导致内存数据丢失,为了解决该问题,HBase引入了WAL。
3、 预写入日志(WAL)
WAL(write ahead log)即预写入日志。由于LSM为了提高写性能,数据先写入内存,如果服务器宕机或者断点会导致内存数据丢失,HBase写入内存之前也需要写WAL以便异常恢复。
USE_DEFAULT:默认的持久化策略
SKIP_WAL:不写WAL
ASYNC_WAL:异步写入
FSYNC_WAL:等同于sync_wal
当HBase客户端向服务端分区服务器提交数据修改请求后,分区服务器的RPC处理线程池负责接收处理这些请求,客户端与服务端的数据交互格式为Protobuf。在WAL的写入过程中使用了一个叫做LMAX Disruptor的高性能缓存对垒RingBuffer,RPCHandler作为生产者向RingBuffer按序列添加数据变更封装成的WALEdit,而FSHLog的内部类作为消费者从队列读取数据然后写入文件系统,这个生产消费模型是一个多生产者单消费者模型,单消费者按RingBuffer序列顺序刷新数据到文件系统,保证WAL并发写入只有一个线程在真正写入文件,做到分区服务器全局唯一,WAL的实现类为FSHLog.java。
4、 数据写入读取
HBase数据的写入与读取需要客户端先通过读取HMaster节点上的元数据定位到本次插入或者读取数据所在分区由那个分区服务器负责,之后HBase客户端直接与定位到的分区服务器通信。
分区是Hbase浮在均衡的最小单元,均衡的分布在HBase集群的每台分区服务器。HBase客户端进行数据查询、修改、删除等操作时,都需要先定位操作数据所在的分区,以及分区由那个分区服务器负责。HBase依赖Zookeeper来实现分区服务器的定位。
第三步,由于前面已经缓存了分区的开始结束行键以及所在分区服务器地址,因此之后的数据操作请求只需与对应的分区服务器交互,除非hbase客户端捕捉到IOException,此时HBase客户端会清除缓存,重新拉取分区位置信息。
注意:HBase客户端会将hbase:meta表数据缓存在本地,因此大部分情况下前两步只有在客户端第一次做数据操作请求的时候发生,因而对Zookeeper集群的压力很小。
HBase提供的客户端数据查询操作类包括Scan、Get,Get请求会被封装成Scan,然后当成一个特殊的Scan类型处理。
5、 协处理器
通过协处理器,我们可以把客户端复杂的计算逻辑移动到分区服务器去处理,即在数据的实际存储位置执行计算,这就是常说的移动“计算”比移动“数据”容易,数据在服务端处理完之后,再讲处理结果返回给客户端,这样就避免了大量的网络IO,效率大大提高。
因为协处理器是运行在服务端的,一旦代码有bug或者性能问题,对HBase集群性能甚至数据完整性等都有可能造成不可恢复的影响。
协处理器分为两大类:观察者类型协处理器、断点类型协处理器。
协处理器的具体使用方式请自行查找,不做更新
Dubbo
1. Dubbo是什么?
Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。
其核心部分包含:
-
远程通讯: 提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及“请求-响应”模式的信息交换方式。
-
集群容错: 提供基于接口方法的透明远程过程调用,包括多协议支持,以及软负载均衡,失败容错,地址路由,动态配置等集群支持。
-
自动发现: 基于注册中心目录服务,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器。
Dubbo能做什么?
1.透明化的远程方法调用,就像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入。
2.软负载均衡及容错机制,可在内网替代F5等硬件负载均衡器,降低成本,减少单点。
3.服务自动注册与发现,不再需要写死服务提供方地址,注册中心基于接口名查询服务提供者的IP地址,并且能够平滑添加或删除服务提供者。
Dubbo采用全Spring配置方式,透明化接入应用,对应用没有任何API侵入,只需用Spring加载Dubbo的配置即可,Dubbo基于Spring的Schema扩展进行加载。
之前使用Web Service,我想测试接口可以通过模拟消息的方式通过soapui或LR进行功能测试或性能测试。但现在使用Dubbo,接口之间不能直接交互,我尝试通过模拟消费者地址测试,结果不堪入目,再而使用jmeter通过junit进行测试,但还是需要往dubbo上去注册,如果再不给提供源代码的前提下,这个测试用例不好写啊….
