



 本文介绍如何利用Scrapy框架爬取一个网站上的妹子图片。每个图片详情页的图片数量不固定,总共成功抓取了约12万张图片。代码包括items.py、pipelines.py、settings.py和spiders.py四个部分。
本文介绍如何利用Scrapy框架爬取一个网站上的妹子图片。每个图片详情页的图片数量不固定,总共成功抓取了约12万张图片。代码包括items.py、pipelines.py、settings.py和spiders.py四个部分。
Scrapy爬取妹子图详解
scrapy的安装此处不做详细介绍,网上有跟多教程,可以自己找一下,直接上代码。
先看一下我们要开始爬的页面,将地址栏中的地址复制,作为我们的起始爬取点,也就是scrapy中的start_urls,然后提取图片的地址,利用scrapy自有的ImagesPipeline进行下载图片。
拿到地址
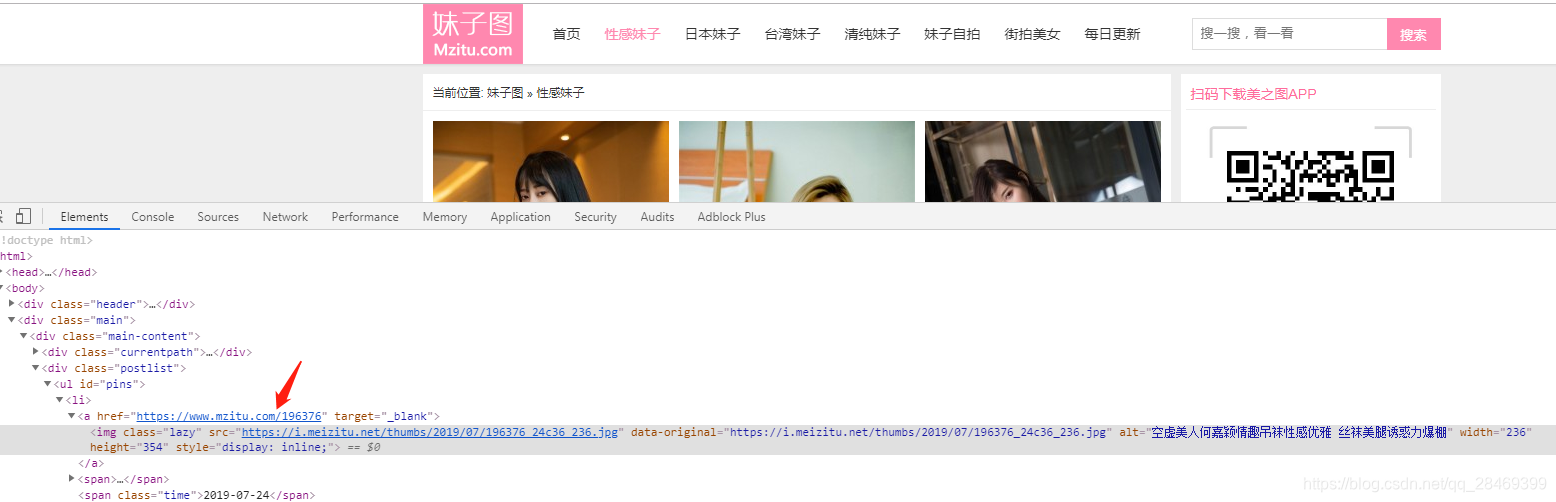
代码编写
items.py
class MeizituItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field()
pipelines.py
class MeizituPipeline(object):
def process_item(self, item, spider):
return item
settings.py
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:65.0) Gecko/20100101 Firefox/65.0',
'Referer':'https://www.mzitu.com/xinggan/',
'Cookie':'BAIDUID=F660214629B549A8C8C22F50416150B7:FG=1; BIDUPSID=F660214629B549A8C8C22F50416150B7; PSTM=1540432706; HMACCOUNT=03EE5D782043D96A; BDUSS=X4teUpSZGxxVUNwZmNuaEFzfnFsazlDYjFFSjRGY3ZMMXpMRHF3ZnRlOVVFdmxiQVFBQUFBJCQAAAAAAAAAAAEAAACwLQs30Ka~tMLkyNWy0NH0AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFSF0VtUhdFbU; H_PS_PSSID=1447_21125_20697_28557_28608_28584_28604_28626_28605; HMVT=6bcd52f51e9b3dce32bec4a3997715ac|1552549118|dbc355aef238b6c32b43eacbbf161c3c|1552549160|; delPer=0; PSINO=1; BDRCVFR[gltLrB7qNCt]=mk3SLVN4HKm; cflag=13%3A3; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; BDRCVFR[SsB3xVCBoFf]=Ae1_MfEv1LYmLPbUB48ugf; locale=zh'
}
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline':1,
}
#存放图片的目录,如果不自己修改的话,scrapy会在指定的目录下载新建一个full的文件夹,下载的图片会存放当改文件夹中
IMAGES_STORE = 'meizitudownload'
spiders.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from meizitu.items import MeizituItem
class MeizituSpiderSpider(scrapy.Spider):
name = 'meizitu_spider'
start_urls = ['https://www.mzitu.com/xinggan/']
def parse(self, response):
links = response.xpath('//ul[@id="pins"]/li/a/@href').extract()
for link in links:
yield scrapy.Request(link,callback=self.image_parse)
next_url = response.xpath('//a[@class="next page-numbers"]/@href').extract_first()
if next_url:
yield scrapy.Request(next_url,self.parse)
def image_parse(self,response):
next_image = response.xpath('/html/body/div[2]/div[1]/div[3]/p/a/@href').extract_first()
iamge_url = response.xpath('/html/body/div[2]/div[1]/div[3]/p/a/img/@src').extract_first()
item = MeizituItem()
item['image_urls'] = [iamge_url]
yield item
if str(next_image).startswith(response.url[:str(response.url).rindex('/')]):
yield scrapy.Request(next_image,self.image_parse)
注意,每张图片点进去之后是有详细页面的,每个图点进去的图片数量不定,所以在代码中对此有做处理,最终爬取的结果在性感页签下大概爬取了有12万张图片吧。
有所不对地方,望大家留言指教。

















 1734
1734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