dubbo的架构
dubbo架构图如下所示:
节点角色说明:
Provider: 暴露服务的服务提供方。
Consumer: 调用远程服务的服务消费方。
Registry: 服务注册与发现的注册中心。
Monitor: 统计服务的调用次调和调用时间的监控中心。
Container: 服务运行容器。
这点我觉得非常好,角色分明,可以根据每个节点角色的状态来确定该服务是否正常。
调用关系说明:
-
服务容器负责启动,加载,运行服务提供者。
-
服务提供者在启动时,向注册中心注册自己提供的服务。
-
服务消费者在启动时,向注册中心订阅自己所需的服务。
-
注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
-
服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
-
服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
dubbo的容错性显而易见,性能方面还没有还得及测,我们系统某页面需要掉5次接口,本来想建议做个缓存,但业务关系不能采纳,还需要研究下dubbo的性能调优问题…
负载均衡算法
轮询(RoundRobin):按请求顺序分发请求给队列中的服务器处理
比率(Ratio):给队列中的每个服务器分配一个加权值为比例,把每个请求按比例分发
优先权(Priority):给所有服务器分组,给每个组定义优先权,按照优先级分发请求到组(组内分发可按照轮询或者比率)
最少连接数(LeastConnection):负载均衡设备记录每个服务器或者服务端口上的连接数,新的连接将分发给连接数少的服务器
最快响应时间(Fast Response time):新的连接分发给响应最快的服务器
哈希算法(Hash):将客户端的源地址端口进行哈希运算,根据结果分发给对应的机器
基于策略:针对不同的数据流设置导向规则,用户自行编辑流量分配策略,利用这些策略对通过的数据流实施导向控制
基于数据包内容:可根据HTTP的url是否带有.jpg扩展名,分发给指定的服务器处理
健康检查
健康检查用于负载均衡设备检查服务器开放的各种服务的可用状态,可配置的检查方法有如ping,TCP,UDP,HTTP,FTP,DNS等。
创建健康检查可以设定检查的间隔时间和尝试次数。最好结合应用情况来评估设置,既不会对业务产生影响,又不会对负载设备产生很大负担。
会话保持
假设同一个用户的不同请求连续访问,连接是需要重新分发还是固定服务器处理呢?
其实由于服务器之间很难做到实时同步用户访问信息,比如用户登陆请求在一台机器处理,后续应用请求分发给其他机器处理的话,这时实时获取到集群其他机器中该用户的登陆信息成本是跟高的,所以对于同一用户的连续请求在负载均衡设备做会话保持动作,将同源地址请求分发给同一机器响应处理。当然对于一些静态页面数据可以不用保持会话,例如公告新闻类,在每台机器的响应结果都是一样的。
Zookeeper Watch
Znode发生变化(Znode本身的增加,删除,修改,以及子Znode的变化)可以通过Watch机制通知到客户端。那么要实现Watch,就必须实现org.apache.zookeeper.Watcher接口,并且将实现类的对象传入到可以Watch的方法中。Zookeeper中所有读操作(getData(),getChildren(),exists())都可以设置Watch选项。Watch事件具有one-time trigger(一次性触发)的特性,如果Watch监视的Znode有变化,那么就会通知设置该Watch的客户端。
在上述说道的所有读操作中,如果需要Watcher,我们可以自定义Watcher,如果是Boolean型变量,当为true时,则使用系统默认的Watcher,系统默认的Watcher是在Zookeeper的构造函数中定义的Watcher。参数中Watcher为空或者false,表示不启用Wather。
一,一次性触发器
客户端在Znode设置了Watch时,如果Znode内容发生改变,那么客户端就会获得Watch事件。例如:客户端设置getData(“/znode1”, true)后,如果/znode1发生改变或者删除,那么客户端就会得到一个/znode1的Watch事件,但是/znode1再次发生变化,那客户端是无法收到Watch事件的,除非客户端设置了新的Watch。
二,发送至客户端
Watch事件是异步发送到Client。Zookeeper可以保证客户端发送过去的更新顺序是有序的。例如:某个Znode没有设置watcher,那么客户端对这个Znode设置Watcher发送到集群之前,该客户端是感知不到该Znode任何的改变情况的。换个角度来解释:由于Watch有一次性触发的特点,所以在服务器端没有Watcher的情况下,Znode的任何变更就不会通知到客户端。不过,即使某个Znode设置了Watcher,且在Znode有变化的情况下通知到了客户端,但是在客户端接收到这个变化事件,但是还没有再次设置Watcher之前,如果其他客户端对该Znode做了修改,这种情况下,Znode第二次的变化客户端是无法收到通知的。这可能是由于网络延迟或者是其他因素导致,所以我们使用Zookeeper不能期望能够监控到节点每次的变化。Zookeeper只能保证最终的一致性,而无法保证强一致性。
三,设置watch的数据内容
Znode改变有很多种方式,例如:节点创建,节点删除,节点改变,子节点改变等等。Zookeeper维护了两个Watch列表,一个节点数据Watch列表,另一个是子节点Watch列表。getData()和exists()设置数据Watch,getChildren()设置子节点Watch。两者选其一,可以让我们根据不同的返回结果选择不同的Watch方式,getData()和exists()返回节点的内容,getChildren()返回子节点列表。因此,setData()触发内容Watch,create()触发当前节点的内容Watch或者是其父节点的子节点Watch。delete()同时触发父节点的子节点Watch和内容Watch,以及子节点的内容Watch。
Zookeeper Watcher的运行机制
1,Watch是轻量级的,其实就是本地JVM的Callback,服务器端只是存了是否有设置了Watcher的布尔类型。(源码见:org.apache.zookeeper.server.FinalRequestProcessor)
2,在服务端,在FinalRequestProcessor处理对应的Znode操作时,会根据客户端传递的watcher变量,添加到对应的ZKDatabase(org.apache.zookeeper.server.ZKDatabase)中进行持久化存储,同时将自己NIOServerCnxn做为一个Watcher callback,监听服务端事件变化
3,Leader通过投票通过了某次Znode变化的请求后,然后通知对应的Follower,Follower根据自己内存中的zkDataBase信息,发送notification信息给zookeeper客户端。
4,Zookeeper客户端接收到notification信息后,找到对应变化path的watcher列表,挨个进行触发回调。
ZooKeeper 的 watch 机制目前只能推送节点变更信息,比如节点内容数据变更,监听节点下子节点列表变更等,具体如下图:
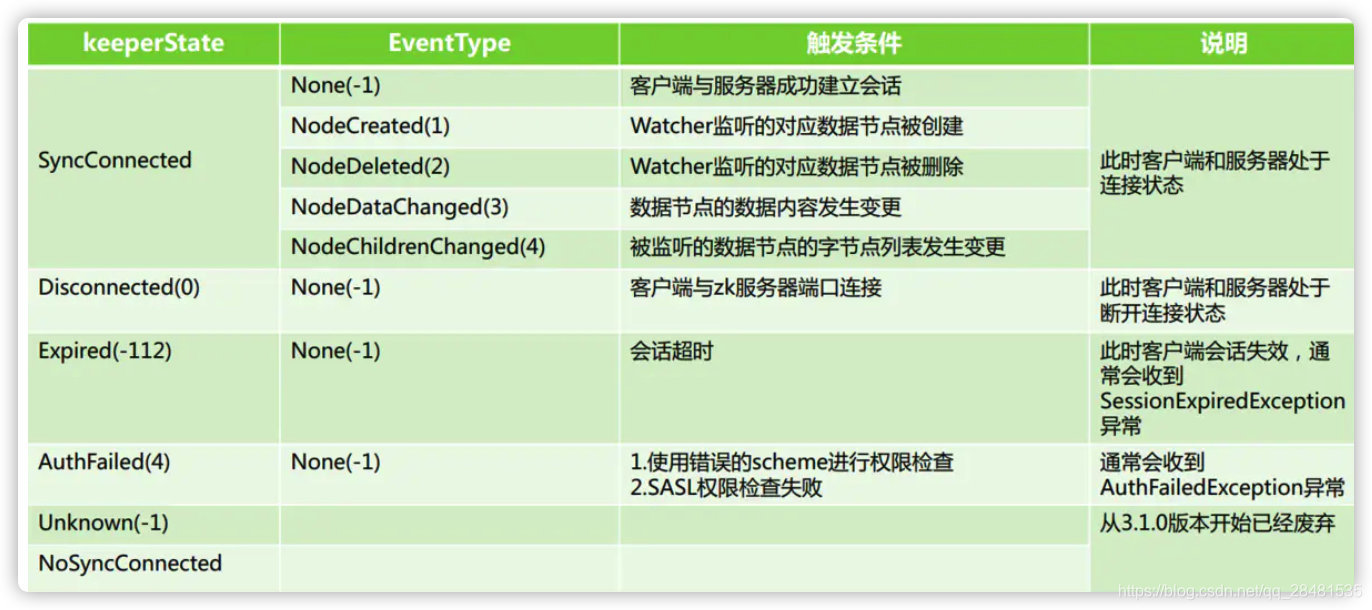
进一步从 Zookeeper 客户端的源码上来看,watcher 回调通知内容最终转为 WatchedEvent。
在收到推送的时候,我们能获取到变动节点信息,然后我再拉取一下子节点的列表不就好了!
HashMap数据插入原理
- 判断数组是否为空,为空进行初始化;
- 不为空,计算 k 的 hash 值,通过(n - 1) & hash计算应当存放在数组中的下标 index;
查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中; - 存在数据,说明发生了hash冲突(存在二个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据(onlyIfAbsent为false);
- 如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;(如果当前节点是树型节点证明当前已经是红黑树了)
- 如果不是树型节点,创建普通Node加入链表中;判断链表长度是否大于 8并且数组长度大于64, 大于的话链表转换为红黑树;
- 插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的二倍。
1.8还有三点主要的优化:
- 数组+链表改成了数组+链表或红黑树;
- 链表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,原始节点作为新节点的后继节点,1.8遍历链表,将元素放置到链表的最后;
- 扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑,位置不变或索引+旧容量大小;
- 在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容;
Docker
docker面试集锦
http://www.bjpowernode.com/hot/608.html
镜像创建步骤
- 拉取镜像,若本地已经存在该镜像,则不用到网上去拉取。
- 创建新的容器。
- 分配union文件系统并且挂着一个可读写的层,任何修改容器的操作都会被记录在这个读写层上,你可以保存这些修改成新的镜像,也可以选择不保存,那么下次运行改镜像的时候所有修改操作都会被消除。
- 分配网络\桥接接口,创建一个允许容器与本地主机通信的网络接口。
- 设置ip地址,从池中寻找一个可用的ip地址附加到容器上,换句话说,localhost并不能访问到容器。
- 运行你指定的程序。
- 捕获并且提供应用输出,包括输入、输出、报错信息。
Dockerfile指令ADD和COPY介绍
一、ADD指令
ADD指令的功能是将主机构建环境(上下文)目录中的文件和目录、以及一个URL标记的文件拷贝到镜像中。
其格式是:ADD 源路径 目标路径
有如下注意事项:
1、如果源路径是个文件,且目标路径是以/结尾,则docker会把目标路径当做一个目录,会把源文件拷贝到该目录下。
如果目标路径不存在,则会自动创建目标路径。
2、如果源路径是个文件,且目标路径不是以/结尾,则docker会把目标路径当做一个文件。
如果目标路径不存在,会以目标路径为名创建一个文件,内容同源文件;
如果目标文件是个存在的文件,会用源文件覆盖它,当然只是内容覆盖,文件名还是目标文件名。
如果目标文件实际是个存在的目录,则会将源文件拷贝到该目录下。注意,这种情况下,最好显示的以/结尾,以避免混淆。
3、如果原路径是个目录,且目标路径不存在,则docker会自动以目标路径创建一个目录,把源路径目录下的文件拷贝进来。
如果目标路径是个已经存在的目录,则docker会把源路径目录下的文件拷贝到该目录下。
4、如果源文件是个归档文件,则docker会自动帮解压。
二、COPY指令
COPY指令和ADD指令功能和使用方式类似。只是COPY指令不会做自动解压工作。
kafka原理
https://blog.youkuaiyun.com/suifeng3051/article/details/48053965
Tomcat类加载
详述Tomcat的类加载过程
Tomcat的类加载机制是违反了双亲委托原则的。主要是为了隔离加载。
加载类时,优先使用各个web应用自己的类加载器(WebAppClassLoader)加载。起到隔离加载的作用。
而在WebAppClassLoader的load方法中,会先找ExtClassLoader加载器加载,防止web应用覆盖加载核心jre类。然后通过WebAppClassLoader加载,做隔离加载目的。
若还是加载不到时再交给上层SharedClassLoader -> commonClassLoader -> appClassLoader 走双亲委托。实现统一加载。
上层启动类加载器,扩展类加载器与应用类加载器保持不变。
下面增加Common类加载器,加载/common/*下的class文件,用于加载所有项目与tomcat共用的class。其下再分两个分支。
其一Catalina类加载器,加载/server/*下的class文件,用于加载tomcat独有的class文件。
其二是Share类加载器,加载加载/share/*下的class文件,用于加载项目间共有的class文件。
但是由于一般的tomcat下仅部署一个项目,这三者最后都放在了lib目录下统一了。可在catalina.properties中见到配置。
其二下是WebApp类加载器,用于加载/WEB-INF/*下的class,用于加载项目独有的class文件。以防各项目间依赖的版本不同。每个webappClassLoader加载自己的目录下的class文件,不会传递给父类加载器。如果tomcat 的 Common ClassLoader 想加载 WebApp ClassLoader 中的类,需使用contextClassLoader。
webapp下是jsp类加载器, jsp会随jsp加载器一起被丢弃。从而完成jsp的热加载。
https://www.cnblogs.com/aspirant/p/8991830.html
Tomcat为何采取这样的类加载方式而不是双亲委派
1.要使同一tomcat下多个web应用间各自的类库互相隔离。尤其是不同版本。如果一旦交给同一个类加载器如common加载器,那么不同版本的类就具备了相同类型,这可能会发生问题。
2.要使同一tomcat下多个web应用间,相同版本的类库共享。
3.要使tomcat自己的类库和web应用的类库隔离
4.要支持JSP的热替换
应用对比
sychronized和reentrantlock区别
- 原始构成
Synchronized 是关键字,属于JVM层面,底层是通过 monitorenter 和 monitorexit 完成,依赖于 monitor 对象来完成。由于 wait/notify 方法也依赖于 monitor 对象,因此只有在同步块或方法中才能调用这些方法。
Lock 是 java.util.concurrent.locks.lock 包下的,是 api层面的锁。 - 使用方法
1、Synchronized 不需要用户手动释放锁,代码完成之后系统自动让线程释放锁
2、ReentrantLock 需要用户手动释放锁,没有手动释放可能导致死锁。 - 等待是否可以中断
1、Synchronized 不可中断,除非抛出异常或者正常运行完成
2、ReentrantLock 可以中断。一种是通过 tryLock(long timeout, TimeUnit unit),另一种是lockInterruptibly()放代码块中,调用interrupt()方法进行中断。 - 加锁是否公平
1、synchronized 是非公平锁
2、ReentrantLock 默认非公平锁,可以在构造方法传入 boolean 值,true 代表公平锁,false 代表非公平锁。 - 锁绑定多个 Condition
1、Synchronized 只有一个阻塞队列,只能随机唤醒一个线程或者唤醒全部线程。
2、ReentrantLock 用来实现分组唤醒,可以精确唤醒。
kafka和rabbitmq
1、集群负载均衡
从集群负载均衡方面来说
rabbitMQ的负载均衡需要单独的loadbalancer进行支持
kafka采用的是zookeeper对集群中的broker、consumer进行管理,能够注册topic到zookeeper上
通过zookeeper的协调机制,producer保存对应topic的broker信息,能够随机或者是轮询发送到broker上
producer能够基于语义指定分片,消息发送到broker的某分片上
2、吞吐量
从吞吐量方面来说
rabbitMQ比kafka的吞吐量要稍微逊色一些,两者的出发点是不一样的,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作,基于存储的可靠性的要求存储可以采用内存或者是硬盘
kafka有着较高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率非常高
3、架构模型
从架构模型方面来说
RabbitMQ遵循AMQP协议,RabbitMQ的broker由Exchange,Binding,queue组成,其中exchange和binding组成了消息的路由键
客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)
rabbitMQ以broker为中心
有消息的确认机制
kafka遵从一般的MQ结构,producer,broker,consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据
无消息确认机制
4、 可用性
从可用性方面来说
rabbitMQ支持miror的queue,主queue失效,miror queue接管
kafka的broker支持主备模式
mysql和hbase对比
- 并发性:关系型数据库更依赖单机性能,对于上万的QPS,硬盘IO无法支撑,并且关系型数据库除了写数据外还要写索引,而NoSql,以HBase为例,写入为顺序写入,如果能容忍部分数据的丢失不写WAL,hbase写入只需写内存,速度大大提高,同时hbase通过分片可以将一台机器的压力均衡地转移到集群的每一台机器。
- 可扩展性:现在一般的在线系统可用性至少都要求达到99.9%,对于淘宝天猫这种与金钱密切相关的系统,可用性要求就更高了。传统关系型数据库的升级和扩展对于系统的可用性是一个很头疼的问题,可能需要停机迁移数据,重启加载新配置等而且需要运维人员、开发人员、DBA的密切配合,而HBase集群具有线性伸缩,自动容灾和负载均衡的优势,可以很容易的增加或者替换集群节点以扩展集群的存储和计算能力。
- 数据模型:关系型数据库需要为存储的数据预先定义表结构与字段名,而Nosql无须事先为需要存储的数据定义一个模式,这样可以更容易、更灵活去适配各种类型的非结构化数据。
当然,并不是说Nosql已经全面优于关系型数据库了,NoSql相比关系型数据库也有很多缺点,例如HBase不支持多行事务;基于LSM存储模型导致需要读取多个文件来找到需要的数据,这样会牺牲一些读的性能。NoSql可以说是对关系型数据库的一种补充。
spring、springmvc、springcloud、dubbo
spring和springMvc:
-
spring是一个一站式的轻量级的java开发框架,核心是控制反转(IOC)和面向切面(AOP),针对于开发的WEB层(springMvc)、业务层(Ioc)、持久层(jdbcTemplate)等都提供了多种配置解决方案;
-
springMvc是spring基础之上的一个MVC框架,主要处理web开发的路径映射和视图渲染,属于spring框架中WEB层开发的一部分;
springMvc和springBoot:
-
springMvc属于一个企业WEB开发的MVC框架,涵盖面包括前端视图开发、文件配置、后台接口逻辑开发等,XML、config等配置相对比较繁琐复杂;
-
springBoot框架相对于springMvc框架来说,更专注于开发微服务后台接口,不开发前端视图,同时遵循默认优于配置,简化了插件配置流程,不需要配置xml,相对springmvc,大大简化了配置流程;
springBoot和springCloud:
-
spring boot使用了默认大于配置的理念,集成了快速开发的spring多个插件,同时自动过滤不需要配置的多余的插件,简化了项目的开发配置流程,一定程度上取消xml配置,是一套快速配置开发的脚手架,能快速开发单个微服务;
-
spring cloud大部分的功能插件都是基于springBoot去实现的,springCloud关注于全局的微服务整合和管理,将多个springBoot单体微服务进行整合以及管理; springCloud依赖于springBoot开发,而springBoot可以独立开发;
总结:
-
Spring 框架就像一个家族,有众多衍生产品例如 boot、security、jpa等等。但他们的基础都是Spring的ioc、aop等. ioc 提供了依赖注入的容器, aop解决了面向横切面编程,然后在此两者的基础上实现了其他延伸产品的高级功能;
-
springMvc主要解决WEB开发的问题,是基于Servlet 的一个MVC框架,通过XML配置,统一开发前端视图和后端逻辑;
-
由于Spring的配置非常复杂,各种XML、JavaConfig、servlet处理起来比较繁琐,为了简化开发者的使用,从而创造性地推出了springBoot框架,默认优于配置,简化了springMvc的配置流程;但区别于springMvc的是,springBoot专注于微服务方面的接口开发,和前端解耦,虽然springBoot也可以做成springMvc前后台一起开发,但是这就有点不符合springBoot框架的初衷了;
-
对于springCloud框架来说,它和springBoot一样,注重的是微服务的开发,但是springCloud更关注的是全局微服务的整合和管理,相当于管理多个springBoot框架的单体微服务;
1.什么是SpringCloud
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、熔断器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
2.SpringCloud与SpringBoot的关系
Spring Boot 是 Spring 的一套快速配置脚手架,可以基于Spring Boot 快速开发单个微服务,Spring Cloud是一个基于Spring Boot实现的云应用开发工具;Spring Boot专注于快速、方便集成的单个微服务个体,Spring Cloud关注全局的服务治理框架;
Spring Boot使用了默认大于配置的理念,很多集成方案已经帮你选择好了,能不配置就不配置,Spring Cloud很大的一部分是基于Spring Boot来实现.
可以不基于Spring Boot吗?不可以。
Spring Boot可以离开Spring Cloud独立使用开发项目,但是Spring Cloud离不开Spring Boot,属于依赖的关系。
3.SpringCloud主要框架
服务发现——Netflix Eureka
服务调用——Netflix Feign
熔断器——Netflix Hystrix
服务网关——Netflix Zuul
分布式配置——Spring Cloud Config
消息总线 —— Spring Cloud Bus
或许很多人会说Spring Cloud和Dubbo的对比有点不公平,Dubbo只是实现了服务治理,
三、dubbo的优势
单一应用架构,当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的 数据访问框架(ORM)是关键。
垂直应用架构,当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的 Web框架(MVC)是关键。
分布式服务架构,当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的 分布式服务框架(RPC)是关键。
流动计算架构当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的 资源调度和治理中心(SOA)是关键
分布式锁
加锁
public class RedisTool {
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
/**
* 尝试获取分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @param expireTime 超期时间
* @return 是否获取成功
*/
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
解锁(Lua脚本)
public class RedisTool {
private static final Long RELEASE_SUCCESS = 1L;
/**
* 释放分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @return 是否释放成功
*/
public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));
if (RELEASE_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
zookeeper分布式锁和redis的比较
总结一下ZooKeeper分布式锁:
(1)优点:ZooKeeper分布式锁(如InterProcessMutex),能有效的解决分布式问题,不可重入问题,使用起来也较为简单。
(2)缺点:ZooKeeper实现的分布式锁,性能并不太高。为啥呢?
因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。大家知道,ZK中创建和删除节点只能通过Leader服务器来执行,然后Leader服务器还需要将数据同不到所有的Follower机器上,这样频繁的网络通信,性能的短板是非常突出的。
总之,在高性能,高并发的场景下,不建议使用ZooKeeper的分布式锁。而由于ZooKeeper的高可用特性,所以在并发量不是太高的场景,推荐使用ZooKeeper的分布式锁。
在目前分布式锁实现方案中,比较成熟、主流的方案有两种:
(1)基于Redis的分布式锁
(2)基于ZooKeeper的分布式锁
两种锁,分别适用的场景为:
(1)基于ZooKeeper的分布式锁,适用于高可靠(高可用)而并发量不是太大的场景;
(2)基于Redis的分布式锁,适用于并发量很大、性能要求很高的、而可靠性问题可以通过其他方案去弥补的场景。
总之,这里没有谁好谁坏的问题,而是谁更合适的问题。
分布式事务(2PC/3PC/TCC 最终一致性详解)
kafka和rabbitmq什么区别,各自适合什么场景?
在应用场景方面
RabbitMQ RabbitMQ遵循AMQP协议,由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上,适合企业级的消息发送订阅,也是比较受到大家欢迎的。
kafka
kafka是Linkedin于2010年12月份开源的消息发布订阅系统,它主要用于处理活跃的流式数据,大数据量的数据处理上。常用日志采集,数据采集上。
ActiveMQ
异步调用
一对多通信
做多个系统的集成,同构、异构
作为RPC的替代
多个应用相互解耦
作为事件驱动架构的幕后支撑
为了提高系统的可伸缩性
在架构模型方面,
RabbitMQ
RabbitMQ遵循AMQP协议,RabbitMQ的broker由Exchange,Binding,queue组成,其中exchange和binding组成了消息的路由键;客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)。rabbitMQ以broker为中心;有消息的确认机制。
kafka
kafka遵从一般的MQ结构,producer,broker,consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据;无消息确认机制。
在吞吐量
kafka
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
rabbitMQ
rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
在可用性方面,
rabbitMQ
rabbitMQ支持miror的queue,主queue失效,miror queue接管。
kafka
kafka的broker支持主备模式。
在集群负载均衡方面,
kafka
kafka采用zookeeper对集群中的broker、consumer进行管理,可以注册topic到zookeeper上;通过zookeeper的协调机制,producer保存对应topic的broker信息,可以随机或者轮询发送到broker上;并且producer可以基于语义指定分片,消息发送到broker的某分片上。
rabbitMQ
rabbitMQ的负载均衡需要单独的loadbalancer进行支持。
单机和分布式系统的流控方案
[Hystric断路器]
https://zhuanlan.zhihu.com/p/88471553
https://blog.youkuaiyun.com/manzhizhen/article/details/79591132




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











